概要
入門書の知識習得を終えたOracle DBエンジニア向けに、知識を一歩深めるために、実機で試せるフルスキャン、インデックススキャン、パーティションフルスキャンの効果確認になります。
内容としては、以下三点を確認する内容となっています。
・1件検索でフルスキャンとインデックススキャンの検索速度の比較→インデックススキャンの速さを確認する
・25%の範囲検索でフルスキャンとインデックススキャンの検索速度の比較→フルスキャンの方が速くなる分岐点のあたりを確認する
・25%の範囲検索をパーティション表に対して実施することで表のフルスキャンよりパーティションフルスキャンが速くなることを確認する
準備
--sysで作成
create user test identified by WElcome12345##;
grant connect,resource,dba to test;
ALTER USER test quota unlimited on USERS;
--testユーザーで接続してから
CREATE TABLE sales_np (
id NUMBER NOT NULL,
pad VARCHAR2(100)
);
/* 2000万件のテストテーブル作成。PGA不足になった
INSERT /*+ APPEND */ INTO sales_np (id, pad)
SELECT LEVEL AS id,
RPAD('x', 100, 'x') AS pad
FROM dual
CONNECT BY LEVEL <= 20000000;
*/
--上記がPGA不足になるため、どうすればいいかChatGPTに聞いたらでてきた技。別の機会に解説したい
INSERT /*+ APPEND */ INTO sales_np(id, pad)
SELECT ((a.l-1)*10000 + (b.l-1)*10 + c.l) AS id,
RPAD('x',100,'x') AS pad
FROM (SELECT LEVEL l FROM dual CONNECT BY LEVEL <= 2000) a
CROSS JOIN (SELECT LEVEL l FROM dual CONNECT BY LEVEL <= 1000) b
CROSS JOIN (SELECT LEVEL l FROM dual CONNECT BY LEVEL <= 10) c;
commit;
exec DBMS_STATS.GATHER_TABLE_STATS('TEST', 'SALES_NP');
1件検索でのフルスキャンとインデックススキャンの比較
--1件検索 キャッシュはクリアして実行しています(以下このことわりは省略)。
select count(*) from sales_np where id = 1;
--実行時間:4.325秒
--インデックスつけるとどうなるか
CREATE INDEX sales_np_ind ON sales_np(id);
--1件検索
select count(*) from sales_np where id = 1;
--実行時間:0.018秒
SQLは何も変えず、インデックスをつけただけでこれほどの高速化を実現できる。これがインデックスの威力。
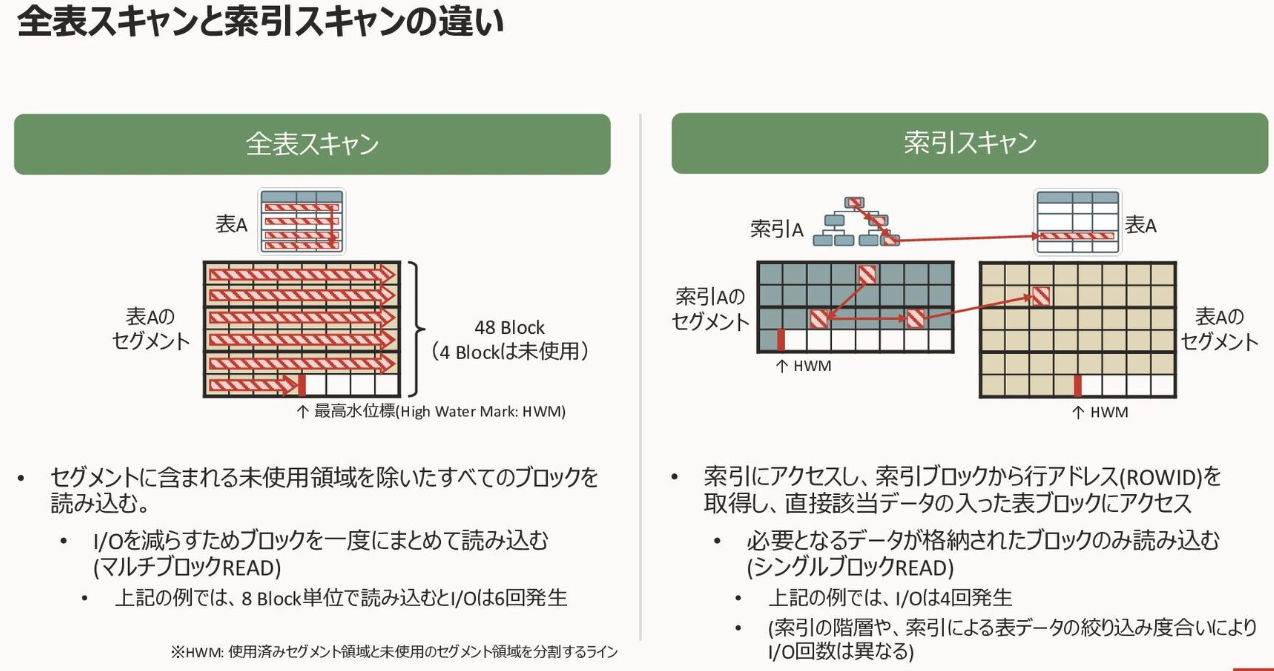
