- 間違えて5GBくらいのファイルを
Shift + Deleteしてしまった - Pandora Recoveryなどの復元ソフトを使えば簡単に元に戻せるだろう
- なぜかサイズが0KBになってしまう
- どうせ32bit変数を使っているとかで、自分でNTFSを読めば復元できるだろう
ということで、NTFSの読み方を調べた。
結論を先に書くと、消したファイルのサイズが4GB以上の場合、4GB未満のファイルのように簡単に元に戻すことはできない(詳細は後述)。4GB以上のファイルは慎重に扱おう。
参考にしたサイト
- http://www.writeblocked.org/resources/ntfs_cheat_sheets.pdf
- https://flatcap.org/linux-ntfs/ntfs/
- http://www.kes.talktalk.net/ntfs/
- http://blogs.technet.com/b/askcore/archive/2009/10/16/the-four-stages-of-ntfs-file-growth.aspx
公式な仕様書は非公開。
試しに実装したプログラムはGitHubに置いてある。
https://github.com/kusano/ntfsdump
ボリュームの開き方
MSDNに書いてあるように、例えばドライブレターがCの場合は、\\.\C: を開けば良い。
HANDLE h = CreateFile(
_T("\\\\.\\C:"),
GENERIC_READ,
FILE_SHARE_READ | FILE_SHARE_WRITE,
NULL,
OPEN_EXISTING,
0,
NULL);
USB外付けドライブは管理者権限無しで開けたけど、内蔵ドライブは管理者権限が必要だった。
Pythonなどのスクリプト言語でも同じように開けるけど、内部的なフラグなどがどうなっているのか分からなくて、ちょっと怖い。
>>> open(r"\\.\Q:", "rb").read(16)
'\xebR\x90NTFS \x00\x02\x08\x00\x00'
MSDNには
FILE_FLAG_NO_BUFFERING フラグを指定せずにディスクデバイスを開いた場合でも、すべての I/O バッファをセクタ整列させる(メモリ内のアドレスを、ボリュームのセクタサイズの整数倍の位置に整列させる)べきです。ディスクにもよりますが、この要件が自動的に適用されないこともあります。
との記載があるけど、メモリアドレスは境界整列されていなくても動いた。ただ、読み込みのサイズがセクタサイズの整数倍でないとエラーになった。
基本
クラスタ、セクタ、$MFT
ファイルはクラスタに分割されてディスクに保存される。クラスタはいくつかのセクタで構成されていて、ディスクへのアクセスは常にセクタ単位。ファイルシステム中の全てのファイルの情報は$MFTという特殊なファイルに書かれている。$MFT中のファイルの情報が書かれているレコードは固定長。初期設定でフォーマットした場合、クラスタ、セクタ、レコードのサイズはそれぞれ、4096バイト, 512バイト, 1024バイトだった。
4段階のファイルの扱い
The Four Stages of NTFS File GrowthやNTFS ボリューム上で新規ファイルが作成できない現象についてでマイクロソフトの人が説明しているように、NTFS中のファイルはサイズや断片化の度合いによって、4段階の扱いをされる。
