目的
Apache SparkのWebUIはアプリケーションのデバッグにとても役立ちます。
デバッグのため、このWeb UIを使って本番環境で取得したログを検証環境で確認したいことがあります。
取得したイベントのログをSparkのHistory Serverに渡すことで、本番環境のイベントログを手元の環境で見ることができて便利です。(Thanks! @kmizumar)
今回はCDH5.7の環境で検証しました。
(2016/7/20 Clouderaのライセンスによりログが取得できないため一部記載を変更)
環境
- Spark 1.6
- CDH5.7
- Cloudera Manager 5.7
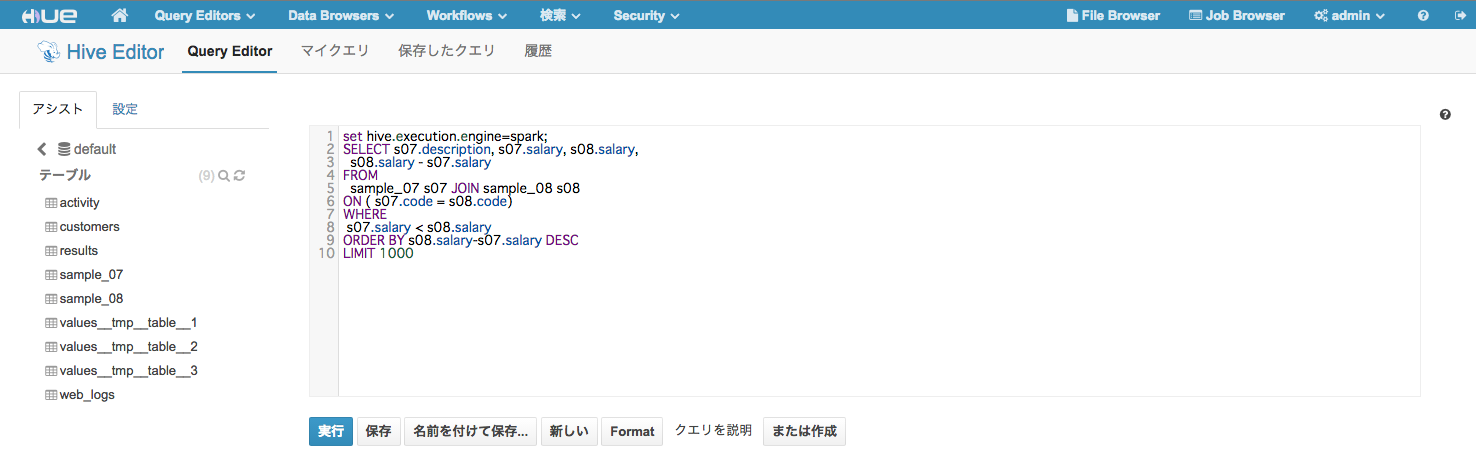
HueからHive on Sparkでクエリを実行
今回Sparkを実行したのはCloudera Manager5.7で構築したYARNの環境です。HiveをSpark上で実行するために、HueのHiveクエリエディタからクエリの実行前に以下のオプションを指定します。
set hive.execution.engine=spark
Sparkのイベントログを収集 (Cloudera Enterprise ライセンスがある場合)
Cloudera Enteprise ライセンスがある場合、Cloudera ManagerのUIからイベントログを収集できます。(ライセンスがない場合はイベントログを直接コピーします。手順は後述)
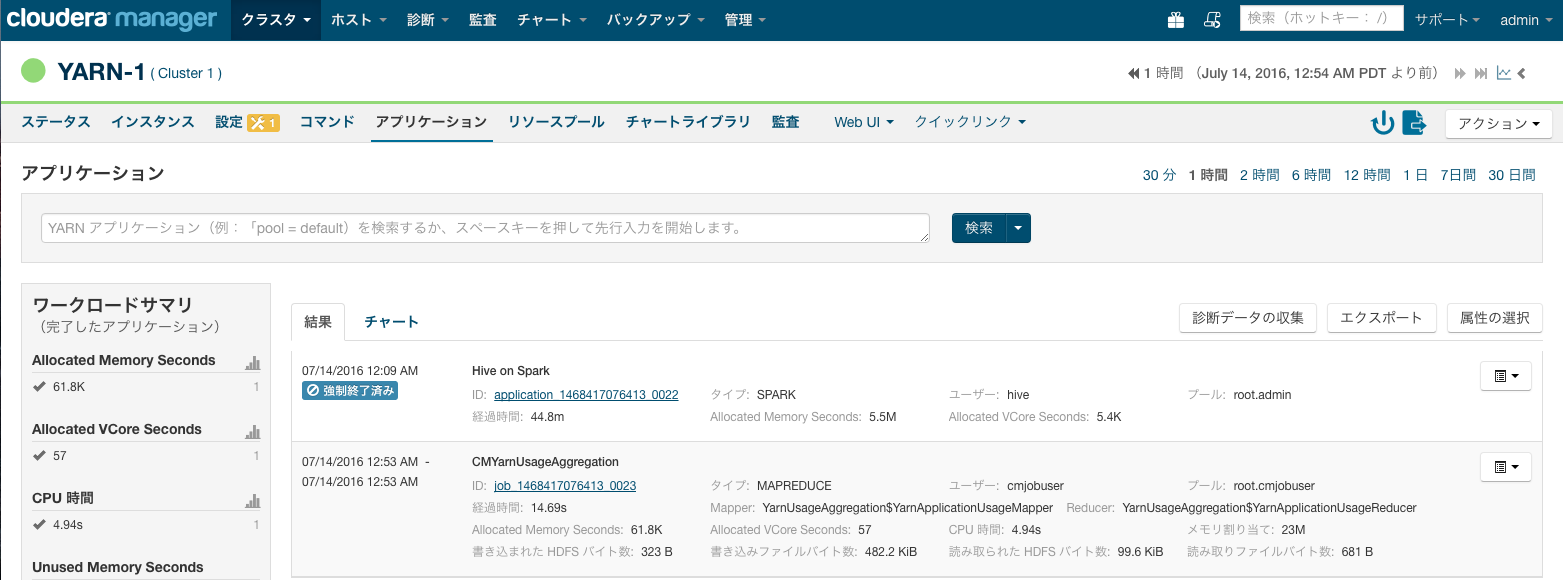
Cloudera ManagerでYARNのアプリケーションを表示
Cloudera Managerでは、クラスタで実行された、YARN(MapReduceやSpark)やImpalaアプリケーションの履歴が一覧ができます。以下のスクリーショットはYARNで実行されたアプリケーションを表示しています。
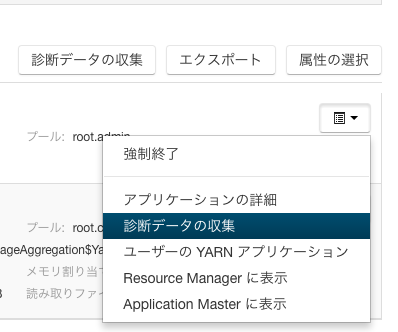
アプリケーションの診断データを収集
先ほど実行したHive on Spark(Sparkアプリケーション)の診断データを右側のメニューから取得します。
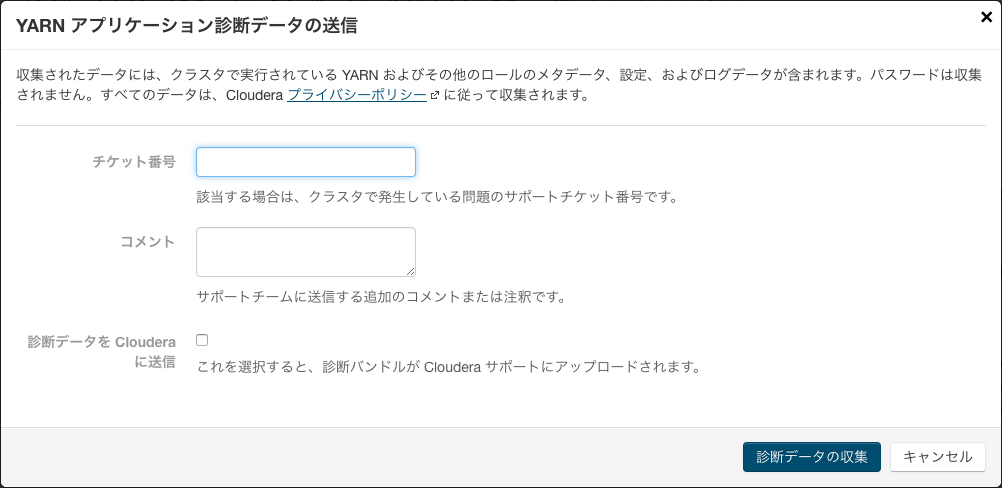
Clouderaのサブスクリプションを契約している場合はサポートに診断データを送ることもできますが、今回は「診断データの収集」ボタンをクリックしてダウンロードしました。「結果データのダウンロード」ボタンを押して各診断情報やメタデータがアーカイブされダウンロードします。
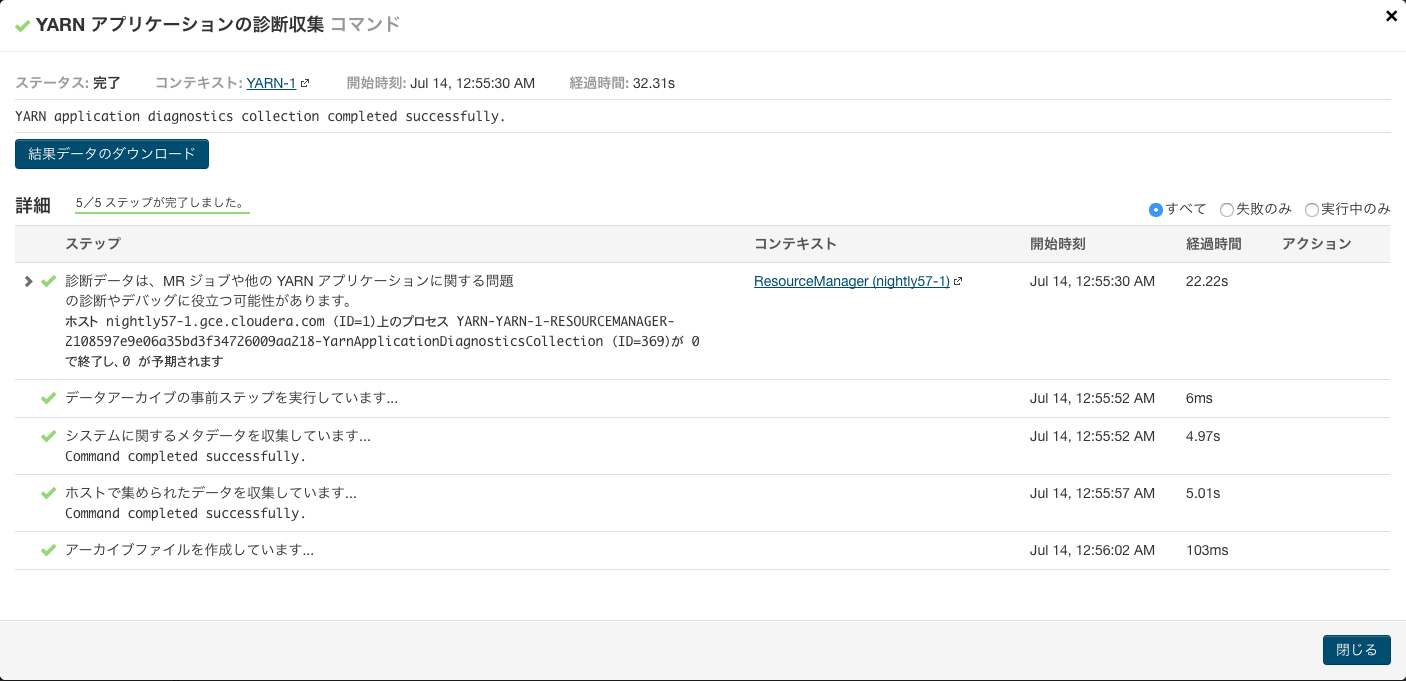
ダウンロードされたのは次のファイルです。
12c8052f-d78f-4a8e-bba4-a55a2d141fcc.default.20160714-07-56-02.support-bundle.zip
ローカル環境で表示する
ダウンロードデータをSparkの検証環境にアップロード
ダウンロードしたデータをローカルのSpark環境にアップロードし、中身を見てみましょう。
