Humanity's Last Examに向けたスコアアップを目的とした、データの取り扱い
前回記事に続き、本記事では、データセットを取り扱うにあたって注意すべき点などを解説していきます。
【注意】 本記事は、コンペ参加者個人としての振り返りであり、所属機関・主催者を代表するものではありません。あくまで、私の経験や、一般的に抽象化した非同期開発の教訓として記載します。
東大松尾研 LLM開発プロジェクト2025
東大松尾研 LLM開発プロジェクト2025ではHumanity's Last Exam ( 以下、HLE ) と、Do-Not-Answerをターゲットに、オープンなベースモデルを使用した事後学習・ファインチューニングを実施してスコアを競い合うという内容でした。予選では、約1か月に渡り12チームで構成された人々が取り組みました。本コンペでは、HLEの内、マルチモーダルモデル問題を除く、テキストオンリー問題が解くターゲットとなりました。
私はCogitoチームのデータセット班にて活動し、HuggingFaceのデータセットを学習用にクリーンナップ加工する作業を主に担当しました。
コンペルール
本コンペでは、使用可能なモデル一覧が存在します。また、チーム間のリソース公平性を保つため外部リソースを使用した学習・データ生成などは不可となっておりました。その中で、クローズドモデルが使用されたモデル・データセットの使用などは禁止という、現実問題でもきちんと考えなければいけない事項も考慮する必要がありました。
HLEとは
Humanity's Last Examの略で、大規模言語モデル(LLM)の高難易度なベンチマークです。
https://lastexam.ai/
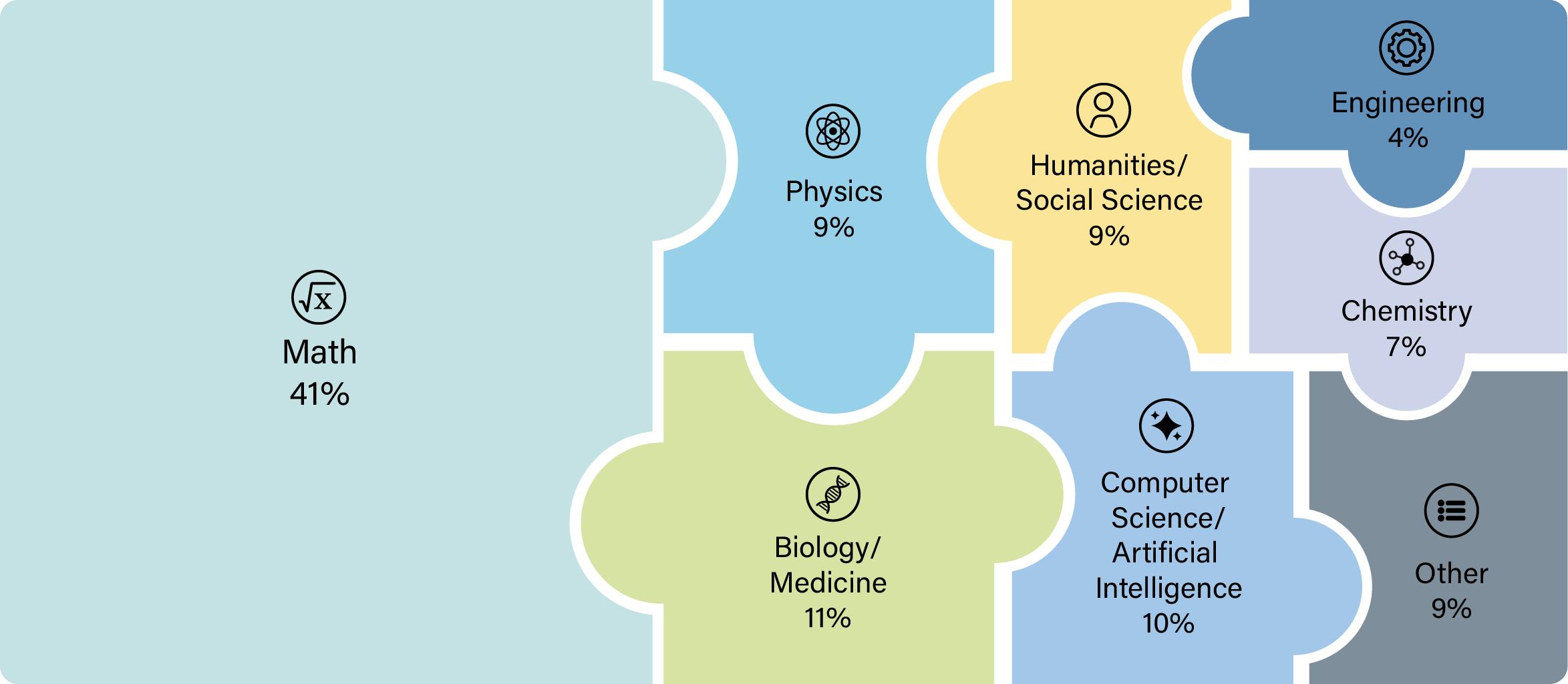
下記画像のような問題分布で構成される2500問近くのデータセットとなります。
今回、Cogitoチームで使用したベースモデルは下記になります。
学習ベースとなったモデル
DeepSeek-R1-0528-Distill-Qwen32B↓
最終的に提出となったモデル
DeepSeek-R1-0528
上記モデルに対して、スコア向上に貢献できるデータセットの作成・発見が急務となりました。コンペ期間は約1か月。学習に後半2週間提供リソースを使うと考えると、どんなに遅くても2週間。土日しか活動できないデータセット班の人の場合、実質3,4日以内でデータセットを用意しなければいけない状況となっていました。
求められるデータセット内容
HLEの問題は特に難しく、大学院レベルの数学問題などが多数含まれています(英語)。分野外の人には、問題文に出てくる単語の意味すら分からない状態でした。問題の分布では数学が主である点と、数学ができれば他の分野も理論的に考えられるのではという予測の下、数学をメインとしたものを探す事をメインとしました。
