はじめに
この記事はMastodon Advent Calendar 2018 23日目 と Keras Advent Calendar 2018 23日目 の記事になってます。(重複させちゃいけなかったかな?まいっか)
趣味でMastodon上で稼働するbot をいじってます。おしゃべり機能等にディープラーニングを使ったりしてます。
今回はおしゃべり機能(日本語文章の自動生成)に関した内容です。
主旨
タイムライン上の会話の流れを読んで、流れに応じた内容の文章を自動生成して投稿してみようというものです。
(以前LSTMを使用して文章の自動生成にチャレンジしていますが、それをもうちょっと発展させてみた感じです)
doc2vecを使用して各トゥートをベクトル化し未来のトゥートのベクトルを予想、その予想したベクトルから日本語の文章をLSTMで自動生成するような流れです。
環境
ubuntu 18.04/python 3.6/cuda 9.0
tensorflow 1.12.0(Keras APIを使用)
gensim 3.6.0
Mecab
大まかな仕組み
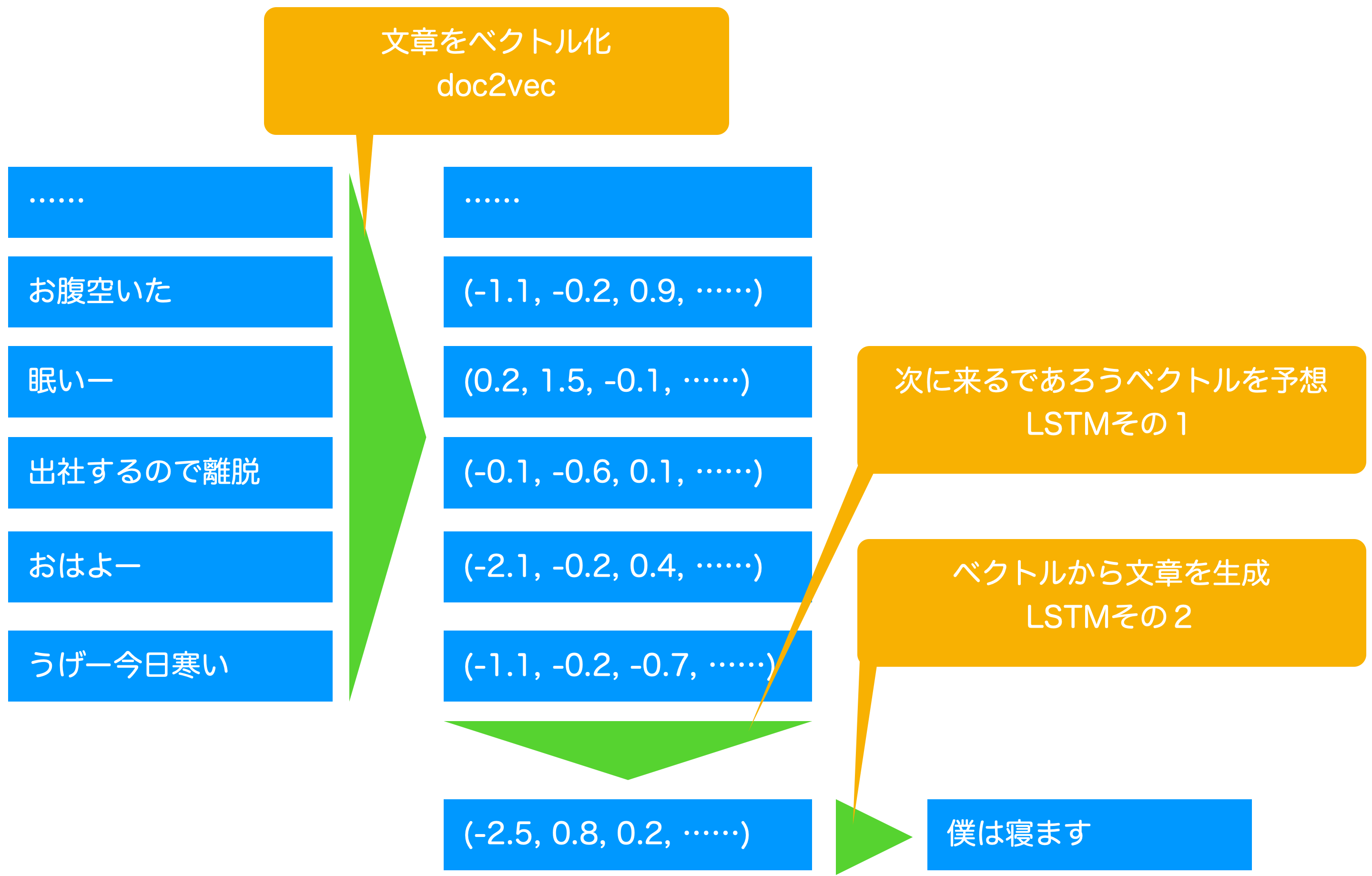
実装
ソースコードはgithubで公開しています。ご参考まで。
学習データ
学習データとして、今回は30万トゥート(投稿)を用意しました。下処理としてテキストの標準化(アルファベットや記号の半角/全角の統一など)を行っています。
doc2vecするために、上記をMecabを使って「分かち書き(単語をスペース区切り)」したものを作ります。
doc2vecのドキュメントタグは各トゥートのIDを使用します。
doc2vec
まずは、各トゥートをベクトル化します。
doc2vecにgensimを使います。出力するベクトルは256次元としました。
30epochsで1〜2時間くらいかかったと思います。
# -*- coding: utf-8 -*-
import logging
import sys,os
from gensim.models.doc2vec import Doc2Vec
from gensim.models.doc2vec import TaggedDocument
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
f = open(sys.argv[1])
tags = f.readlines() # 1行毎にファイル終端まで全て読む(改行文字も含まれる)
f.close()
f = open(sys.argv[2])
lines = f.readlines() # 1行毎にファイル終端まで全て読む(改行文字も含まれる)
f.close()
training_docs = []
sentents = []
for (line,tag) in zip(lines,tags):
# 各文書を表すTaggedDocumentクラスのインスタンスを作成
# words:文書に含まれる単語のリスト(単語の重複あり)
# tags:文書の識別子(リストで指定.1つの文書に複数のタグを付与できる)
sentents.append(line)
sent = TaggedDocument(words=line.split(), tags=tag.split())
# 各TaggedDocumentをリストに格納
training_docs.append(sent)
# 学習実行(パラメータを調整可能)
# documents:学習データ(TaggedDocumentのリスト)
# min_count=1:最低1回出現した単語を学習に使用する
# 学習モデル=DBOW(デフォルトはdm=1:学習モデル=DM)
if not os.path.exists(sys.argv[3]):
model = Doc2Vec(documents=training_docs,
vector_size=256,
window=5,
#alpha=0.0025,
#min_alpha=.0001,
min_count=5,
sample=1e-5,
workers=4,
epochs=30,
negative=5,
hs=1,
dm=1)
else:
model = Doc2Vec.load(sys.argv[3])
model.train(documents=training_docs, epochs=50, total_examples=model.corpus_count)
