
データの畳み込みnestを上手く利用して見通しよく処理をしよう、という記事を書きました(nestしていこう。)。その中で、大した説明もなしにガンガンmapやmap2を使っていたのでフォローしておきます。
その前に書いた超長文の中の繰り返しに関するパートでもmap2を登場させているので、お前誰だ、というヤツです。
尚、資料としては既に良いものがアレコレあります。
・そろそろ手を出すpurrr
・purrr — ループ処理やapply系関数の決定版
・モダンな繰り返し処理purrrの使い方
これらの記事とかなり重複する内容ですが、フォローアップという意味で一連の資料をまとめておくために、理解に必要な情報にかなり絞ってまとめました。まずこのレベルで手をつけてみて、慣れてきたら色々と広げていくのが良いかと思います。
ライブラリ
面倒なので、まとめてattachしておきましょう。
library(tidyverse)
ベクトルの演算
テストのため、単純な独自関数を定義します。
f <- function(dat){ dat + 1 }
これをベクトルvectorに適用すると、
x <- 1:4
x
# > [1] 1 2 3 4
f(x)
# > [1] 2 3 4 5
こうなります。
ベクトル演算の場合、個々の要素それぞれにfunctionが適用されています。
ベクトルの取り扱いに関する詳しい情報は、biostatisticsさん、R-Tipsさん等をご参照ください。
入力xが、ベクトルを要素に取ったlistだったらどうなるかというと、エラーになります。
x <- list(a = 1:4, b = 3:8)
x
# > $a
# > [1] 1 2 3 4
# >
# > $b
# > [1] 3 4 5 6 7 8
f(x)
# > x + 1 でエラー: 二項演算子の引数が数値ではありません
意図する挙動は、x$aにfを適用し、x$bにもfを適用したい。
forを使う。
for文を使ったループで計算するならこうですね。
results <- NULL
for(i in 1:length(x)){
results[[i]] <- f(x[[i]])
}
results <- set_names(results, names(x))
results
# > $a
# > [1] 2 3 4 5
# >
# > $b
# > [1] 4 5 6 7 8 9
面倒くさいですね。
mapを使う。
こんな時に、mapが便利です。
map(x, f)
# > $a
# > [1] 2 3 4 5
# >
# > $b
# > [1] 4 5 6 7 8 9
狙い通りの結果が得られています。
つまり、入力xの要素(.$a, .$b)ごとに関数fが適用されています。
ヘルプを表示して関数の詳細を確認してみましょう。
?map
| Usage |
|---|
| map(.x, .f, ...) |
| Arguments | |
|---|---|
| .x | A list or atomic vector. |
| .f | A function, formula, or vector (not necessarily atomic). |
| ... | Additional arguments passed on to the mapped function. |
という事で、入力.xはlistかvector、処理に使う関数.fが二番目に来ます。
f <- function(dat){ dat + 1 }
map(.x = x, .f = f) # これを省略してmap(x, f)と書けます。
fをmapの中で無名関数として定義することもできます。
map(x, function(dat){ dat + 1 })
関数名を考える必要がないという利点があります。
難点は、複雑な処理を入れるとフローを追う(読む)のが大変になります。
トレードオフですね。
更に、チルダ~を使ったラムダ式で書くこともできます。
map(x, ~ { . + 1 })
pipe演算子%>%を使うとこうですね。
x %>% map(~ { . + 1 })
こんな事もできます。
x %>% map( ~ { . + 1 } %>% sum)
# > $a
# > [1] 14
# >
# > $b
# > [1] 39
このラムダ式の.は、第一引数を参照しています。.xと書いても良いです。
デフォルトだと返り値はlistですが、wrapper関数を使う事で、出力のデータ型を変える事もできます。よく使う3種類は下記。
