論文とコード
- Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, Yinxiao Li, MaxViT: Multi-Axis Vision Transformer, arXiv:2204.01697, 2022
- コード(https://github.com/google-research/maxvit)
挿入している画像は、特に言及していない限り、本論文からの引用となります。
概要
Transformerモデルは、画像認識分野で注目を集めています。しかし、完全なセルフアテンションは画像サイズが大きくなると計算量が増大するため、大規模な画像認識タスクへの適用が難しくなります。これを解決するために、ウィンドウベースのアテンションが提案されましたが、この方法では情報を取り込む範囲が狭くなり、大きなデータセットでは性能が低下する傾向があります。論文では、この課題を解決する新しいMulti-axis self-attention (Max-SA)を提案しています。Max-SAは、局所的なアテンションと大域的なアテンションを組み合わせることで、高い性能を発揮できるアテンション機構です。また、任意の画像サイズに対して線形計算量で済むため、大きなデータセットでも適用可能です。さらに、Max-SAを畳み込み層と効果的に組み合わせるハイブリッドな構造も提案しています。これを基本ブロックとして階層的に積み重ねたMulti-axis Vision Transformer (MaxViT)は、画像分類、物体検出、インスタンスセグメンテーション、画像美学評価、画像生成の幅広いタスクで最先端の性能を達成することができています。
MaxViTの構造
以下に、MaxViTの全体的なアーキテクチャを示します。
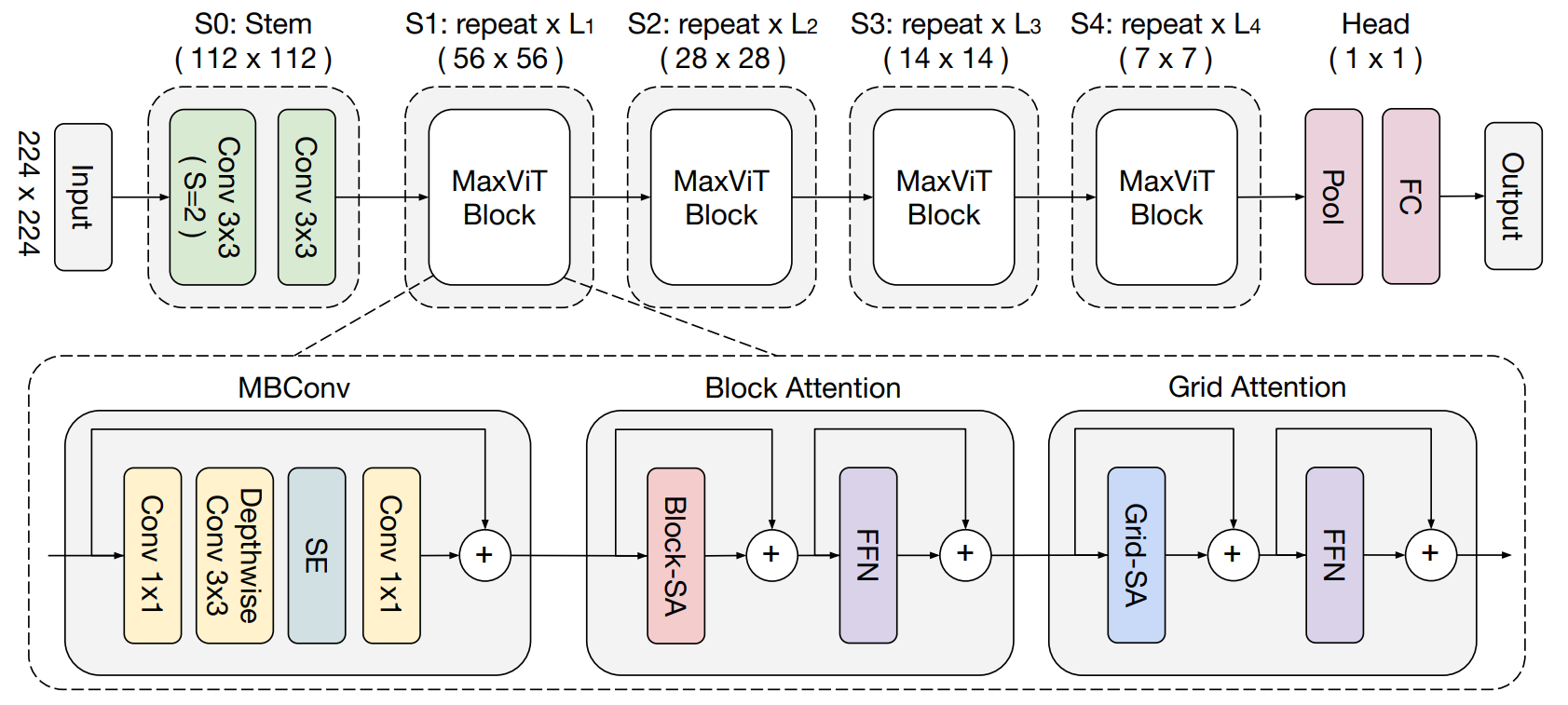
入力画像は、Stem層を経て、Conv3x3(ストライド=2)によるダウンサンプリングが行われます。ネットワーク本体は4つのステージから成り、各ステージは前のステージの解像度を半分にし、チャンネル数を2倍にします1。これらのステージでは、MaxViT Blockを複数回適用されます。MaxViT Blockは、畳み込みネットワークとTransformer Blockを組み合わせたハイブリッド構造が採用されています。