model.save(sys.argv[3])
LSTMで未来のベクトルを予想
トゥートのベクトルができたので、このベクトルを時系列に読み込み次のベクトルを予測する自己回帰モデルをLSTMで作ります。
実はこのベクトル予想、簡単にはうまく行かずかなり試行錯誤しています。(最終的にうまく行ったのかどうかも自信はないですが)
単純に1トゥート単位でLSTMを構築して学習させると、どんな入力ベクトルが来ても、似たようなベクトルしか出力しないモデルになってしまいました。
推測ですが、当該Mastodonインスタンスでは「空リプが多くトゥート間の関連が(人間にも)わかりにくい」という特徴があるため、
- LSTMではベクトルの時系列に法則性を見い出せなかった(ランダムにしか見えない)
- LOSSを最小とするためには全トゥートベクトルの平均値を出力するしかなくなった
ということではないかと思います。
LSTMをより深くしても改善せず、1次元畳み込み(Convolution1D)を使ったモデルでも試しましたが結果は一緒でした。
取り敢えずの解決策として、1トゥート単位の入力/予測ではなく、直近nトゥート(下記ソースコードの"AVE_LEN = 5")の平均値を取るやり方で進めました。
self.vecs[i,:] = np.mean(temp_vecs[i:i+AVE_LEN,:], axis=0)
これで、1トゥート単位では変化が鋭すぎて予測不能だったものが、nトゥート平均ベクトルにすることでじんわりと変化するベクトルに均されて”雰囲気を表す”ベクトルをある程度予測できるようになったような気がします。
学習には1〜2時間程度かかったと思います。
# -*- coding: utf-8 -*-
from tensorflow.keras.models import Sequential,load_model
from tensorflow.keras.callbacks import LambdaCallback,EarlyStopping
from tensorflow.keras.layers import Dense, Activation, Conv1D, LSTM,\
Dropout, GaussianNoise, BatchNormalization , Flatten, MaxPooling1D
from tensorflow.keras.optimizers import RMSprop, Adam
from tensorflow.keras.utils import Sequence, multi_gpu_model
from tensorflow.keras import backend
from gensim.models.doc2vec import Doc2Vec
import multiprocessing
import numpy as np
import random,json
import sys,io,re,os
from time import sleep
import argparse
from math import ceil
import tensorflow as tf
graph = tf.get_default_graph()
# 変更するとモデル再構築必要
VEC_SIZE = 256 # Doc2vecの出力より
MAXLEN = 5 # vec推定で参照するトゥート(vecor)数
AVE_LEN = 5
# いろいろなパラメータ
epochs = 10000
# 同時実行プロセス数
process_count = multiprocessing.cpu_count() - 1
def lstm_model():
model = Sequential()
model.add(LSTM(1024, return_sequences=True, input_shape=(MAXLEN, VEC_SIZE)))
model.add(LSTM(512))
model.add(Dense(VEC_SIZE))
return model
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--d2v_model", type=str)
parser.add_argument("--model_path", type=str)
parser.add_argument("--toots_path", type=str)
