GBDTで予測分布が出せると話題のNGBoostを試してみましたので、備忘録がわりに投稿します。実際に動かしてみたい方は**こちら**を参考にしてください。
所感
- modelチューニングをほぼしていない状態かつ、今回の小さいデータセットでは精度はほぼ同じ。
- 分布が算出できるのは使いどころがあるかもですね。
インポート
あとでNGBoostとLightGBMをちょっと比較するのでlightgbmもインポートしておきます。
# ngboost
from ngboost.ngboost import NGBoost
from ngboost.learners import default_tree_learner
from ngboost.scores import MLE
from ngboost.distns import Normal, LogNormal
# lightgbm
import lightgbm as lgb
# skleran
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
データの準備
回帰問題のボストンデータセットをsklearnから取ってきます。数百行の軽いデータです。ホールドアウトで検証します。
X, y = load_boston(True)
rd.seed(71)
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2)
X_train.shape, X_valid.shapae
[output]
((404, 13), (102, 13))
NGBoostの学習
インスタンス作ってfitは同じですね。予測分布を取り出すには pred_dist を使います。
%%time
rd.seed(71)
ngb = NGBoost(Base=default_tree_learner, Dist=Normal, #Normal, LogNormal
Score=MLE(), natural_gradient=True, verbose=False, )
ngb.fit(X_train, y_train, X_val=X_valid, Y_val=y_valid)
y_preds = ngb.predict(X_valid)
y_dists = ngb.pred_dist(X_valid)
# test Mean Squared Error
test_MSE = mean_squared_error(y_preds, y_valid)
print('ngb Test MSE', test_MSE)
# test Negative Log Likelihood
test_NLL = -y_dists.logpdf(y_valid.flatten()).mean()
print('ngb Test NLL', test_NLL)
[output]
ngb Test MSE 9.533862361491169
ngb Test NLL 3.8760352
CPU times: user 8.35 s, sys: 1.82 s, total: 10.2 s
Wall time: 6.27 s
比較用のLightGBMの学習
64 core CPUでぶん回したので一瞬で学習が終わります。
%%time
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_valid, y_valid, reference=lgb_train)
model = lgb.train({'objective': 'regression',
'metric': "mse",
'learning_rate': 0.01,
'seed': 71},
lgb_train,
num_boost_round=99999,
valid_sets=[lgb_valid],
early_stopping_rounds=100,
verbose_eval=500)
y_pred_lgb = model.predict(data=X_valid)
[output]
Training until validation scores don't improve for 100 rounds.
[500] valid_0's l2: 10.8615
[1000] valid_0's l2: 10.0345
[1500] valid_0's l2: 9.66004
Early stopping, best iteration is:
[1651] valid_0's l2: 9.57796
CPU times: user 3min 51s, sys: 223 ms, total: 3min 51s
Wall time: 3.62 s
精度比較
modelのチューニングはきちんとやっていません。なのでどちらが性能がいいかはわかりませんが、えいやっと使った感触ではこれくらいのデータなら遜色ないですね。
| Model | valid MSE |
|---|---|
| NGBoost | 9.53386 |
| LightGBM | 9.57796 |
NGBoostの分布の可視化
NGBoostの分布を可視化しました。ここがNGBoostのキモだと思います!