具体的には、MBConvによるダウンサンプリングを含む畳み込み、Block Attentionによる局所的な相互作用、Grid Attentionによる大域的な相互作用によって構成されています。また、Block AttentionとGrid Attentionは一般的なTransformer Blockと同様に、Attention機構とFFNの前後にそれぞれレイヤーノルム層と残差結合が配置されています。図には、正規化層や活性化層が省略されています。
MBConv
MBConvは、まず入力の特徴マップに対してバッチ正規化を適用し、その後に1x1の畳み込みを用いてチャンネル数を4倍増やします。次に、バッチ正規化とGELU活性化関数を適用し、ダウンサンプリングを実施するためにストライド数2のDepthwiseConv3x3を使用します。このDepthwiseConv3x3は、条件付き位置エンコーディング(CPE)として見なすことができます。その後、再びバッチ正規化とGELU活性化関数を適用し、Squeeze-and-Excitation (SE)モジュールでチャンネルごとの重要度を調整します。最後に、チャンネル数を半分に減少させる1x1の畳み込みを行い2、残差結合を追加します。残差結合を行う際、入力特徴マップとConv1x1の出力特徴マップの形状を一致させるために、入力特徴マップの空間形状を平均値プーリングで変更し、チャンネル形状をConv1x1によって調整する操作が追加されます。
同じステージでMaxViT Blockを複数回実行する場合、2回目以降は、ダウンサンプリングは行わず、代わりにストライド数1のDepthwiseConv3x3を実行します。また、最後のConv1x1によるチャンネル変換では、チャンネル数を4分の1に減らします2。これらの変更により、2回目以降のConv1x1の出力は、入力特徴マップと同じ空間次元とチャンネル数を持つ形状となります。これは、残差結合を行う際に、平均値プーリングやチャンネル変換の操作が不要になることを意味します。
Squeeze-and-Excitation module
