Amazon Aurora MySQL SQLチューニングについて解説していきます。

Webページやアプリにログインして、表示されるまで、時間がかかると、イライラしませんか?
使う側としては、画面が表示されるまでに、耐えられる時間って、限られていますよね?
そのため、ユーザが心地よく、Webページやアプリにログインして、
快適にコンテンツを表示させるよう、工夫が必要です。
その工夫の一つに、データベースのチューニングというものがあります。
チューニングって、何?という人のために、
データベースのチューニング3つに分類してみました。
①書き込み
インデックスの更新を抑止する
大量データは一括、並列で格納する
大量データ挿入時は一時的にインデックスを外す
COPYコマンドの利用や多重実行でデータを格納する
更新頻度が高い場合は、ページにテーブルやインデックスを格納する際、敢えて空き領域を作成していく仕組みを利用する
②検索
インデックスを有効活用する
ソート処理をインデックススキャンで代用する
複合インデックスは絞り込める順に記述する
③インフラ
データを整理し、統計情報を最新化する
ANALYZEで統計情報を手動で、最新化する
パラメーター調整で高速化する
今回は、インフラに焦点を当てて、お話したいと思います。
初めに、統計情報や実行計画のSQLチューニングを見ていきましょう。
これができるようになれば、単純にSQLを書くだけじゃなく、
パフォーマンス上問題ないかを意識しながらSQLが書けるようになります。
SQL上級者と言えるようになるかもしれません。
データベースでは、パフォーマンスが非常に重要になります。
データベースは、ただ、データを入れればいいわけではありません。SQLもただ書けばいいというわけではありません。
将来的のデータ増加を見越して、SQLが問題を起こさないようによく考えながら、
テーブル設計とSQLでチューニングをやっていく必要があります。
まずは、統計情報、実行計画について、考えてみましょう。
データベースの運用を続けていくと、データベースの容量というのは増えていきます
データ量がどんどん増えていきます。
SQLが適切に設計されてないと、データが増えるにつれて、どんどんスピードが遅くなっていって、
何年かしたらですね、
処理が返ってこないってことになりかねません。
パフォーマンスが劣化する可能性があります。
アプリケーションサーバーならば、スケールアウトが容易ですが、DBサーバーは、スケールアウトが難しいです。
(Amazon Aurora Serverlessは、例外ですが。。だだ、AuroraとAurora Serverlessは両方とも長短があります。)
これは、置いておいて、話を続けます。
データベースサーバーを増やすことが難しく、処理にSQLを流すと、それだけリソースを使ってしまって、
データベースサーバーでパンクしてしまって、処理を返せないということがあり得ます。
データベースの容量が増えすぎて、
あるページは表示できないとか、遅すぎて表示できないとか、
あるいは1週間ぐらい経っても、実行が終わらないSQLがずっとデータベースで回り続けて、リソースをすごく使ってるとか、
そのようになる可能性があります。
そのため、データベースがどれぐらい増えるのか、データ量がどれぐらい増えるのか、
性能的に問題ないのかなど考えながら、データベースを構築する必要があります。
オンライン処理で実行されるSQLは1秒以下の処理速度を目指した方がいいです。
オンライン処理というのは、ブラウザ画面や、アプリ画面で、ボタンを押して、
そのボタンを押した後に、次の画面が表示されるまでの時間の事をいいます。
一般的には、3秒以下で、次の画面が表示されるサイトが良いようです。
3秒以上かかると、ユーザーがイライラしてしまって、
サービス利用をやめてしまうことがありうるので、3秒以下で表示されるのが、ギリギリセーフかなと思います。
画面上に3秒で表示されるには、このデータベースのSQLは、それ以上に早くする必要があり、
基本的に1秒以下の処理速度が必要となります。
処理速度が速いと、リソースもその分使わなくて済みます。
処理速度が速いSQLで、リソースを処理しているので、パフォーマンス効率の良いSQLと言えます。
SQLは書き方によって、実行計画が変わってきます。
まず、Optimizerと実行計画についてご説明します。
SQLがどのように実行されるのか仕組みを紐解いて行こうと思います。
SQLは、そのまま実行されるのではなく、最も効率的に実行される処理内容(バイナリのプログラム)
を最終的に作成して実行されます。
例えば東京から名古屋に行く最短経路を決める場合を考えてみます。
飛行機で行くのか?新幹線で行くのか?どちらが早いのか、
名古屋空港か、JR名古屋駅どちらに行き先が近いのかに合わせて、
より効率的な経路を選択すると思います。
空港なのか、鉄道の駅なのか、どちらに近いのかによって、
飛行機で行くのか、新幹線で行くのか、使い分けると思います。
データベースの場合は、ユーザが、データにたどり着くための経路を考えて、
処理を書きます。これが、SQL文です。
データベースのエンジンは、ユーザが書いたSQL文を識別して、より効率的な方法で、データを取得します。
最短経路は、飛行機を使うのか、あるいは新幹線を使うのかみたいな感じでですね。
それは何かのプログラムが決めることであって実際にどういう処理がされるのかデータベースが全部決めています。
どういうふうに決められるかというと、これは、SQL文を開発者が書いて、
データベースの中で文法チェックをします。
SQLとして正しいか間違ってないかっていうのを見ます。
次に、意味チェックをします。
このテーブルは存在するのか、を確認します。
SQLの構文は正しいけれども、テーブルはちゃんと存在するのか、カラムは存在するのかと確認します。
その次が、共有プールチェックというのをします。
何かというと、以前に実行されたことがあるSQLかどうかを確認します。
