以前、新人の研修担当をしていた時に、その新人が『社内ドキュメントを検索できるツールあったら便利じゃないか』という提案したことがある。
完成イメージ画像まで作っていて、名前は 『検索君』 だった。
弊社では、一部クラウド化はされているものの、様々な事情で未だ NAS に大量のドキュメントが置かれている。
管理はしっかりされている一方、とにかく量が多く階層も深く、探すのが辛かった。
新人が、しっかりと新人の目でその不満点を見ていた事に感心し、作るのも簡単そうだったのでサクッと作ってみた。
初代 検索君
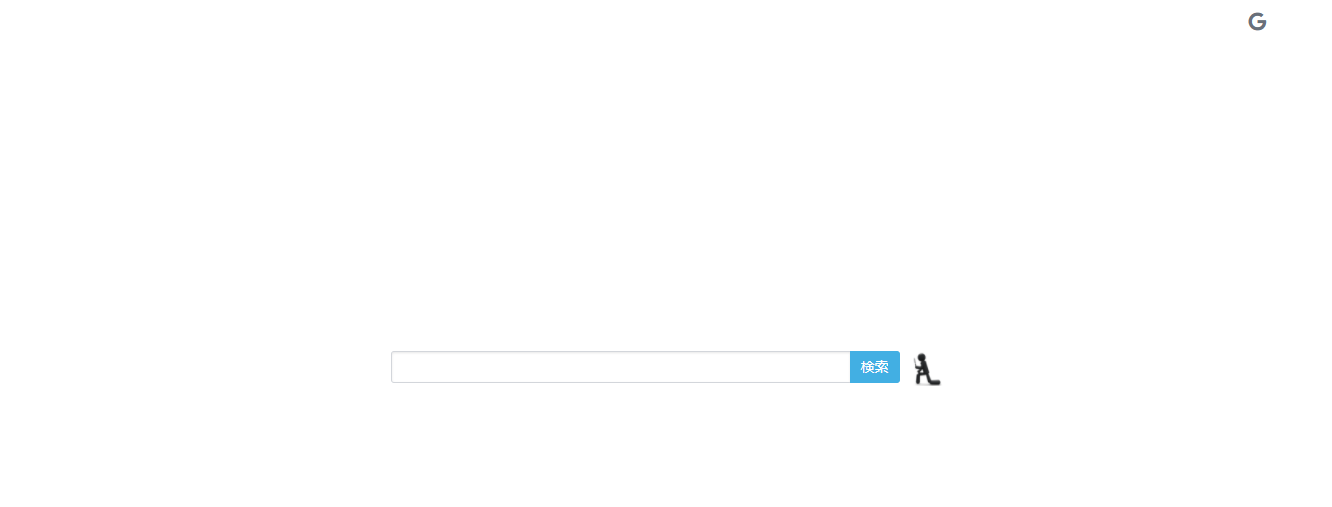
初代検索くんは、数時間で作られてこともあり、便利さは限定的だった。
実行環境
- Ruby
- Sinatra
- groonga
- Frontend
- riot.js
- Bulma.css
できる事
- NAS 内とクラウドストレージのシームレス検索
- NAS
- Google Drive
- 検索エンジンは groonga
- ファイルパスでの部分一致検索
できない事
- コンテンツでの検索
- あいまい検索
- Index は手動で数時間 ~ 数日かかる
-
Find.findで検索が遅かった - 一旦作ると、再 Index 化が面倒でやらなくなる
- 現実と乖離していく Index
-
直したい所
とにかく、現実との乖離 はサービスの価値としては致命的なので、これをまず何とかしたい。
二代目 J Soul 検索君
二代目でやりたい事は、
- MFT による Index の高速化
- 検索エンジンを Elasticsearch に
- Web API を Elixir 化
- Docker 化
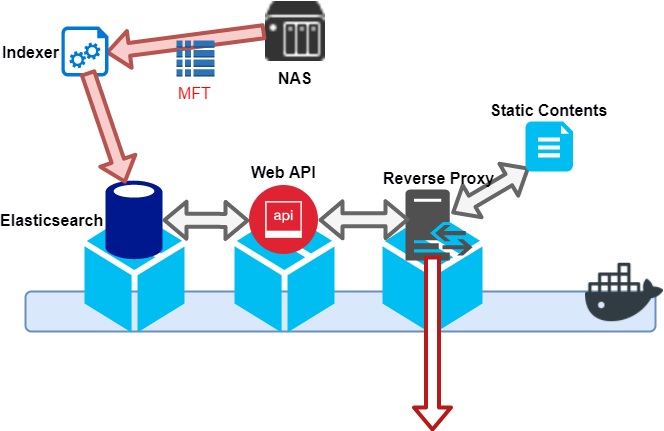
実際のソースコードは全てGithub にある。
github.com/kentork/kensakukun
github.com/kentork/tansakukun
MFT による Index の高速化
NTFS ファイルシステムには、 MFT ( Master File Table ) という全てのファイルエントリを管理する親玉ファイルが存在する。
どうやら、 Everything 等の高速 Index 検索ツールもこれを使って高速化しているらしいと聞き、検索君もこれを使って高速化できないだろうかと挑戦してみた。
以下、参考に
Wikipedia - マスター ファイル テーブル
NTFSの読み方
情報がない
全然無い。
ソースコードはチラチラと見つかるが、古かったりよく分からなかったりと、とにかく無い。
取り敢えず、良さそうなサンプルソースをいくつか読み解きながら、主にこのコードを参考に進めた。
CCS LABS C#: Accessing the Master File Table
● 参考
stackoverflow - How do we access MFT through C#
How to read file attributes using Master File Table data
Get file info from NTFS-MFT reference number
開発
役割としては検索君とは独立しているため、プロジェクトを切りだした。
◆ 開発環境
- Windows 10
- VS Code
- DotNet SDK 2.3.1 ( x86 )
◆ C# プロジェクト作成
C# を書くのは久しぶりなので、まずは C# の環境を作るところから始める。
以下、 scoop は使えるものとして進める