CNNは局所的な空間依存関係をよく捉えますが、チャンネル間の依存関係をうまく捉えられません。SEは、この弱点を補うために、チャンネル間の依存関係を明示的にモデル化する手法です。SEは、Squeeze操作とExcitation操作の2つのステップで構成されています。Squeeze操作は、グローバル平均プーリングを使用して、空間次元を1x1に縮小し、各チャンネルの特徴量を抽出します(下図の$F_{sq}$)。Excitation操作は、抽出した特徴量を元に、各チャンネルの重要度を決定します(下図の$F_{ex}$)。重要度は、2つの1x1畳み込みとその間にSwish非線形活性化関数によって計算され、最後にシグモイド関数を使用して0から1に変換されます。最終的に、重要度と入力特徴量マップを乗算して、出力特徴量マップを生成します(下図の$F_{scale}$)。これにより、重要度が大きいチャンネルは、出力特徴量マップにおいて強調され、重要度が小さいチャンネルは弱められます。
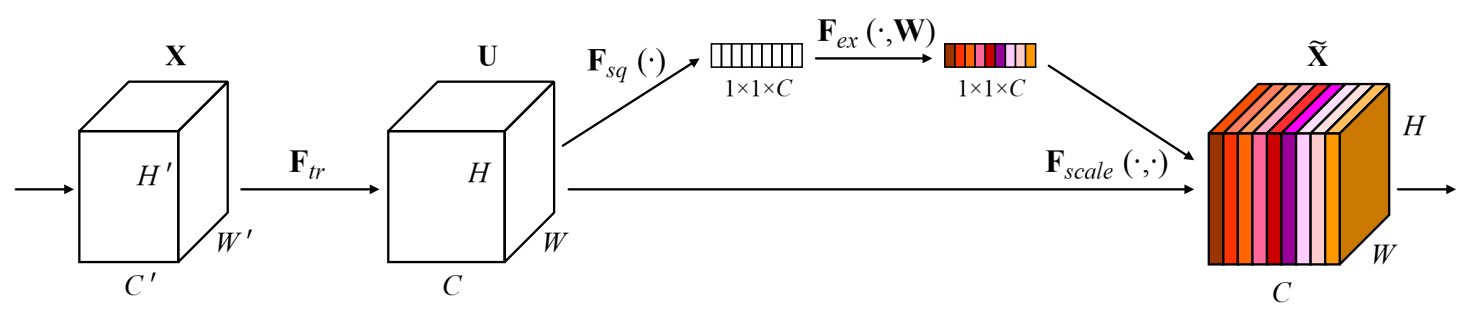
図: SEブロック(Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks, arXiv:1709.01507, 2017より)
Multi-axis Attention
Max-SAは、空間軸を分割して局所的な相互作用と大域的な相互作用を別々に計算するアテンション機構です。局所的な相互作用はBlock Attentionと呼ばれる手法で計算され、大域的な相互作用はGrid Attentionと呼ばれる手法で計算されます。下図に示すように、Block Attentionはウィンドウ内のセルフアテンションを行い、Grid Attentionは、全体の2D空間に等間隔に配置されたグリッド上のピクセルに対してセルフアテンションを行います。
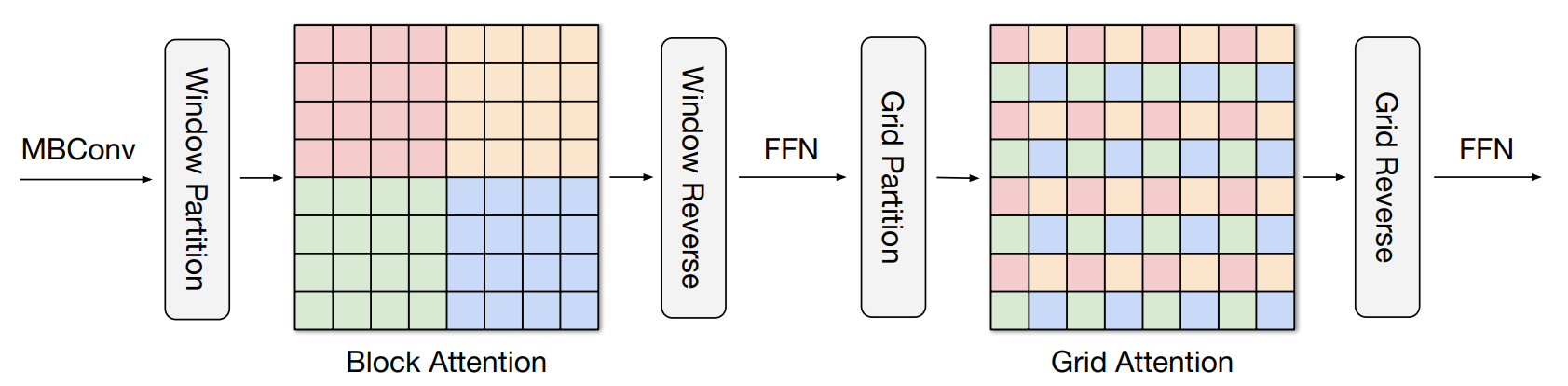
これらのセルフアテンションは、入力データサイズに比例した計算コストで動作します。ただし、セルフアテンションを適用する前後には、特徴マップをウィンドウまたはグリッドに分割する操作と、分割された特徴マップを元の空間に戻すための結合操作が必要です。分割後は、分割方式に関係なく、相対位置エンコーディングを追加した通常のセルフアテンションを適用します。そのため、この手法では、マスクやパディング、循環シフトなどの複雑な操作は不要です。分割用と結合用の次元操作を変更するだけで実装でき、その次元操作は、以下のように簡単に実装できます。
# 特徴マップのバッチ次元と特徴量次元を省略し、空間次元のみを考慮した行列xに対して、
# ウィンドウ方式とグリッド方式で分割し、その後、それらを元に戻す結合操作を行います
import torch