- ファイルの内容が$MFTのレコードに含まれる。NTFSの特徴で小さいファイルの扱い方が上手いから断片化がしにくいと言われる理由がこれ。ファイルのプロパティでディスク上のサイズが0バイトになっている状態。
- ファイル内容はディスク中の$MFT以外の場所に保存され、$MFTのファイルに対応するレコード中にその位置情報が書かれている。たぶん最も一般的な状態。
- ファイルの位置情報が$MFTの別レコードに書かれている。断片化がひどかったりファイルサイズが大きくて位置情報がレコードに入りきらないとこの状態になる。元のレコードには、どのレコードに記録したかという情報が残る。この別レコードは複数になる場合もある。
- ファイルの位置情報が書かれている別レコードが増えすぎて、別レコードがどこにあるかという情報が元のレコードに入りきらなくなり、別レコードがどこにあるかという情報が$MFTの外に置かれている。ややこしい。位置情報そのものは$MFT中にある。私のディスク中に3.の状態のファイルは大量にあったけど、この状態のファイルは1個も無かった。
属性
$MFT中のレコードは複数の属性(Attribute)で構成される。属性には、更新日時などの情報($Standard_Information)、ファイル名($File_Name)、レコード中に入りきらなかった属性のリスト($Attribute_List)などがある。NTFSではファイルの内容も$Dataという属性の内容でしかない。属性の内容のサイズによって、$MFT中に直接書かれている場合(Resident)と、内容は$MFTの外にありレコードにはその位置のみが書かれている場合(Non-resident)とがある。
実際に読んでみる
各構造体の詳しい内容は↑の参考にしたサイトに載っている。
Boot sector
ボリュームの先頭1KiBには、セクタ・クラスタ・レコードのサイズや$MFTの位置(クラスタ単位)が書かれている。
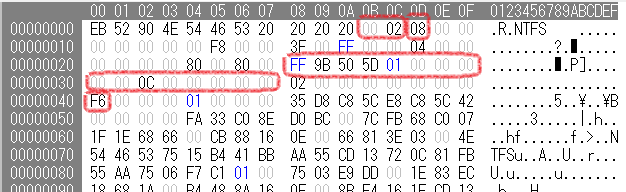
- セクタのサイズは、0x0200 = 512バイト
- クラスタのサイズは、0x08 = 8セクタ = 4096バイト
- セクタの総数は、0x015d509bff = 5860531199個 = 3000591973888バイト
- $MFTは、0x0c0000番目のクラスタ
- ファイルレコードあたりのセクタ数は、0xf6 = -10。負の場合、この値はファイルレコードのサイズをセクタ数単位ではなく2の冪で表すらしい。レコードのサイズは、$2^{-(-10)}$ = 1024バイト
$MFT
$MFTのクラスタ番号(0x0c0000)とクラスタサイズ(4096)から、0x0c0000×4096 = 0xc0000000に$MFTがあることが分かる。$MFTも1個のファイルであり、下図のように断片化することもありうる。$MFTの最初のレコードは$MFT自身なので、まずはここを通常のファイルと同じように読んで$MFTの全体がどこにあるかを調べる必要がある。一度メモリに全部読んでしまえば後が楽だけど、$MFTのサイズは数GBになりうるので、そういうわけにもいかず面倒。Autopsyや、FTKで$MFTを取り出すこともできる。Autopsyは$MFTが1.4GBのボリュームを読み込ませると固まったけど、FTKなら大丈夫だった。

ファイルレコードヘッダ

ここで読む必要があるのは、
- アップデートシーケンスのオフセット(0x30)
- アップデートシーケンスのサイズ(0x03)
- 最初の属性のオフセット(0x38)
- フラグ(0x0001)
- アップデートシーケンスの内容(0300, 616c, 0000)
