1. はじめに
以前、下記の記事で強化学習の DQN(Deep Q-Network) を使って宇宙船の着陸ゲームに挑戦しました。
この記事の内容が楽しく、あれから強化学習の勉強をしていたので、今回は少しレベルをあげて、以下の動画のような MuJoCo (Multi-Joint Dynamics with Contact) と呼ばれる物理エンジンを使って、複雑なモデルの強化学習を行いたいと思います。

(学習途中です)
MuJoCo 環境は以前まで有料だったのですが、2021年10月にDeepMindに買収され、2022年にオープンソースになりました。
本記事では専門的な解説はそこそこに、強化学習らしくロボットが頑張って学習している過程を、動画をつけて紹介しようと思います!
2. 事前準備
2.1. Docker での環境構築
MuJoCo は Windows環境では動かないので、Dockerで環境構築を行いました。
使用したDockerfileはこちらです。
FROM nvidia/cuda:11.8.0-devel-ubuntu22.04
ENV LANG C.UTF-8
RUN apt-get update -q \
&& DEBIAN_FRONTEND=noninteractive apt-get install -y \
curl \
python3.10 \
python3-pip \
wget \
git \
libgl1-mesa-dev \
libgl1-mesa-glx \
libglew-dev \
libosmesa6-dev \
software-properties-common \
net-tools \
virtualenv \
xpra \
xserver-xorg-dev \
patchelf \
swig \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN ln -s /usr/bin/python3.10 /usr/bin/python
RUN pip install --upgrade pip
WORKDIR /work
COPY requirements.txt /work/
RUN pip install --no-cache-dir torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
RUN pip install --no-cache-dir -r /work/requirements.txt
wheel
gym
numpy
matplotlib
gym[mujoco]
mujoco
pyvirtualdisplay
pyopengl
pandas
tqdm
seaborn
scikit-learn
pytorch-lightning
tensorboard
jupyterlab
cython<3
moviepy
インストールされたPythonライブラリとそのバージョン
absl-py==1.4.0
aiohttp==3.8.5
aiosignal==1.3.1
anyio==4.0.0
argon2-cffi==23.1.0
argon2-cffi-bindings==21.2.0
arrow==1.2.3
asttokens==2.4.0
async-lru==2.0.4
async-timeout==4.0.3
attrs==23.1.0
Babel==2.12.1
backcall==0.2.0
bcrypt==3.2.0
beautifulsoup4==4.12.2
bleach==6.0.0
blinker==1.4
Brotli==1.0.9
cachetools==5.3.1
certifi==2022.12.7
cffi==1.15.1
charset-normalizer==2.1.1
cloudpickle==2.2.1
cmake==3.25.0
comm==0.1.4
contourpy==1.1.0
cryptography==3.4.8
cycler==0.11.0
Cython==0.29.36
dbus-python==1.2.18
debugpy==1.8.0
decorator==4.4.2
defusedxml==0.7.1
distlib==0.3.4
distro==1.7.0
distro-info==1.1+ubuntu0.1
exceptiongroup==1.1.3
executing==1.2.0
fastjsonschema==2.18.0
filelock==3.6.0
fonttools==4.42.1
fqdn==1.5.1
frozenlist==1.4.0
fsspec==2023.9.1
glfw==2.6.2
google-auth==2.23.0
google-auth-oauthlib==1.0.0
grpcio==1.58.0
gssapi==1.6.12
gym==0.26.2
gym-notices==0.0.8
httplib2==0.20.2
idna==3.4
ifaddr==0.1.7
imageio==2.31.3
imageio-ffmpeg==0.4.9
importlib-metadata==4.6.4
ipykernel==6.25.2
ipython==8.15.0
isoduration==20.11.0
jedi==0.19.0
jeepney==0.7.1
Jinja2==3.1.2
joblib==1.3.2
json5==0.9.14
jsonpointer==2.4
jsonschema==4.19.0
jsonschema-specifications==2023.7.1
jupyter-events==0.7.0
jupyter-lsp==2.2.0
jupyter_client==8.3.1
jupyter_core==5.3.1
jupyter_server==2.7.3
jupyter_server_terminals==0.4.4
jupyterlab==4.0.6
jupyterlab-pygments==0.2.2
jupyterlab_server==2.25.0
keyring==23.5.0
kiwisolver==1.4.5
launchpadlib==1.10.16
lazr.restfulclient==0.14.4
lazr.uri==1.0.6
lightning-utilities==0.9.0
lit==15.0.7
lz4==3.1.3+dfsg
Markdown==3.4.4
MarkupSafe==2.1.2
matplotlib==3.8.0
matplotlib-inline==0.1.6
mistune==3.0.1
more-itertools==8.10.0
moviepy==1.0.3
mpmath==1.2.1
mujoco==2.2.0
multidict==6.0.4
nbclient==0.8.0
nbconvert==7.8.0
nbformat==5.9.2
nest-asyncio==1.5.7
networkx==3.0
notebook_shim==0.2.3
numpy==1.25.2
oauthlib==3.2.0
olefile==0.46
overrides==7.4.0
packaging==23.1
pandas==2.1.0
pandocfilters==1.5.0
paramiko==2.9.3
parso==0.8.3
pexpect==4.8.0
pickleshare==0.7.5
Pillow==9.0.1
platformdirs==2.5.1
proglog==0.1.10
prometheus-client==0.17.1
prompt-toolkit==3.0.39
protobuf==4.24.3
psutil==5.9.5
ptyprocess==0.7.0
pure-eval==0.2.2
py-cpuinfo==5.0.0
py3dns==3.2.1
pyasn1==0.5.0
pyasn1-modules==0.3.0
pycairo==1.20.1
pycparser==2.21
Pygments==2.16.1
PyGObject==3.42.1
pyinotify==0.9.6
PyJWT==2.3.0