[kawasaki@localhost Desktop]$ unzip -l 12c8052f-d78f-4a8e-bba4-a55a2d141fcc.default.20160714-07-56-02.support-bundle.zip
Archive: 12c8052f-d78f-4a8e-bba4-a55a2d141fcc.default.20160714-07-56-02.support-bundle.zip
Length Date Time Name
--------- ---------- ----- ----
485 07-14-2016 00:56 arguments.json
198309 07-14-2016 00:56 YarnApplicationDiagnosticsCollection-1802.tgz
179 07-14-2016 00:56 cm_version.json
62158 07-14-2016 00:56 cm_http_instrumentation.json
53 07-14-2016 00:56 bundle-meta.json
1 07-14-2016 00:56 ticket_number.txt
158 07-14-2016 00:56 license.json
630 07-14-2016 00:56 performance-data.json
80 07-14-2016 00:56 trial_status.json
2176204 07-14-2016 00:56 scm-cluster-description.json
207009 07-14-2016 00:56 cm_deployment.json
1 07-14-2016 00:56 comments.txt
--------- -------
2645267 12 files
[kawasaki@localhost Desktop]$
zipファイルを展開
[kawasaki@localhost Desktop]$ unzip 12c8052f-d78f-4a8e-bba4-a55a2d141fcc.default.20160714-07-56-02.support-bundle.zip
Archive: 12c8052f-d78f-4a8e-bba4-a55a2d141fcc.default.20160714-07-56-02.support-bundle.zip
inflating: arguments.json
inflating: YarnApplicationDiagnosticsCollection-1802.tgz
inflating: cm_version.json
inflating: cm_http_instrumentation.json
inflating: bundle-meta.json
inflating: ticket_number.txt
inflating: license.json
inflating: performance-data.json