フラグは、0x0001がファイル、0x0003がフォルダ、0x0000が削除されたファイル、0x0002が削除されたフォルダ。
このレコードが他のレコードに入りきらなかった内容の場合、+0x20に元のレコードの参照が含まれるので、ここが0ではないときには、このレコードを読み飛ばせば良い。
アップデートシーケンス
これに気が付かなくて悩んだ。NTFSの$MFTにはセクタの破損を検知するためにアップデートシーケンスというものがある。下図の青枠がセクタ。$MFTでは各セクタの最後の2バイトをランダムな値に置換し、元の値をファイルレコードのヘッダに保存している。レコード中のi番目の最後の値は、アップデートシーケンスの最初の値に置換され、元の値はアップデートシーケンスのi+1番目に保存される。下の例だと、読み込む側はセクタ最後の0003がアップデートシーケンスの最初の値0003に等しいことを確認し、読み込んだ後で616cに置換する必要がある。

属性(Resident)

- 属性ID(0x10)
- 属性の(レコード中の)サイズ(0x60)
- Form code(0x00)
- 内容のサイズ(0x48)
- 内容のオフセット(0x18)
を読む。Form codeの0x00がこの属性の内容が$MFT中に含まれている(Resident)ことを示している。
次の属性は、現在の属性のオフセットに属性のサイズを加えた場所にある。属性種別0xffffffffが、このファイルレコードの終端。
属性(Non-resident)
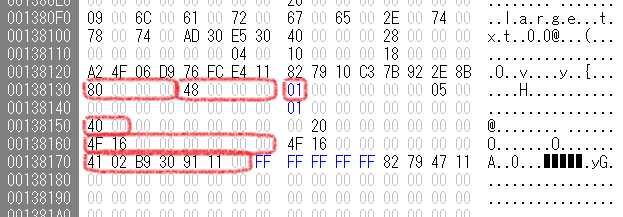
内容が$MFTに含まれない属性。種別とレコード中のサイズはResidentの場合と同じだが、Form codeが0x01になり、以降の内容が次のように変わっている。
- Data run listのオフセット(0x40)
- 内容のサイズ(64bitになっている)(0x164f)
- Data run list(読み方は後述)(41 02 b9 30 91 11 00)
ファイル名($File_Name属性)

属性IDは0x30。属性の内容の0x40バイト目以降にファイル名に関する情報がある。
- ファイル名の文字数(0x09)
- ファイル名の種別(0x00)
- ファイル名(Unicode)(73 00 6d 00 61 00 …)
このファイルのファイル名がsmall.txtであることが分かる。DOS形式のファイル名を保存する設定になっているボリュームの場合、ファイル名種別0x02として保存されている。ファイル名種別0x00の属性が別にあるはずなので、0x02の属性は無視すれば良い。
ファイルの内容(1段階目)
ファイルの内容は$Data属性(IDは0x80)の内容なので、$Data属性の内容をどう取得するかという話。ファイルの内容と書いているけれど、サイズの大きな属性は同じ扱いをされるはず。
1段階目は$DataがResident。この場合、属性中にそのまま内容が書かれているので簡単。属性中で指定されたオフセット(0x18)から指定されたサイズ(0xde)だけ読めば良い。
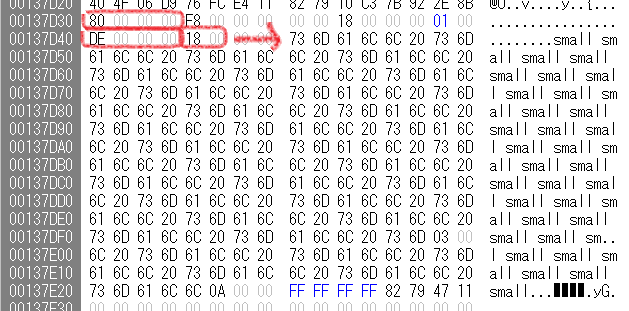
ファイルの内容(2段階目)
$DataがNon-resident。$MFTにはData run listだけが含まれているので、これを元にディスク中からファイルの内容を読む必要がある。