h = w = 6
window_size = grid_size = 3
x = torch.arange(h * w).view(h, w)
# ウィンドウ分割: (h, w) -> (num_windows, window_size, window_size)
windows = x.view(h // window_size, window_size, w // window_size, window_size).permute(0, 2, 1, 3)
windows = windows.contiguous().view(-1, window_size, window_size)
# ウィンドウ結合
x_restored_window = windows.view(h // window_size, w // window_size, window_size, window_size)
x_restored_window = x_restored_window.permute(0, 2, 1, 3).contiguous().view(h, w)
# グリッド分割: (h, w) -> (num_grids, grid_size, grid_size)
grids = x.view(grid_size, h // grid_size, grid_size, w // grid_size).permute(1, 3, 0, 2)
grids = grids.contiguous().view(-1, grid_size, grid_size)
# グリッド結合
x_restored_grid = grids.view(h // grid_size, w // grid_size, grid_size, grid_size)
x_restored_grid = x_restored_grid.permute(2, 0, 3, 1).contiguous().view(h, w)
print(x); print(windows); print(grids)
# tensor([[ 0, 1, 2, 3, 4, 5], tensor([[[ 0, 1, 2], tensor([[[ 0, 2, 4],
# [ 6, 7, 8, 9, 10, 11], [ 6, 7, 8], [12, 14, 16],
# [12, 13, 14, 15, 16, 17], [12, 13, 14]], [24, 26, 28]],
# [18, 19, 20, 21, 22, 23],
# [24, 25, 26, 27, 28, 29], [[ 3, 4, 5], [[ 1, 3, 5],
# [30, 31, 32, 33, 34, 35]]) [ 9, 10, 11], [13, 15, 17],
# [15, 16, 17]], [25, 27, 29]],
#
# [[18, 19, 20], [[ 6, 8, 10],
# [24, 25, 26], [18, 20, 22],
# [30, 31, 32]], [30, 32, 34]],
#
# [[21, 22, 23], [[ 7, 9, 11],
# [27, 28, 29], [19, 21, 23],
# [33, 34, 35]]]) [31, 33, 35]]])
print(torch.equal(x, x_restored_window) and torch.equal(x, x_restored_grid))
# True
実験
MaxViTの有効性を検証するために、様々な視覚タスクにおいて検証を行っています。これには、ImageNet分類、画像物体検出およびインスタンスセグメンテーション、画像の美学/品質評価、そして無条件の画像生成が含まれます。さらに、アブレーションスタディも行っています。以下では、画像分類の検証結果と、アブレーションスタディの一部を紹介します。
ImageNet-1Kにおける画像分類
以下の図は、MaxViTと最新のモデルのImageNet-1Kにおける性能比較を示しています。
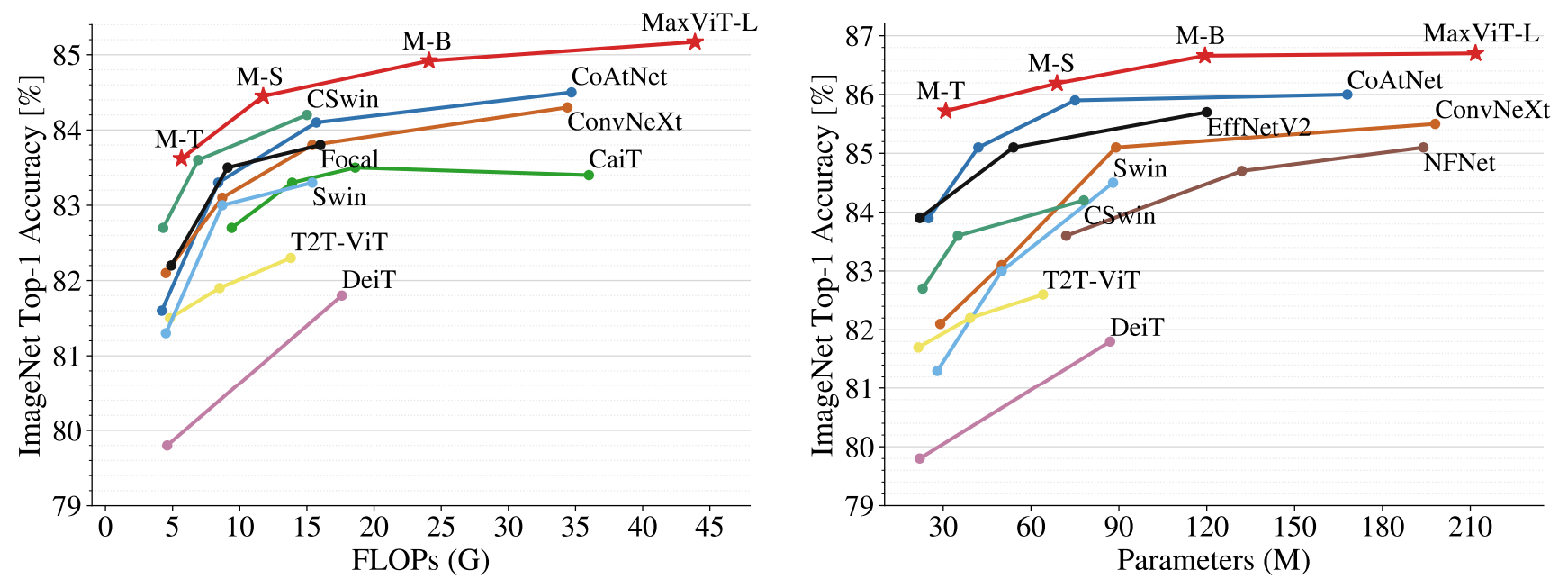
左図は、解像度が224x224でのトレーニング設定において、FLOPsと精度を比較しています。MaxViTは、最新のハイブリッドモデルであるCoAtNetを大きく上回っています。右図は、より高い解像度(384/512)でファインチューニングされた場合の、パラメータ数と精度の比較を表しています。MaxViTは、CoAtNet、Convモデル、Transformerモデルと比較して、高いパフォーマンスを示しています。さらに、より大規模なデータセットを用いて事前学習したモデルの性能評価も行っています。