探すべきデータセット
- 使用するモデルが世に出た以降のデータセット
- 難易度が高い物 (HLE向け
結論としては、期間内に見つけられたHuggingFace上のデータセットでは、該当するようなデータがなかなか見つからず、スコア向上に至らないデータが大多数を占めてしまいました。
(※ あくまで今回の場合であることに注意)
データセット探しの旅
私の場合の探し方は、出社や就寝前にClaude(Pro)やPerplexity(Free)、また、genspark(Free)などにDeepResearchでデータセット探しタスクを与えておりました。その後、昼間や休憩時間にHuggingFaceでのデータセット一覧から、最新のものを順に探していく。という事を、実施しておりました。
そこそこの量のデータセットは見つかりましたが、それらの内でも実際にスコア向上に寄与する物は少なく、非常に難しいタスクであると感じておりました。
また、thinkモデルとして使えるthinkの部分が無い物も多く、のちに合成データで生成する必要があるものも多数見つかっておりました。
データセット合成について
最初からデータ合成によるデータセット作成も考えられましたが、中盤からの戦略変更などもあり、3ノードを学習で占める必要が出てきたり、DeepSeek-R1-0528やQwen3-235B-A22Bといったモデルすでに作られているデータなども見つかったため、弊チームのデータセット班では、GPUリソースを使ってデータセット合成をする事はほとんどありませんでした。(一部生成、未使用)
以降では、HuggingFaceのデータセットで直面した問題について記載します。
HuggingFaceデータセット
HuggingFaceのデータセット。
と言うよりは、既存のデータセットを使用する場合に当てはまるかと思われます。
メリット
- 作成のためのリソース・時間が削減できる
デメリット
- データとしてはおかしいものも存在する
- ライセンスに注意する必要がある
- 更新されたり、削除される可能性がある
- 他のチームも使う
データ合成のためのGPUリソースが不要になる一方、注意深く見ないと上記の問題に出会って、全てが台無しになる可能性があります。
データとしておかしいもの
何をもって おかしい と定義するか次第ですが、大手が作ったから大丈夫だろうと、内容を精査せずにそのまま使用すると違和感があるようなデータもあります。
Ahaモーメントのためか、誤った知識が入り込んだり、長すぎる思考が入ってきたりする事もありました。
