概要
前回の記事で、リアルタイムセマンティックセグメンテーションの学習やテストに使われるデータセットについてまとめました。
今回は、どのようなモデルが今存在しているのか、ということについてまとめていきたいと思います。
モデルの性能の変遷
Paper with Code のそのままの転載となりますが、
まずはセマンティックセグメンテーションがどのように性能向上し、
リアルタイム性を持ってきたのか、ということについて理解します。
Paper with code + real time semantic segmentation へのリンクはこちら
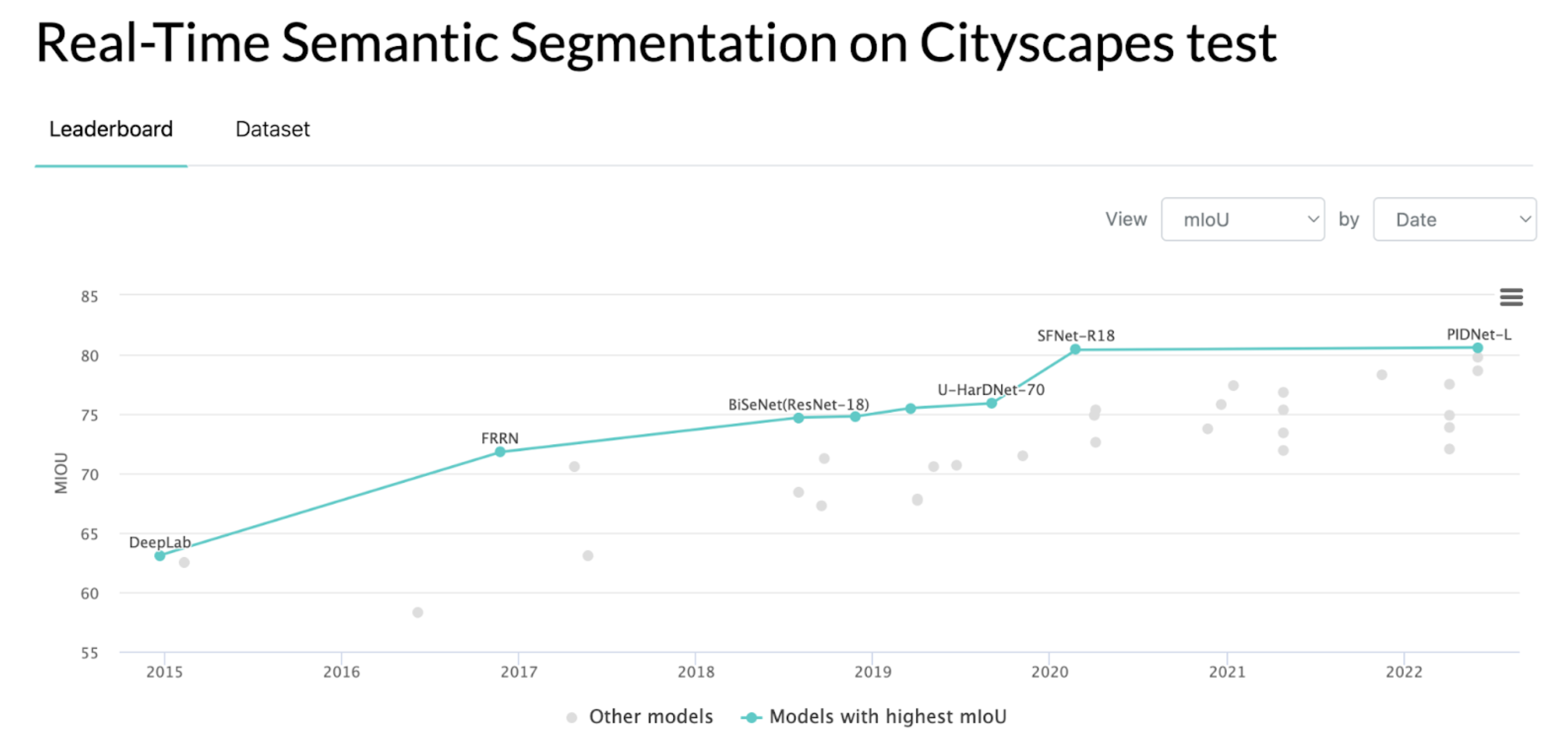
精度
これを見ていただければわかるように、CityScapesのデータセットに対して、
モデルの持つmIoUの値は年々向上しており、
今現在のSoTAモデルは約80のmIoU を持っていることがわかります。
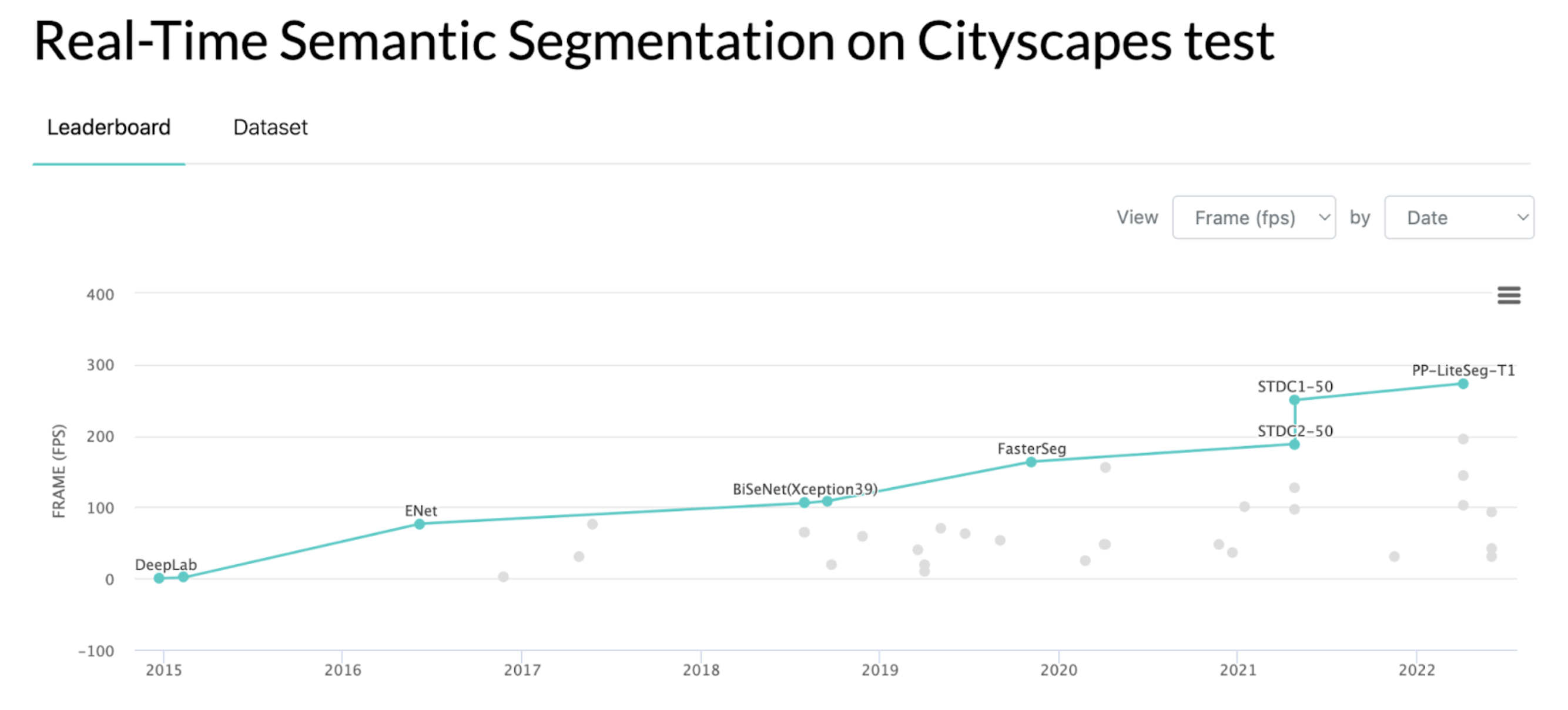
速度
次に、推論速度ですが、これも年々大きな改善が見られます。
もちろん計算環境が良くなっているという前提はありますが、モデル自体の改善も大きく、
現在では200~300を超えるFPSでの推論も可能な水準です。
リアルタイムセマンティックセグメンテーションという言葉が出てき始めたのは、2016年〜2017年頃からのようです。グラフを見ると、そのあたりでFPSが100前後を達成しており、そのあたりから実際にリアルタイム性をもつセグメンテーションモデルで精度を出すことができるか、という研究が大きくなったようです。
現在の200、300くらいのFPSが出れば
リアルタイムでセグメンテーションをかけながら自動運転に応用したりなども余裕で考えられそうですね。
精度と速度のまとめ(後述のPIDNetの論文より)
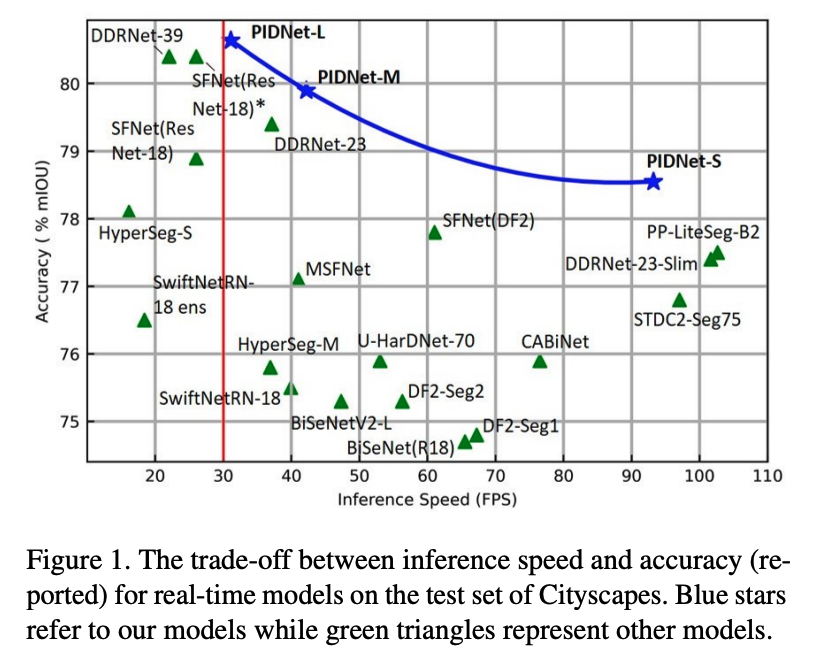
ここ数年で、セマンティックセグメンテーションのタスクは非常に早く、正確になっていることがみて取れます。
アルゴリズムの変遷
さて、ここからセグメンテーションモデルのアルゴリズムについて言及します。