以前に実行されたころことがあるSQLだったら、
そのバイナリのプログラムが、どういう処理をしたのかを保持しているので、
そのまま、以前実行されたバイナリプログラムが実行されます。
以前実行されてないSQL、初めて実行される場合は、
バイナリプログラムを作成しなければいけないので、処理内容を最適化して、
実行計画複数作成して、どの実行計画を選択するのかを決めて、処理を実行します。
つまりSQLは、そのまま実行されるのではなく、
データベースが、最適な実行計画を最終的に作成して、その実行計画に沿って実行します。
データベースは一番適切で、一番高速な実行計画を最終的に作成して実行するようになっています
ソフトパースとハードパースという概念があります。
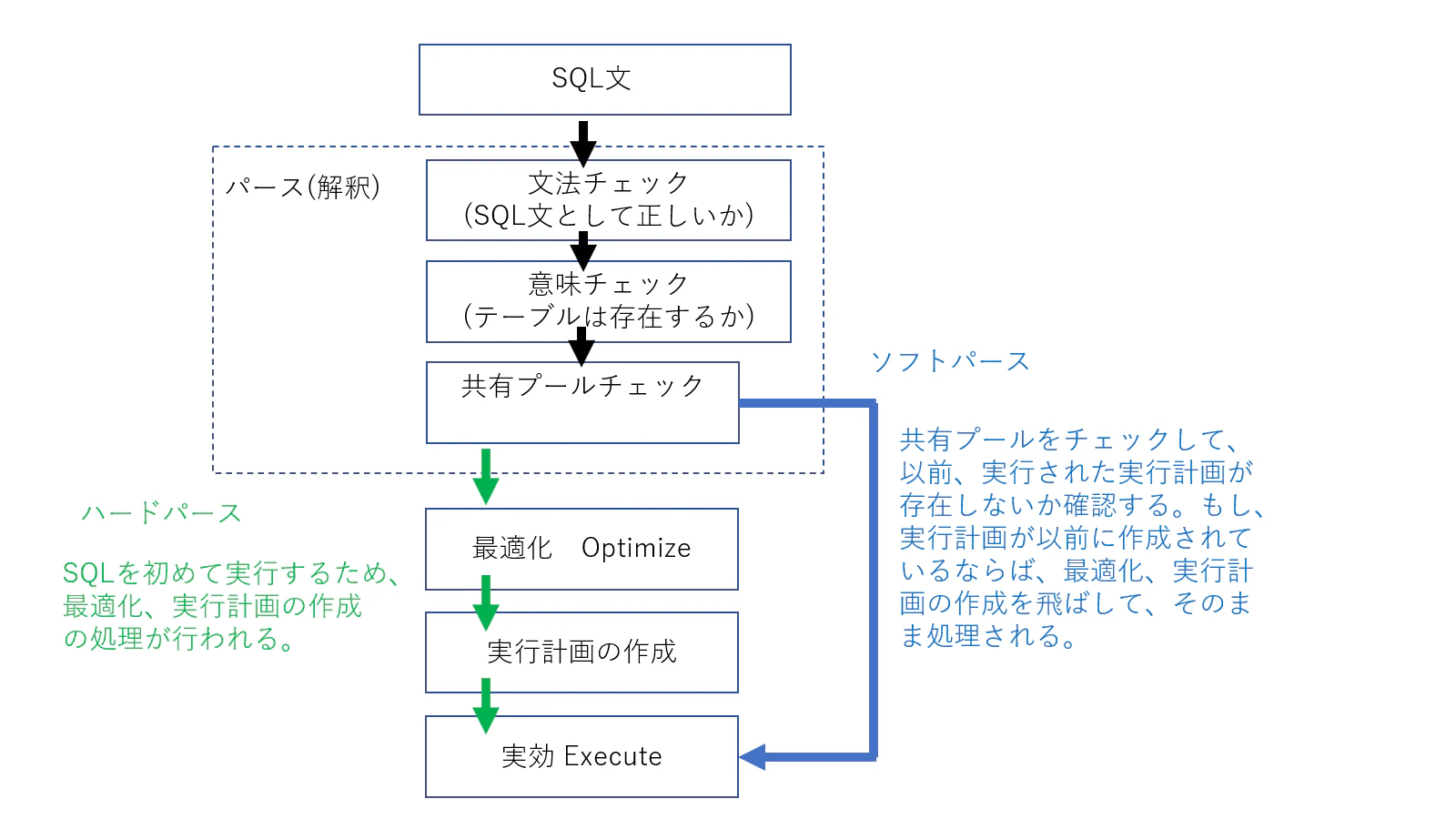
ソフトパースは、パースの際に、共有プールをチェックして、
共有プールに以前実行された実行計画ある場合は、その実行計画を使って実行します。
ハードパースは、初めて実行する場合の処理です。
この場合、実行計画作成する分、時間がかかります。
作成する分だけ最適化作成の処理が走るので時間がかかります
よって、ソフトパースの方が処理速度は速いです。
複雑なSQLになればなるほど、ちょっとした実行計画の時間に違いが出てきます。
多少なので、0. 2ミリ秒とか、それぐらいです。
最初に、データベースを立ち上げた時、ハードパースは、必ず起こります。
ただ、意識すべきなのは、意図しないハードパースを避けることです。
意図しないハードパースを避ける方法を確認して行きたいと思います。
例えば次のようなSQLを考えてみましょう。
SELECT * FROM users WHERE name = "kimura"
SELECT * FROM users WHERE name = "kimunii"
データベースを立ち上げて初めての実行では、同じSQLとして認識されません。
二つ書いてあり、似たようなSQLなんですが、
この絞り込み条件が違うので、同じSQLという認識がされず、
それぞれ、ハードパースされてしまいます。
それぞれ実行計画が新たに作成され、それに基づいて実行され、その時間がかかります。
これを避けるにはどうするかというと、
バインド変数「SET @=""」を使います。
使用例
◇SQL1
SET @name="kimura"
SELECT * FROM users WHERE name = @name;
◇SQL2
SET @name="kimunii"
SELECT * FROM users WHERE name = @name;
@で変数化して、実行すると、これは全て◇SQL1も◇SQL2も同じSQLとして認識されるので、
◇SQL1でハードパースされますが、
◇SQL2では、同じ◇SQL2としてソフトパースされて、既にある実行計画が実行されて、処理が早くなります。
変数化が推奨されます。
基本的に、アプリケーションのORマッパーのメソッドを使うと、自動的にバインド変数が活用されます。
よっぽど下手な書き方しなければ、バインド変数が活用されるので、あまり意識しなくてもいいはずなんですが、
ただアプリケーションからSQLを直書きして実行したりすると、バインド変数を使わずに実行されるので、
ハードパースが発生することもありえますので、注意が必要です。
【ORマッパーとは】
アプリケーションとデータベースの橋渡しをする機能。
SQLを書かずに、プログラムでデータベースの操作を行うもの。
例
SQL ALchemy(python)
ActiveRecord(ruby)
もう少し、バインド変数の使い方を見ていきましょう。
◇SQL3
SELECT * FROM customers WHERE id = 1;
◇SQL4
SELECT * FROM customers WHERE id = 3;
◇SQL3と◇SQL4は、違うSQLとして認識されてしまうんです。
毎回、実行結果が新たに作成されて、処理が遅くなってしまうことがあります。
将来は、データベースの方で改善されるかもしれませんが、
古いデータベースだと処理が遅くなる事がありえます。
そのため、こういう変数的な箇所には、バインド変数を用います。
豆知識ですが、
例えば、イコールの部分ですが、スペース空けたり開けてなかったりして、
MySQL5.6やMySQL8.0は、どちらでも実行できるんですが、
MySQL5.7だと、同じSQLと認識されないことになってしまうようなので、
常に、同じSQLとして認識されるようにするには、バインド変数を使います。
【スペースなし】
SELECT * FROM customers WHERE id=1;
【スペースあり】
SELECT * FROM customers WHERE id = 1;
では、バインド変数の使い方を見ていきましょう。
どうするかというと
--バインド変数
SET @customer_id=5;
SELECT * FROM customers WHERE id = @customer_id;
SET@で、カスタマイズすると、バインド変数を利用することができます
@customer_id=5;
としてですね、これをcustomer_id、とするとバインド変数を使って、IDが5の人を取り出せます
SET @customer_id=6;
として実行すると、id=6;の人で取り出すことができます
このようにする事で、毎回同じSQLの構文にする事が出来ます。
データベースも同じ構文として認識してくれるので、
毎回、実行計画を作り直す必要がなく、処理速度も、向上することができます。
こうする事で、実効計画作成分の処理速度が速くなります。
意図しないハードパースを避ける事が出来ます。
意図しないハードパースを避ける方法が、確認出来ましたので、
視点を変えて、WEBサーバとDBサーバの効率の良い処理について、考えてみたいと思います。
ユーザが、WEBサーバにアクセスした後、