まずは、DotNet SDK を入れる。
PS> scoop install -a x86 dotnet-sdk
※ 今回は、x86向けにビルドする必要があるので、アーキテクチャを指定している。x64 を使っている人は何とか頑張ってください
次に、gh コマンド で Github プロジェクトを作り、C# プロジェクトとして初期化する。
PS> gh create
# create kentork/tansakukun project
PS> gh cd kentork/tansakukun
PS> dotnet new console -o .
├── ./Program.cs
├── ./tansakukun.csproj
└── ./obj
├── ./obj/tansakukun.csproj.nuget.cache
├── ./obj/tansakukun.csproj.nuget.g.props
├── ./obj/tansakukun.csproj.nuget.g.targets
└── ./obj/project.assets.json
◆ サンプル実行
サンプルソース を実行してみたが、以下でエラーが出たので、ちょっと直した。
- [DllImport("kernel32.dll")]
- public static extern void ZeroMemory(IntPtr ptr, Int32 size);
+ [DllImport("Kernel32.dll", EntryPoint = "RtlZeroMemory", SetLastError = false)]
+ public static extern void ZeroMemory(IntPtr ptr, Int32 size);
実行
PS> dotnet restore
PS> dotnet run
これで、一応動いたんだけど、取れるのはファイル名だけだった。
以降、カスタマイズしていく。
◆ フルパス取得
まずは、これをフルパスにする機能を追加した。
public class FileNameAndParentFrn
{
private string _name;
public string Name
{
get { return _name; }
set { _name = value; }
}
private string _path = "";
public string Path
{
get { return _path; }
set { _path = value; }
}
private UInt64 _parentFrn;
public UInt64 ParentFrn
{
get { return _parentFrn; }
set { _parentFrn = value; }
}
public FileNameAndParentFrn(string name, UInt64 parentFrn)
{
if (name != null && name.Length > 0)
{
_name = name;
}
else
{
throw new ArgumentException("Invalid argument: null or Length = zero", "name");
}
if (!(parentFrn < 0))
{
_parentFrn = parentFrn;
}
else
{
throw new ArgumentException("Invalid argument: less than zero", "parentFrn");
}
}
}
...