inflating: trial_status.json
inflating: scm-cluster-description.json
inflating: cm_deployment.json
inflating: comments.txt
[kawasaki@localhost Desktop]$
ここで展開されたファイルのうち、YarnApplication*.tgzファイルにイベントログが含まれています。(それ以外の情報はCloudera Managerのメタデータなどです)。tgzファイルを展開しましょう。
[kawasaki@localhost Desktop]$ tar xvf YarnApplicationDiagnosticsCollection-1802.tgz
diagnostics/
diagnostics/command.log
diagnostics/layout_version.txt
diagnostics/application_1468417076413_0022/
diagnostics/application_1468417076413_0022/spark_event_logs.zip
diagnostics/application_1468417076413_0022/app_info.json
diagnostics/application_1468417076413_0022/app_attempts.json
diagnostics/application_1468417076413_0022/aggregated_logs/
diagnostics/application_1468417076413_0022/aggregated_logs/application_1468417076413_0022/
diagnostics/application_1468417076413_0022/aggregated_logs/application_1468417076413_0022/nightly57-3.gce.cloudera.com_8041
diagnostics/application_1468417076413_0022/aggregated_logs/application_1468417076413_0022/nightly57-4.gce.cloudera.com_8041
[kawasaki@localhost Desktop]$
ここで展開されたspark_event_logs.zipがイベントログです。zipファイルを展開しましょう。
[kawasaki@localhost Desktop]$ unzip diagnostics/application_1468417076413_0022/spark_event_logs.zip
Archive: diagnostics/application_1468417076413_0022/spark_event_logs.zip
inflating: application_1468417076413_0022_1
[kawasaki@localhost Desktop]$