WEBサーバは、DBサーバとやり取りして、DBサーバから必要な情報を抽出し、
ユーザに処理結果を返します。
その際、アプリケーションでは、SQLの実行毎に、
アプリケーションサーバとデータベースサーバ間で、通信が発生し、その分の時間が必要です。
このサーバ間のやり取りは、何度も繰り返し行うよりも、少ない回数で済ませた方が、効率よく処理出来るという事になります。
具体的には、
SELECT の実行回数を減らすというものがあります。
WEHREで、毎回、絞り込むのではなく、INで一回で済ませる方が効率が良いです。
【✖】同じSQLを複数回実行する。
SELECT * FROM customer WHERE id = 100;
SELECT * FROM customer WHERE id = 200;
SELECT * FROM customer WHERE id = 300;
【〇】同じSQLを複数回実行する。
SELECT * FROM customer WHERE id IN(100,200,300);
こうすると、実行されるSQLの回数を減らす事ができ、
アプリケーションサーバとデータベースサーバ間で、通信が発生する回数を減らす事が出来ます。
【実行されるSQLの回数を減らす必要性】が、わかりますね。
また、マルチインサートの実装というのも、あります。
INSERTの実行回数を減らす。というものです。
【✖】3回INSERTの処理を行う。
INSERT INTO projects(name,start_date,end_date) VALUES ('Marketing','2022-11-01','2022-12-31');
INSERT INTO projects(name,start_date,end_date) VALUES ('Sales','2022-10-01','2022-11-30');
INSERT INTO projects(name,start_date,end_date) VALUES ('Management','2022-10-01','2022-12-31');
【〇】1回のINSERTで、3つのレコードを追加する。
INSERT INTO projects(name,start_date,end_date)
VALUES
('Marketing','2022-11-01','2022-12-31'),
('Sales','2022-10-01','2022-11-30'),
('Management','2022-10-01','2022-12-31');
すっきりして、美しいですね。
SQLの実行順序は、次のようなものです。この処理の中の、実行計画が、早くなるわけですね。
1.FROM,JOIN
2.WHERE
3.GROUP BY
4.集計関数(SUMなど)
5.HAVING
6.ウィンドウ関数
7.SELECT(レコード取得)
8.DISTINCT
9.UNION/INSERT/EXCEPT
10.ORDER BY
11.OFFSET
12.LIMIT
現在は、コストベースオプティマイザーが、ほとんどのデータベースでは用いられてます。
対象となる統計情報として、カラム、データタイプ、データ量、レコード件数、
テーブルに存在するインデックス制約、カーディナリティ(値にどれだけばらつきがあるか)なんかがあります。
統計情報を用いて、オプティマイザーが最終的な実行計画を決定します。
統計情報は、最新な状態で、確保しておく必要があります。
つまり古い統計情報、間違った形でテーブルを認識してしまって、
その結果作成される実行計画が出て、悪い実行結果になってしまう可能性があるので、
統計情報は、最新の状態にしておく必要があります。
効率的な処理方法を作成するには最新の統計情報が必要になります。
コストベースOptimizerでは、インデックスやデータ量などの情報をもとに、
複数の実行計画のコスト(効率)を計算して、
最もコストが低い実行計画を実行するそういった機能をもっています。
Optimizerで、データベースを最適化します。
SQLから最も効率的な処理の実行計画を作成します。
Optimizerが、統計情報を活用し、実行計画を作成します。
どのテーブルにどれぐらいデータが入っているのか、どういうインデックスを持っているのか、
SQLを比較して、どういうふうに処理すれば一番効率がいいのか、計算して、実行計画を作成します。
テーブル統計情報一覧を確認するには、「mysql.innodb_table_staus」を参照します。
n_rowsを見て、何件入っているかが確認出来ます。
つまり、テーブルに、どれくらいの件数が入っているか確認出来ます。
SELECT
*
FROM
mysql.innodb_table_staus;
database_name|table_name |last_update |n_rows |clustered_index_size|sum_of_other_index_sizes|
-------------+--------------------------------------+-------------------+-------+--------------------+------------------------+
data_db |classes |2022-12-17 20:47:10| 10| 1| 0|
data_db |customers |2022-12-17 20:47:22| 20| 1| 0|
data_db |departments |2022-12-17 20:47:31| 20| 1| 0|
data_db |employees |2022-12-17 20:47:46| 100| 1| 0|
data_db |enrollments |2022-12-17 20:47:57| 20| 1| 0|
data_db |items |2022-12-17 20:48:08| 80| 1| 0|
data_db |orders |2022-12-17 20:48:21| 100| 1| 0|