private void ResolvePath(string drive, ref Dictionary<ulong, FileNameAndParentFrn> files)
{
foreach (KeyValuePair<ulong, FileNameAndParentFrn> entry in files)
{
FileNameAndParentFrn file = (FileNameAndParentFrn)entry.Value;
file.Path = string.Concat(FrnToParentDirectory(drive, file.ParentFrn), Path.DirectorySeparatorChar, file.Name);
}
}
private string FrnToParentDirectory(string drive, ulong frn)
{
if (!_directories.ContainsKey(frn)) return "";
var parent = _directories[frn];
if (parent.ParentFrn == 0) return drive;
if (parent.Path != "") return parent.Path;
parent.Path = string.Concat(FrnToParentDirectory(drive, parent.ParentFrn), Path.DirectorySeparatorChar, parent.Name);
return parent.Path;
}
ファイルをリストしている間に、実はフォルダも全部リストアップしていたのでそれを使った。
やっていることは、親への Reference を辿りながら、パスを結合していくというシンプルなもの。
C# 的に再帰ってどうなの?とは思ったけど、眠くてこれ以外にアルゴリズムが思いつかなかった。
これで、フルパスが取れるようになった。
ローカルマシンで確認した所、『C:』から350万ぐらいのファイルを読み込んで、2分弱 ( CPU Core i5, Mem 16GB )。早い。
◆ 巨大な壁
ここで、試しに社内の NAS に繋いでみようと思ったが、1つ疑問が。
あれ、共有フォルダって Drive Letter 無いよね?
とは言え、ホスト名とか入れれば動くんでしょ、と思ってやってみたが、駄目だった。
ネットワークドライブの割当も駄目。
え、NAS 繋がらないの? 意味ないじゃん!!
しかし、MFT をつかっているであろう高速 Index ツールにも、共有フォルダに対応する物はあるので、できないことは無いのでは、と思っている。
今の所、対策は無い。
[追記]
さっき、出張から戻った同僚に相談したら、なんだかんだで MFT を取るのは難しんじゃないかと言う感じになった。
さて、次の方法を考えないと。。。
検索エンジンを Elasticsearch に
次に、検索エンジンを groonga から Elasticsearch に変更。
安定感、アクセスのしやすさ、情報の多さ、これまでの経験を含めて、Elasticsearch がベストと判断。
開発
Elasticsearch は Docker として立ち上げる。
これは、検索君のプロジェクトで管理している。
version: '3'
services:
es:
container_name: es
image: docker.elastic.co/elasticsearch/elasticsearch:6.1.1
ports:
- "9200:9200"
volumes:
- es_data:/usr/share/elasticsearch/data
environment:
- ELASTIC_PASSWORD=MagicWord
- ES_JAVA_OPTS=-Xms512m -Xmx512m
- transport.host=0.0.0.0
- bootstrap.memory_lock=true
- discovery.type=single-node
# - cluster.name=full-house
# - node.name=Jesse
ulimits:
memlock:
soft: -1
hard: -1
networks:
- default
...
volumes:
es_data:
driver: 'local'
Elasticsearch のイメージは、library/elasticsearch ではなく docker.elastic.co/elasticsearch/elasticsearch が公式サポート版。
今の所、クラスタを組む気は無いため、single-node で動作している。
◆ Elasticsearch に Bulk Insert
上記で Elasticsearch を立ち上げたら、まずは tansakukun の方から入れ込む。
C# から Elasticsearch を操作をする場合、以下クライアントが公式にサポートされている。
-
NEST
- Higl Level Client と呼ばれている
- LINQ っぽい Query DSL で操作可能
- NEST - High level client
-
Elasticsearch.Net
- Low Level Client と呼ばれている
- Elasticsearch.Net - Low level client
Bulk API が提供されているのは Elasticsearch.Net だけ なので、コッチを使う。
public class BulkInsert
{
public static void execute(string host, int port, Dictionary<ulong, FileNameAndParentFrn> files, int chunkSize = 10000)
{
var settings = new ConnectionConfiguration(new Uri("http://" + host + ":" + port))
.RequestTimeout(TimeSpan.FromMinutes(2));
var lowlevelClient = new ElasticLowLevelClient(settings);
var index = DateTime.Now.ToString("yyyyMMddHHmmss");
var type = "pathes";
long id = 1;
foreach (var chank in files.Values.Chunks(chunkSize))