インデックスの凄さは、とってきてから絞るFILTER形式ではなく、必要なところのみアクセスし、そもそもとってくるデータが極少というアプローチであること。また、必要な部分を割り出す計算コストも木構造をたどるだけなので少ない。データ量が増えてもスキャンの性能劣化の度合いが小さい、というところです。
検索範囲を広げたときのインデックススキャンの性能劣化
インデックススキャンの速度は検索範囲が広がっていくほど劣化していく。インデックスのキーから該当ブロックの読み出しはランダムアクセスになるため、数が多くなると性能劣化が顕著になってくる。
一方、フルスキャンの方はmulti block readという複数ブロックをまとめて読む機能を備えているため、テーブル全件読むといっても高速化の工夫が効いています。
インデックススキャンがフルスキャンより遅くなるのは、感覚知として、テーブルの10から20%を超える範囲検索になるとき、とよく言われています。
--10%検索 インデックススキャンの場合 1.956秒 キャッシュはクリアしながら実施しています
select /*+ INDEX(a sales_np_ind) */ count(*)
from sales_np a
where id between 1 and 2000000;
--実行時間:1.956秒
--10%検索 フルスキャンの場合 4.579秒 キャッシュはクリアしながら実施しています。
select /*+ FULL(a) */ count(*)
from sales_np a
where id between 1 and 2000000;
--実行時間:4.579秒
--今回は10%程度の範囲検索では、まだインデックススキャンの方が早い。
--25%検索に変えて実施
--25%検索 インデックススキャンの場合
select /*+ INDEX(a sales_np_ind) */ count(*)
from sales_np a
where id between 1 and 5000000;
--実行時間:4.96秒
--25%検索 フルスキャンの場合。4.593秒
select /*+ FULL(a) */ count(*)
from sales_np a
where id between 1 and 5000000;
--実行時間:4.593秒
--インデックススキャンより速くなった。
今回のインデックススキャンとフルスキャンの速度が逆転する閾値は20-25%くらいのところにありそうでした。
この閾値の実際については、インデックスのリーフ内での隣のキーの宛先が同じブロックに入っているか(クラスタ化係数)が大きく効いてきます。
例えば、インデックスキーに対してソート済みでインサートされた表の場合は、インデックスのリーフ内での隣のキーは同じブロックに入っている率が高く、インデックスの範囲検索が高速になります。
逆に、インデックス作成列へのデータの入り方がランダムで、インデックスのリーフ内での隣のキーが別のブロックをさすような割合が多くなってくると、インデックスの範囲検索は遅くなります。この場合、フルスキャンの方が高速になる閾値が20-25%よりもっと早い段階で現れることもありえます。
パーティション表によるフルスキャンの高速化