pykerberos==1.1.14
PyNaCl==1.5.0
PyOpenGL==3.1.5
pyparsing==2.4.7
python-apt==2.4.0+ubuntu2
python-dateutil==2.8.2
python-json-logger==2.0.7
python-lzo==1.12
pytorch-lightning==2.0.9
pytz==2023.3.post1
PyVirtualDisplay==3.0
pyxdg==0.27
PyYAML==6.0.1
pyzmq==25.1.1
referencing==0.30.2
rencode==1.0.6
requests==2.31.0
requests-oauthlib==1.3.1
rfc3339-validator==0.1.4
rfc3986-validator==0.1.1
rpds-py==0.10.3
rsa==4.9
scikit-learn==1.3.0
scipy==1.11.2
seaborn==0.12.2
SecretStorage==3.3.1
Send2Trash==1.8.2
setproctitle==1.2.2
six==1.16.0
sniffio==1.3.0
soupsieve==2.5
stack-data==0.6.2
sympy==1.11.1
tensorboard==2.14.0
tensorboard-data-server==0.7.1
terminado==0.17.1
threadpoolctl==3.2.0
tinycss2==1.2.1
tomli==2.0.1
torch==2.0.1+cu118
torchaudio==2.0.2+cu118
torchmetrics==1.1.2
torchvision==0.15.2+cu118
tornado==6.3.3
tqdm==4.66.1
traitlets==5.10.0
triton==2.0.0
typing_extensions==4.4.0
tzdata==2023.3
unattended-upgrades==0.1
uri-template==1.3.0
uritools==3.0.2
urllib3==1.26.13
virtualenv==20.13.0+ds
wadllib==1.3.6
wcwidth==0.2.6
webcolors==1.13
webencodings==0.5.1
websocket-client==1.6.3
Werkzeug==2.3.7
xdg==5
xpra==3.1
yarl==1.9.2
zeroconf==0.38.3
zipp==1.0.0
この Docker イメージでは、jupyterlab から Mujoco を使用できるようにしています。
起動するときは、以下のような docker-compose.yml を作成し,
version: '3.8'
services:
gym-jupyter:
build:
context: .
command: sh -c "jupyter lab --ip=0.0.0.0 --allow-root --LabApp.token='' "
container_name: gym-jupyter
volumes:
- ./work:/work
working_dir: /work
environment:
- CUDA_VISIBLE_DEVICES=0
ports:
- 8888:8888
- 6006:6006
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
$ docker-composer up -d --build
と実行すると、イメージの作成 & コンテナが起動します。
http://localhost:8888/lab に jupyterlab が起動しているので、以降は下の画面のような jupyterlab から操作します。
(./work ディレクトリに入ったファイルを jupyterlab から使用できるようにしています。)
2.2. 強化学習アルゴリズム SAC について
今回使用する MuJoCo 環境のモデルは,行動が連続的な値を取る連続値制御タスクになります。
このような連続時間のタスクは、DQNといった離散値用のアルゴリズムで解くのは不向きであるため、今回は連続値制御タスク向け強化学習アルゴリズム SAC (Soft Actor-Critic) を使用します。
SACの特徴は以下の通りです。
- Off-policy 学習
- Off-policy学習とは、現在のポリシーとは異なるポリシーで収集されたデータを再利用する方法です。これにより、学習に必要なサンプル数が削減され、サンプル効率が向上します。
- Actor-Critic 構造
- Actor-Critic構造では、Criticが最適な行動価値を学ぶ一方、Actorはその情報を元に行動を選択します。これにより、行動の選択と価値の評価を効率的に同時に進行させることができます。
- エントロピー正則化付きの報酬
- エントロピー正則化項を通常の報酬に追加することで、エージェントは単に報酬を最大化するだけでなく、多様な行動を探索するようになります。
- デュアルQ学習
- 2つのQ関数 (Critic) を使用し、それぞれを独立して学習します。これらのQ関数の出力の最小値を用いることで、Q関数の過大評価の問題を緩和します。このアプローチにより、学習の安定性が向上します。
- ターゲットネットワーク
- ターゲットネットワークは、Qネットワークにゆっくりと追従して更新される方式を採用することにより、更新時のネットワークの安定性が増し、学習がより滑らかに進行するようになります。
詳しい解説は、以下の記事などをご確認ください。
2.3. 作成したコード
機械学習ライブラリとしてPytorchを使用し、作成したSACのコードは以下になります。長いので折りたたんでいます。
 SACのコード
SACのコード
import gym
import pytorch_lightning as pl
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Normal
import numpy as np
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.dataset import IterableDataset
from gym.wrappers import RecordVideo
import torch.nn.functional as F
import copy
from collections import deque
import random
class ReplayBuffer:
"""経験を保存するためのリプレイバッファ"""
def __init__(self, capacity):
# デックで固定長のバッファを初期化
self.buffer = deque(maxlen=capacity)
def __len__(self):
return len(self.buffer)
def append(self, experience):
"""バッファに経験を追加"""
self.buffer.append(experience)
def sample(self, batch_size):
"""バッファからランダムに経験をサンプリング"""
return random.sample(self.buffer, batch_size)
class GymDataset(IterableDataset):
"""リプレイバッファからのサンプリング結果を使用してPyTorchデータセットを作成"""
def __init__(self, buffer, sample_size=400):
self.buffer = buffer
self.sample_size = sample_size
def __iter__(self):
# リプレイバッファからサンプルを取得し、テンソルに変換してイテレータとして返す
for experience in self.buffer.sample(self.sample_size):