data_db |salaries |2022-12-17 20:48:34| 80| 1| 0|
data_db |stats |2022-12-17 20:48:45| 49| 1| 0|
インデックス統計情報の一覧を確認するコマンド
SELECT * FROM mysql.innodb_index_staus;
database_name|table_name |index_name|last_update |stat_name |stat_value|sample_size|stat_description
-------------+--------------------------------------+----------+-------------------+------------+----------+-----------+--------------------------
my_db |people |PRIMARY |2022-12-18 07:19:34|n_diff_pfx01| 2| 1|id |
my_db |people |PRIMARY |2022-12-18 07:19:34|n_leaf_pages| 1| |Number of leaf pages in the index|
my_db |people |PRIMARY |2022-12-18 07:19:34|size | 1| |Number of pages in the index |
mysql |component |PRIMARY |2022-12-17 10:15:02|n_diff_pfx01| 0| 1|component_id |
mysql |component |PRIMARY |2022-12-17 10:15:02|n_leaf_pages| 1| |Number of leaf pages in the index|
mysql |component |PRIMARY |2022-12-17 10:15:02|size | 1| |Number of pages in the index |
sys |sys_config |PRIMARY |2022-12-17 10:15:04|n_diff_pfx01| 6| 1|variable |
sys |sys_config |PRIMARY |2022-12-17 10:15:04|n_leaf_pages| 1| |Number of leaf pages in the index|
sys |sys_config |PRIMARY |2022-12-17 10:15:04|size | 1| |Number of pages in the index |
統計情報を集める方法ですが、基本的には自動的に収集されるのであまり意識することはないです。
ただ、急激にデータを増やすこととかもありますので、急なテーブルのデータ量増加があった場合、
手動で統計情報を更新する必要性が出てきます。
テーブルの統計情報は、自動的に収集されるが、コマンドを用いて、手動で収集する事も出来ます。
急なテーブルのデータ量の増加があった場合は、手動で統計情報を更新すれば、大丈夫です。
ただ、お作法があります。マニュアルに次のような記載があります。
innodb_stats_auto_recalc が無効になっている場合は、インデックス付きカラムへの大幅な変更を行なったあと、該当する各テーブルに対して ANALYZE TABLE ステートメントを発行することによってオプティマイザ統計の精度を確保してください。
https://dev.mysql.com/doc/refman/5.6/ja/innodb-persistent-stats.html
そのため、Auroraのパラメータ値を変更します。★やり方は、後述します。
統計情報を収集するコマンドには、次のようなものがあります。
ANALYZE TABLE テーブル名;
結果
+------------------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+------------------------+---------+----------+----------+
| データベース名.テーブル名 | analyze | status | OK |
+------------------------+---------+----------+----------+
1 row in set (0.02 sec)
ANALYZE実行しますと、テーブルごとに統計情報を収集出来ます。
ただ、これをやる前に、しなければならないことがあります。
パラメータの設定を編集し、一旦、
★innodb_stats_auto_recalcをOFF「0」にします。

OFFにした後、「ANALYZE TABLE テーブル名;」のコマンドを走らせます。
さて、処理が終わったら、パラメータ値をもとに戻します。「1」にします。
★innodb_stats_auto_recalcをON「1」にします。
手動で統計情報を更新したら、実行計画を確認し、どれくらい良くなったか、確認してみましょう。
では、具体的に、どのように確認するのか、を見て行きたいと思います。
まず、実行計画を確認するコマンドを見ていきましょう。
EXPLAIN SQL文あるいはEXPLAIN ANALYZE SQL文でSQLすると実行計画を確認できます。
①EXPLAIN SELECT SQLを実行せずに実行計画だけ表示
EXPLAIN SELECT * FROM customers;
id|select_type|table |partitions|type|possible_keys|key|key_len|ref|rows|filtered|Extra|
