機械学習をどう学んだか by 日経 xTECH ビジネスAI② Advent Calendar 2019 1日目の記事です。今日は @kenmatsu4 が機械学習をどうやって学んできたか、有用だった本の紹介をまじえて解説してみたいと思います。初のポエム記事ですw
こちらは日経 xTECHさん企画のAdvent Calendarですが、ちなみに実はワタクシ @kenmatsu4 はAI道場「Kaggle」の正体 AI道場「Kaggle」の衝撃、DeNAが人材採用の特別枠を設けた訳 の中の人だったりもします![]()
1. 学生時代
大学では経済学部に所属していまして、統計学の先生の下で勉強しました。もう15年以上前ですw 当時データサイエンスという言葉は当然なかったですが、今、データサイエンティストとして働いているのはやはりこの時期にデータ分析に携われたおかげです。文系だったので、数学は独学で勉強しましたが、下記の教科書等がとても役に立ちました。
数学(解析)
ラング解析入門(ラング): https://www.amazon.co.jp/dp/4000051512/
続:ラング解析入門(ラング): http://amazon.co.jp/dp/4000051687/
高校数学の復習から、大学教養レベルの数学、「続」の方では多変数まで扱われています。イチから丁寧に解説されているので、独学の最初の一冊としては非常におすすめです。
数学(線形代数)
線型代数(長谷川 浩司): https://www.amazon.co.jp//dp/4535787719
2x2の行列の話から始まり、こちらも非常にわかりやすく線形代数を独学で学ぶことができます。
統計学
工科系のための統計概論(ガットマン、ウィルクス): https://www.amazon.co.jp/dp/4563008168
なかなか古くて絶版なのですが(中古で安く買えるようではあります)、何冊か読んだ統計学の本の中では一番好きな本です。例と数式のバランスが絶妙で、使う意味もわかるし、きちんと数式でも説明してくれている印象があります。
確率
入門確率過程(松原望): https://www.amazon.co.jp/dp/4489006594
確率の本というより、確率過程の本なのですが、前半の通常の確率に関する章が当時の僕にはレベル感があって非常にすんなり理解できて役に立ちました。
経済数学
経済数学早わかり(西村和雄): https://www.amazon.co.jp/dp/4535572755/
意外と良いのが経済数学の本です。条件付き最適化をラグランジュの未定乗数法で解く、とか意外と後々役立ちました。
ノンパラ回帰
みんなのためのノンパラメトリック回帰 上(竹澤 邦夫): https://www.amazon.co.jp/dp/4842703393
卒論では、年金制度の世代別分析を経済モデルを使ってシミュレーションしてみるといったテーマで書きました。そのなかでカーネル回帰を使って非線形の賃金カーブの回帰曲線を推定し経済シミュレーションのパラメータ推定利用したのですが、この本のナダラヤ=ワトソン回帰にはお世話になりました。実はこのナダラヤ=ワトソン、その十数年後にPRMLの下巻を読んでいたところで再会し、懐かしく思いつつも今とあんまりやっていることが実は変わらないなぁと思いましたね。
2. ソフトウェアエンジニア時代
大学を卒業して新卒でSIerに就職しました。割とプログラミングをしっかりとやる会社でしたので、webアプリから携帯電話の組み込みソフトまで色々やりました。プログラマとして最初に読んだ下記の本でプログラミングやコンピュータの基本的な考え方を身につけ、今でも活きていると思います。(この辺りは古めの本が多いので、今ではもっと良い本があるかも?)