tensors = [torch.tensor(item, dtype=torch.float32) if not isinstance(item, float) else torch.tensor([item], dtype=torch.float32) for item in experience]
yield tuple(tensors)
def init_weight(layer, initializer="he normal"):
"""ネットワークの重みの初期化を行う関数"""
if initializer == "xavier uniform":
nn.init.xavier_uniform_(layer.weight)
elif initializer == "he normal":
nn.init.kaiming_normal_(layer.weight)
class Critic(nn.Module):
"""クリティックネットワークの定義"""
def __init__(self, n_states, n_actions, n_hidden_filters=256):
super(Critic, self).__init__()
self.n_states = n_states
self.n_hidden_filters = n_hidden_filters
self.n_actions = n_actions
# ネットワークの層の定義
self.hidden1 = nn.Linear(in_features=self.n_states + self.n_actions, out_features=self.n_hidden_filters)
init_weight(self.hidden1)
self.hidden1.bias.data.zero_()
self.hidden2 = nn.Linear(in_features=self.n_hidden_filters, out_features=self.n_hidden_filters)
init_weight(self.hidden2)
self.hidden2.bias.data.zero_()
self.q_value = nn.Linear(in_features=self.n_hidden_filters, out_features=1)
init_weight(self.q_value, initializer="xavier uniform")
self.q_value.bias.data.zero_()
def forward(self, states, actions):
"""フォワードパスの定義"""
x = torch.cat([states, actions], dim=1) # 状態とアクションを結合
x = F.relu(self.hidden1(x))
x = F.relu(self.hidden2(x))
return self.q_value(x)
class Actor(nn.Module):
"""アクターネットワークの定義。このネットワークは環境の状態を取り、行動の確率分布を出力する。"""
def __init__(self, n_states, n_actions, action_bounds, n_hidden_filters=256):
super(Actor, self).__init__()
self.n_states = n_states
self.n_hidden_filters = n_hidden_filters
self.n_actions = n_actions
self.action_bounds = action_bounds # 行動の上限・下限
# ネットワークの層の定義
self.hidden1 = nn.Linear(in_features=self.n_states, out_features=self.n_hidden_filters)
init_weight(self.hidden1) # 重みの初期化
self.hidden1.bias.data.zero_()
self.hidden2 = nn.Linear(in_features=self.n_hidden_filters, out_features=self.n_hidden_filters)
init_weight(self.hidden2)
self.hidden2.bias.data.zero_()
# 各行動の平均を出力するための層
self.mu = nn.Linear(in_features=self.n_hidden_filters, out_features=self.n_actions)
init_weight(self.mu, initializer="xavier uniform")
self.mu.bias.data.zero_()
# 各行動の標準偏差の対数を出力するための層
self.log_std = nn.Linear(in_features=self.n_hidden_filters, out_features=self.n_actions)
init_weight(self.log_std, initializer="xavier uniform")
self.log_std.bias.data.zero_()
def forward(self, states):
"""フォワードパスの定義。確率分布を返す。"""
x = F.relu(self.hidden1(states))
x = F.relu(self.hidden2(x))
mu = self.mu(x)
log_std = self.log_std(x)
# 標準偏差を取得(-20から2の範囲でクリップ)
std = log_std.clamp(min=-20, max=2).exp()
# 正規分布を返す
dist = Normal(mu, std)
return dist
def sample(self, states):
"""アクションをサンプルし、そのアクションの対数確率を返す。"""
dist = self(states)
# Reparameterization trickを使用してアクションをサンプル
u = dist.rsample()
action = torch.tanh(u)
# アクションの確率を計算
log_prob = dist.log_prob(u)
# アクションが-1から1の範囲になるように修正
log_prob -= torch.log((1 - action ** 2) + 1e-6)
log_prob = log_prob.sum(-1, keepdim=True)
# 行動の上限をかけることで行動の範囲を調整
return action * self.action_bounds[1], log_prob
class SACAgent(pl.LightningModule):
def __init__(self, env, max_episodes=2000, batch_size=4096, gamma=0.99, tau=0.005, lr=1e-3, capacity=1000000, alpha=0.2, samples_per_epoch=256, learn_start_size=10000):
super(SACAgent, self).__init__()
# 環境の情報を取得
self.env = env
self.state_dim = env.observation_space.shape[0]
self.action_dim = env.action_space.shape[0]
self.action_scale = [env.action_space.low[0], env.action_space.high[0]]
# SACアルゴリズムのハイパーパラメータを設定
self.batch_size = batch_size
self.gamma = gamma
self.tau = tau
self.lr = lr
self.max_episodes = max_episodes
self.capacity = capacity
self.learn_start_size = learn_start_size
self.alpha = alpha