{
var json = new List<object>();
foreach (var file in chank)
{
json.Add(new Index(id, index, type));
json.Add(new FileEntry(file.Path, ""));
id++;
}
var indexResponse = lowlevelClient.Bulk<StreamResponse>(PostData.MultiJson(json));
using (var responseStream = indexResponse.Body)
{
Console.Write(".");
}
}
Console.WriteLine("");
}
}
// from https://webbibouroku.com/Blog/Article/chunk-linq
public static class Extensions
{
public static IEnumerable<IEnumerable<T>> Chunks<T>(this IEnumerable<T> list, int size)
{
while (list.Any())
{
yield return list.Take(size);
list = list.Skip(size);
}
}
}
public class Index
{
public Metadata index { get; set; }
public Index(long id, string _index, string type)
{
index = new Metadata(_index, type, id.ToString());
}
public class Metadata
{
public Metadata(string index, string type, string id)
{
_index = index;
_type = type;
_id = id;
}
public string _index { get; set; }
public string _type { get; set; }
public string _id { get; set; }
}
}
public class FileEntry
{
public string path { get; set; }
public string date { get; set; }
public FileEntry(string path, string date)
{
this.path = path;
this.date = date;
}
}
ポイントとしては、
- 起動時間毎に新しい Index をつくる
- Index のオブジェクトと Data のオブジェクトを交互に渡すと、勝手に Serialize してくれる
- 10000 ファイルずつチャンクして Bulk
10000 ファイルでチャンクしたのは、HTTPリクエストと大量データ送信の程よい均衡点を探しての事。
設定ファイルで変更可能であり、現在は 2~50000 ファイルあたりでもパフォーマンス調査しているが、失敗もなく時間増加も線形的なので、もっと増やしてみたい。
先程の350万レコードを挿入して、大体 15 分程度だった。まぁまぁ早い。
※ 後で気付いたけど、Elasticsearch に日本語検索のプラグイン入れてなかった。パフォーマンス確実に変わるので、上記は参考程度に。
Web サーバを Elixir 化
これは、以前の Ruby + Sinatra のままでも良かったのだが、クエリ検索の機能があまり優秀ではなかったりして、もう少し本格的にしていきたいなぁと。
で、そうなると Ruby + Sinatra だと少し不安だなぁ。ということで、 Elixir にした。
速度や安定感もさることながら、データ加工 が素晴らしい。
◆ Elixir
パイプラインやパターンマッチ等で流れるようにデータが加工できるのがとても良く、データを少し加工して返すシンプルな API サーバとしてとても優秀だと実感した。
以下の資料に、その素晴らしさがまとめられている。
辛かったのは、まとまった良い情報が Web 上にあまり無いこと。
同時期に Rust も書いていたが、あっちは公式も充実していたし記事も多かった。
仕方なく、昔買った プログラミングElixir を見ながら頑張った。
開発
メインプロジェクトとして、Elasticsearch 等クラスタ管理も仕切る。
◆ 開発環境
- Windows 10
- VS Code
- Erlang OTP 20
- Elixir 1.6.0-dev
◆ Elixir プロジェクト作成
Elixir を書くのも久しぶりなので、まずは Elixir の環境を作るところから始める。
以下、 scoop は使えるものとして進める
本来は、Docker で動かしたかったが、変更監視 → Recompile の手法が見つけられなかったので、今回はローカルでの動作を前提とする。
PS> scoop install elixir
次に、gh コマンド で Github プロジェクトを作り、Elixir プロジェクトとして初期化する。
PS> gh create
# create kentork/kensakukun project
PS> gh cd kentork/kensakukun
PS> cd ..
PS> mix new kensakukun
# The directory "hoge" already exists. Are you sure you want to continue? [Yn] y
├── ./LICENSE.txt
├── ./README.md
├── ./config
│ └── ./config/config.exs
├── ./lib
│ └── ./lib/kensakukun.ex
├── ./mix.exs
└── ./test
├── ./test/kensakukun_test.exs
└── ./test/test_helper.exs
◆ 依存パッケージを追加
今回は、Phoenix 等のフルスタックフレームワークは要らないので、シンプルに plug だけの web サーバを考える。
...
defp deps do
[
{:cowboy, "~> 1.1"},
{:plug, "~> 1.5.0-rc.0"},
{:poison, "~> 3.1.0"},
{:httpotion, "~> 3.0.3"}
]
end
...
