こんにちは、DeNAでデータサイエンティストをやっているまつけんです。
今回は、Transformerの中で重要な役割を果たしているSelf Attention、特にQKVの仕組みについて直感的に理解できるように解説してみます。
Transformer、特にGPTなどの生成モデルでは
O = \mathrm{softmax}\left(\frac{QK^{\mathrm{T}}}{\sqrt{d_k}} + M\right)\cdot V
のようなSelf Attentionの計算を行うことで、各単語のそれ以前の文脈に基づいた文脈化と、長文の理解を実現しています。このブログではこの数式が何を行っているかを直感的にわかりやすくすることを重要視して解説します。
概略:
本記事における簡単化のいくつかの前提
- わかりやすさのためにtokenは単語単位となっている前提とします。実際の GPT 系モデルでは入力は単語そのものではなくtokenに分割されますが、本記事では直感的な理解を優先して、各tokenを「単語」のように扱って説明します
- Q, K, Vは元の単語embeddingそのものではなく、各token表現に線形変換をかけて得られるベクトル列ですが、直感的理解のため本スライドでは各行を単語に対応するベクトルとして扱います
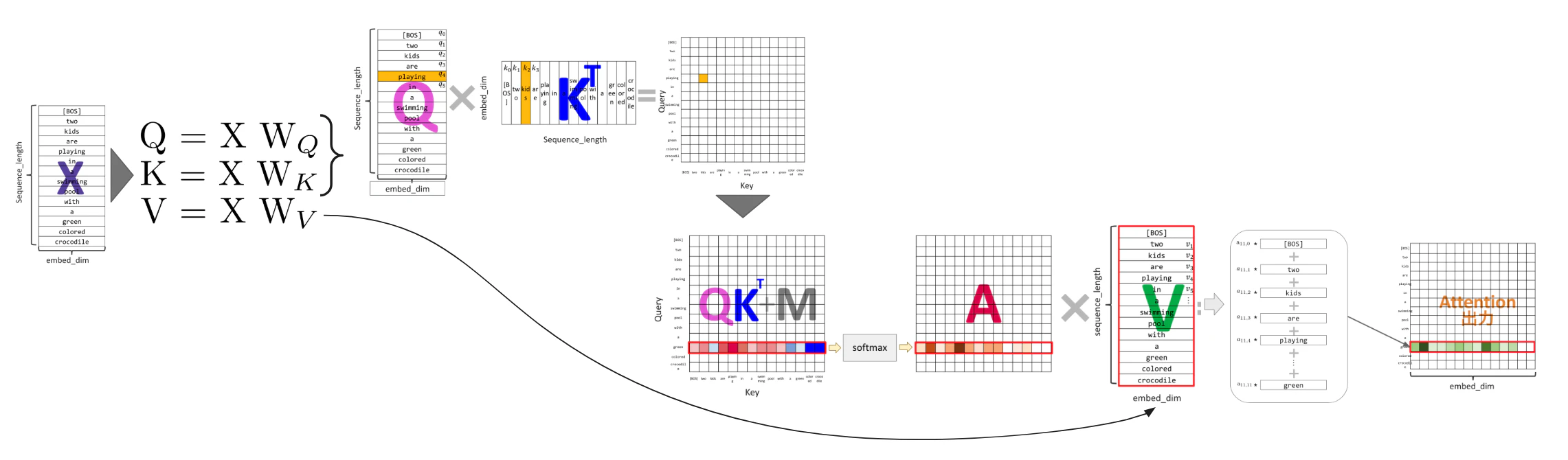
入力からQueryとKeyとValueの作成
Transformer の Self-Attention では、各単語の表現 X から Query:Q, Key:K, Value:V という3種類のベクトル列を作ります。Query は「何を探しにいくか」、Key は「どんな問い合わせに反応するか」、Value は「実際に出力へ渡される情報本体」のように考えると直感的です。