--+-----------+---------+----------+----+-------------+---+-------+---+----+--------+-----+
1|SIMPLE |customers| |ALL | | | | | 20| 100.0| |
1 row(s) fetched.
②EXPLAIN ANALYZE SELECT SQLを実行して、実行計画を表示
EXPLAIN ANALYZE SELECT * FROM customers;
EXPLAIN |
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-> Limit: 200 row(s) (cost=3.00 rows=20) (actual time=1.000..1.015 rows=20 loops=1)¶ -> Table scan on customers (cost=3.00 rows=20) (actual time=0.998..1.011 rows=20 loops=1)¶|
1 row(s) fetched.
actual time=0.998..1.011
一行あたり、0.998ミリ秒
全レコード処理に、1.011 秒かかっている。
ANALYZE TABLE テーブル名;
実行後
EXPLAIN |
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-> Limit: 200 row(s) (cost=2.25 rows=20) (actual time=0.036..0.049 rows=20 loops=1)¶ -> Table scan on customers (cost=2.25 rows=20) (actual time=0.035..0.045 rows=20 loops=1)¶|
1 row(s) fetched.
【前】actual time=0.998..1.011
【実行後】actual time=0.035..0.045
一行あたり、0.035ミリ秒、全レコード処理に、1秒かからなくなっている。0.045秒になっている。
統計情報を表示するので、実際の実行時間がわかります。
実行時間は、actual time = に書かれています。
Table scanと書かれてますがこれはフルスキャンと呼ばれていてインデックスを使わずに、
データをテーブルの中の全データを取ってきているというそういった意味です。
①②二つ違いがあってですね、①の方、EXPLAIN SQL文SQLを実行せずに、実行計画だけを表示する
のが、EXPLAIN SQL文です。
②のEXPLAIN ANALYZE SQL文で、SQLを実行して実行時間を含めた実行計画を表示します
Actualレポートも呼ばれてます。
どっちがいいかというと、②の方がいいです
EXPLAIN ANALYZE SQL文の方が、SQLも実行した上でどこをどの部分にどれぐらい時間がかかったかわかるので、
SQLを分析するのに便利なんで、②の方がいいんです。
ただ、処理の重いSQLであるとか、アップデート系のSQLとか、実行したくない場合もあるので、
そういった場合、仕方なく、EXPLAIN SQL文の実行計画だけを用意する場合もあります。
②の方が使いやすいですし、実行計画時間はわかった方がいいです。
EXPLAIN ANALYZE SQL文ですが、
②の形で表示されていて、見るべきところとしてはテーブルです。
出力行のテーブルで、タイプ結合する型です。
あるいは、調査される行の行数の見積もりとか、
フィルターされる行の割合とかがあります。
割合とか見積もりです。EXPLAIN ANALYZE SQL文の実行計画です。
EXPLAIN ANALYZE SQL文を実行すると、どれくらいの行数が取得されるのか、
どれぐらい時間かかったか表示されます。
actual timeは、何秒かかったかです。
rowsは、何件取得できたかって、つまりどの部分でどれくらいの秒数かかっているのかです。
どれぐらい時間がかかってどれくらいの行数が取得されたのか。
どういう処理が用いられてるのかというのがわかります。
Table scanと書いてあるんですけどこれはですね、インデックスを使わずに、
テーブルの中のデータを全部見る処理です。
インデックススキャン、インデックス〇〇と書かれていたら、
大体インデックス使ってます。Table scanすると全レコードを見ている事になります。
フルスキャンとか、あるいはシーケンシャルスキャンと書かれていると、
テーブルの中のデータを全部見てる事になります。
テーブルの中の全データを全部見てると処理が重いのかというと必ずしもそうではなく、
インデックススキャンの方が重いこともありますし、そもそもデータ量が少なければ、
そんなに気にしなくていいという考えもあります。
どういう事かというと、
まず、代表的なテーブルアクセスの方法について見ていきましょう。
フルスキャン、インデックススキャンについて見ていきます。
テーブルフルスキャンは、テーブルから、各行全てを確認してデータを取り出す事です。
大量のデータがテーブルに存在する場合、非常に時間がかかります。
100万件とか1000万とか超えてくるとフルスキャンを行うと、
非常に時間がかかるので、別の方法を考える必要があります。
フルスキャンとインデックススキャンのどちらを使うべきか
・インデックススキャンは、データの一部しか読み込まないため処理時間を短く出来る
・フルスキャンは、データ量が増えれば、処理時間が長くなるが、
インデックススキャンは、データ量が増えても一定のパフォーマンスで処理が出来る
・ただし、絞り込めるデータの割合が、全データ量と比較して少ない
(あまり絞り込めない)場合は、フルスキャンの方が早い事がある
目安としては、絞り込まれる行の全体に占める割合で判断するようです。
20%以上 フルスキャンを用いる
1-20% ケースバイケース
1%未満 インデックススキャンを使う
ここで、クイズです。問題点は、何でしょうか?