ここでは、アルゴリズムの構造に対して、系列分けしてみました。
- UNet 系列
- DeepLab 系列
- 畳み込み層改善 系列
- マルチパス系列
- YOLOからの派生系列
- コンピュータビジョンからの工夫を組み込んだ派生系列
ここからは、各系列ごとにモデルのアルゴリズムを追っていこうと思います。
モデル構造
UNet 系列
まずは、セグメンテーション元祖UNetを踏襲したアルゴリズムです。
Unet として2015年に登場し、Unet++などでより表現力が改善されたモデルになったあと、
2021年にはトレンドのSwin Transformer を応用したSwin Unetも発表されています。
-
Unet(2015)
https://arxiv.org/pdf/1505.04597.pdf -
Unet++(2018)
https://arxiv.org/pdf/1807.10165v1.pdf -
Swin Unet(2021)
https://arxiv.org/pdf/2105.05537v1.pdf
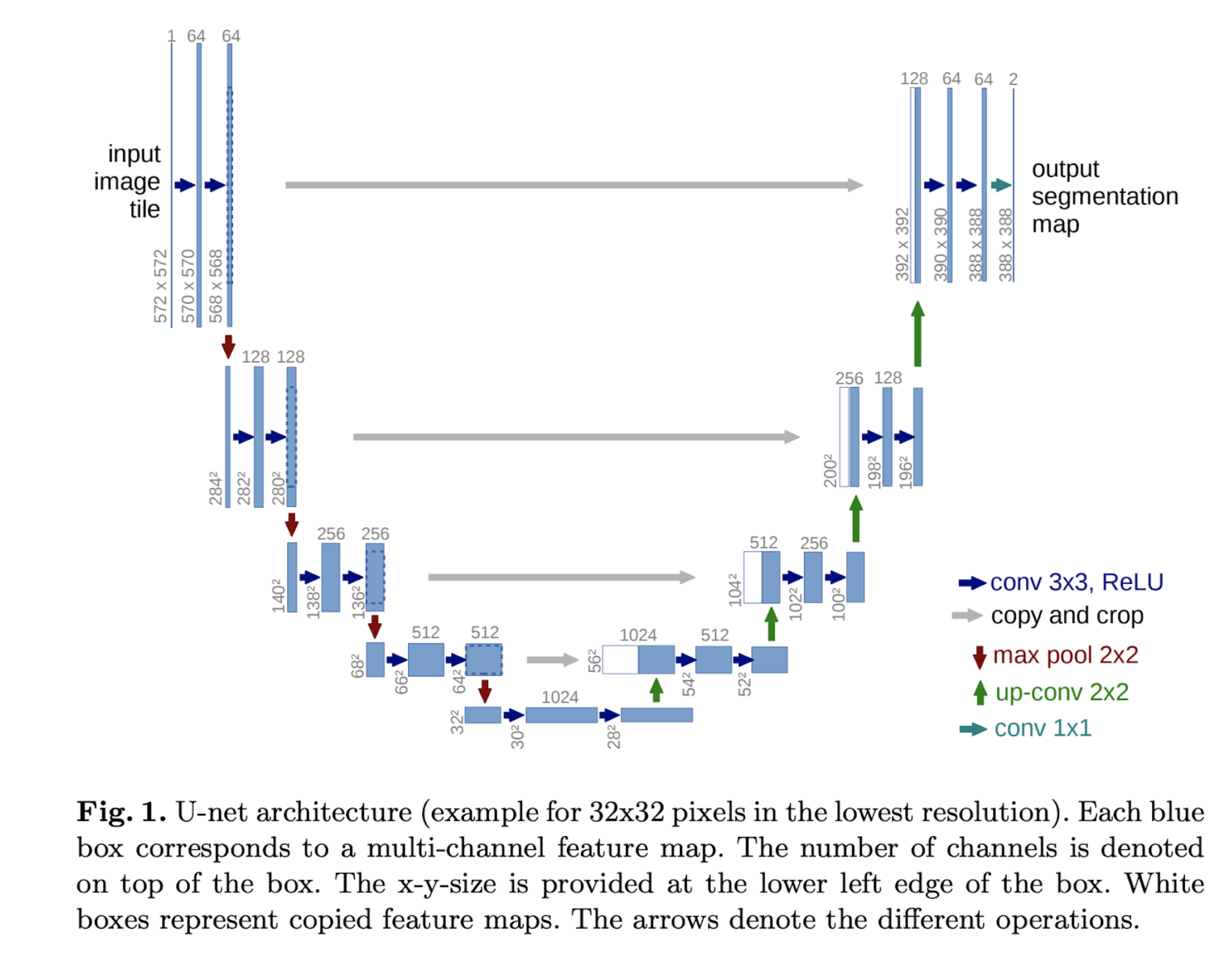
Unet
UNet は知っている方も多いと思いますが、エンコードとデコードをボトルネック層を挟んで実装したモデルで、
デコード部分にはエンコードからのスキップコネクションを使用することで、特徴量を抽出することを抑えた、細部のセグメンテーションに効く部分を残すことで、セグメンテーションタスクのスタンダードモデルとなりました。
モデルの形がU字に見えることから、UNetと呼ばれています。
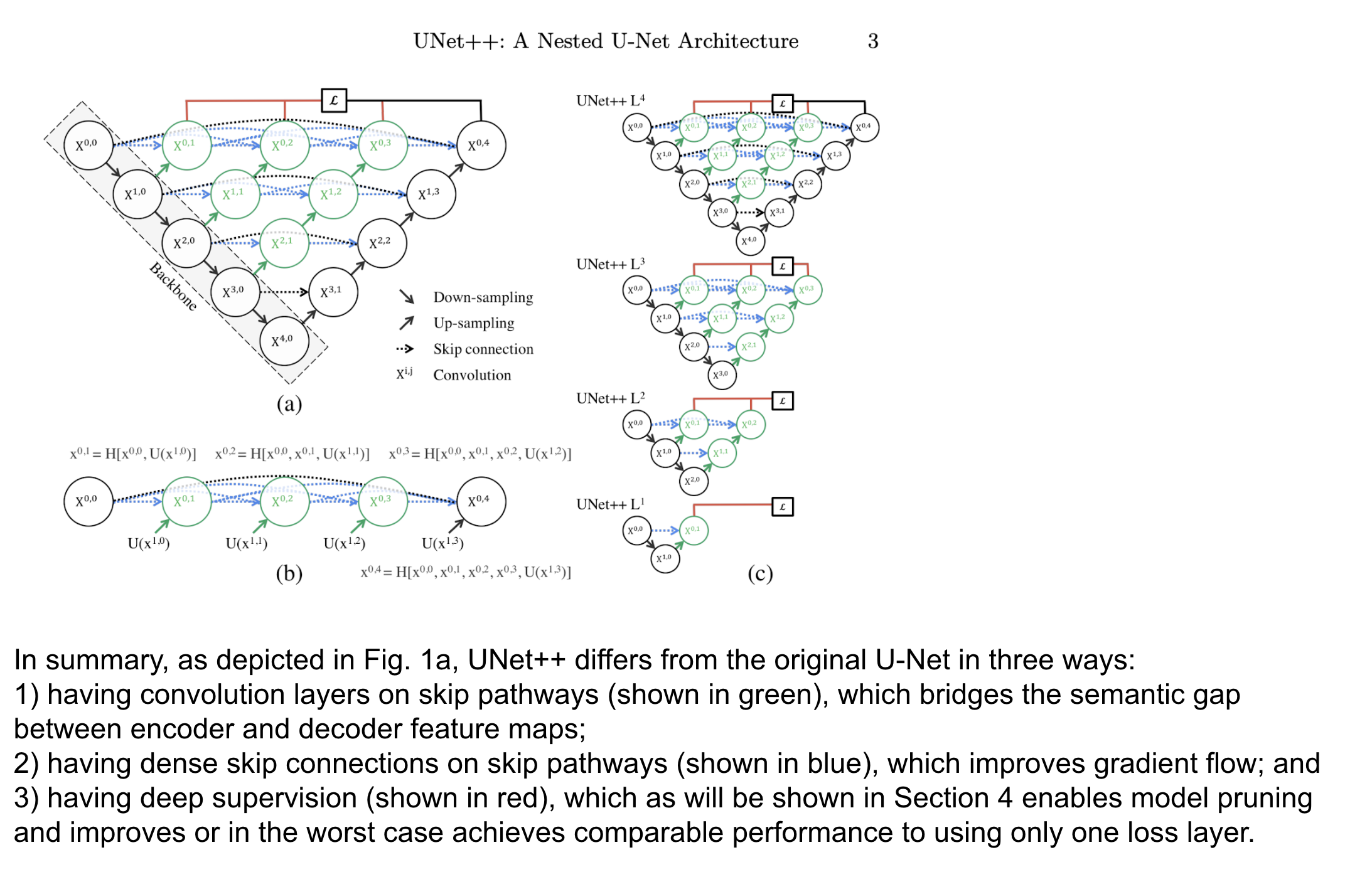
UNet++
UNetのスキップコネクションを改善する形で発表されたUNet++ですが、元のUNetでは単純だったスキップコネクションを、もっと多層にして実行しています。
こうすることで、今までエンコーダとデコーダで乖離していた特徴マップの差を小さくすること、グラディエントマップを改善することなどをメリットとして挙げています。
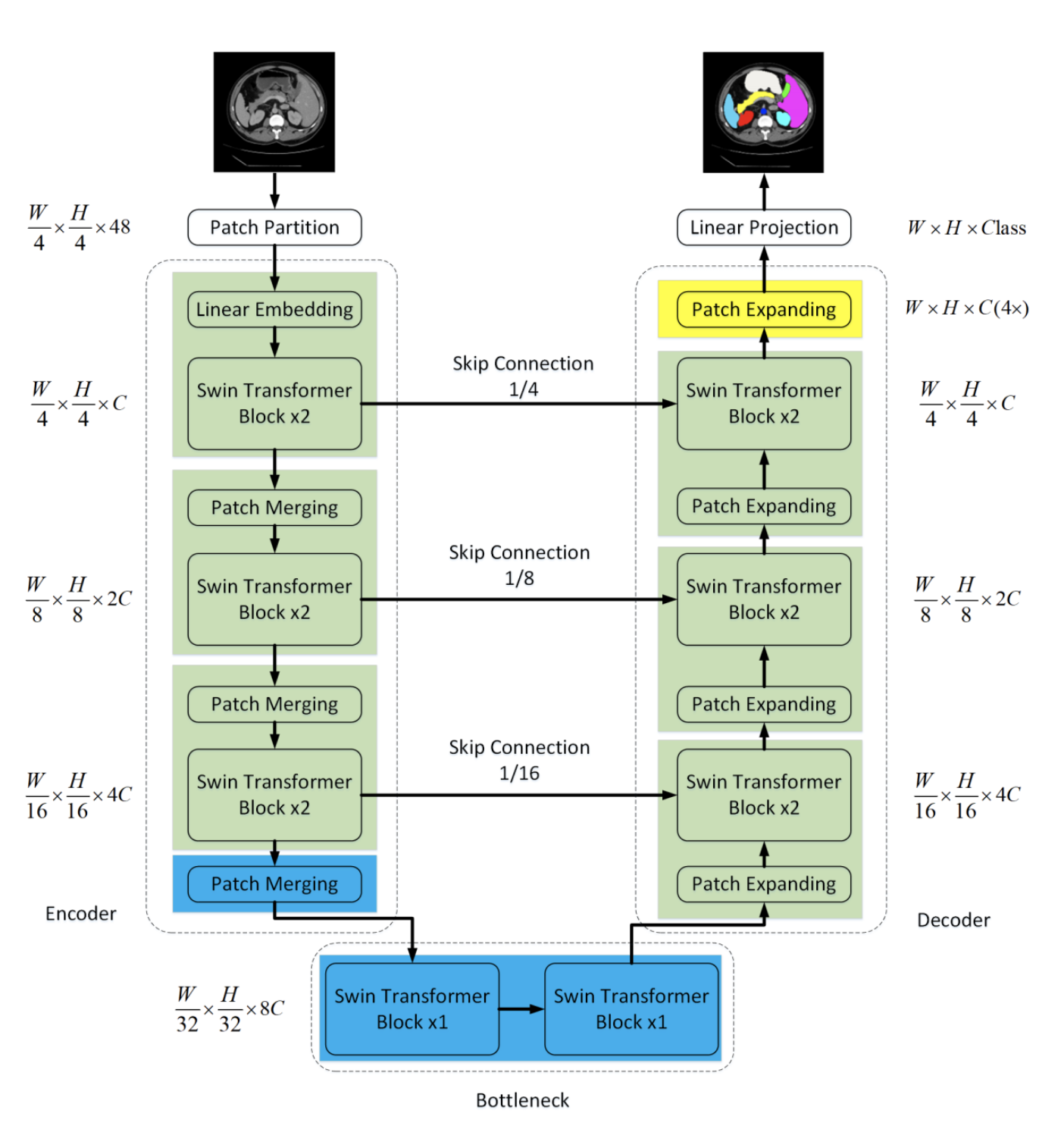
