はじめに
自社システムのFAQとして日本語AI回答機能を追加する場合、LlamaIndexで実現可能
との記事がありましたので参考にして試してみました。
結果、たしかにネットワーク接続なし (LANケーブル接続なし) 環境でも日本語で質問すると
日本語で回答してくれることが分りました。
質問と回答の組み合わせを自分で登録しておけるので、これは使えそうな気がします。
今回試した手順を残します。
前提
Windows 環境 Python 3.10.11 を使用します。
Microsoft Store からインストールでも、別の方法でも問題なし。
venv で仮想環境を構築し、そこで作業することにします。
フォルダ構成 (最終的にこうなります)

1.inputs
質問と回答の組み合わせを記載したファイルを配置します。

2.models
モデル形式ファイルを配置します。
今回は別記事 (LM Studioでローカル環境でLLMを動かす手順について
https://qiita.com/kharada_toyotec/items/d81214234bc429475789) でダウンロードした ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf を使用します。

仮想環境 (venv) 設定
1.ルートフォルダ
今回は Dドライブに Python\LlamaIndexSample フォルダを作成し、そこで作業します。
2.venv作成
python -m venv .venv

3.activate
.venv\Scripts\activate

行の先頭が (.env) に変わります。

必要なライブラリをインストール
1.transformers accelerate bitsandbytes
pip install transformers accelerate bitsandbytes

2.torch torchvision torchaudio
python -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121

3.langchain
pip install langchain

4.llama_index
pip install llama_index

5.llama-cpp-python
pip install llama-cpp-python

6.sentence-transformers
pip install sentence-transformers

実行するプログラム
from llama_index import LLMPredictor, ServiceContext, SimpleDirectoryReader, GPTVectorStoreIndex
from llama_index.embeddings import LangchainEmbedding
from llama_index.prompts.prompts import QuestionAnswerPrompt
from langchain.llms import LlamaCpp
#from langchain_community.llms import LlamaCpp
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
llm = LlamaCpp(model_path=f'./models/ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf', temperature=0, n_ctx=4096, n_gpu_layers=1)
llm_predictor = LLMPredictor(llm=llm)
embed_model = LangchainEmbedding(HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-base"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, embed_model=embed_model)
# ドキュメントのインデックス化
documents = SimpleDirectoryReader('./inputs').load_data()
index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)
# 質問
temp = """
<s>[INST] <<SYS>>
あなたは誠実で優秀な日本人のアシスタントです。
以下の「コンテキスト情報」と「制約条件」を元に質問に回答してください。
# コンテキスト情報
---------------------
{context_str}
---------------------
# 制約条件
- コンテキスト情報はマークダウン形式で書かれています。
- 「コンテキスト情報に」のような書き方を絶対に回答に含めないでください。
- コンテキスト情報に無い情報は絶対に回答に含めないでください。
- コンテキスト情報の内容を丸投げするのではなく、絶対にきちんとした文章にして回答してください。
- 質問の答えを知らない場合は、誤った情報を共有しないでください。
<</SYS>>
{query_str} [/INST]
"""
query_engine = index.as_query_engine(text_qa_template=QuestionAnswerPrompt(temp))
while True:
req_msg = input('\n## Question: ')
res_msg = query_engine.query(req_msg)
print('\n##', str(res_msg).strip())
質問と回答の組み合わせ
# 〇〇システム FAQ
## こんなときは
### 問合せ先を知りたい
- ■×株式会社(TEL 000-111-2222、FAX 000-111-9999) へ連絡ください。
### ログインできない
- キーボードのCapsLockがONになっていないか確認いただき、ユーザID、パスワードに誤りがないか再確認してください。
### 他の端末で使用中と表示される
- 対象プログラムの「ロック区分」を確認いただき、「処理中」の場合は「通常状態」に戻し、再実行してください。
プログラム実行
実際に実行してみます。
それほど待たずに回答がきます。
python main.py

「##Question: 」で止まり、質問受付状態となります。

質問してみます。
大きな問題はなさそう。

続けて質問してみます。
これも特に問題なさそう。
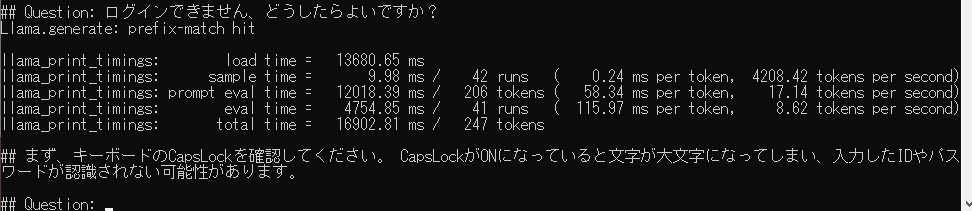
最後の質問。
質問と回答の組み合わせで登録した内容以外に余計な回答 (Windowsの場合~) が返りました。
これはイマイチです。
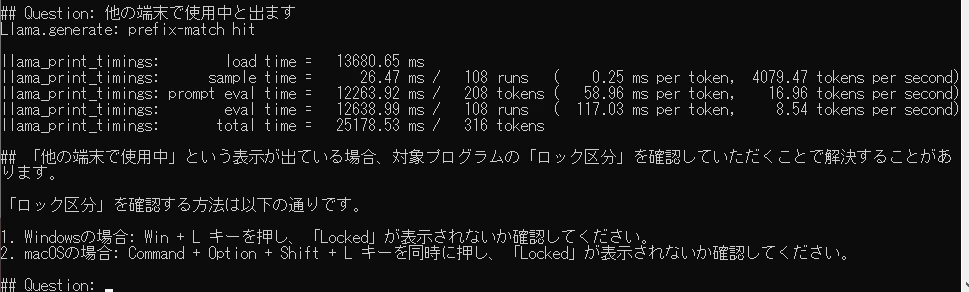
最後に
改善する必要はありそうですが、ネットワークに接続していない環境で使えることが分りました。
使い道は色々とありそうです。
参考文献
この記事は以下の情報を参考にして執筆しました。