parser.add_argument("--tags_path", type=str)
parser.add_argument("--gpu", type=str, default='1')
parser.add_argument("--idx", type=int, default=0)
parser.add_argument("--batch_size", type=int, default=256)
parser.add_argument("--step", type=int, default=1)
args = parser.parse_args()
return args
class DataGenerator(Sequence):
def __init__(self, d2v_model, batch_size=1, step=1):
# コンストラクタ
self.d2v_model = d2v_model
self.batch_size = batch_size
temp_vecs = d2v_model.docvecs.vectors_docs
self.vecs = np.zeros((temp_vecs.shape[0] - AVE_LEN, temp_vecs.shape[1]))
for i in range(temp_vecs.shape[0] - AVE_LEN):
self.vecs[i,:] = np.mean(temp_vecs[i:i+AVE_LEN,:], axis=0)
def __len__(self):
# 全データ数をバッチサイズで割って、何バッチになるか返すよー!
deta_len = self.vecs.shape[0] - MAXLEN
sample_per_epoch = ceil(deta_len/self.batch_size)
return sample_per_epoch
def __getitem__(self, idx):
# データの取得実装
x = []
y = []
for i in range(self.batch_size*idx,min([self.vecs.shape[0] - MAXLEN, self.batch_size*(idx+1)])):
x.append(self.vecs[i:i + MAXLEN, :])
y.append(self.vecs[i + MAXLEN, :])
return np.asarray(x), np.asarray(y)
def on_epoch_end(self):
# Function invoked at end of each epoch. Prints generated text.
print()
print('----- Generating text after Epoch')
start_index = random.randrange(0, self.vecs.shape[0] - MAXLEN)
x_pred = self.vecs[start_index:start_index + MAXLEN, :]
for i in range(MAXLEN):
ret = self.d2v_model.docvecs.most_similar([x_pred[i,:]])
id, score = ret[0]
print(f"in:{score:3f} {toots[id]}")
print("ans:",toots[tags[start_index + MAXLEN]])
print("ans:",self.vecs[start_index + MAXLEN, :10])
x_pred = np.reshape(x_pred,(1,x_pred.shape[0],x_pred.shape[1]))
with graph.as_default():
preds = model.predict_on_batch(x_pred)
print(f"pred vec ={preds[0][:10]}")
ret = self.d2v_model.docvecs.most_similar(preds)
for id, score in ret:
print(f"out:{score:3f} {toots[id]}")
def on_epoch_end(epoch, logs):
### save
print('----- saving model...')