コンピュータはなぜ動くのか~知っておきたいハードウエア&ソフトウエアの基礎知識~ 矢沢 久雄: https://www.amazon.co.jp/dp/4822281655/
CPU、メモリ、ストレージがどういう役割で、コンピュータがどのように動くかの基礎知識はこの本で得られることができました。読みやすいので最初の1冊に最適だと思います。
オブジェクト指向でなぜつくるのか(平澤章): https://www.amazon.co.jp/dp/4822284654/
クラスとは何か、カプセル化、継承、ポリモーフィズムなど、オブジェクト指向の考え方がとてもわかりやすく解説されています。
3. 機械学習覚醒期
ここまでは仕事でデータ分析的なことはやっていなかったのですが、学生時代に統計学、仕事でプログラミングを覚え、実はデータサイエンスするための土台が築かれていたと思います。
そして、2015年初頭のことです。コンピュータが猫を認識したというweb記事(この記事じゃなかったけどこの話題)でDeep Learningの存在を知り、機械学習というものに初めて触れました。学生時代に身につけた確率・統計の知識を活用でき、プログラミングも使える。なにより人工知能って夢がありそうだ、と魅せられ、久々に確率や統計の本を引っ張り出したり、機械学習の本を買って読み始めました。
ただ本を読んでいてもつまらなかったので、「ブログでも書いてまとめるか」と思い立ち始めたのがこのQiitaでのブログ投稿です。最初は統計学的な話題から始め、Deep Learningについても学びながら自分が理解したことをアウトプットする場として活用しました。やはりアウトプットすることが一番勉強になったと思いますし、何より、人にも読んでもらえる嬉しさ・楽しさがあり、筆が進みました。
いままでQiitaに統計学、機械学習、Pythonのトピックを中心に書いてきまして、下記のページにその記事まとめを作りました。
今までの投稿記事のまとめ(統計学/機械学習/数学 etc)
今や記事の数も69となり、総contribution数14,403件、Follower1842人(2019年12月6日現在)とおかげさまで多くの方に読んでもらえました。ありがたいことです。
当時Qiitaに在籍していた及川さんのスライドでご紹介いただいたのですが、2016年終盤の90日で検索経由でもっとも読まれたQiita記事が僕の「【統計学】初めての「標準偏差」(統計学に挫折しないために)」だったそうです。(ありがたや)

そんなこんなでブログのアウトプットが楽しくなってしまい、機械学習も一層楽しくなってきました。そんな機械学習入門期に読んで役に立ったと思う本がこちらになります。
機械学習入門
はじめてのパターン認識(平井有三): https://www.amazon.co.jp/dp/4627849710
何と言っても最初の1冊は「はじパタ」こと初めてのパターン認識だと思います。機械学習の基礎的なことを幅広く、わかりやすく網羅されていますし、モデルの評価についても記載が充実しているところがお気に入りです。
深層学習
機械学習プロフェッショナルシリーズ 深層学習(岡谷貴之): https://www.amazon.co.jp/dp/4061529021
みなさんご存知、機械学習プロフェッショナルシリーズです。最初、本を開いたときに印刷の粗さに衝撃を受けたものの、慣れるとこれが味があって気に入ってきますw シリーズの初期にこの「深層学習」が刊行され、僕はこの本で深層学習の理論を学びましたが、いまも自分の深層学習の知識の大部分はこの本から得られたと思っています。