self.samples_per_epoch = samples_per_epoch
# 報酬を保持するデックの初期化
self.episode_rewards = deque(maxlen=50)
# モデルの初期化
self.actor = Actor(self.state_dim, self.action_dim, self.action_scale).to(self.device)
self.critic1 = Critic(self.state_dim, self.action_dim).to(self.device)
self.critic2 = Critic(self.state_dim, self.action_dim).to(self.device)
self.target_critic1 = copy.deepcopy(self.critic1)
self.target_critic2 = copy.deepcopy(self.critic2)
# リプレイバッファの初期化
self.replay_buffer = ReplayBuffer(capacity)
self.episode_count = 0
# PyTorch Lightningの自動最適化を無効にする
self.automatic_optimization = False
# 環境の初期状態を取得
self.current_state, _ = self.env.reset()
self.current_reward = 0
self.current_episode = 0
self.current_step = 0
self.max_step = 1000
def prepare_replay_buffer(self):
"""リプレイバッファを準備する"""
state, _ = self.env.reset()
while len(self.replay_buffer) < self.batch_size:
action = self.env.action_space.sample()
next_state, reward, done, _, info = self.env.step(action)
self.append_to_replay_buffer(state, action, reward, next_state, done)
if not done:
state = next_state
else:
state, _ = self.env.reset()
def train_dataloader(self):
"""訓練データローダーを返す"""
# データセットの作成
dataset = GymDataset(self.replay_buffer, self.samples_per_epoch)
# データローダーの作成
dataloader = DataLoader(dataset, self.batch_size)
return dataloader
def soft_update(self, target_network, local_network, tau=0.005):
"""ソフトアップデートを行う"""
for target_param, local_param in zip(target_network.parameters(), local_network.parameters()):
target_param.data.copy_(tau * local_param.data + (1 - tau) * target_param.data)
def train_step(self, batch):
"""1ステップの訓練を行う"""
states, actions, rewards, next_states, dones = batch
rewards = rewards.unsqueeze(1)
dones = dones.unsqueeze(1)
# Q値のターゲットを計算
with torch.no_grad():
next_actions, target_log_probs = self.actor.sample(next_states)
target_q1 = self.target_critic1(next_states, next_actions)
target_q2 = self.target_critic2(next_states, next_actions)
next_action_values = torch.min(target_q1, target_q2)
v = (1 - dones) * (next_action_values - self.alpha * target_log_probs)
target_values = rewards + self.gamma * v
# 現在のQ値を取得
q1 = self.critic1(states, actions)
q2 = self.critic2(states, actions)
# クリティックの損失を計算
critic_loss1 = F.mse_loss(q1, target_values)
critic_loss2 = F.mse_loss(q2, target_values)
# アクターの損失を計算
new_actions, log_probs = self.actor.sample(states)
q1_new = self.critic1(states, new_actions)
q2_new = self.critic2(states, new_actions)
q_new = torch.min(q1_new, q2_new)
actor_loss = (self.alpha * log_probs - q_new).mean()
return critic_loss1, critic_loss2, actor_loss
@torch.no_grad()
def play_episode(self):
"""エピソードの実行を行い、リプレイバッファに結果を追加する"""
# 現在のステートからアクターネットワークを使って行動をサンプルする
states = np.expand_dims(self.current_state, axis=0)
state_tensor = torch.from_numpy(states).float().to(self.device)
action, _ = self.actor.sample(state_tensor)
action = action.detach().cpu().numpy()[0]
# 選択された行動を環境に適用し、新しいステートと報酬を取得する
next_state, reward, done, _, info = self.env.step(action)
# 経験をリプレイバッファに保存
self.append_to_replay_buffer(self.current_state, action, reward, next_state, done)
# 状態、報酬、ステップ数を更新
self.current_state = next_state
self.current_reward += reward
self.current_step += 1
# エピソードが終了した場合、またはステップ数が最大値を超えた場合の処理
if done or self.current_step > self.max_step:
# エピソード数をインクリメント
self.current_episode += 1
# ログ情報を保存
self.log('train/episode_num', torch.tensor(self.current_episode, dtype=torch.float32))
self.log('train/episode_reward', self.current_reward)
self.log('train/current_step', self.current_step)
# 過去の報酬の平均値を計算
self.episode_rewards.append(self.current_reward)
avg_reward = sum(self.episode_rewards) / len(self.episode_rewards)