model.save(args.model_path)
if __name__ == '__main__':
#パラメータ取得
args = get_args()
#GPU設定
config = tf.ConfigProto(gpu_options=tf.GPUOptions(allow_growth=False,
visible_device_list=args.gpu
))
session = tf.Session(config=config)
backend.set_session(session)
GPUs = len(args.gpu.split(','))
d2v_model = Doc2Vec.load(args.d2v_model)
tags = [tmp.strip() for tmp in open(args.tags_path).readlines()]
toots = {tag:toot.strip() for tag,toot in zip(tags,open(args.toots_path).readlines())}
if os.path.exists(args.model_path):
# loading the model
print('load model...')
model = load_model(args.model_path)
else:
model = lstm_model()
model.summary()
model.compile(loss='mean_squared_error', optimizer=RMSprop())
m = model
if GPUs > 1:
p_model = multi_gpu_model(model, gpus=GPUs)
p_model.compile(loss='mean_squared_error', optimizer=RMSprop())
m = p_model
generator = DataGenerator(d2v_model=d2v_model, batch_size=args.batch_size)
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
ES = EarlyStopping(monitor='loss', min_delta=0.0001, patience=10, verbose=0, mode='auto')
m.fit_generator(generator,
callbacks=[print_callback,ES],
epochs=epochs,
verbose=1,
# steps_per_epoch=60,
initial_epoch=args.idx,
max_queue_size=process_count,
workers=2,
use_multiprocessing=False)
予想したベクトルを元にLSTMで文章生成
先人の知恵 をお借りしました。
Mastodonでもお世話になっている方で、今回の発想もこの方から パクり 参考にさせてもらっています。
ここでのポイントは主に以下です。
- 文章の生成は、”単語”ではなく”文字”単位で生成します。
- 文字にはそれぞれIDを振り、Embedding層で256次元のベクトルに変換しています。(doc2vecの次元数に合わせています)
- インプットは2つ。1つは直近の文字(のID)、もう一つは前述で予測したベクトル(雰囲気を示すベクトル)
- この2つを結合(concatenate)してLSTM層へ渡し、雰囲気に合わせた文字を予測することを期待します(結合させる都合上、次元を合わせました)
- ベクトル化した30万トゥート分のベクトルを雰囲気ベクトルとし、それぞれのトゥートの文字列を使って自己回帰的に学習させます
学習には1〜2時間程度かかったと思います。
# -*- coding: utf-8 -*-
from tensorflow.python.keras.models import Sequential,load_model,Model
from tensorflow.python.keras.callbacks import LambdaCallback,EarlyStopping
from tensorflow.python.keras.layers import Dense, Activation, CuDNNLSTM, LSTM, Dropout,\
GaussianNoise, BatchNormalization, Embedding, Flatten, Input, Concatenate, Reshape
from tensorflow.python.keras.optimizers import RMSprop
from tensorflow.python.keras.utils import Sequence, multi_gpu_model
from tensorflow.python.keras import backend
# from tensorflow.python.keras.preprocessing.text import Tokenizer
import multiprocessing
import numpy as np
import random,json
import sys,io,re,os
from time import sleep
import argparse
import math
from gensim.models.doc2vec import Doc2Vec
import tensorflow as tf
graph = tf.get_default_graph()
# 変更するとモデル再構築必要
VEC_SIZE = 256 # 文字ベクトル次元/トゥートベクトル次元
MAXLEN = 5 # timestep
MU = "🧪" # 無
END = "🦷" # 終わりマーク
# いろいろなパラメータ
epochs = 10000
# 同時実行プロセス数
process_count = multiprocessing.cpu_count() - 1
def lstm_model():
num_chars = len(wl_chars)
input_chars = Input(shape=(MAXLEN,))
layers = Embedding(input_dim=num_chars+2,
output_dim=VEC_SIZE,
input_length=MAXLEN)(input_chars)
input_vector = Input(shape=(VEC_SIZE,))
vector = Reshape(target_shape=(1, VEC_SIZE))(input_vector)
layers = Concatenate(axis=1)([vector, layers])
layers = LSTM(1024, return_sequences=True)(layers)
layers = LSTM(512)(layers)
layers = Dropout(0.3)(layers)
layers = Dense(num_chars+2, activation='softmax')(layers)
return Model(inputs=[input_vector, input_chars], outputs=[layers])
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, default='train')
parser.add_argument("--input", type=str)
parser.add_argument("--model_path", type=str)