大きなファイルの場合、ファイルが分割(フラグメント)されてディスク中に保存される。Data run listには各フラグメント(Run)の長さとオフセットがクラスタ単位で保存されている。また、オフセットは1個前のRunのオフセットからの相対値(最初は0)になっている。最上位ビットが1ならば負値。容量を節約するため、長さとオフセットは最低限必要なバイト数で格納されている。各Runの最初の1バイトの下位4ビットが長さのビット数、上位4バイトがオフセットのビット数。長さもオフセットもビット数が0のRunが出てきたら終了。スパースファイル中の空の部分はオフセット(の差分)が0になるらしい。

このファイルのData run listを読むと次のようになる。
| 元データ | ビット数 | 長さ | オフセット(差分) | オフセット |
|---|---|---|---|---|
| 42 2f 01 13 84 90 35 | 42 | 012f | 35908413 | 35908413 |
| 42 93 01 51 b5 0b db | 42 | 0193 | db0bb551(-24f44aaf) | 109c3964 |
| 32 00 0c c6 69 03 | 32 | 0c00 | 0369c6 | 109fa32a |
| 22 00 28 10 14 | 22 | 2800 | 1410 | 109fb73a |
| 42 7e 0d c4 be 3d 0b | 42 | 0d7e | 0b3dbec4 | 1bdd75fe |
| : | : | : | : | : |
クラスタサイズが4KiBの場合、このファイルの最初の0x012f×4096 = 1241088バイトは、ボリューム中の0x35908413×4096 = 3680925462528バイト目に存在する。次の0x0193×4096バイトは、0x109c3964×4096バイト目。
ファイルの内容(3段階目)
↑のData run listのサイズは246バイトなので、レコード中に収まるが、Data run listのサイズが大きくなると別レコードに置かれ、元のレコードには$Attribute_List属性が書かれるようになる。$Attribute_Listの属性IDは0x20。
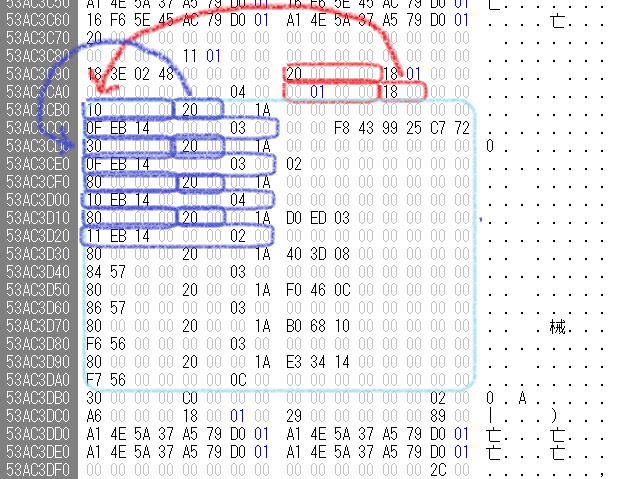
この例では、$Attribute_List中の最初の属性は、IDが0x10で、この項目のサイズは0x20(次の項目は+0x20)で、0x14eb0f番目のファイルレコードに含まれていることが分かる。上位2バイトには何か値が入っているので、下位6バイトだけを使えば良いらしい。今見ているファイルレコードも0x14eb0f番目。元のレコードに含まれる属性も、$Attribute_List自身以外は列挙される。$Attribute_Listがあったら、全ての属性を$Attribute_List経由で読めば良いらしい。目的の$Dataは0x14eb10番目、0x14eb11番目、0x5784番目、0x5786番目、0x56f6番目、0x56f7番目の6個のレコードに分割して格納されていることが分かる。このボリュームの1個のレコードのサイズは、1024 = 0x400バイトなので、それぞれ$MFT中の0x53ac4000バイト目、0x53ac4400バイト目、0x15e1000バイト目、…に属性が存在する。属性の個数や終端を表すものは無いので、$Attribute_Listの内容の最後まで読めば良いらしい。