GPT のような生成モデルでは、causal mask によって未来の token を見ないようにしながら、各単語が自分自身と過去の単語から必要な情報を重み付きで集約します。
$Q, K, V$は下記の計算式のように入力された文章Xに係数($W_Q, W_K, W_V$)をかけて作った$Q,K,V$で作られます。このように文章Xが変換されてできたのが$Q, K, V$なのですが、本ブログではイメージしやすさのため、以降それぞれ単語だと思って進めます。
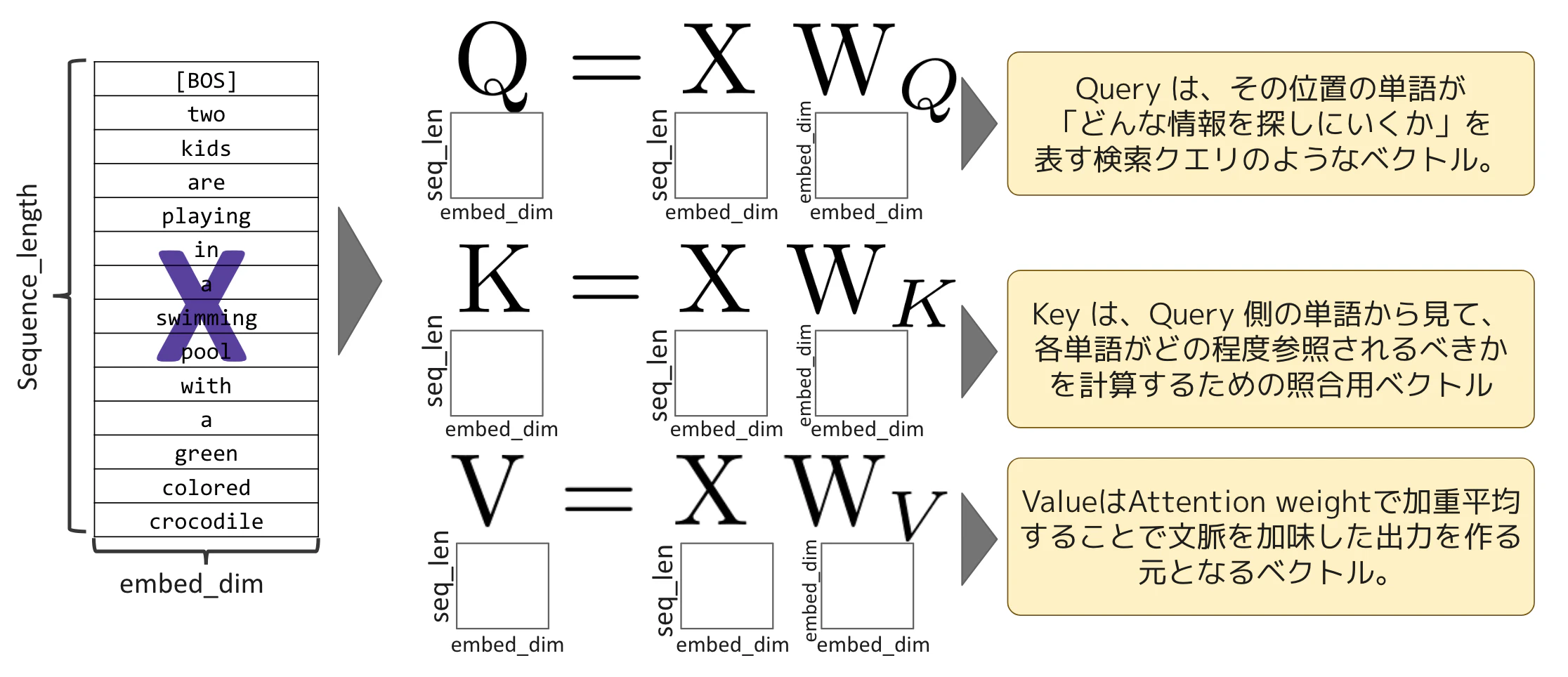
QとKで単語間の関係性を表現
$\frac{QK^{\mathrm{T}}}{\sqrt{d_k}} $の分子の部分はQに含まれる単語それぞれと、Kの単語それぞれの内積をとって結果を行列に詰めています。本記事では、この内積はラフに単語間の関係の強さと解釈しましょう。(内積の意味の考え方はこの記事参照)