x %>% map_df( ~ { . + 1 } %>% sum) # data.frame形式で出力(tibbleですが)
# > # A tibble: 1 x 2
# > a b
# > <dbl> <dbl>
# > 1 14 39
x %>% map_dbl( ~ { . + 1 } %>% sum) # 実数ベクトル形式で出力
# > a b
# > 14 39
x %>% map_chr( ~ { . + 1 } %>% sum) # 文字列ベクトル形式で出力
# > a b
# > "14.000000" "39.000000"
複数の要素を引数にとるなら。
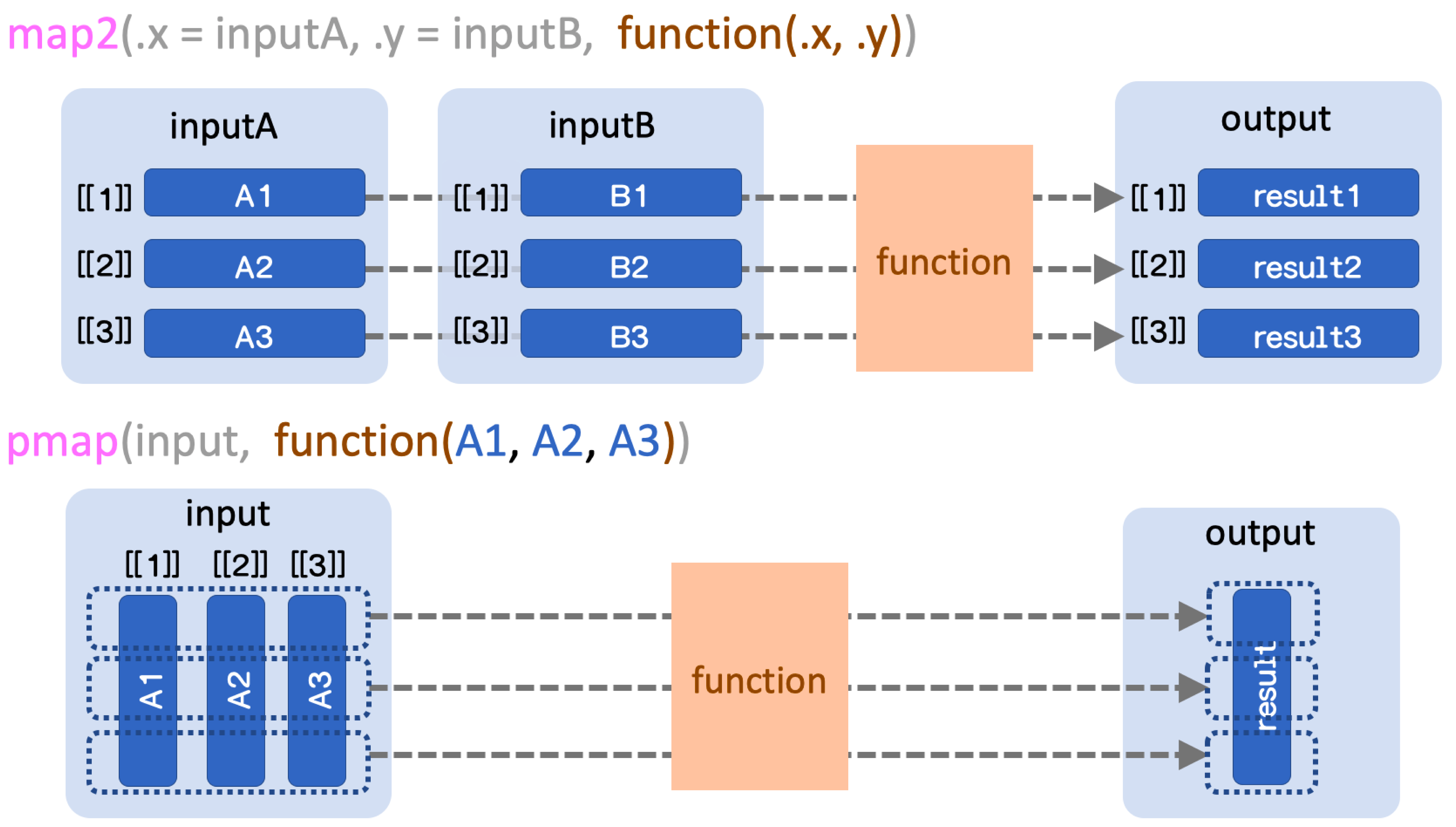
mapは、1つのlistを.xに取って、その要素に対して順に.fを適用するわけですが、適用したい関数によっては2つの引数を取りたい時もありますね。そんな時にはmap2を使います。
x1 <- list(a = 1:6, b = 3:8)
x2 <- list(a = 6:1, b = 10:15)
map2(x1, x2, ~ .x + .y)
# > $a
# > [1] 7 7 7 7 7 7
# >
# > $b
# > [1] 13 15 17 19 21 23
チルダ式の.xは第一引数x1を、.yは第二引数x2をそれぞれ参照します。
3つ以上を参照したい場合は、pmapを使います。要素数は揃っている必要があります。
list(1:5, 3:7, 11:15) %>%
pmap_dbl(function(x, y, z){x + y * z})
# > [1] 34 50 68 88 110
data.frameは名前付きlistで要素数が揃っている事が保証されているので相性が良いです。
data.frame(x = 1:5, y = 3:7, z = 11:15) %>%
pmap_dbl(function(x, y, z){x + y * z})
# > [1] 34 50 68 88 110
デモpmapハチョットツカイニクイ
例えば、これ↓が通らない。
data.frame(x = 1:5, y = 3:7, z = 11:15) %>%
pmap_dbl(function(a, b, c){a + b * c})
# > .f(x = .l[[1L]][[i]], y = .l[[2L]][[i]], z = .l[[3L]][[i]], ...) でエラー:
# > 使われていない引数 (x = .l[[1]][[i]], y = .l[[2]][[i]], z = .l[[3]][[i]])
# コレ↓は通る
list(1:5, 3:7, 11:15) %>%
pmap_dbl(function(a, b, c){a + b * c})
# > [1] 34 50 68 88 110
pmap内部の.fの引数名が、与えられる入力.lのnameと一致している必要があるのです。
また、入力は.lの一つですので、.xや.yといった書き方ができず、チルダを用いたラムダ式が書けない。(引っ張りたい要素の数が分からないので当然といえば当然ですが。)
data.frame(x = 1:5, y = 3:7, z = 11:15) %>%
pmap_dbl(~{.x + .y * .z})
# > .f(x = .l[[1L]][[i]], y = .l[[2L]][[i]], z = .l[[3L]][[i]], ...) でエラー:
# > オブジェクト '.z' がありません
なんともならない。
data.frame(x = 1:5, y = 3:7, z = 11:15) %>%
pmap(~{.$x + .$y * .$z})
# > .$x でエラー: $ operator is invalid for atomic vectors
data.frame(x = 1:5, y = 3:7, z = 11:15) %>%
pmap_dbl(~{.data$x + .data$y * .data$z})
# > エラー: Result 1 must be a single double, not an integer vector of length 0
# > Call `rlang::last_error()` to see a backtrace
どうせpmapを使うような関数は複雑になりそうなので、引数と要素名を合わせた関数を別途定義しておくのが良さそうですね。
f <- function(x, y, z){x + y * z}