- 欠損値、異常値がある
- 推論がブランク
- "n/a"などの文字がある
- 思考が無限ループしている
などがあったりもします。
今回は特に難易度が高い物を英語で大量に集める必要があったため、全てを人の目で見ることは非現実的でした。
データ加工
そのため、上記内容のクリーニング処理に加え、
- 学習用に以上に長いデータを省く
- 難易度カテゴリーがある場合は、高難易度をフィルターする
などの加工処理を実施しておりました。
HugginFaceのDataset Viewerの表示上のズレ
HuggingFaceの無料プランでは容量制限があるため、制限を気にせずアップロードするためにはpublicとしてデータを公開しておく必要が有ります。ただし、public設定又は、private設定でも有料プランである場合は、Dataset Viewerが使えるようになるため、簡単にデータを閲覧する事ができます。
私は、python環境を用意できないような状況や、簡単な目視チェックに使えるため、便利だと思って使うようにしていましたが、ここで一つトラップ?がありました。
ここでは、全ジャンルのスコア向上に貢献した
open-thoughts/OpenThoughts3-1.2M を参考に見てみます。
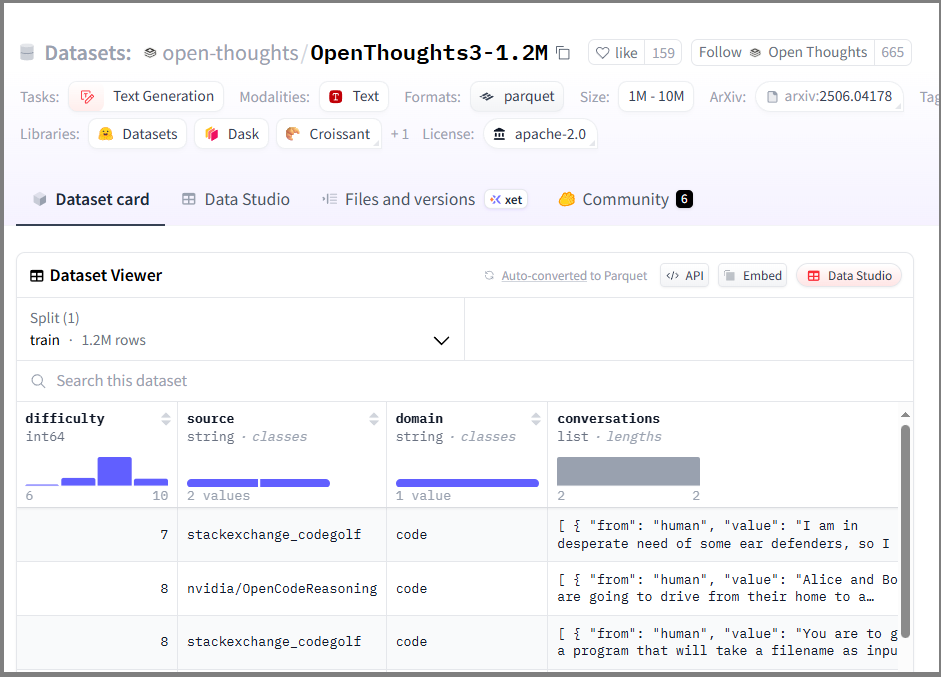
データセットURLを開いた状態で表示されるDataset Viewerを見ると、domainの中にcodeがあり、1 value ( 100%表示 )となっています。このため、このデータセットにはコードのデータのみが存在するという認識でした。
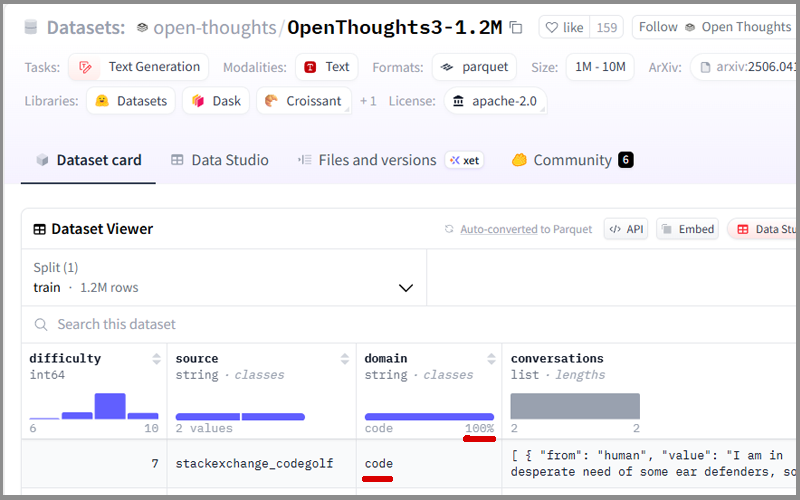
しかし、最後までページネーション ( Last側のデータを表示 ) してみると。
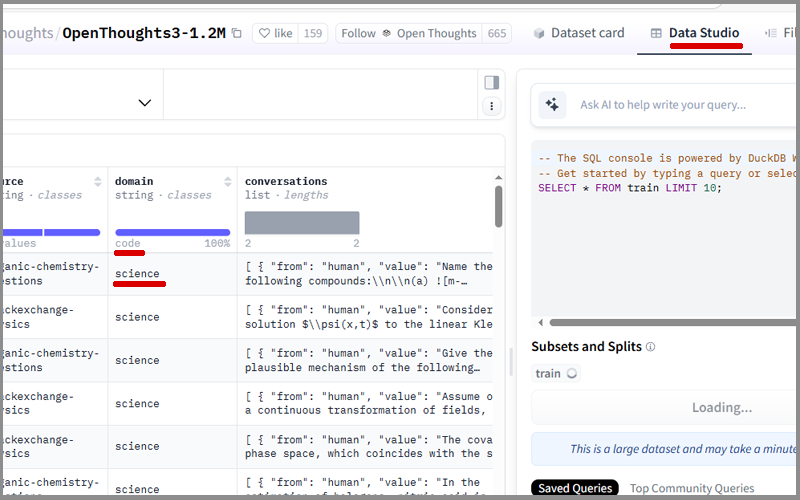
domain列として表示されているのはcodeなのに、実際に表示されているものはscienceという状態でした。
これは、予選終了するまで気づくことが出来ませんでした。
データセットビューワーのみで確認した事による失敗
データ量が28.2GBと多くて細かく見れておらず、Dataset Viewerの方を信じてしまっていたため、
1.diffuculty9を取り出す処理
2.conversations列からそれぞれquestion, thought, answerを取り除く処理
など、その他の処理にばかりに気を取られ、domain列をおろそかにしてしまいました。