Webサーバは cowboy で、Rack 的な Web インターフェイスに plug。
JSON パーサとして poison を利用。
Elasticsearch へのクエリは、クライアントを使わずに httpotion でリクエストする。
◆ Application
defmodule Kensakukun do
use Application
require Logger
def start(_type, _args) do
children = [
Plug.Adapters.Cowboy.child_spec(:http, Kensakukun.Plug.Router, [], port: 8080)
]
Logger.info("Started application")
Supervisor.start_link(children, strategy: :one_for_one)
end
end
◆ Routing
defmodule Kensakukun.Plug.Router do
use Plug.Router
require Logger
if Mix.env() == :dev do
use Plug.Debugger
end
plug(Plug.Logger)
plug(Plug.Parsers, parsers: [:json], json_decoder: Poison)
plug(:match)
plug(:dispatch)
get "/api/oauth/google/client_id" do
client_id = Application.fetch_env!(:kensakukun, :api_token)
resp(conn, 200, client_id)
end
get "/api/search" do
index =
Kensakukun.Elasticsearch.get_indices()
|> Enum.max_by(&Integer.parse(&1["index"]))
result = Kensakukun.Elasticsearch.search_path(index["index"], conn.params["query"])
pathes =
Poison.encode(result)
|> (fn {:ok, result} -> result end).()
resp(conn, 200, pathes)
end
match _ do
resp(conn, 404, "Not Found")
end
end
クライアントで使う Google API 用の Client ID は、クライアントに埋め込見たくない。
ので、エンドポイントを 1つ設けてある。
◆ Elasticsearch の操作
これは、通常の HTTP を用いる普通のやり方。特に無し。
350 万件から部分一致件検索で 1000件取得して 150 ms 前後。
以前に比べて数倍~数十倍早いんじゃなかろうか。
インクリメンタル検索も夢じゃない?

※ 後で気付いたけど、Elasticsearch に日本語検索のプラグイン入れてなかった。パフォーマンス変わるので参考程度に。
◆ Docker 化
本番 ( と言っても社内だが ) に向けて、Docker 化はしておきたい。
公式のパッケージが Hex や Rebar を含んでおらず、入れていないと毎度聞かれるのが面倒なので、あらかじめ入れたイメージを作っておく。
FROM elixir:1.5.3-alpine
RUN mix local.hex --force && mix local.rebar --force
サービス定義はこんな感じ
...
api-init:
container_name: api-init
build: .
volumes:
- ./:/usr/src/app
- elixir_cache:/usr/src/app/deps
working_dir: /usr/src/app
entrypoint: sh -c "mix deps.get && mix compile"
networks:
- default
api:
container_name: api
build: .
ports:
- "8080:8080"
environment:
- MIX_ENV=prod
- ES_HOST=es
- ES_PORT=9200
env_file: .env
volumes:
- ./:/usr/src/app
- elixir_cache:/usr/src/app/deps
working_dir: /usr/src/app
entrypoint: mix run --no-halt
networks:
- default
...
渡した環境変数は、config/prod.exs で参照している。
API_TOKEN だけは、便宜上 .env から取得している。
use Mix.Config
config :kensakukun,
es_host: System.get_env("ES_HOST"),
es_port: System.get_env("ES_PORT"),
api_token: System.get_env("API_TOKEN")
動かす時は、一度初期化が必要。
docker-compose run --rm api-init
docker-compose up -d api
フロントエンド
- Riot.js v3.7.4
- Bulma.css v0.6.1
ここは、ほぼ初代からの流用である。バージョンだけ上げている。
やはり、Riotjs + Bulma.css の組み合わせは、ぱっと作るのに向いている。
配信は、Caddy が担当している。
...
web:
container_name: web
image: abiosoft/caddy:latest
ports:
- "443:2015"
volumes:
- ./Site/Caddyfile:/etc/Caddyfile
- ./Site/public:/srv
networks:
- default
...
Site
├── Caddyfile
└── public
├── 404.html
├── component
│ └── app.tag
├── css
│ ├── bulma.min.css
│ └── font-awesome.min.css
├── favicons
│ ├── android-icon-144x144.png
│ ├── ...