検索対象が広く、インデックススキャンよりフルスキャンの方が高速になった場合は、フルスキャンの速度以上の高速化は見込めないかというと、代表的な高速化の方法としてパーティション表を使うという手があります。
パーティションは、表のデータを別々の領域に分割して持つことができる技術ですが、ルールに従ってそれぞれの領域にデータを寄せることができます。パーティション1には2025年1月、パーティション1には2025年2月のデータを集める、といった感じです。
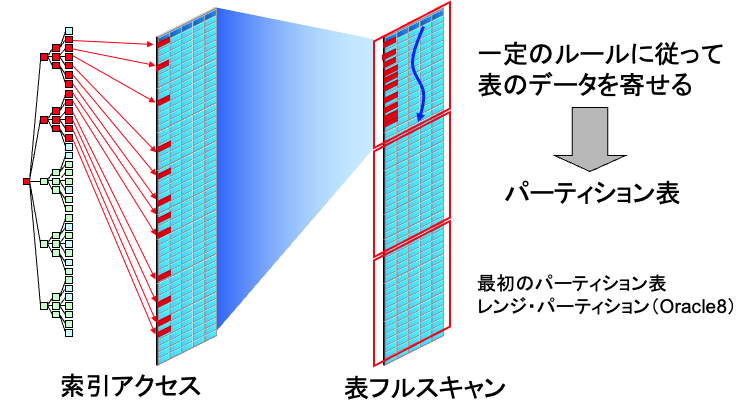
こちらは、昔のOracle Direct Seminarの、著者登場!これは使えるOracle新機能活用術-パーティション表編-というスライドの画像です。今は残念ながらリンク切れで見ることができません。
--パーティション数は100になるように作成
CREATE TABLE sales_p (
id NUMBER NOT NULL,
pad VARCHAR2(100)
)
PARTITION BY RANGE (id) INTERVAL (200000)
(
PARTITION p000000 VALUES LESS THAN (200001)
);
INSERT /*+ APPEND */ INTO sales_p
SELECT * FROM sales_np;
--500万件
--25%検索 インデックススキャンの場合 4.96秒
--25%検索 フルスキャンの場合。4.593秒
--25%検索 パーティションフルスキャンの場合。1.318秒 フルスキャンより速くなった。
select /*+ FULL(a) */ count(*)
from sales_p a
where id between 1 and 5000000;
このようにパーティションを利用するとインデックススキャンでカバーできない高速化を実現することができます。
考察として、パーティション数について数を多めに設定しとけばいいのかという話をします。
パーティションの数について、分割数が大きい方(月次より週次、週次より日時など)が、幅広く対応できて便利なので、多めに設定したいところです。
しかし、多くしすぎると、ディクショナリのメタデータが増えメモリを多く必要になってしまう、ディクショナリ・ビューの検索が遅くなる、起動が遅くなるなどのデメリットが発生します。
https://speakerdeck.com/oracle4engineer/technology-night78-oracle-partitioning?slide=32
そのため、不要に多くしすぎないことが大事です。特にハッシュサブパーティションを作る時は簡単にパーティションの数が増えがちなので気をつけたいところです。
パーティションの数の決め方の例としては、例えば、レンジパーティションだった場合、パーティション・キーのDATEの列に対して3年分保持するルールなので、これなら365 * 3 = 1095個くらいなら日次レンジパーティションを採用しても数的にはそれほどインパクトはなさそう。この表は、データ量も多いし、日次検索も多い。日次を週次に変えてしまうと性能要件が厳しくなる。それならこの表は日次パーティションにするか、といった感じです。
もちろん、ストレージ性能が高く、日次検索の速度で達成したい速度が、週次の粒度のパーティションで達成できるのなら、週次パーティションにしておくという判断もありかと思います。