その結果、 codeのデータしか抽出してないのにDeepSeek-R1-0528-Distill-Qwen32Bでは全てのジャンルでのスコアが向上した。これは、thinkが長くなるようなSFTになればスコアが上がるのではないか。 と、いう思考に至ってしまいました。
Datas dard, Data Studio, 元データで見え方が違う
どの内容が正しいのかは、元データを見る必要がありますが、ブラウザー上ではHuggingFaceが推奨するparquet形式だとコードを動かさないと内容が確認できません。そのような状況を考え、データ形式をjsonファイルにしてアップロードし、rawデータを見る事でpython環境がない状態でも(例:スマホやタブレット)確認する事ができる状態にした方がよいと考えてしまってました。
が、上記のような問題もあったり、エスケープ処理か?、【"】文字が非非常になったりなどの問題もあったため、データ内容確認は確実に元データを見た方が良かったと感じております。
モデルカード上のライセンスと、提示論文内のズレ (Data Studio
本データセットでは、Lisenceタグがapache-2.0になっており、Githubの方でもapache-2.0、そして、HuggingFaceのCommunityを見てもライセンスでのissueが特になかったので問題は無いと認識しておりました。しかし、添付の論文内にてクローズドモデルの使用の記載があり、今回のコンペでは使ってはいけないデータに該当する。というやらかしをやってしまっていました。
https://arxiv.org/abs/2410.07985
( ※ ただし、途中でモデルを変更し、このデータでは学習までいけなかったため、学習には使用しておりません。 )
その他、ほとんどのチーム(12チーム内、10チームが該当)でも、論文内ではクローズドモデルが使用されていたためNGだった等。という、事態に陥っておりました。(ただし、同じく学習には使ってない(使えなかった)物が多い。)
以上、既存のデータセットを使用する場合は、GPUリソースなどが不要になる分、 内容自体を精査する事の労力は必ず忘れず にする。という反省点がありました。
PS.
他のチームでも、使用したデータセットは被る物が多く、その場合にデータセット班としては、クリーニング処理などでスコアの差を出すしか無かったような気がします。HLEのスコアアップに使えるような高難易度・高品質なデータでオープンに公開されている物はなかなか見つけられず、データセット作成はやっぱり難しい。というのが今回の感想です。
プロジェクトのクレジット
本プロジェクトは、国立研究開発法人新エネルギー・産業技術総合開発機構(以下「NEDO」)の「日本語版医療特化型LLMの社会実装に向けた安全性検証・実証」における基盤モデルの開発プロジェクトの一環として行われます。