self.log('train/avg_episode_reward', avg_reward)
# 新しいエピソードのための状態をリセット
self.current_state, _ = self.env.reset()
# 100エピソードごとの情報をプリント
if self.current_episode % 100 == 0:
print(f"episode:{self.current_episode}, episode_reward: {self.current_reward}, avg_reward: {avg_reward}")
# 現在の報酬とステップ数をリセット
self.current_reward = 0
self.current_step = 0
# エピソード数が最大値に達した場合、トレーニングを終了
if self.current_episode >= self.max_episodes:
self.trainer.should_stop = True
return done
def training_step(self, batch, batch_idx):
"""訓練ステップを実行する"""
current_episode_done = self.play_episode()
states, actions, rewards, next_states, dones = map(torch.squeeze, batch)
states, actions, rewards, next_states, dones = states.to(self.device), actions.to(self.device), rewards.to(self.device), next_states.to(self.device), dones.to(self.device)
critic_loss1, critic_loss2, actor_loss = self.train_step((states, actions, rewards, next_states, dones))
opt_actor, opt_critic1, opt_critic2 = self.optimizers()
# クリティック1の最適化
opt_critic1.zero_grad()
self.manual_backward(critic_loss1)
opt_critic1.step()
# クリティック2の最適化
opt_critic2.zero_grad()
self.manual_backward(critic_loss2)
opt_critic2.step()
# アクターの最適化
opt_actor.zero_grad()
self.manual_backward(actor_loss)
opt_actor.step()
self.soft_update(self.target_critic1, self.critic1, self.tau)
self.target_critic1.eval()
self.soft_update(self.target_critic2, self.critic2, self.tau)
self.target_critic2.eval()
if current_episode_done:
self.log('train/critic_loss1', critic_loss1)
self.log('train/critic_loss2', critic_loss2)
self.log('train/actor_loss', actor_loss)
self.log('train/alpha', self.alpha)
def configure_optimizers(self):
"""オプティマイザを設定する"""
critic_optimizer1 = optim.Adam(self.critic1.parameters(), lr=self.lr)
critic_optimizer2 = optim.Adam(self.critic2.parameters(), lr=self.lr)
actor_optimizer = optim.Adam(self.actor.parameters(), lr=self.lr)
return actor_optimizer, critic_optimizer1, critic_optimizer2
def forward(self, state):
"""アクターの方策を使用してアクションを生成する"""
with torch.no_grad():
action = self.actor.sample(state)
return action.cpu().numpy()
def append_to_replay_buffer(self, state, action, reward, next_state, done):
"""リプレイバッファに結果を追加する"""
self.replay_buffer.append((state, action, reward, next_state, float(done)))
def setup_display():
# Docker上なので仮想ディスプレイを作成する。
from pyvirtualdisplay import Display
Display(visible=False, size=(1400, 900)).start()
def main():
# 仮想ディスプレイのセットアップ
setup_display()
# OpenAI GymのAnt-v4環境を作成
env = gym.make('Ant-v4', render_mode="rgb_array")
# 10エピソードごとにビデオを記録するように環境をラップ
env = RecordVideo(env, './videos', episode_trigger=lambda x: x % 10 == 0)
# SACAgentモデルのインスタンス化
model = SACAgent(env, lr=3e-4, max_episodes=5000, gamma=0.99,
batch_size=256, samples_per_epoch=256)
# リプレイバッファの準備
model.prepare_replay_buffer()
# PyTorch Lightningトレーナのインスタンス化
trainer = pl.Trainer(max_epochs=-1, accelerator="auto",
log_every_n_steps=1, enable_progress_bar=False)
# モデルのトレーニング開始
trainer.fit(model)
if __name__ == "__main__":
# スクリプトが直接実行された場合、main関数を呼び出す
main()
工夫した点
- 強化学習ライブラリ OpenAI Gym から MuJoCo を使用しますが、Gym については最近のメジャーアップデートがされて書き方が変わった部分が多く、過去に公開されている多くの記事では、そのままのコードでは動かないようになっていました。最新バージョンで動くように書き換えています。
- PyTorch Lightning と TensorBoard を使って学習状況がリアルタイムでブラウザから確認できるようにしました。
- OpenAI Gym Wrapper を使って定期的に学習中に動画が生成されるようにしています。(強化学習は学習時間がそれなりにかかるのですが)今はこんな感じかーと、学習を頑張っている様子を確認できます。
苦労した点
この記事を書くのに1.5カ月くらい時間がかかってしまったのですが、今回の一番の苦労の原因は
「ChatGPTにSACのコードを聞くことにより、逆にバグがたくさん発生して、デバッグに難航した」ことです。
普段は「ChatGPTにお願いした」系の記事ばかり書いているのですが、今回の強化学習のように、ちょっとアルゴリズムを間違えるだけで、動かない繊細なアルゴリズムの場合、少しのミスで学習がまったく進まないようになります。
ChatGPTが出してくれるコードが一見非常に美しく、どこも間違っているように見えなかったために、逆にバグ取りに難航しました...