parser.add_argument("--d2v_path", type=str)
parser.add_argument("--gpu", type=str, default='0')
parser.add_argument("--idx", type=int, default=0)
parser.add_argument("--batch_size", type=int, default=256)
parser.add_argument("--step", type=int, default=1)
args = parser.parse_args()
return args
def sample(preds, temperature=1.0):
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
class DataGenerator(Sequence):
def __init__(self, toots_path, d2v_model, batch_size=1, step=1):
# コンストラクタ
self.idx_char = {i:c for i,c in enumerate(wl_chars)}
self.num_chars = len(self.idx_char)
self.idx_char[self.num_chars] = MU
self.idx_char[self.num_chars+1] = END
self.char_idx = {c:i for i,c in enumerate(wl_chars)}
self.char_idx[MU] = self.num_chars
self.char_idx[END] = self.num_chars + 1
self.vecs = d2v_model.docvecs.vectors_docs
self.toots = list([tmp.strip() for tmp in open(toots_path).readlines()])
self.x_vecs_id = []
self.x_idxs = []
self.y_next_idx = []
for id,toot in enumerate(self.toots):
tmp_chars = MU * MAXLEN
for next_char in toot+END:
tmp_idxs = []
try:
for char in tmp_chars:
tmp_idxs.append(self.char_idx[char])
# tmp_mat = np.zeros((self.num_chars+1))
# tmp_mat[ self.char_idx[next_char] ] = 1
tmpidx = self.char_idx[next_char]
except Exception:
pass
else:
self.x_vecs_id.append(id)
self.x_idxs.append(tmp_idxs)
self.y_next_idx.append(tmpidx)
tmp_chars = tmp_chars[1:] + next_char
self.batch_size = batch_size
self.step = step
def __getitem__(self, idx):
# データの取得実装
vecs = [self.vecs[i] for i in self.x_vecs_id[self.batch_size*idx:self.batch_size*(idx+1)]]
tmp_mat = []
for i,j in enumerate( self.y_next_idx[self.batch_size*idx:self.batch_size*(idx+1)]) :
mat = np.zeros((self.num_chars+2))
mat[j] = 1
tmp_mat.append(mat)
return [np.asarray(vecs),\
np.asarray(self.x_idxs[self.batch_size*idx:self.batch_size*(idx+1)])],\
np.asarray(tmp_mat)
def __len__(self):
# 全データ数をバッチサイズで割って、何バッチになるか返すよー!
deta_len = len(self.x_vecs_id)
sample_per_epoch = math.ceil(deta_len/self.batch_size)
return sample_per_epoch
def on_epoch_end(self):
# Function invoked at end of each epoch. Prints generated text.
print()
print('----- Generating text after Epoch')
# start_index = random.randrange(0, len(self.x_idxs))
starts = random.sample(range(0, len(self.vecs)),5)
for start_index in starts:
vec = self.vecs[start_index]
toot = self.toots[start_index]
for diversity in [0.1, 0.25, 0.4]:
print()
print('----- diversity:', diversity)
generated = ''
idxs = [self.char_idx[MU] for _ in range(MAXLEN)]
print('----- toot on input vec: "' + toot + '"')
sys.stdout.write(generated)
for i in range(50):
with graph.as_default():
preds = model.predict_on_batch([ np.asarray([vec]), np.asarray([idxs]) ])
next_index = sample(preds[0], diversity)
idxs = idxs[1:]
idxs.append(next_index)
next_char = self.idx_char[next_index]
generated += next_char
sys.stdout.write(next_char)
sys.stdout.flush()
if next_char == END:
break
print()
def on_epoch_end(epoch, logs):
### save
sleep(5)
print('----- saving model...')
model.save(args.model_path)
if __name__ == '__main__':
#パラメータ取得
args = get_args()
#GPU設定
config = tf.ConfigProto(gpu_options=tf.GPUOptions(allow_growth=False,
visible_device_list=args.gpu
))
session = tf.Session(config=config)
backend.set_session(session)
GPUs = len(args.gpu.split(','))
wl_chars = list(open('wl.txt').read())
if os.path.exists(args.model_path):
# loading the model
print('load model...')