左図はImageNet-21Kで、右図はJFT-300Mでの事前学習を示しています。MaxViTは高い精度を実現し、同じモデルサイズの以前のモデルを上回っています。右図におけるより大きなモデルのCoAtNet(Params=688M,FLOPs=812G)は、MaxViT-XL(Params=475M,FLOPs=535.2G)よりも0.24%高い精度を達成しています。
前回の記事で取り上げたAxWin Transformerは、MaxViTと同様に、局所的および大域的なアテンション機構を組み込んだトランスフォーマーです。これらの2つのモデルにはいくつかの違いがありますが、特に大きな違いの一つは、大域的なアテンションの仕組みがグリッドアテンションから軸ベースアテンションに変更されていることです。また、局所的セルフアテンションと大域的アテンションが逐次的な実行ではなく、並列設計が採用されている点も大きな違いの一つです。以下の表では、両者の性能を比較しています。比較結果からは、AxWin Transformerが少ないパラメータ数と計算コストでありながら、高い精度を達成しています。画像サイズの拡大や、より大規模なデータセットで事前学習したとき、あるいは異なる視覚タスクにおける比較も興味深いところですが、これらに関する比較資料は見当たりませんでした。
| Model | Size | Params | FLOPs | IN-1K Top-1 Acc.(%) |
|---|---|---|---|---|
| MaxViT-T | 224 | 31M | 5.6G | 83.62 |
| AxWin-T | 224 | 22M | 3.5G | 83.9 |
| MaxViT-S | 224 | 69M | 11.7G | 84.45 |
| AxWin-S | 224 | 48M | 7.6G | 84.6 |
| MaxViT-B | 224 | 120M | 23.4G | 84.95 |
| AxWin-B | 224 | 84M | 12.7G | 85.1 |
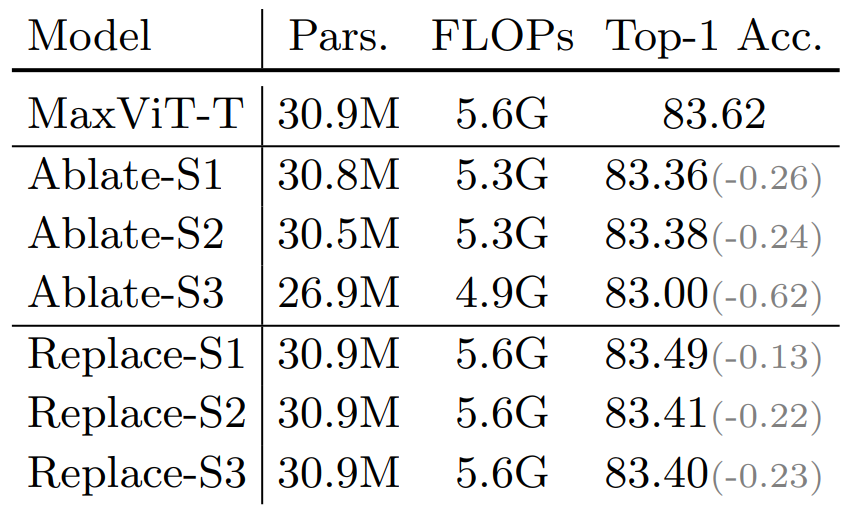
グリッドアテンションの効果