内積は、ベクトルの長さがともに1の単位ベクトルであれば、ベクトルの方向がどれだけ近いかを表す類似度と見なせます。今回は単位ベクトルではなく長さを持つのですが、内積のイメージの1つとして持っておくと理解の助けになると思います。
このような意味合いを持つ内積を、Self Attentionで利用する場合は「Query 側の単語が、Key 側の各単語をどれだけ参照したいかを表すスコア」であると解釈します。意味的な類似度に近い働きをする場合もありますが、実際には文脈や、文法的関係、参照関係なども含む、学習された照合スコアです。
本記事では簡略化のため$d_k$は単語embeddingの次元とみなし1、分母にある$\sqrt{d_k}$は計算処理上のスケール調整2を表す。
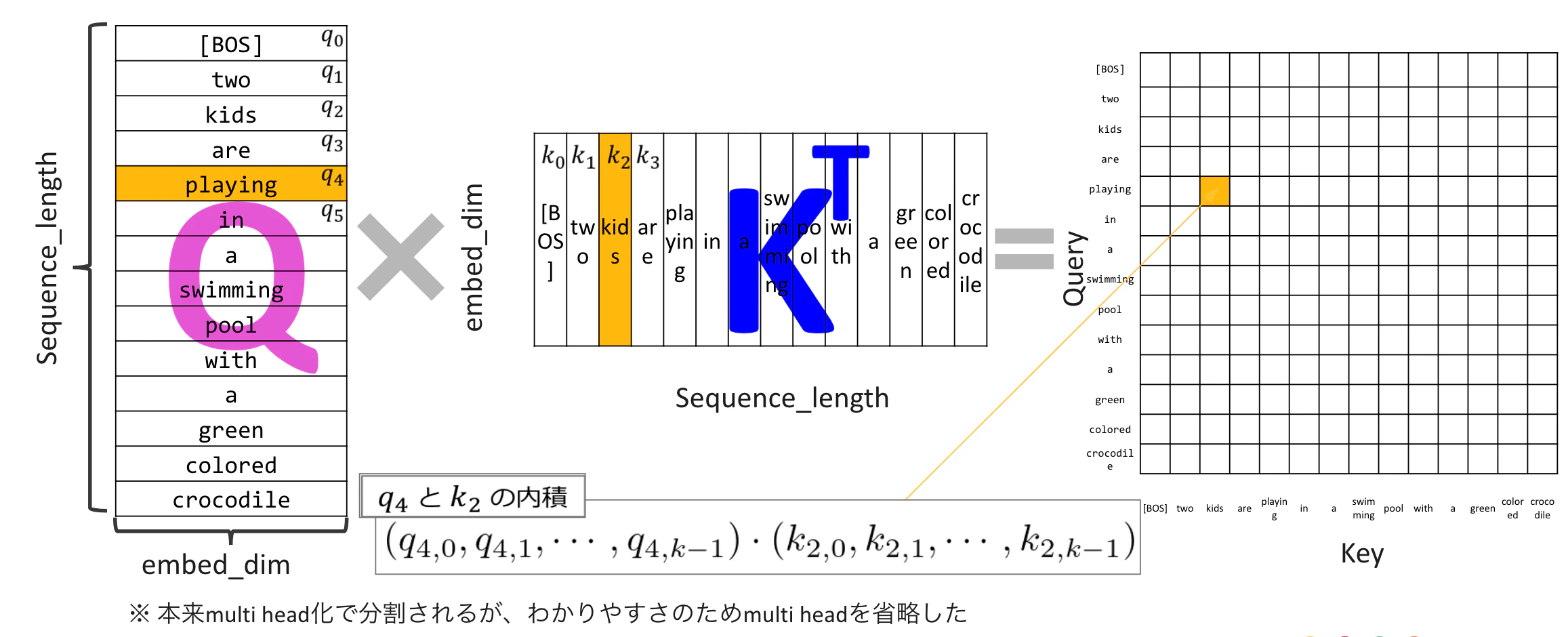
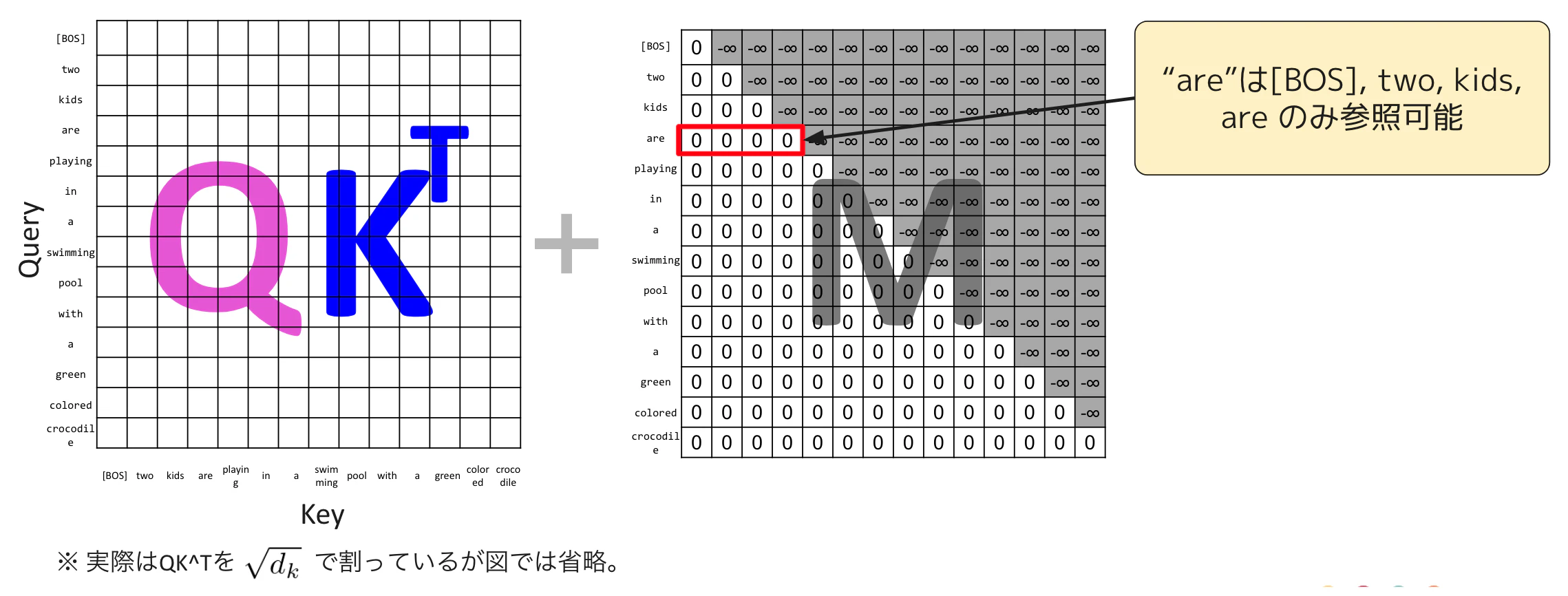