入りきらなかった属性が置かれている別レコード自体は、属性が1個だけであることと、元のレコードの番号(0x14eb0f)を含んでいること以外は通常のレコードと同じ。ファイルサイズ(0x015fdca158)は最初のレコードのみに書かれている。オフセットは差分で保存されているが、このオフセットは2番目以降のレコードでは0に初期化される。後は2段階目と同じように読めば良い。
ファイルの内容(4段階目)
$Attribute_ListがNon-residentになる($MFT外に置かれる)場合があるらしいが、手元にそういうファイルが無いので試していない。$Dataの内容を読むときと同じように$Attribute_Listの内容を読めば良いはず。
ファイルの復元について
ファイルが削除された場合、ファイルレコードのフラグの値が変わるだけで、レコードが上書きされるまでは各属性などはそのまま残っている。普通のファイルを読むのと同じように読めば簡単に復元できる。いちいち別ドライブに書き出すのではなく、同じドライブでファイルを復元できれば楽だが、フラグの値を戻すだけではなく、親フォルダの情報を変更したりしないといけないので、面倒。
では、なぜ4GB以上のファイルの復元が困難かというと、Everything I know about NTFSに書かれているように、4GB以上の場合はなぜかファイルサイズやData run listなどが削除されてしまうから。フラグを削除済みにするだけで良さそうなものだが、なぜかご丁寧に0クリアされる。下図は4GB以上のファイルの別レコードにおかれていた$Data属性の様子。4GB未満のサイズではこうはならない。
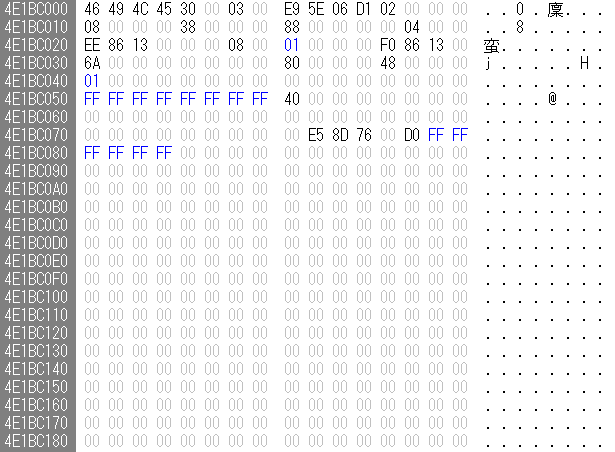
ディスク上のファイルサイズが4GiB以上だとダメらしく、ファイルサイズを変えて試したところ復元できる最大のファイルサイズは4294963200バイト(4GiB-4KiB)だった。
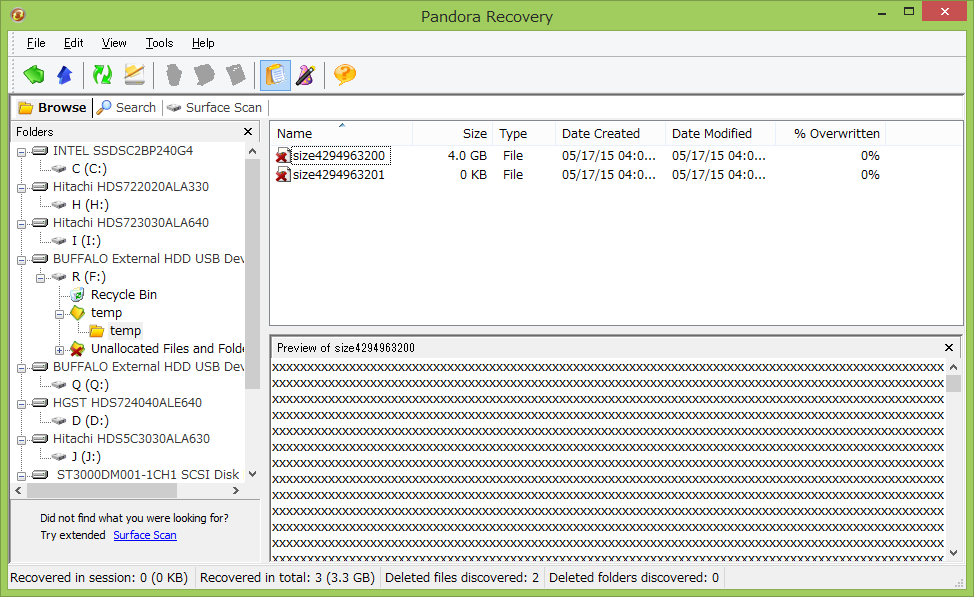
この動作はホントに意味が分からない。多少パフォーマンスが落ちても良いから、レジストリ設定などで止められるなら止めたい。
4GB以上のファイルの復元について
たいていの復元ソフトには、サーフェススキャン機能($MFTに頼らず、ディスク上を全探索)が付いているので、これを使うしかない。ただ、4GB以上のファイルはたいていはフラグメントされているだろうから、厳しい。同時に複数のファイルが書き込まれた場合、書き込み位置は交互になるだろうし、一方だけを消したなら他方のData run listの抜けている部分を寄せ集めれば良いのでは……とも考えたけど、私の場合はフラグメントがひどすぎて諦めた。
4GB以上のファイルなんてほとんどが.tsだろうし、.tsにはチャンネルや時刻が書き込まれているので、それらを使えばフラグメントされたファイルを正しく並べ替えられそう。誰かそういうソフトを作ってほしい。
おまけ
4GB以上のファイルを復元する方法が無いかとググっていたら、ファイナルデータのQ&Aがひっかかった。
Question.
ファイルサイズが 4GBを超えるファイルが復元できません。
Answer.
復元先のドライブのフォーマットが FAT32 ではないことを確認して下さい。
FAT32では、1個のファイルのサイズが最大 4GBに制限されており、 4GB超のファイルを作ることができません。NTFSでフォーマットされたド ライブを復元先にしてください。
4GBを超えるファイルが復元できません
上で書いたようにNTFSではそもそも4GB以上のファイルの復元が難しいので、これはFAT32がどうこうという話ではない気がする。質問した人(´・ω・) カワイソス