次の表は、各ステージからグリッドアテンションを削除したモデル(Ablate-Si)と、グリッドアテンションをブロックアテンションに置き換えたモデル(Replace-Si)の性能を比較しています。Siはステージ番号を表します。その結果、初期ステージからグリッドアテンションを有効にすると、モデルの性能が向上します。なお、Ablate-S3のパラメータ数、計算コスト、および精度は、他と比べて大きな影響を与えています。この要因の1つは、S3が他のステージと異なり、MaxViT Blockが5つ存在することです。他のステージではMaxViT Blockが2つしかないため、MaxViT Blockの数も影響を与えていると考えられます。
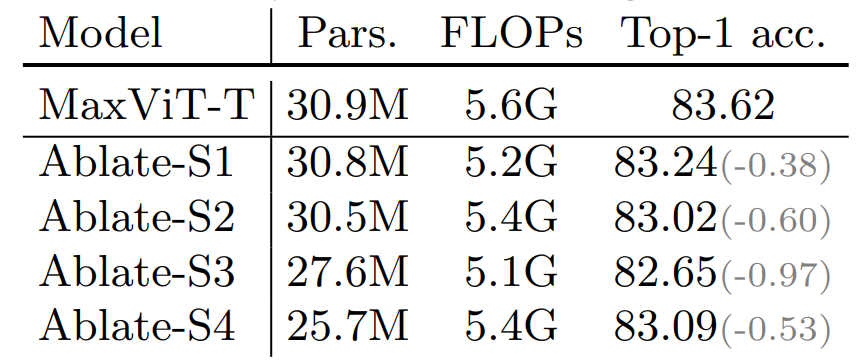
MBConvの重要性
次の表は、各ステージからMBConvを削除したモデル(Ablate-Si)の性能を比較しています。その結果、MBConvを使用すると性能を大幅に向上します。
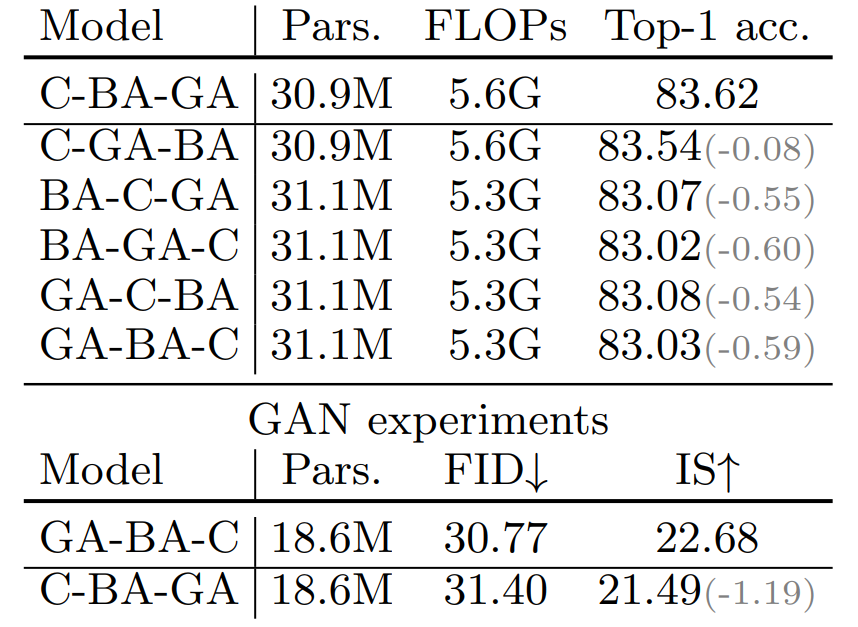
MaxViT Blockのコンポーネント順序と精度の関係
次の表は、MaxViT Blockを構成する3つのコンポーネント、MBConv(C)、Block Attention(BA)、Grid Attention(GA)の順番を入れ替えたときの精度の結果を示しています。BAとGAの順序は、精度にほとんど影響を与えません。しかし、MBConvをアテンションレイヤーの前に配置すると、他の組み合わせよりも精度が高くなります。これは、ローカルからグローバルへの順序が精度に有利であることを示しています。一方、画像生成タスクでは、グローバルからローカルへの順序、GA-BA-Cが最良の結果をもたらします。
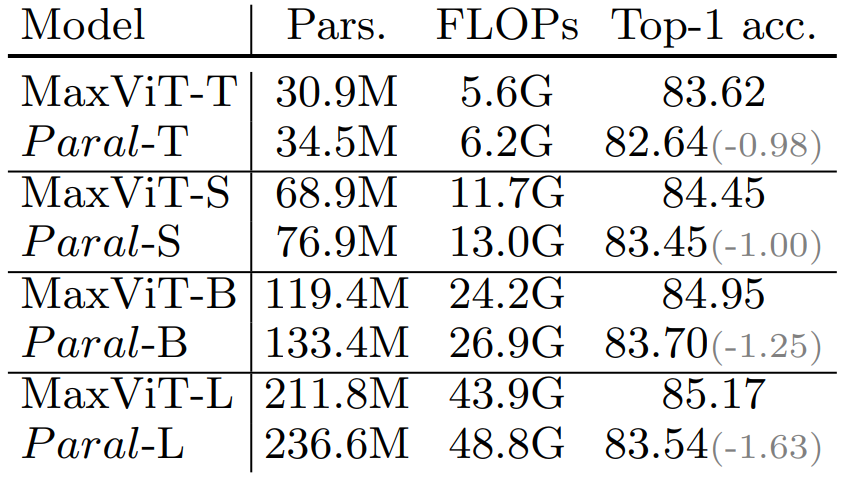
逐次設計と並列設計の性能比較
MaxViT Blockは、ブロックアテンションとグリッドアテンションを順に処理しますが、同時にこれらを並列に処理する設計も提案されています。この並列設計では、MaxViTと同等の複雑さを維持するために、チャンネル数を2倍にするなどの変換操作が行われます。以下の表は、逐次設計と並列設計の性能を比較したものです。その結果、逐次設計は、並列設計よりもパラメータ数と計算量が少なく、優れた性能を示しています。
結論
MaxViTは、効率的な畳み込みと局所的かつ大域的なアテンションを統合した設計により、さまざまな視覚タスクにおいて最先端の性能を達成しています。さらに、大規模なデータセットに対しても、高いスケーラビリティを備えてることが実証されています。