3. アリ型ロボット Ant-v4 の学習を始めよう!
3.1. 学習結果
jupyterlab から先ほどのコード(SAC.py)を実行すると,学習が始まります。
学習中のログ結果を確認したいときは、jupyterlab の別のタブからTerminal を開いて以下のコマンドを実行すると tensorboard が開きます。http://localhost:6006/ から開いてください。
$ tensorboard --logdir=./lightning_logs --host 0.0.0.0
学習の推移が、グラフ形式でリアルタイムに表示されます。
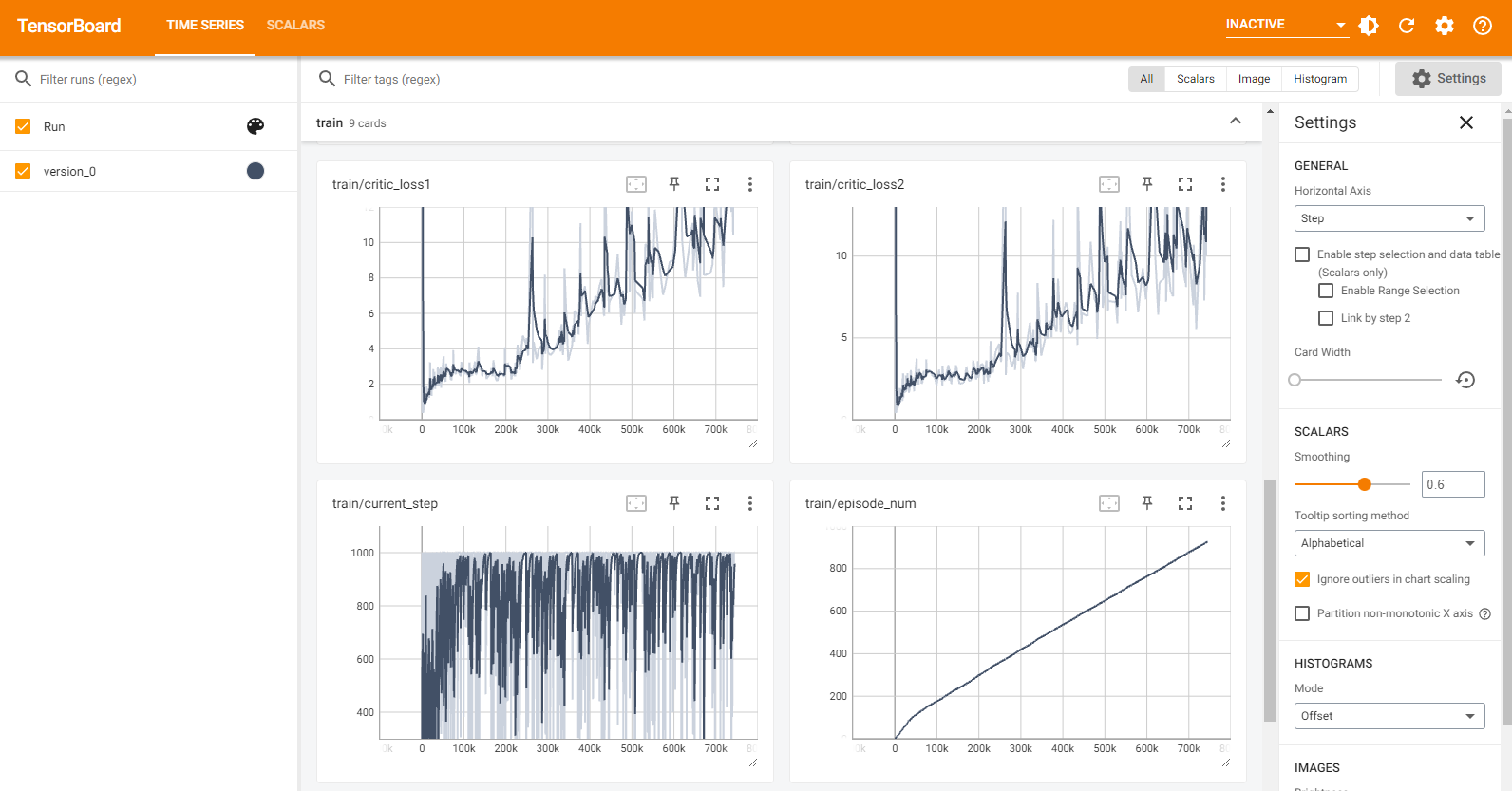
初期学習が非常にスムーズにいく場合と、ゆっくりになる場合があるので、学習が遅ければ打ち切ってやり直す方が早く終わったりします。
900エピソード程度の学習の推移(エピソードごとの報酬の推移)は以下になります。
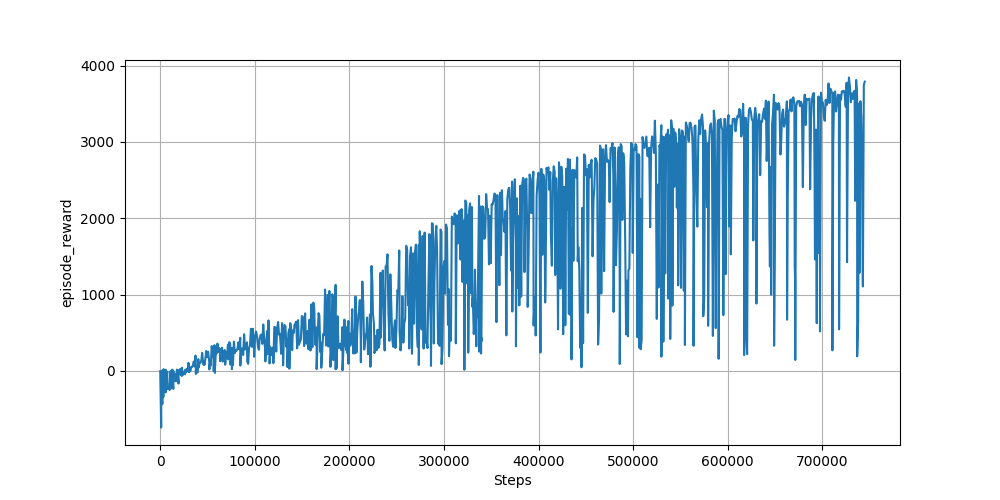
最終的にスコアは3700くらいでした。
3.2. 学習中の動画
ここから、学習中の動画を紹介します。このアリ型ロボットは画面右側に進めばスコアを獲得できます。
学習初期