SELECT * FROM sales_summary
WHERE YEAR(sales_date) = "2022" AND MONTH(sales_date) = "8"
問題点は、カラムに対して、関数を用いているため、インデックスが利用出来ない事です。
改善策は、関数を使わず、同じ意味の構文を活用する事です。
SELECT *
FROM sales_summary
WHERE
sales_date BETWEEN "2022-08-01" AND "2022-08-31";
エクセルにデータを入れて、ソートすると、ぐるぐる回って、なかなか、保存が出来ない時とかが、
あると思いますが、それは、メモリを消費している証拠です。
エクセルもデータベースみたいなもんで、無駄なソートとかを行うと、
処理に時間がかかります。
このように、データベースのSQLも、無駄にソートをかけると、処理に時間がかかります。
無駄な処理を無くして、効率の良いSQLを実行計画通りに行えば、データベースが最適化出来ているという事になりますね。
SQLチューニングの基本的な方法
1.絞り込まれる行の全体に占める割合を踏まえて、インデックスを活用する
2.無駄な処理を無くす 意味のない並べ替えで、メモリを消費しない。
3.効率の良いSQLの使い方をする。
ご参考ですが、Amazon RDS Proxyを利用すると、次のような事が出来ます。

https://pages.awscloud.com/rs/112-TZM-766/images/EV_amazon-rds-aws-lambda-update_Jul28-2020_RDS_Proxy.pdfより引用
■初期化クエリ。(オプション) 新しい各データベース接続を開くときに実行するプロキシ用の 1 つ以上の SQL ステートメントを指定できます。設定は通常、各接続のタイムゾーンや文字セットなどの設定が同一であることを確認するために、SET ステートメントとともに使用されます。複数のステートメントの場合は、セミコロンをセパレータとして使用します。例えば、1 つの SET ステートメントに SET x=1, y=2 など複数の可変を含めることもできます。PostgreSQL の場合、初期化クエリは現在サポートされていません。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/rds-proxy-setup.htmlより引用
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★
最後に、復習を兼ねて、おさらいしていきましょう。
例えば、stateのテーブルに、
アメリカの州が全部で50個、データが入っているとします。
現在のアメリカの州の数は、50です。
--特定のデータベースの統計情報の確認例
SELECT * FROM mysql.innodb_table_stats WHERE database_name="data_db;
database_name|table_name |last_update |n_rows |clustered_index_size|sum_of_other_index_sizes|
-------------+--------------------------------------+-------------------+-------+--------------------+------------------------+
data_db |customers |2022-12-17 19:25:13| 50000| 2980| 0|
data_db |state |2022-12-17 19:25:13| 50| 1| 0|
data_db |products |2022-12-17 19:26:22|10000| 5863|
SELECT * FROM state;
state_code|name|
---------------+----+
01 |Alabama |
02 |Alaska|
03 |Arizona|
04 |Arkansas |
05 |California|
06 |Colorado |
07 |Connecticut|
08 |Delaware |
09 |Florida |
10 |Georgia|
11 |Hawaii |
12 |Idaho |
13 |Illinois |
14 |Indiana|
15 |Kansas |
16 |Kentucky |
17 |Louisiana |
18 |Maine |
19 |Maryland |
20 |Massachusetts|
21 |Michigan |
22 |Minnesota |
23 |Mississippi |
24 |Missouri|
25 |Montana |
26 |Nebraska|
27 |Nevada |
28 |New Hampshire|
29 |New Jersey |
30 |New Mexico|
31 |New York |
32 |North Carolina |
33 |North Dakota|
34 |Ohio |
35 |Oklahoma |
36 |Oregon|
37 |Pennsylvania |
38 |Rhode Island |
39 |South Carolina |
40 |South Dakota |
41 |Tennessee |
42 |Texas |
43 |Utah |
44 |Vermont |
45 |Virginia |
46 |Washington|
47 |West Virginia |
48 |Wisconsin |
49 |Wyoming |
50 |District of Columbia |
50 row(s) fetched.