data.frame(x = 1:5, y = 3:7, z = 11:15) %>%
pmap_dbl(f)
# > [1] 34 50 68 88 110
data.frameを取り扱う場合、よっぽどの事がなければ素直にmutateで計算してしまうのも手です。
data.frame(x = 1:5, y = 3:7, z = 11:15) %>%
mutate(val = x + y * z)
# > x y z val
# > 1 1 3 11 34
# > 2 2 4 12 50
# > 3 3 5 13 68
# > 4 4 6 14 88
# > 5 5 7 15 110
nested dataの演算に便利。

dat <- iris %>%
group_by(Species) %>%
nest
dat
# > A tibble: 3 x 2
# > Species data
# > <fct> <list>
# > 1 setosa <tibble [50 × 4]>
# > 2 versicolor <tibble [50 × 4]>
# > 3 virginica <tibble [50 × 4]>
nestされているdataカラムは、listになっています。
dat$data
# > [[1]]
# > # A tibble: 50 x 4
# > Sepal.Length Sepal.Width Petal.Length Petal.Width
# > <dbl> <dbl> <dbl> <dbl>
# > 1 5.1 3.5 1.4 0.2
# > 2 4.9 3 1.4 0.2
# > 3 4.7 3.2 1.3 0.2
# > # … with 47 more rows
# >
# > [[2]]
# > # A tibble: 50 x 4
# > Sepal.Length Sepal.Width Petal.Length Petal.Width
# > <dbl> <dbl> <dbl> <dbl>
# > 1 7 3.2 4.7 1.4
# > 2 6.4 3.2 4.5 1.5
# > 3 6.9 3.1 4.9 1.5
# > # … with 47 more rows
# >
# > [[3]]
# > # A tibble: 50 x 4
# > Sepal.Length Sepal.Width Petal.Length Petal.Width
# > <dbl> <dbl> <dbl> <dbl>
# > 1 6.3 3.3 6 2.5
# > 2 5.8 2.7 5.1 1.9
# > 3 7.1 3 5.9 2.1
# > # … with 47 more rows
なので、mapで取り扱うと捗ります。
mutateで新たなカラムを作り、そこにdataの要素をmapの引数に取り、.fを適用した結果を格納します。

dat %>%
mutate(mean = map(data, ~summarise_all(., mean)))
# > # A tibble: 3 x 3
# > Species data mean
# > <fct> <list> <list>
# > 1 setosa <tibble [50 × 4]> <tibble [1 × 4]>
# > 2 versicolor <tibble [50 × 4]> <tibble [1 × 4]>
# > 3 virginica <tibble [50 × 4]> <tibble [1 × 4]>
$meanの中身はこんな感じになります。
[[1]]
# A tibble: 1 x 4
Sepal.Length Sepal.Width Petal.Length Petal.Width
<dbl> <dbl> <dbl> <dbl>
1 5.01 3.43 1.46 0.246
[[2]]
# A tibble: 1 x 4
Sepal.Length Sepal.Width Petal.Length Petal.Width
<dbl> <dbl> <dbl> <dbl>
1 5.94 2.77 4.26 1.33
[[3]]
# A tibble: 1 x 4
Sepal.Length Sepal.Width Petal.Length Petal.Width
<dbl> <dbl> <dbl> <dbl>
1 6.59 2.97 5.55 2.03
冒頭の繰り返しになりますが、nestを使った畳み込みとmap族を使ったデータ処理については、別途、nestしていこう。という記事を書いたので、詳細はそちらをご参照ください。