model = load_model(args.model_path)
else:
model = lstm_model()
model.summary()
model.compile(loss='categorical_crossentropy', optimizer=RMSprop()) #mean_squared_error
m = model
if GPUs > 1:
p_model = multi_gpu_model(model, gpus=GPUs)
p_model.compile(loss='categorical_crossentropy', optimizer=RMSprop())
m = p_model
d2v_model = Doc2Vec.load(args.d2v_path)
generator = DataGenerator(toots_path=args.input, d2v_model=d2v_model, batch_size=args.batch_size, step=args.step)
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
ES = EarlyStopping(monitor='loss', min_delta=0.0001, patience=10, verbose=0, mode='auto')
if args.mode == 'train':
m.fit_generator(generator,
callbacks=[print_callback,ES],
epochs=epochs,
verbose=1,
# steps_per_epoch=60,
initial_epoch=args.idx,
max_queue_size=process_count,
workers=2,
use_multiprocessing=False)
else:
generator.on_epoch_end()
実験結果
"input"が入力トゥート、"gen text"が会話の流れを読んで自動生成した文章です。
input**********************
オン会で呑も呑も
いい景色やったね
いい景色じゃねーか草
朝ごはんピルクル買ってきた!
やりすぎた影響でメトロポリスレベルまで来てしまった
とーふだよ
とーふ君じゃないか
なに勝手にロック画面変わってるんだよ、いい景色じゃねーか
:@_tofu: とーふ(✿ ́ ꒳ ` )ぐっといーぶにんーー♪
づほさんと一緒にお酒飲みたい
gen text******************
さすがに草
10トゥートの中に話題が4個くらいあるように見えます。
とりあえず、無難な発言を選んだのかも?
input**********************
服脱ぎますね
まず服を脱ぎます
人類はやがてGoogleやAmazonだけで生活できる時代が来るだろう実質、コンテンツもただもしくは月額数百円のみで消費できる時代になりつつあるし
着方がわかんねえwwwwww
会議をシステム化すれば、不要な人の出席を要求したり、不必要に長い時間束縛したり、会議をしたけれども結論が出なかったということを回避できそうなのですが、会議というものの性質上、会議をシステム化することを嫌う人たちは非常にたくさんいそうな気はします
ふむふむ
ですね〜
頭からカジられてるやん...
* 「今日は何の日」『フリー百科事典 ウィキペディア日本語版』。Mon, 03 Dec 2018 02:18:40 GMT
なんとなく着てみるか
gen text******************
現実はそれは
現実を見せないでー
input**********************
どっちだよ
天を笑いで買うで草
遅刻証明しようとしてニコフレを先生に見せるシエスタ
ハートビットはブラックだったとか噂も耳にした記憶
長湯するなって言われた:;(∩ ́_`∩);:
天を笑いで買ってたのか
いつも5kはアレだな
ポッターしなくても音割れしてるのにポッターしたら鼓膜5、6枚は破れそう
先生に画面見せるだけで遅延認定だから優しい
アニメ「フランチェスカ」イマイチだったもんなぁ
gen text******************
カメラになった
カメラになっちゃったかー
input**********************
のどにまたね!
にんにくならブレスケアをどうぞ
飲めば多分消えるんじゃない?やったことないけど
大人の話になってました
中央快速線止まっ「てた」のか
リステリンでにんにくは消えないいいね?
お店の人がライム入れてくれてたけど、わからなかった!ばかなのかもしれない!
しばさんイケメンじゃないですか
つーか、マストドンなんかオ**コ叫んでいる連中ばかりじゃないか
かしなりるちゃん、しばがそれは食べるよ
gen text******************
おうどんたべたい
おうどん、おいしいもんねー
食べ物の話からうどんに持っていったのかな?
input**********************
ほわほわもふもふー
MacOSマウンテンライオンの時に戻してぇあのメタリックのやつに戻せぇ
ICレコーダー並の回転速度ってなんだよ(嘲笑)
ふふ...切れ痔ったら拗ねちゃって...///
目と首が痛い
:@tellus52: ぱれおさん(*'∀'人)こんにちはです♪
『切れ痔界隈』
おひるー
あとは適当にここに乗せてあったりするから見てね
切れ痔拗らせるとこうなるよ
gen text******************
腹痛い
「痛い」発言につられたのかな?
まとめ
会話の流れを読めているのかはよくわかりませんが、まあ良しとしました。
ベクトル推定部分がイマイチな感じなので、機会があれば改良してみたいと思います。