そこで、
INSERT INTO state VALUES("51","日本");
とすると、統計情報は、周期的に更新されるんですが、
直ぐに更新されるものではないので、インサートした直後だと、古い情報のままです。
SELECT * FROM state;
state_code|name|
---------------+----+
01 |Alabama |
02 |Alaska|
03 |Arizona|
04 |Arkansas |
05 |California|
・・・・・・・・・・・
45 |Virginia |
46 |Washington|
47 |West Virginia |
48 |Wisconsin |
49 |Wyoming |
50 |District of Columbia |
50 row(s) fetched.
あれ?追加されていないのか??となる。。
そのため、
ANALYZE TABLEを手動で実行します。
そうすると、
SELECT * FROM state;
state_code|name|
---------------+----+
01 |Alabama |
02 |Alaska|
03 |Arizona|
04 |Arkansas |
05 |California|
・・・・・・・・・・・
45 |Virginia |
46 |Washington|
47 |West Virginia |
48 |Wisconsin |
49 |Wyoming |
50 |District of Columbia |
51 |日本 |
51 row(s) fetched.
となります。
さらに、削除してみます。
DELETE FROM state WHERE states_code = "51" AND name="日本";
で、削除したままだと、統計情報は、まだ、51のままです。
SELECT * FROM state;
state_code|name|
---------------+----+
01 |Alabama |
02 |Alaska|
03 |Arizona|
04 |Arkansas |
05 |California|
・・・・・・・・・・・
45 |Virginia |
46 |Washington|
47 |West Virginia |
48 |Wisconsin |
49 |Wyoming |
50 |District of Columbia |
51 |日本 |
51 row(s) fetched.
新しい情報にするには、どうするかというと、
統計情報の手動更新を行い、ANALYZE TABLEを実行します。
--統計情報の手動更新
ANALYZE TABLE state;
Table |Op |Msg_type|Msg_text|
----------------------+-------+--------+--------+
data_db.state|analyze|status |OK |
を実行すると、テーブルの統計情報を手動更新出来ます。
手動で更新するには、必ずテーブルを使いますので、
急激なデータ量の増加か何かがあった場合は、あえて、手動で更新することがあります
例えばテストの際はですね、一気にデータを増やしたりすることもあるので、
そういった場合、統計情報の更新を実行をしましょう。
統計情報を更新しないと、
誤った実行計画が作成されて実行されてしまうことがありますので、
最新にしておくのがベストです。
SELECT * FROM state;
state_code|name|
---------------+----+
01 |Alabama |
02 |Alaska|
03 |Arizona|
04 |Arkansas |
05 |California|
・・・・・・・・・・・
45 |Virginia |
46 |Washington|
47 |West Virginia |
48 |Wisconsin |
49 |Wyoming |
50 |District of Columbia |
50 row(s) fetched.
確認すると、統計情報が、50になります。
いつの間にか、アメリカに、51番目の新しい州として、「日本」が追加されて、
統計情報を取得して、実行計画を作成してみて、
51の実行計画だと、やっぱり、おかしいだろうという事で、
本来の50州のアメリカの州の統計情報を手動更新して、実行計画を作成するという
のを例にしてみました。ショッキングなので、記憶に残りますね。。
■気づき■
パフォーマンスデータを平時から収集、管理し、有事には即座にそのデータを活用、分析出来るインフラが必要だと思います。
さらに、突発的なパフォーマンス障害を想定してリアルタイムに近いデータ収集、分析を可能にする事が望ましいですよね。
そんな時、使えるのが、AWSでチューニングを支援する便利なサービス
Amazon RDS Performance Insights