各グリッドの1マスがX_validの1レコードごとに対応する予測結果になります。X_validが102行あるので、グラフも102個出力されます。
モデルの予測結果は正規分布を採用しているので、平均を点推定していることがわかります。
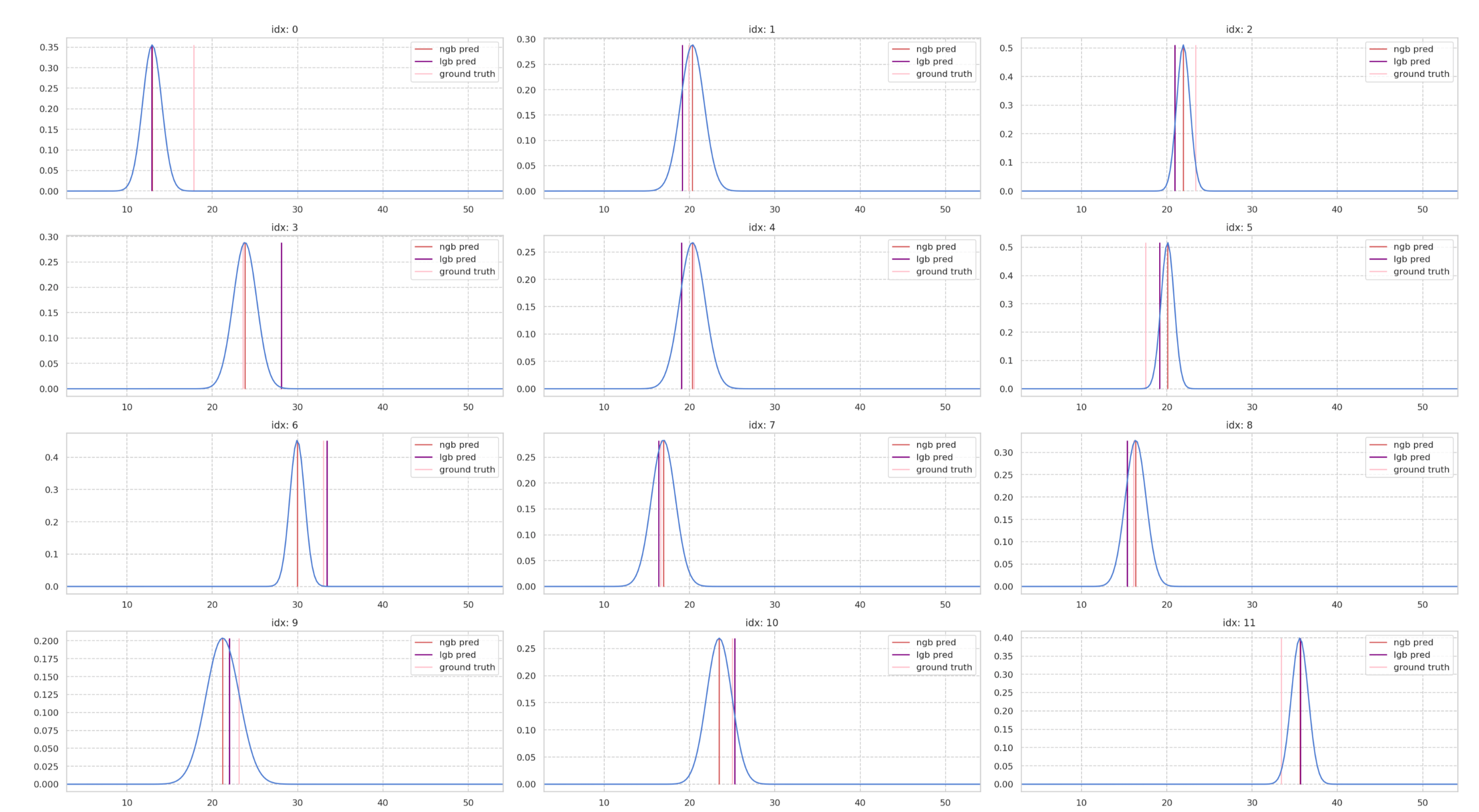
表示の関係から最初の4行のみの表示しています。全てみたい方は**こちら**を見てください。
上記のグラフを描画するコードはこちら。
offset = np.ptp(y_preds)*0.1
y_range = np.linspace(min(y_valid)-offset, max(y_valid)+offset, 200).reshape((-1, 1))
dist_values = y_dists.pdf(y_range).transpose()
plt.figure(figsize=(25, 120))
for idx in tqdm(np.arange(X_valid.shape[0])):
plt.subplot(35, 3, idx+1)
plt.plot(y_range, dist_values[idx])
plt.vlines(y_preds[idx], 0, max(dist_values[idx]), "r", label="ngb pred")
plt.vlines(y_pred_lgb[idx], 0, max(dist_values[idx]), "purple", label="lgb pred")
plt.vlines(y_valid[idx], 0, max(dist_values[idx]), "pink", label="ground truth")