│ └── ms-icon-70x70.png
├── fonts
│ ├── FontAwesome.otf
│ ├── ...
│ └── fontawesome-webfont.woff2
├── images
│ ├── drive.png
│ ├── folder.png
│ └── kensaku.png
├── index.html
└── js
├── clipboard.min.js
└── riot+compiler.min.js
0.0.0.0 {
root /srv
gzip
tls self_signed
index index.html
errors {
404 404.html
}
proxy /api http://api:8080/ {
transparent
}
}
これだけで、 HTTPS + HTTP2 (+ quic) + Reverse Proxy。素晴らしい。
Docker 化
ここまでで Docker 化終わってるので。
現在、ローカルでは一応動いている。
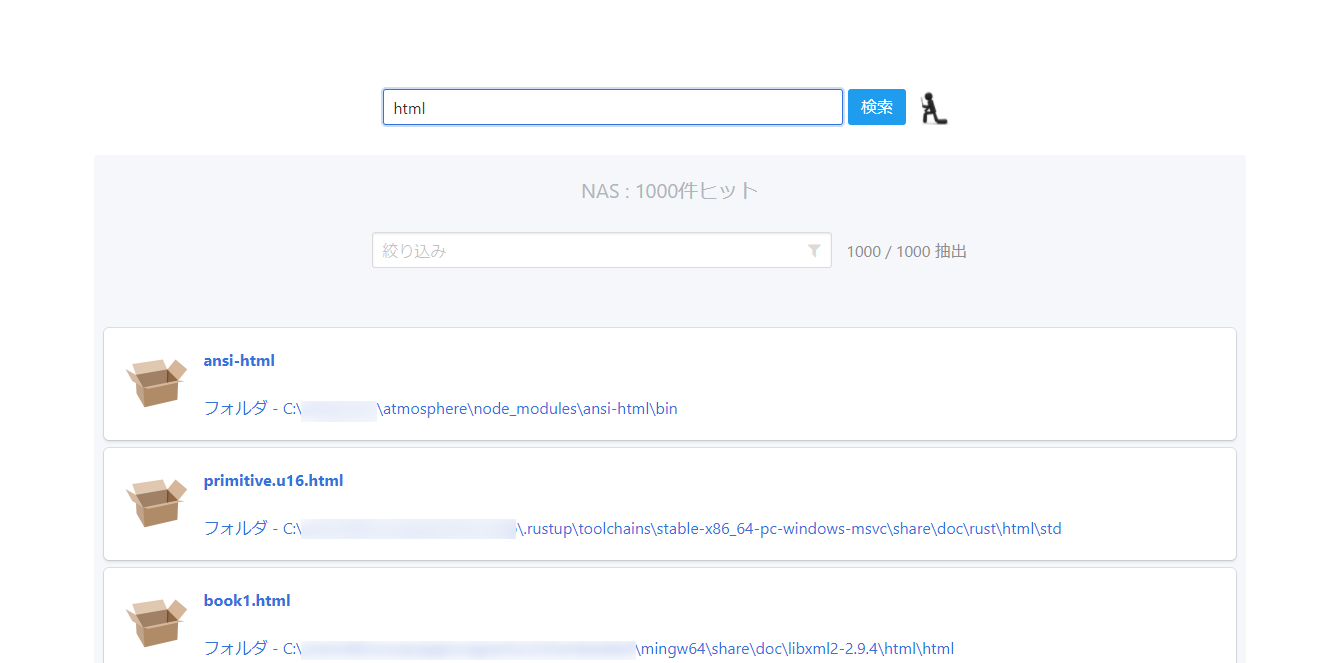
まとめ
検索は確実に早くなるでしょう。
しかし、Index 化が早くならなくては余り意味がない。
最新の情報があるという保証がなければ、サービスの価値は低い。
少なくとも、1日1回は走らせたい。その為には、せいぜい 30分~1時間以内 は欲しい。
とにかく、ネットワークの向こうの NAS をいかに高速に Index するか考えなくては。
MFT が取れるのか、それとも取れないのか。
MFT から取らないのなら、他に方法は無いのか。