Performance Insights の有効化と無効化
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/USER_PerfInsights.Enabling.html
データベース内のパフォーマンスデータを蓄積してボトルネックを特定
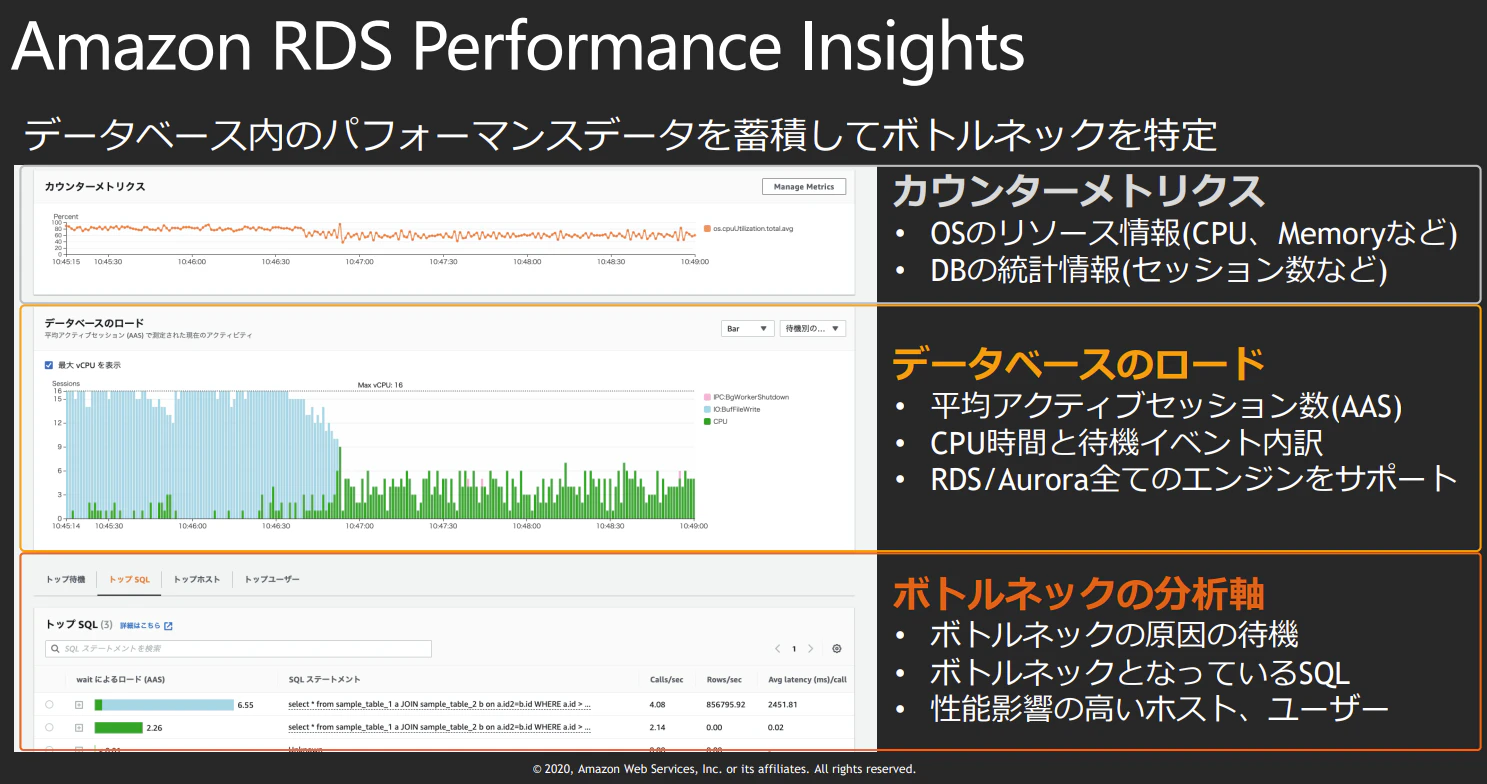
https://pages.awscloud.com/rs/112-TZM-766/images/AAB-01_AWS_Summit_Online_2020_Database.pdfより引用
■気づき■
AuroraとAurora Serverlessは両方とも長短があります。
参考
https://dev.classmethod.jp/articles/aurora-serverless-summary/
■気づき■
実行中のクエリは、show processlistで確認できます。
https://qiita.com/tsurumiii/items/0b70f1a1ee0499be2002
■気づき■
ヒストグラム統計分析
ANALYZE TABLE で HISTOGRAM 句を使用すると、テーブルのカラム値のヒストグラム統計を管理できます。
https://dev.mysql.com/doc/refman/8.0/ja/analyze-table.html
■気づき■
メモリ設定を変更することもできます。例えば、Aurora MySQL と指定すると、innodb_buffer_pool_sizeパラメータのサイズを調整することもできます。このパラメータはデフォルトで物理メモリの 75% に設定されています。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/CHAP_Troubleshooting.html
■気づき■
永続的オプティマイザ統計のパラメータの構成 innodb_stats_persistent=ON
デフォルトで有効になっている innodb_stats_auto_recalc 変数は、テーブルが 10% を超える行に変更された場合に統計を自動的に計算するかどうかを制御します。
https://docs.oracle.com/cd/E17952_01/mysql-8.0-ja/innodb-persistent-stats.html
■気づき■
非永続的オプティマイザ統計のパラメータの構成 innodb_stats_persistent=OFF
オプティマイザ統計は、innodb_stats_persistent=OFF の場合、または個々のテーブルが STATS_PERSISTENT=0 で作成または変更された場合、ディスクに永続化されません。 かわりに、統計はメモリーに格納され、サーバーの停止時に失われます。
https://docs.oracle.com/cd/E17952_01/mysql-8.0-ja/innodb-statistics-estimation.html
■気づき■
ANALYZE TABLE ステートメント
・クエリ オプティマイザーがより適切なクエリ実行プランを見つけるために使用します。
・ヒストグラム統計分析
ANALYZE TABLE で HISTOGRAM 句を使用すると、テーブルのカラム値のヒストグラム統計を管理できます
・histogram_generation_max_mem_size システム変数は、ヒストグラム生成に使用できるメモリーの最大量を制御します。
システム変数で指定されたメモリーサイズに対して、何行のデータが収まるかを計算します。
https://dev.mysql.com/doc/refman/8.0/ja/analyze-table.html
■気づき■
Amazon Aurora MySQL を使用する際のベストプラクティス
①Asynchronous Key Prefetch を使用した Amazon Aurora インデックス付き結合クエリの最適化
Amazon Aurora で AKP を使用すると、インデックス間でテーブルを結合するクエリのパフォーマンスが向上することがあります。この機能は、JOIN クエリで Batched Key Access (BKA) 結合アルゴリズムと Multi-Range Read (MRR) 最適化機能が必要な場合、クエリの実行に必要な行を予測することで、パフォーマンスを向上させます。
②ハッシュ結合を使用した大規模な Aurora MySQL 結合クエリの最適化
等価結合を使用して大量のデータを結合する必要がある場合は、ハッシュ結合によりクエリのパフォーマンスが向上することがあります。Aurora MySQL に対してハッシュ結合を有効にすることができます。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.BestPractices.html