-
以下のようなファイル名を持つ固定長データがあるとする:data_H22.txt, data_H23.txt, ...,data_H30.txt, data_R01.txt
-
各変数の長さ(width)と変数名は別のCSVファイル(varname_H22.csv, ...)で定義されている
-
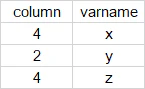
例えば 固定長データの1行目が「xxxyyzzzz...」となっているとすると、最初の4文字が変数x、次の2文字が変数y、次の4文字が変数zといった具合。この場合、varname_*.csvは以下のような中身。
-
以下のRコードは、これらの固定長データを連続で読み込み、Stataデータ形式で出力するものである。
txt2data.R
# install.packages("haven", dependencies = TRUE) # install package if necessary
# install.packages("tidyverse")
library(tidyverse)
library(haven)
setwd("C:/Users/CurrentDirectory")
primes_list <- list("H22", "H23", "H24", "H25", "H26", "H27", "H28", "H29", "H30", "R01")
for (y in primes_list) {
datafilename.input <- paste("data_", y, ".txt", sep = "") # filename: data_*.txt
varfilename <- paste("varname_", y, ".csv", sep = "") # filename: varname_*.txt
d.varname <- read.csv(varfilename) # import varname file
width <- d.varname$column # vector of width
varname <- d.varname$varname # vector of variable name
data <- read.fwf(datafilename.input, width = width, col.names = varname) # import data
# readrパッケージを使う場合
# d <- read_fwf(datafilename.input, fwf_widths(width, col_names = varname)) # import data
datafilename.output <- paste("data_", p, ".dta", sep = "") # filename: data_*.dta
write_dta(data, datafilename.output) # export as .dta file
}