plt.legend(loc="best")
plt.title(f"idx: {idx}")
plt.xlim(y_range[0], y_range[-1])
plt.tight_layout()
plt.show()
結果の比較(散布図)
NGBoost vs LightGBM
だいたいおんなじ予測値を出していますね。
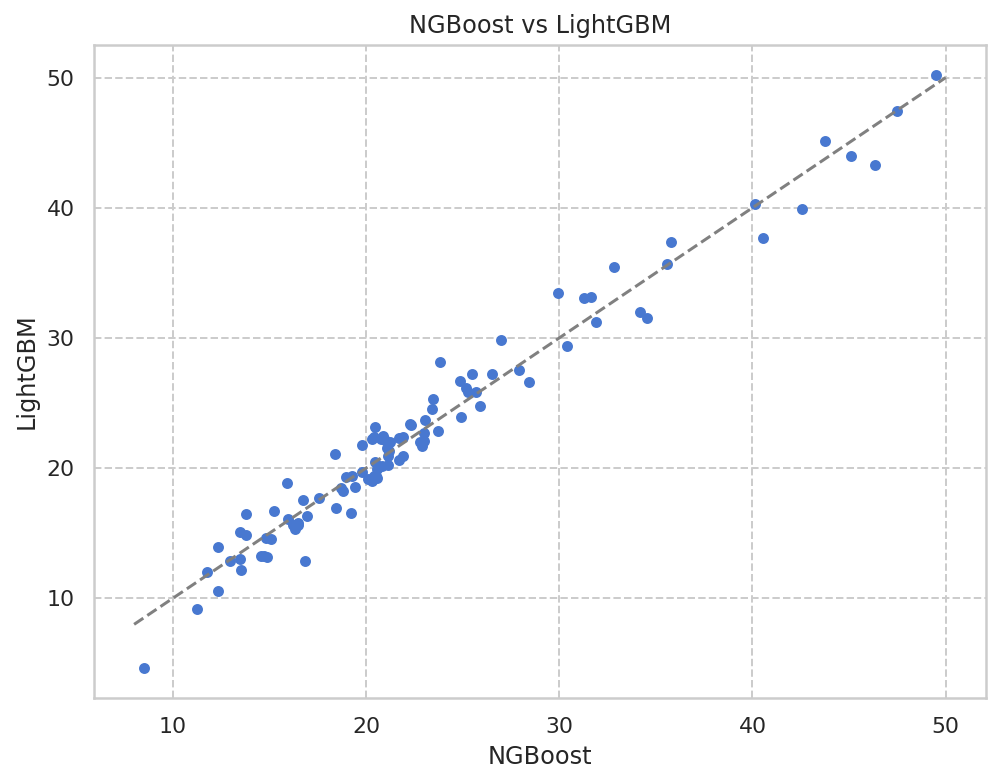
Ground Truthとの比較
Ground Truthと比較してみると、両方とも同じような傾向の出力結果に見えますね。


contribution
early stoppingがなかったり、学習の逐次ログがON/OFFしかなくて、100stepごとにログ出力できないとか、結構色々contributionチャンスがありそうですよ、みなさん!w
参考
- 今回の実験のNotebook:
https://www.kaggle.com/kenmatsu4/ngboost-regression-demo - 公式ページ:
https://stanfordmlgroup.github.io/projects/ngboost/ - Githubリポジトリ:
https://github.com/stanfordmlgroup/ngboost - Githubリポジトリ:example(今回の元ネタ)
https://github.com/stanfordmlgroup/ngboost/blob/master/examples/empirical/regression.py