ぐるぐるとランダムに動くような感じで、まったく前進していません。
200エピソード

心なしか前(画面右側)に進もうとしているように見えます。
400エピソード

かなり頑張って前に動くようになりましたが、勢い余って転倒することが多いです。
550エピソード

ときどき躓くような動きを見せながらも、端まで到達できるようになりました。
900エピソード(最終エピソード付近)
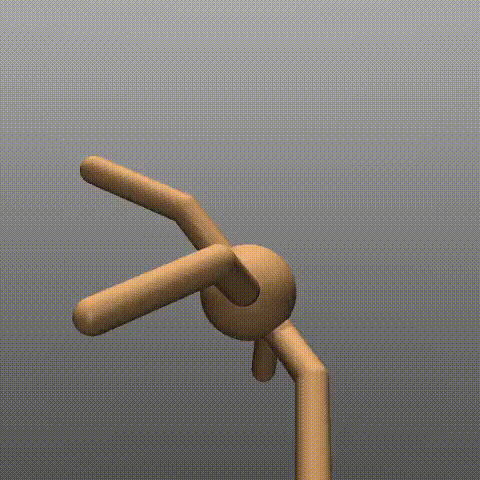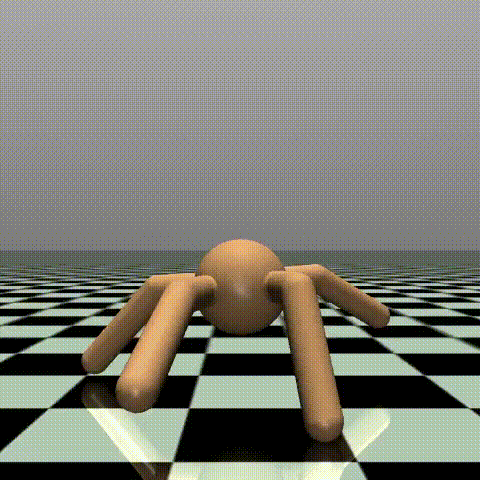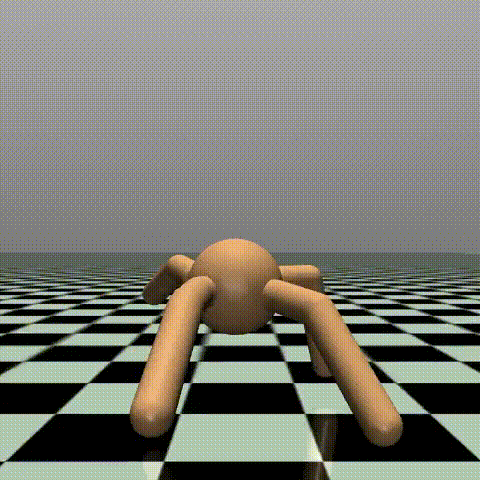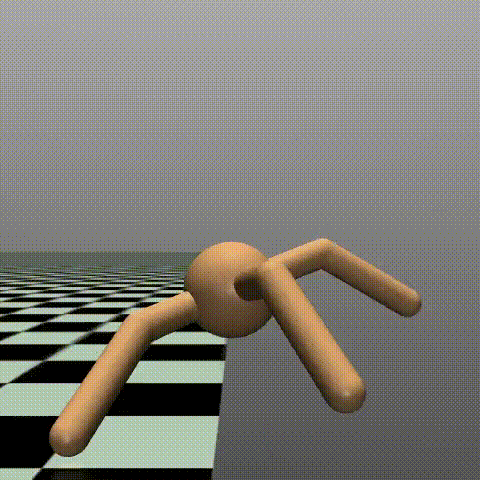
羽が生えたように力強く前進しています。端に到達する時間が、6sほど短縮されました。
実際に動きを見守っていると、だんだんと腕の使い方が変化してきたりと、見ていて面白いです。
4. 一本足の跳躍ロボット Hopper-v4 の学習を始めよう!
4.1. 学習結果
続いて、MuJoCo の別モデルであるHopper-v4モデルで学習を行います。main関数の以下の部分を、Hopper-v4に変更して実行します(パラメータはすべて同じで大丈夫でした)。