また、このシリーズの勉強会を昔にやっていまして、発表資料はこちらのページにまとめていますので、興味のある方はご参照ください。
ベイズ統計
データ解析のための統計モデリング入門 一般化線形モデル・階層ベイズモデル・MCMC (久保拓弥): https://www.amazon.co.jp/dp/400006973X/
通称「みどり本」ですね。ベイズ統計モデリングを学びたい場合にはやはりこの本が定番ではないでしょうか。確率分布が折り重なって構成される階層ベイズモデルをこの本知ったとき、その洗練された考え方に当時の僕は感動すら覚えました。
基礎からのベイズ統計学: ハミルトニアンモンテカルロ法による実践的入門(豊田秀樹) https://www.amazon.co.jp/dp/4254122128/
ベイズ推定の考え方、またそれを計算するためのMCMC、特にメトロポリス・ヘイスティングス法の説明のわかりやすさは、この本はピカイチだと思っています。この本の輪読会も主催させていただき、 https://stats-study.connpass.com/ には発表者の皆さんの解説スライドもあります。
異常検知
入門 機械学習による異常検知(井手 剛) https://www.amazon.co.jp/dp/4339024910
異常検知と変化検知(井手剛,杉山 将) https://www.amazon.co.jp/dp/4061529080
やはり異常検知といえば、井手さんのこの2冊です。様々な手法がここまで整理された日本語の本は他にないかと思います。また、異常検知もさることながら、前者の青本は機械学習の評価についても知見が詰まっています。
4. データサイエンティストデビュー
そうこうするうちに、転職をしてコンサルティングファームのデータサイエンティストにジョブチェンジしました。いよいよデータサイエンティストです![]()
初めてのデータサイエンティストの仕事は、「仕事でこんなに学べるんだ!」という驚きで満ち溢れていました。また、実務における機械学習というものは教科書を読むだけではわからない深くて様々な問題に直面することも多く、どこにも答えがない課題に対する答えを探して調査したり、自分の頭で仮説を考え検証していくことはとてもエキサイティングですし、非常に学びも多かったです。
この時期、特筆すべき紹介する本はあまりないのですが、この時期一番お気に入りだったのはVAEことVariational Autoencoderです。深層学習というと、行列計算の塊というようなイメージを持っていたのですが、このVAEは、そのモデルの中に確率分布を内包しており、それがさらに理論的にもとても綺麗にモデルが説明できるよう構成されており、感動を覚え、とても気に入ってしまいました。具体的には、VAEのlossは計算上、再構成誤差と、内包されている確率分布が標準正規分布になるようにカルバックライブラーダイバージェンスでロスを表現しているのですが、これは$P(X)$の対数尤度を最大化させる式からきちんと理論的に導くことができるのです。VAEを計算だけでなく、お気持ち含めてきちんと理解したいと思った僕は、割と大作のブログを書きます。
Variational Autoencoder徹底解説
このブログは自分が書いた記事のなかでも、最上位のお気に入り記事です。よければ読んでいただけると幸いいです。
5. 分析コンペデビュー
SIGNATEデビュー