Swin UNet
こちらは、Swin Transformer を用いてエンコーダとデコーダを実装しているモデルです。
畳み込み層はSwinTransformerの層に置き換わっています。
DeepLab 系列
-
DeepLab (2014)
https://arxiv.org/pdf/1412.7062v4.pdf -
DeepLab v2 (2017)
https://arxiv.org/pdf/1606.00915v2.pdf -
DeepLab v3 (2018)
https://arxiv.org/pdf/1706.05587v3.pdf
DeepLab
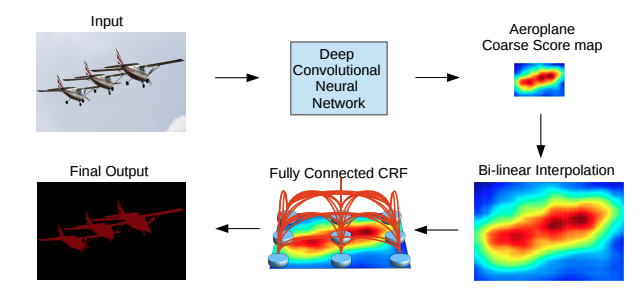
DeepLab もまた、畳み込み層を用いて特徴マップを作るところまでは同じなのですが、
そのあとに最終出力を行うところに、アップサンプリングの後にConditional Random Field (CRF) と呼ばれる前結合モデルを使って最終出力を生成しています。
この工夫により、モデルの課題だった、ディテールの情報が畳み込みによって失われてしまうことを克服した、という記述になっています。
DeepLab v2
DeepLab v2 では、CNN層に対して、視野角を通常より大きく取る、Atrous Convolution を用いることによって、出力される画像が小さくなりすぎるのを防ぐ(結果として特徴マップのディテールが保たれる)ことを工夫しています。
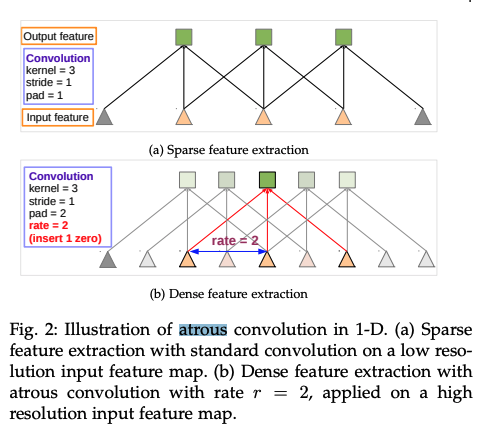
また、これらの視野角をいろいろな大きさで実行し、それらを合わせる、ピラミッド型を採用しており、
これらの手法でより精度を高めたという記述になっています。
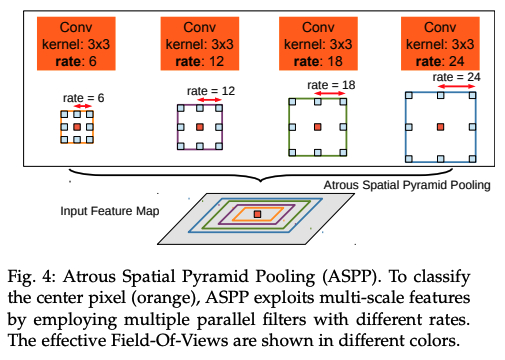
DeepLab v3
v3については、アーキテクチャは基本的にはv2のものを踏襲し、
モデルの細部の更新により精度の向上を図ったというような記述がなされていました。
細部については論文で確認していただければと思います。
畳み込み層改善 系列
- ENet(2016)