Queryとして"playing"に着目すると、"playing"とKeyの各単語とそれぞれ内積をとり、$QK^T$行列の"playing"に該当する行に格納していきます。
つぎに $\frac{QK^{\mathrm{T}}}{\sqrt{d_k}} + M$ に行きます。Mはマスクのための行列です。このマスクは、next token predictionでカンニングしないために、Query側の単語から見て自身と過去の単語のみを参照するためのもので、右上の要素が-∞となる行列を足し合せること後続処理のsoftmaxで当該要素が0になり、関係性が無視されるように調整するものです。
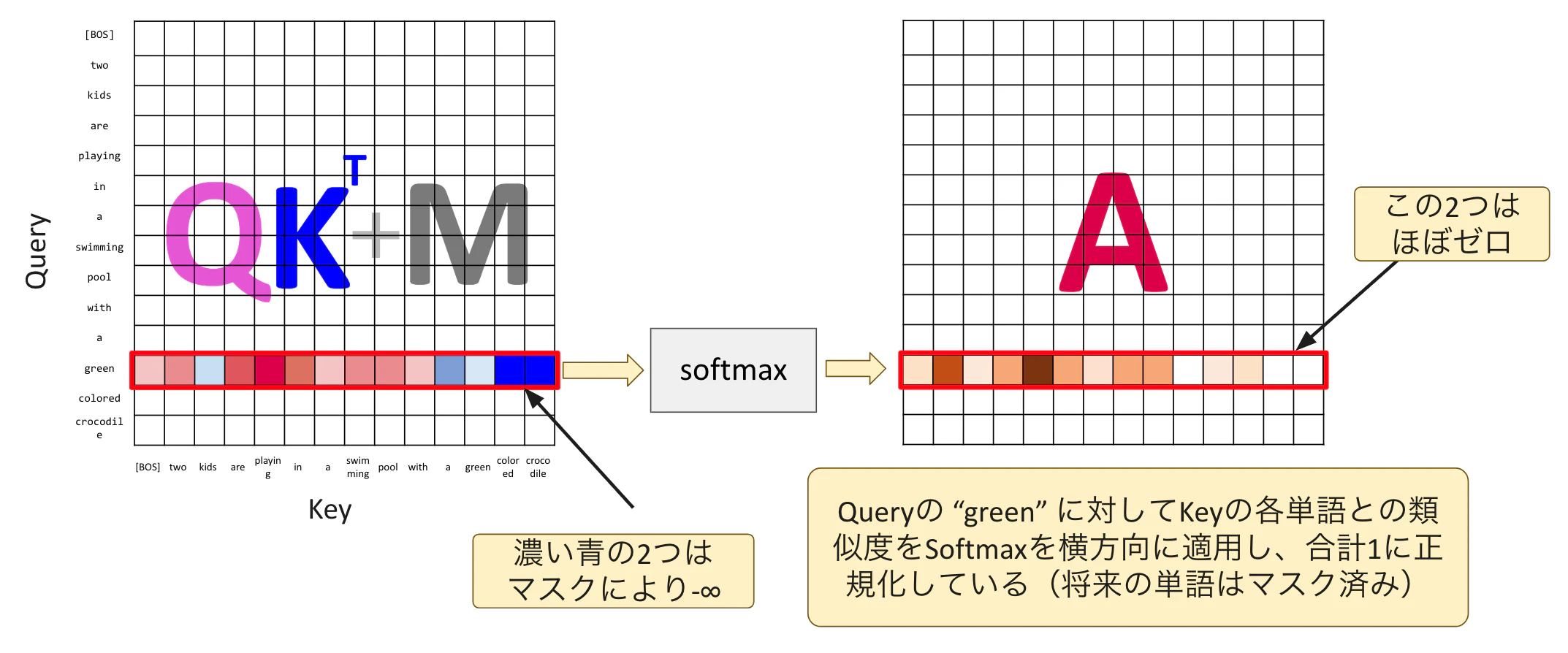
次はAttention: $A = \mathrm{softmax}\left(\frac{QK^{\mathrm{T}}}{\sqrt{d_k}} + M\right)$です。