2018年に重い腰をあげて、分析コンペに参加し始めました。Kaggleの存在は認識していたのですが、やり始めると非常に時間を要するという思い込みから(思い込みではなく事実なのですが・・・w)近づけずにいたのすが、日本の分析コンペサイトSIGNATEで産業技術総合研究所 衛星画像分析コンテストが開催されており、画像サイズもCIFAR-10と同じ32x32と適度な大きさで、お手頃で取り組みやすかったので軽い気持ちで参加し始めました。やり始めると、順位が良いと気分を良くしてもっと取り組みたくなり、順位が下がると悔しくてやはり頑張って精度をあげたくなる、というスパイラルに見事にハマりましたw コンピュータリソースとしてはAWSのEC2を利用していたのですが、コンペ終盤調子が上がってくると同時に、札束で実験速度を加速させてしまい25万円程度の大出費となってしまいました・・・。でも、幸いなことに2位受賞することができ、賞金もいただけたので、差し引きマイナス5万円で済ませることができました。趣味だと思えばこのくらいの出費はなんとか自分を納得させられそうですw
その時のソリューションはこちらのスライドにまとめていますのでご興味のある方は是非。
https://www.slideshare.net/matsukenbook/signate-108228406
Kagglerデビュー
初戦: Avito Demand Prediction Challenge
満を持して次はKaggleに挑戦しました。最初に挑戦したのは、Avito Demand Prediction Challengeです。このコンペは通称「三種の神器コンペ」などと呼ばれたりしましたが、テーブルデータ x 画像 x 自然言語のマルチモーダルコンペです。Avitoとはロシアのフリマサイトで、上記の3種のデータからなる出品情報から、それが落札される確率 deal_probabilityを推定します。
初Kaggleで学びがあったものの一つにoof(out of fold)という考え方があります。通常機械学習では交差検証(Cross Validation:CV)で特徴量を選択したり、ハイパーパラメータのチューニングを行なったりしますが、3-fold CVを採用した場合は3つのモデルが出来上がります。一般的な教科書ではこの場合、このモデルを実適用するときにどのように扱うか、までは言及がないと思います。Kaggleの常套手段では、この3つできたモデルをアンサンブル、よくあるパターンとしては3つのモデルの出力値を平均して使うことが採用されます。(下記図参照)このように、Kaggleでは予測モデルの実適用1つ取っても様々な集合知が集まっており、非常に勉強になると感じました。

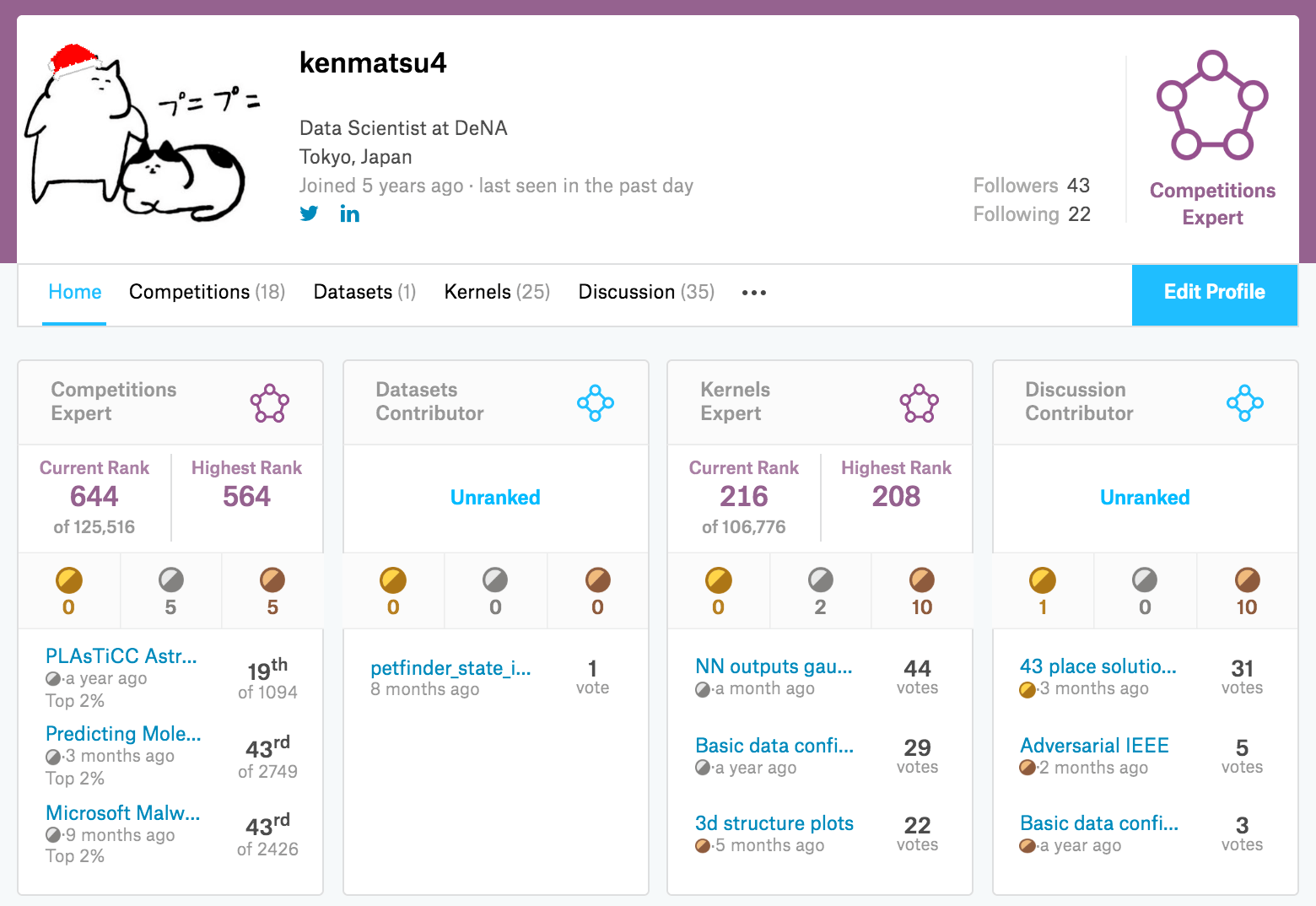
その後も様々なコンペに参加し、現時点では、5つの銀メダル(ソロ2、チーム3)、5つの銅メダル(ソロ5つ)を獲得し、Kaggle Expertとして日々Kaggleに勤しんでいます。
6. おわりに
データサイエンスの領域は学際的で、特に仕事で活用する場合は、理論的(数学的、機械学習的)な知見や、プログラミング、エンジニアリング、ビジネス知識、業務推進力など様々な要素が複合して構成されていると思います。どれか1つに特化して尖ったスキルを持つタイプの方や、満遍なくバランスよくスキルを持って活躍する方もいます。自分の興味に合わせて、楽しいと思うことから身につけていくと結果も付いてくると僕は思っています。なかでもKaggleは一度始めるとやみつきになり、予測モデル構築のスキルもつく一石二鳥の方法なのでオススメです!