https://arxiv.org/pdf/1606.02147v1.pdf
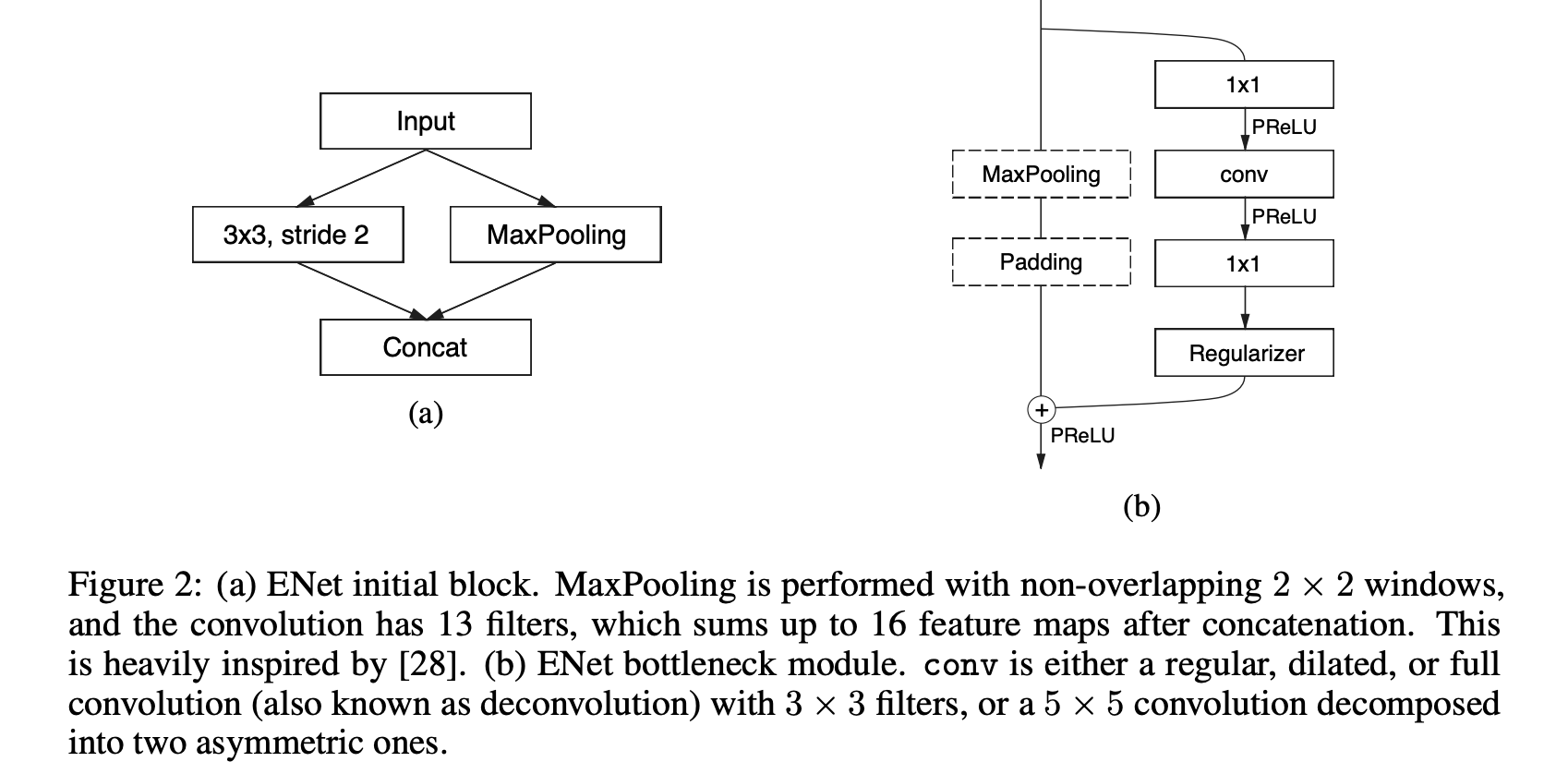
ENet
既存のセグメンテーションモデルの畳み込み層に対して、畳み込みブロックをより少量のパラメータによって実行し、速度を改善したという記述になっています。
マルチパス系列
- bisenet(2018)
https://arxiv.org/pdf/1808.00897v1.pdf
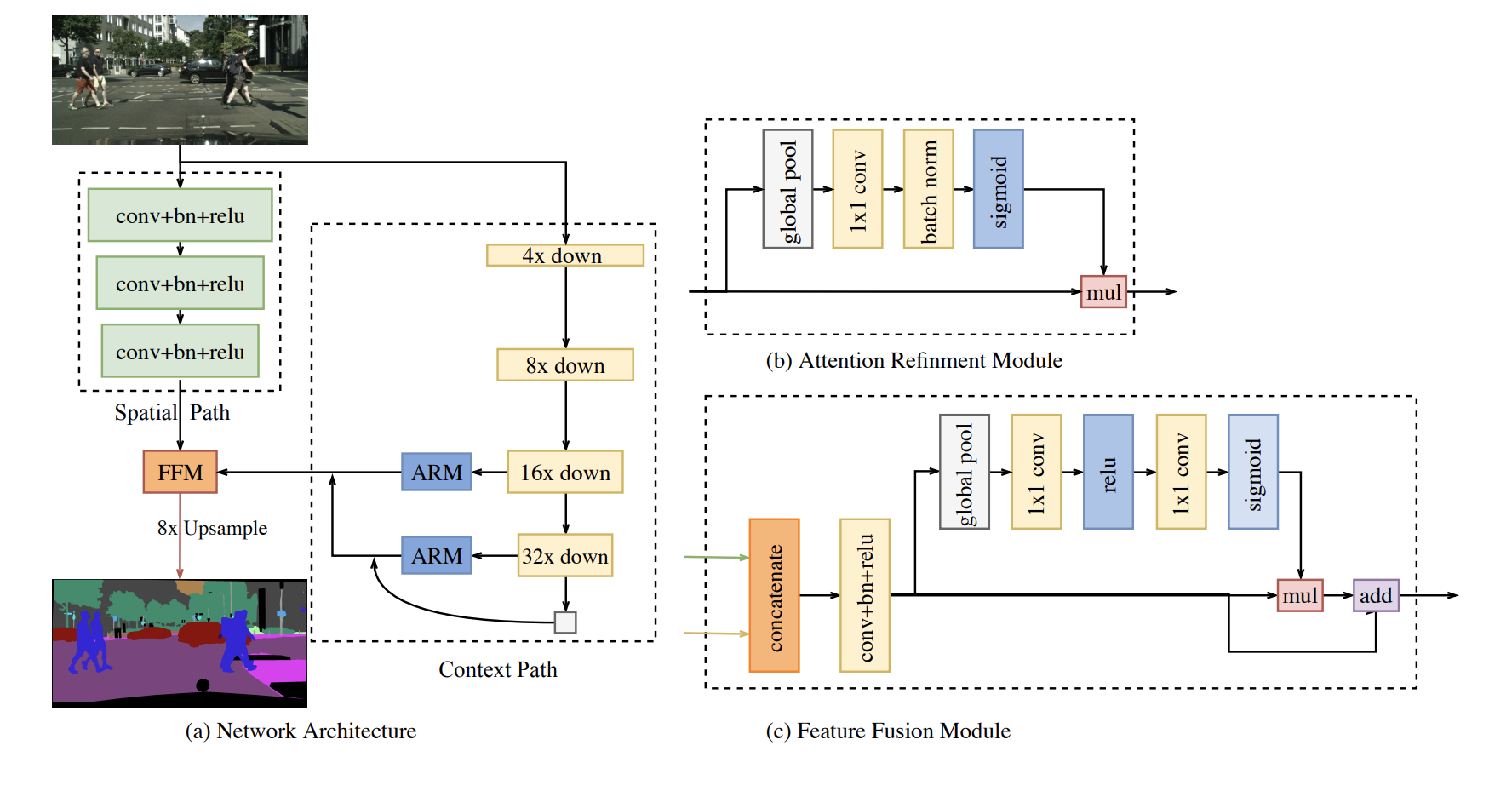
ARM(Attention Refinement Module) と FFM(Feature Fusion Module)は
MobileNetv3のBottleNeckで登場した
Squeeze and Excitation モジュール に類似しています。
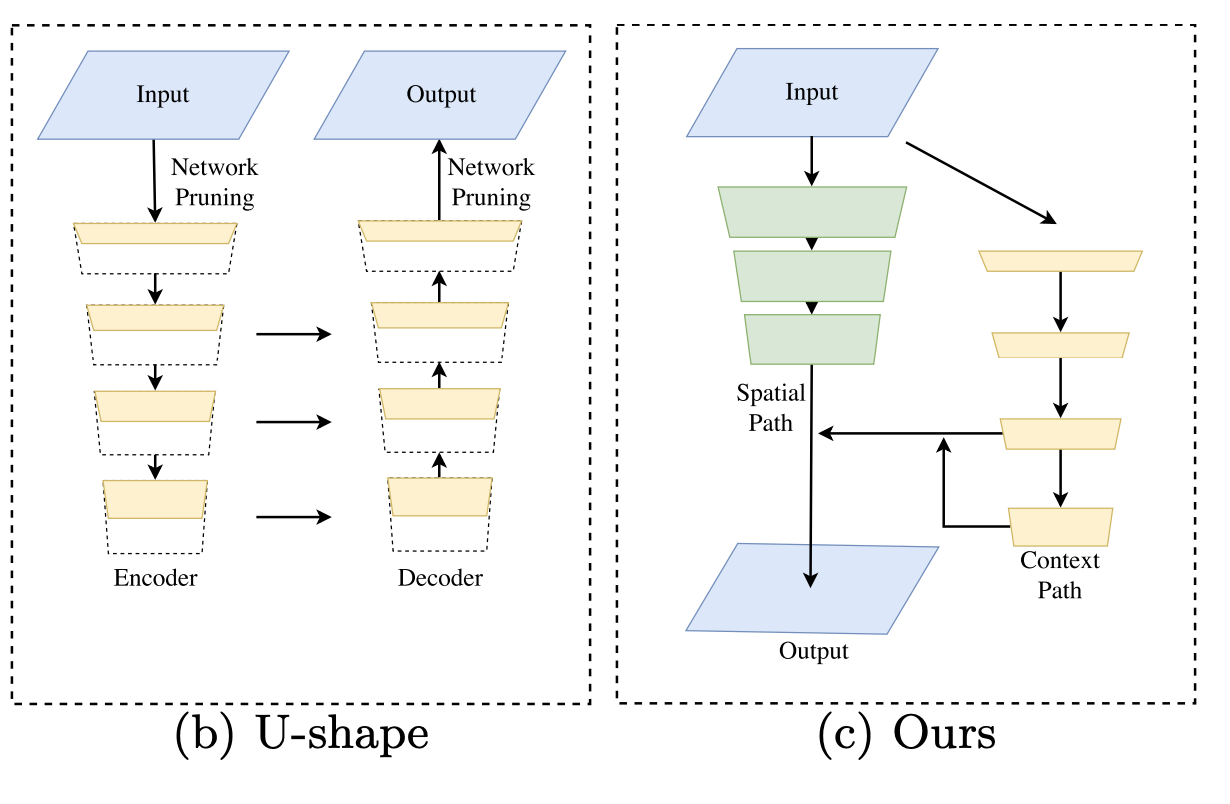
このBisenetで書かれている Context PathとSpatial Pathは
セマンティックセグメンテーションにおいて重要な、
特徴量をより抽出した情報と、ディテールをもっている情報をそれぞれ持っているパスであり、これらの兼ね合いやフュージョンの仕方が全てのモデルにおいて重要であり、それぞれの派生論文での工夫ポイントとなっています。
YOLOからの派生系列
-
YOLACT(2019)
https://arxiv.org/pdf/1904.02689v2.pdf -
YOLACT++(2019)
https://arxiv.org/pdf/1912.06218v2.pdf
YOLACT(2019)
YOLACT は、物体検出モデルとして知られているYOLOのモデルに、セグメンテーションのチャンネルを付け加えたものです。
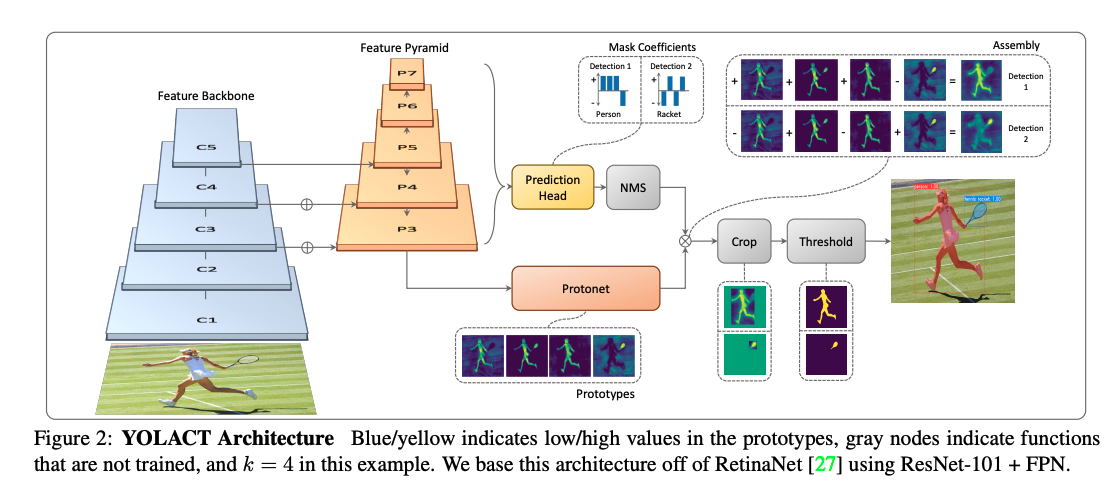
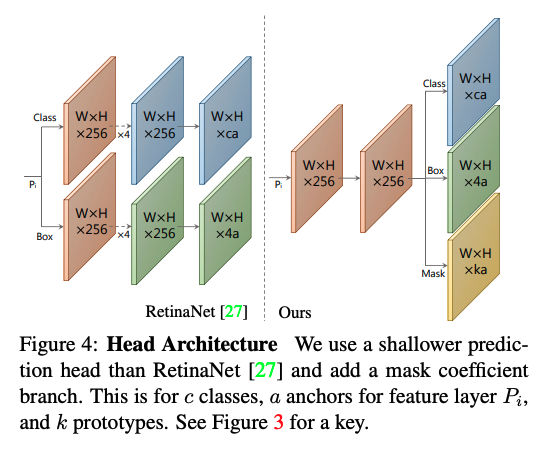
Prediction Headには、YOLOの出力である、物体のクラスを識別するチャンネル、ボックスを出力するチャンネルがあります。