softmaxを横方向に適用し、1つの行の要素の値を足し合わせると1になるように正規化します。これにより加重平均のweightとして利用できるように変換されます。マスクがかかっているところは-∞なのでAttentionの値としてはほぼ0になります。これをQueryの全単語に適用することで、Attention行列が作られます。
Attention出力の計算
$A$のAttention行列をValue:$V$にかけることでSelf Attentionの出力結果が得られます。
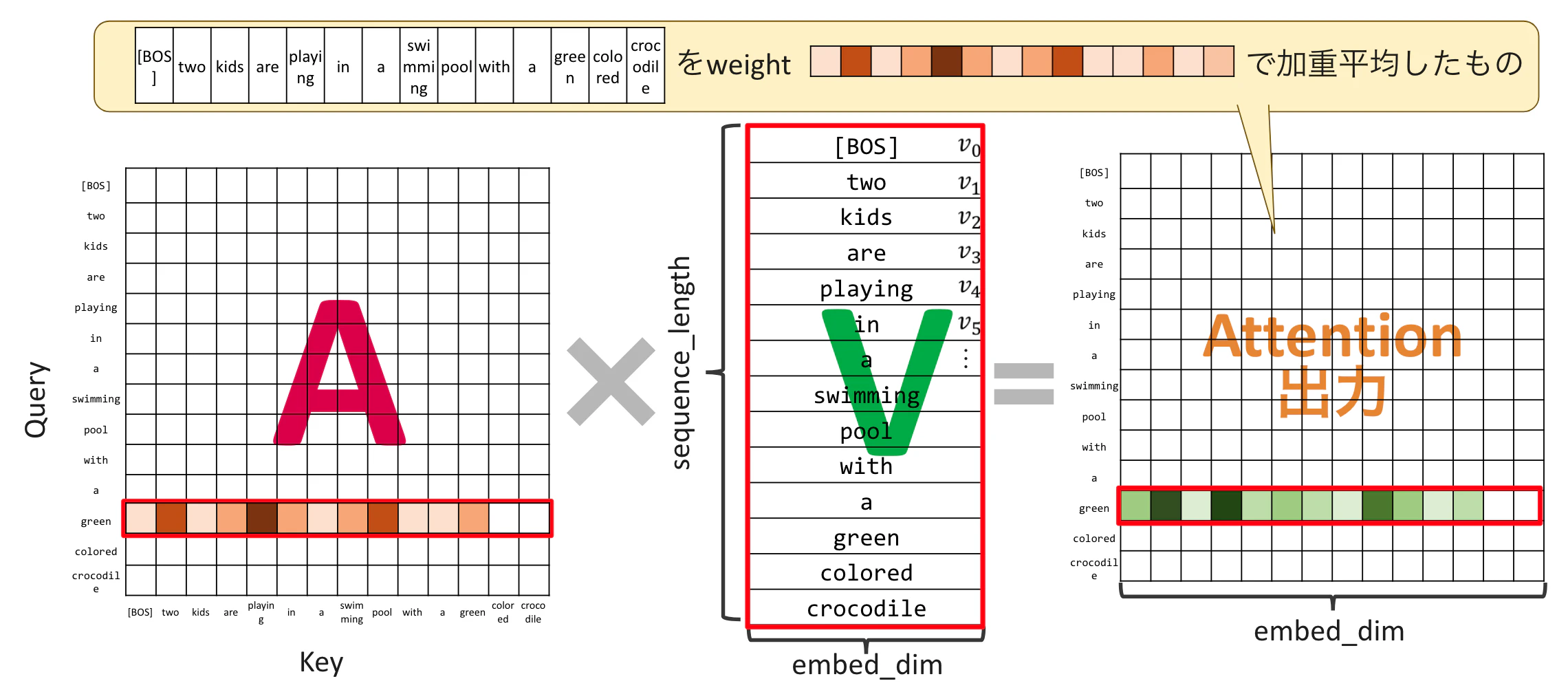
つまり、Attention Weightで重み付けされたValueの各単語を足し合わせたベクトルが、Self Attentionの出力結果なのです。
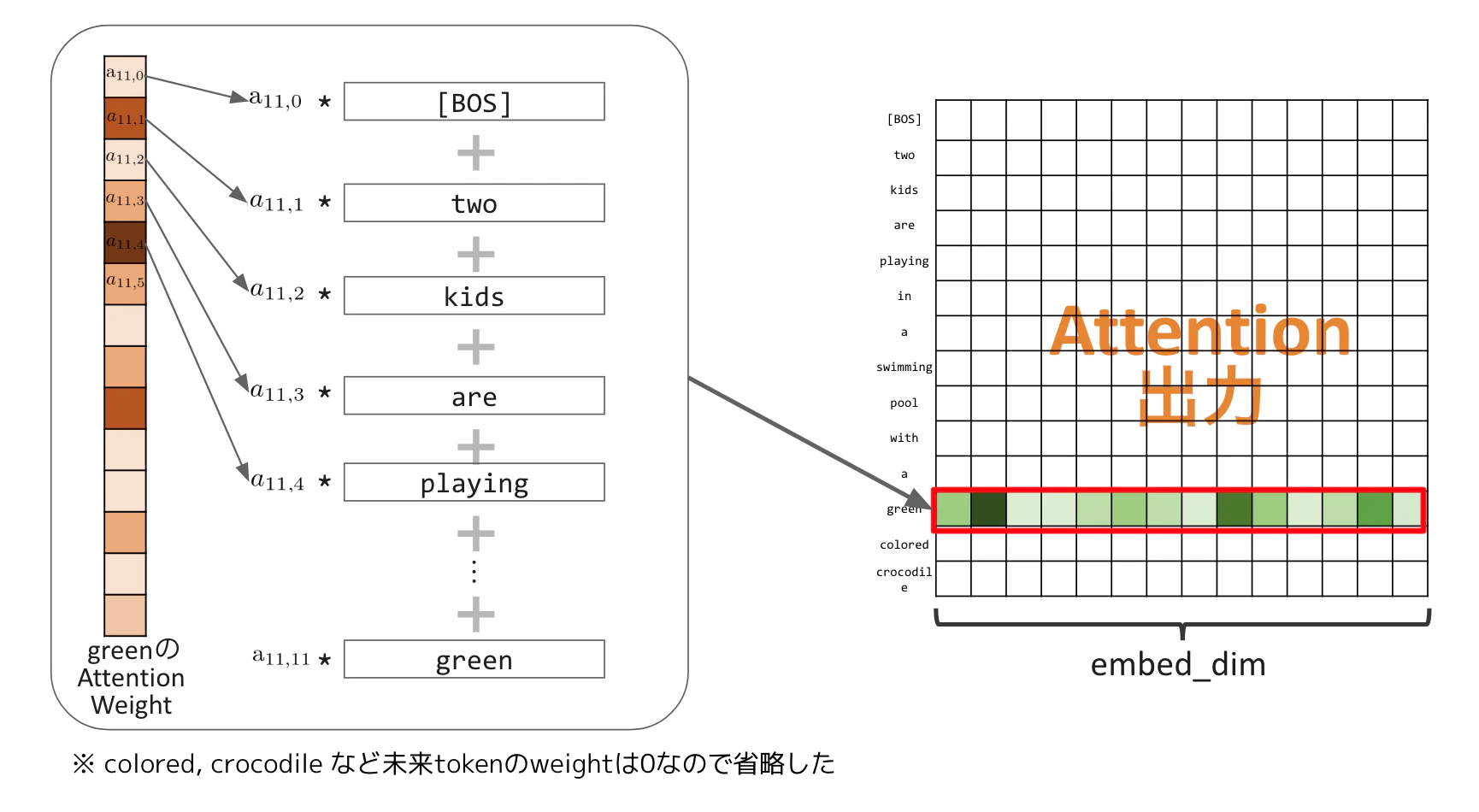
つまり、Queryの中の1つの単語"green"に着目すると、Queryの"green"とKeyの各単語の関係性の強さをAttention Weightとして計算し、そのWeightを用いてValueの各単語を加重平均した結果が、"green"の文章内での文脈を加味した意味としての単語ベクトルと見做せると言うことです。
まとめ
本記事では、Transformer の Self-Attention における $Q, K, V$の役割とその計算の意味合いを直感的に理解できるように説明を試みてみました。
Self-Attentionは、Queryの単語を起点に、Keyで文章中の各単語との関係性を計算してAttention Weightを算出し、そのAttention Weightを用いてValueにある各単語ベクトルを加重平均して、その位置の単語の文脈を反映した出力表現を作る計算でした。
注目している単語自身とそれ以前の単語も参照して当該単語の意味づけを行えることが直感的にも理解できたのではないでしょうか。