env = gym.make('Hopper-v4', render_mode="rgb_array")
1000エピソード程度を学習し、得られた学習の推移(エピソードごとの報酬の推移)は以下になります。
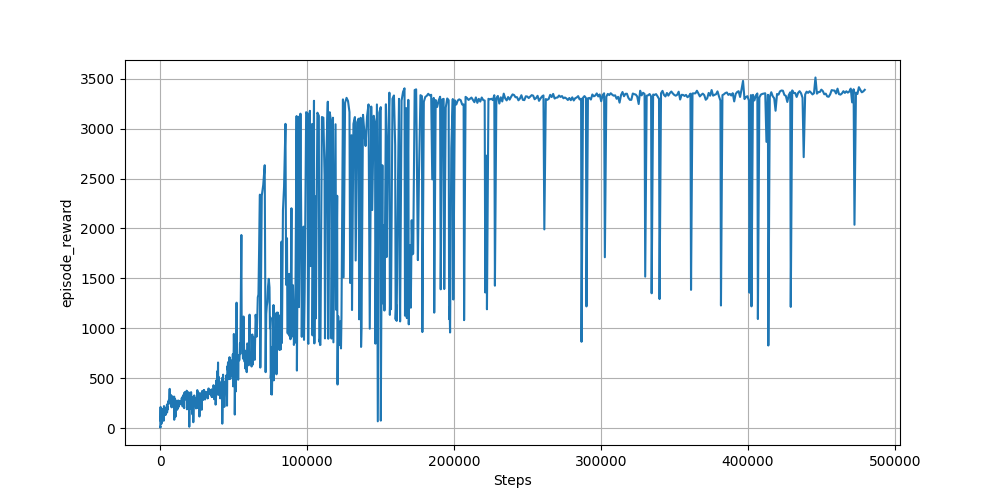
長めに学習しましたが、半分程度で打ち切っても良さそうですね。
4.2. 学習動画
学習初期

即座に体勢がくずれて、エピソードが終了しています(gif動画のため、すぐにループに入っています)。
200エピソード

相変わらずダメダメですが、若干倒れるまでに踏ん張りを見せるようになりました。
400エピソード

このあたりから、1回ジャンプできるようになりました。
550エピソード

ぴょんぴょんと複数回続けてジャンプできるようになりました(バタバタしながら最後はこけています)。
1000エピソード

700エピソードぐらいから端に到達できるようになって、最後はこんな感じです。
5. おわりに
勉強がてら記事にするかと、チャレンジしてみるとバグだらけで苦労しましたが、無事にロボットが端まで到達できるようになって満足です。
ブームが過ぎ去って今更感はありますが、次はマリオ的なものに挑戦してみたいなと思っています!