Head ArchitectureのRetinaNetを見ると、その二つのパスでモデルが構築されています。
YOLACTは、このClassとBoxの出力に加えて、Maskの出力を持っています。
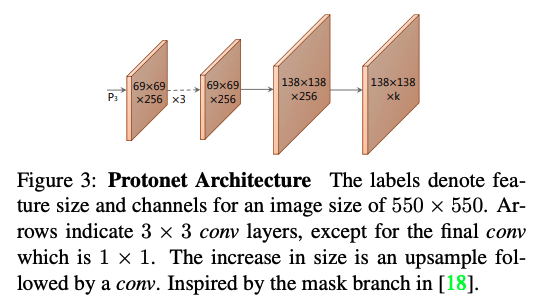
このMaskは、Protonetからの出力と内積を取るような形で重みをつけた状態で足し合わされ、それがMask(セグメンテーションを表す)となります。
その足し合わされた後のMaskは、Head Architecture の他の出力によってクロップされ、閾値によって切り分けられます。
また、これはYOLOを理解するキーワードではあるのですが、NMSというキーワードも出てくるため、知らない人がいたら下の解説記事をご覧ください。
また、YOLACTは∼1500 MB of VRAM even with a ResNet-101 backbone ということで、スペックの低いデバイスに対してもデプロイできるのでは、という記述があります。
一通りモデルを眺めてみると、とても面白いなと思いました。
Head Architectureをマルチパスにするのではなく、シングルパスにして、最後に3つの出力に分けるところなども、高速化という観点でメリットなのだろうなと思いました。
内積を取って重みの付いた和をとるというところは、なんとなくアテンションのようなニュアンスも感じますね。
YOLACT++(2019)
根本的なモデル構造についてはYOLACTと同じなのですが、
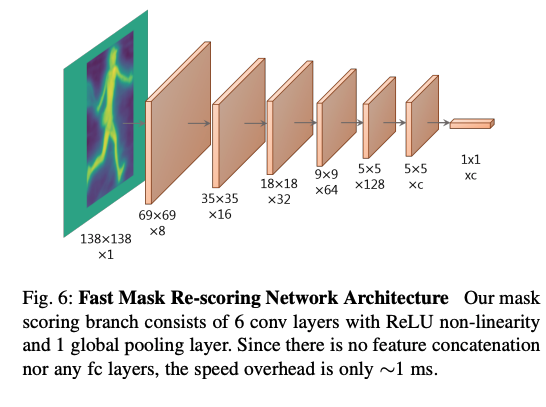
Fast Mask Re-Scoring と呼ばれる層を追加で実装することで、精度を向上させています。
具体的な実装は単純で、Maskを追加の畳み込み層によってベクトル化します。
このベクトルは、教師データとのIoUを予測するように設計しておいて、
このベクトルと、予測されたクラシフィケーションコンフィデンスの積を使って、最後のマスクの結果を再度回帰することで精度向上を図っている、と記述されていました。
コンピュータビジョンからの工夫を組み込んだ派生系列
- SFSeg(2020)
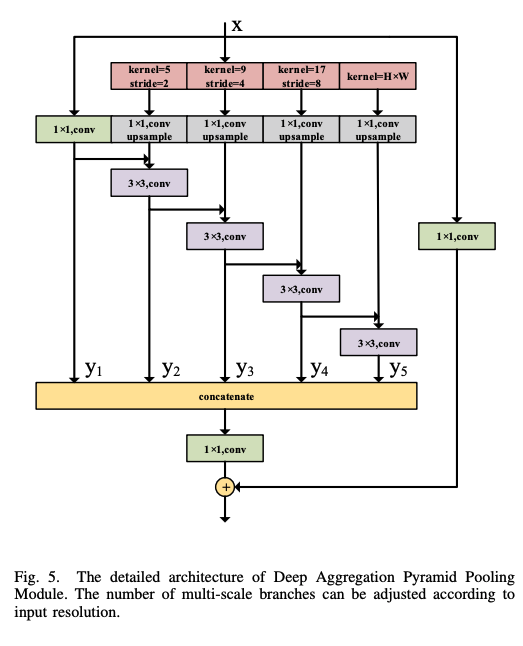
https://arxiv.org/pdf/2002.10120.pdf - DDRNet(2021/01)
https://arxiv.org/pdf/2101.06085.pdf - PIDNet(2022/07)
https://arxiv.org/pdf/2206.02066v2.pdf#page10
SFSeg(2020)
なんとOptical Flowの機構を取り入れたモデルとのこと。
Optical Flowは、動画における隣のフレームの輝度勾配の流れを追って、特徴点がフレーム間でどのように移動したかを予測するものです。
詳しくはいろいろな解説記事をご覧いただければと思います。
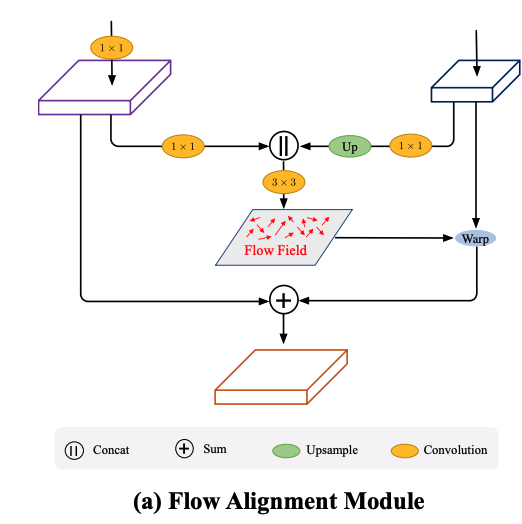
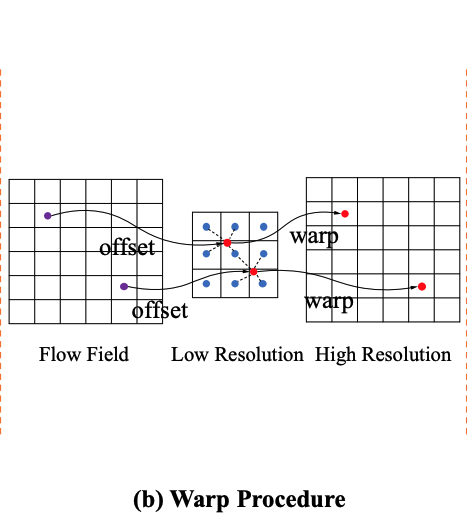
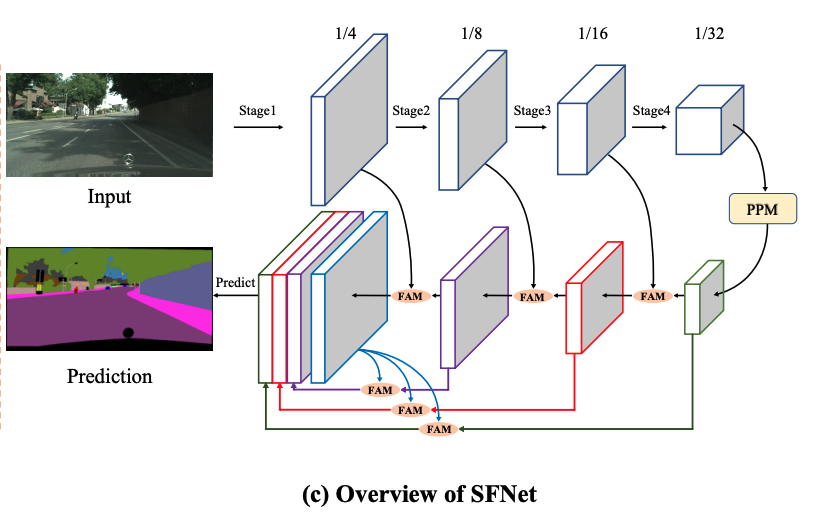
SFSeg では、Flow Alignment Moduleと呼ばれるモジュールを組み込みます。
このモジュールと、今までのFeature Pyramid Fusionを組み合わせることで、Backbone がとても小さくても精度が出るようになり、Backbone はResnet18でも精度が出たので、高速化が大きく達成できた、
という記述になっています。
DDRNet(2021/01)
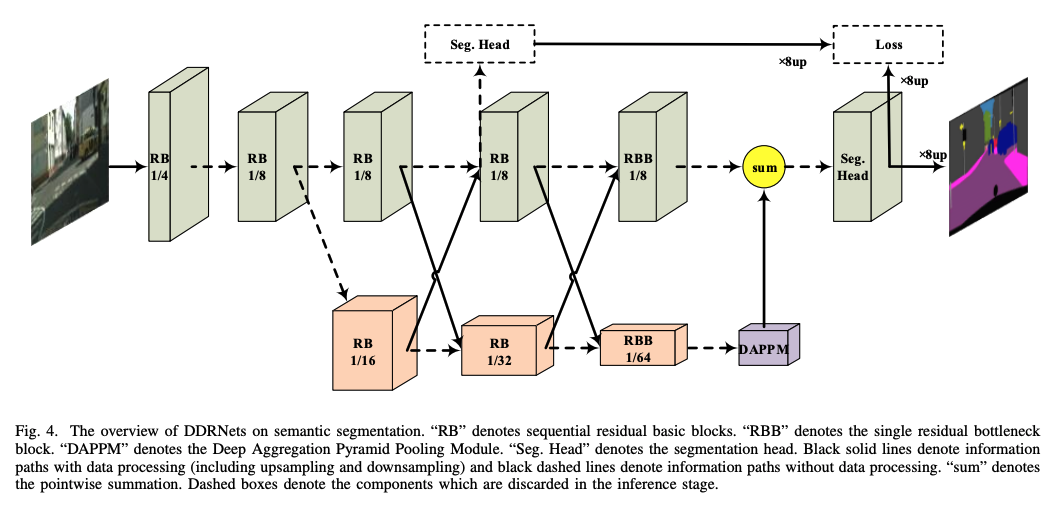
PIDNet(2022/07)
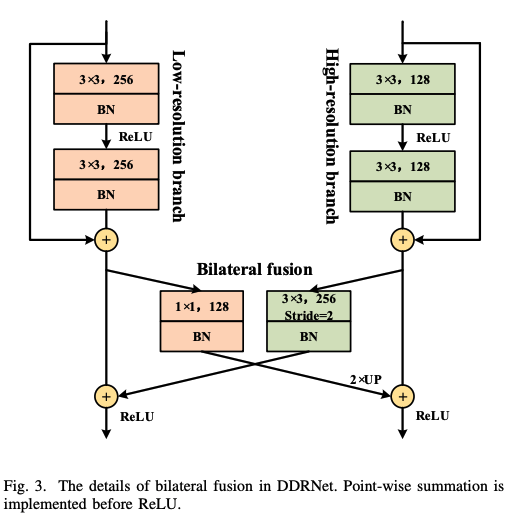
ハイレゾリューションの情報が、セマンティックな意味合いの強いローレゾリューションの情報で上書きされてしまう問題(Overshoot)に着目。
PID制御にアナロジーを見出し、3つのブランチを持つネットワークを構築。
オーバーシュート問題とは、Detail branch (Spatial branch) がContext branch の8倍の大きさを持っており、フュージョンを行うときに物体の境界が周りのピクセル値によってぼやかされてしまい、小さなスケールの物体が圧倒されてしまい、うまくセグメンテーションできない現象のこと。
the output size for detailed branch is 8 times of
context branch in DDRNet (4 times in BiSeNet) and direct
fusion of them will inevitably leads to a phenomenon that
the object boundary are easily corroded by its surrounding
pixels and the small-scale object could be overwhelmed by
its adjacent large objects, namely overshoot in this paper
PID制御をまず理解することでPIDネットでどのような提案がされているか、ということについて理解できます。
Pは現時点と目標の差、Iは時間方向に足し上げた差の積分値、
Dは現時点での変化率を抑える方向の力、
という解釈になっているようです。
PIDコントローラのゲインはトライアル&エラーメソッドにより得られます。エンジニアが各ゲインパラメータの重要性を理解すれば、このメソッドは比較的簡単です。このメソッドでは、まずIとDがゼロに設定され、ループ出力が変動するまで比例ゲインが向上します。比例ゲインを向上させるとシステムは高速になりますが、システムが不安定な状態にならないよう対策が必要となります。Pが希望の応答速度となるよう設定されると、積分項が増加して変動は停止します。積分項により定常状態との誤差は減少しますが、オーバーシュートは増加します。ある程度のオーバーシュートは常に高速なシステムに必要なため、即座に変化に反応する可能性があります。統合項は微調整され、定常状態との誤差を最小限に抑えられます。定常状態との誤差を最小限に抑えた最適な高速制御システムとなるようPとIが設定されると、ループが容認できる程度の高速で設定点に戻るまで微分パラメータが増加し続けます。微分パラメータが増加するとオーバーシュートが減少し、安定性のある高ゲインとなりますが、システムはノイズの影響を非常に受けやすくなります
Auxiliary Derivative Branch という第3のブランチを提唱し、
それはバウンダリ(つまりピクセルのセマンティクスの変化、微分値)に特化して反応するようなブランチを形成しました。
PID制御を模倣したPIDNetは
- P: ハイレゾリューションの情報を保持したブランチ
- I: コンテキスト情報に特化したブランチ
- D: 高周波数な特徴によりバウンダリーを予測するブランチ
として構成されています。
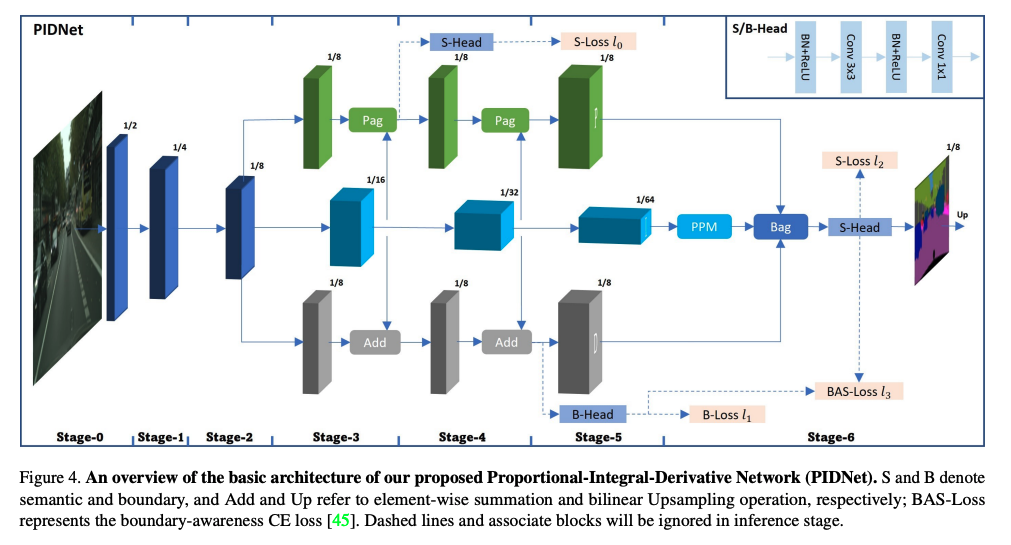
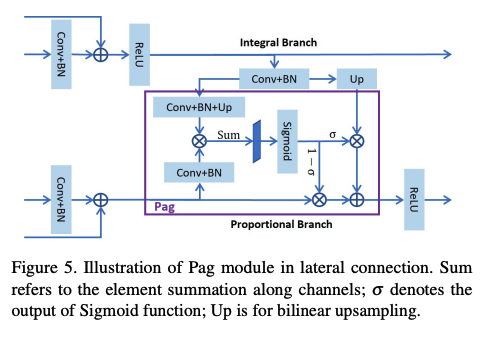
PはPixel-attention-guided fusion module (Pag)を通して、
Iブランチから必要なセマンティクスを選択的に学習できるようにしている。
ただしOverwelm されることなく。ここはセルフアテンションのような実装になっています。
Boundary-attention-guided fusion module (Bag) を使って、3つのブランチの情報を統合します。
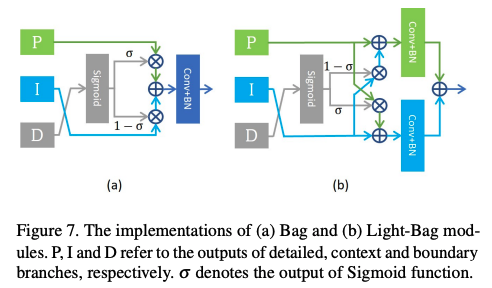
まとめと感想
今回は、セマンティックセグメンテーションタスクにおける近年のAIモデルについて、
いろいろと潮流を理解しながら追いかけてみようとしてみました。
全てを細部まで理解することは難しいですが、画像系AIの基礎知識があれば大体の流れは理解できるはずです。
また、いわゆるAIの知識のみならず、Computer Visonの知識もAIモデルに応用されている様子をみることができ、非常に興味深かったです。
Computer Vison やいろいろな周辺知識もモデル構築のアイディアとして活用され、それらがSoTAを作っているのは非常に素晴らしいことのように感じました。
これからもAIの知識のみならず、いろんな知識をインプットしていくことが大事ですね。
今回はこの辺で。