イベントログをSpark History Serverのログディレクトリにアップロード
展開したファイルをSpark History Serverにアップロードしましょう。アップロード先はspark.history.fs.logDirectoryプロパティで指定され、今回の環境ではhdfs://localhost:8020/user/spark/applicationHistoryになっています。
[kawasaki@localhost Desktop]$ hdfs dfs -put diagnostics/application_146841 /user/spark/applicationHistory
application_1468416381293_0021/ application_1468417076413_0022/
Sparkのイベントログを収集 (Cloudera Managerを使わない場合)
Cloudera Managerを使わない場合は、イベントログファイルを取得してHistory Serverにアップロードします。設定に依存しますが、イベントログはhdfs://:8020/user/spark/applicationHistory 以下に生成されてます。
Sparkのジョブを実行した環境でログをダウンロードします。
[kawasaki@hoge Desktop]$ hdfs dfs -ls /user/spark/applicationHistory
Found 1 items
-rwxrwx-- 1 kawasaki spark 716000 2016-07-19 15:50 /user/spark/applicationHistory/application_1468417076413_0022
[kawasaki@hoge Desktop]$ hdfs dfs -get /user/spark/applicationHistory/application_1468417076413_0022
[kawasaki@hoge Desktop]$
ダウンロードしたファイルをアップロードします。
[kawasaki@localhost Desktop]$ hdfs dfs -put
application_1468416381293_0022 /user/spark/applicationHistory
Spark History ServerのWebUIで表示
http://:にアクセスして表示します。ローカルで取得したのと同様に表示できますね!Enjoy!



参考情報
If Spark is run on Mesos or YARN, it is still possible to reconstruct the UI of a finished application through Spark’s history server, provided that the application’s event logs exist. You can start the history server by executing: