1.NMeCabとは
MeCabは、工藤拓さまと日本電信電話株式会社によって開発された日本語形態素解析エンジンであり、C++で記述されています。
NMeCabは.この日本語形態素解析エンジンMeCabを .NET環境(C#)に移植したものです。開発者は、Tsuyoshi Komutaさまです。
ver0.07 (日付: 2015-07-08)とそれ以前のソースプロジェクトは、OSDNにて公開されています。
Copying の記載は以下です。
NMeCab was ported from MeCab by Tsuyoshi Komuta, and is released under
any of the GPL (see the file GPL) or the LGPL (see the file LGPL).
ver0.10.0以降は、GitHubにて公開されています。製作者は同様にTsuyoshi Komutaさまです。
NMeCab ver0.10は、従前の ver0.07とはインターフェースが刷新されています。どのような点が変更されており、何を気をつけるべきかについて備忘録がわりに記載します。
Copying の記載は以下です。
NMeCab (this software)
NMeCab is copyrighted free software by Tsuyoshi Komuta, and is
released under any of the GPL (see the file GPL) or the LGPL (see the
file LGPL).
2.ver0.07 における仕様
辞書パスの設定方法
NMeCab ver0.07では、ipadicの辞書パスを app.config の DicDir に設定してください。
ユーザ辞書があれば UserDic に設定してください。
なお、app.config のDicDir に設定されていないとき、libnmecab.dll が格納されているパスの
dicディレクトリ直下を ipadic の辞書パスとします。
<?xml version="1.0"?>
<configuration>
<configSections>
<sectionGroup name="applicationSettings" type="System.Configuration.ApplicationSettingsGroup, System, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089">
<section name="NMeCab.Properties.Settings" type="System.Configuration.ClientSettingsSection, System, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" requirePermission="false"/>
</sectionGroup>
</configSections>
<applicationSettings>
<NMeCab.Properties.Settings>
<setting name="DicDir" serializeAs="String">
<value>..\..\..\..\dic\ipadic</value>
</setting>
<setting name="UserDic" serializeAs="String">
<value/>
</setting>
</NMeCab.Properties.Settings>
</applicationSettings>
</configuration>
形態素解析クラスの初期化
最初、MeCabTaggerクラスを生成してください。
使用終了時には、Dispose関数を呼び出してください。
MeCabTagger tagger = MeCabTagger.Create();
// 各種解析処理・・・
tagger.Dispose();
解析処理(Nodeの出力)
そして、MeCabTaggerクラスのParseToNode関数により、文字列を形態素解析すると、形態素に分解したノード群を得ることができます。殆どの場合、ParseToNode関数だけで済むとおもいます。
//解析処理(Nodeの出力)
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
MeCabNode node = tagger.ParseToNode(line);
}
}
解析処理(latticeモードの文字列出力)
latticeモードの文字列を出力するときには、MeCabTaggerクラスのOutputFormatType変数に "lattice"を設定して、同クラスのParse関数を呼び出します。
//解析処理(latticeモードの文字列出力)
tagger.OutPutFormatType = "lattice";
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
string ret = tagger.Parse(line);
}
}
解析処理(Best解5件のNodeの出力)
ベスト解5件をNode出力するときには、MeCabTaggerクラスのlatticeLevel変数に MeCabLatticeLevel.Oneを設定して、同クラスのParseNBestToNode関数を呼び出します。
//解析処理(Best解5件のNodeの出力)
tagger.LatticeLevel = MeCabLatticeLevel.One;
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
int i = 0;
foreach (MeCabNode node in tagger.ParseNBestToNode(line))
{
if (++i == 5) break;
}
}
}
3.ver0.10.2 における仕様変更
3.1.MeCabTaggerクラス(汎用)
辞書パスの設定方法
MeCabTaggerクラスのCreate関数の引数により、呼び出し元の実行ファイルの相対パスで辞書が指定できます。この点が ver0.10とver0.07との第1の相違点です。
なお、Create関数の第1引数にDicDir が設定されていないとき、libnmecab.dll が格納されているパスの
ipadicディレクトリ直下を ipadic の辞書パスとします。
System.Reflection.Assembly executionAsm = System.Reflection.Assembly.GetExecutingAssembly();
string executingPath = System.IO.Path.GetDirectoryName(new Uri(executionAsm.CodeBase).LocalPath);
String dicDir = executingPath + @"\..\..\..\..\dic\ipadic"; // 辞書のパス
//解析準備処理
GC.Collect();
sw.Start();
MeCabTagger tagger = MeCabTagger.Create(dicDir);
sw.Stop();
// 各種解析処理・・・
tagger.Dispose();
解析処理(Nodeの出力)
taggerクラスのParse関数により、形態素解析を行えます。解析したノードは、MeCabNodeの配列として返されます。これが、ver0.10とver0.07との第2の相違点です。
//解析処理(Nodeの出力)
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
sw.Reset();
GC.Collect();
sw.Start();
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
MeCabNode[] nodes = tagger.Parse(line);
}
sw.Stop();
}
Console.WriteLine("ParseToNode:\t\t{0:0.000}sec\t{1:#,000}byte",
sw.Elapsed.TotalSeconds, GC.GetTotalMemory(false));
解析処理(latticeモードの文字列出力)
ParseToLattice関数で、latticeモードの文字列を取得できます。
//解析処理(latticeモードの文字列出力)
MeCabParam prm = new MeCabParam()
{
LatticeLevel = MeCabLatticeLevel.Two,
Theta = 1f / 800f / 2f
};
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
sw.Reset();
GC.Collect();
sw.Start();
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
MeCabLattice<MeCabNode> ret = tagger.ParseToLattice(line, prm);
}
sw.Stop();
}
Console.WriteLine("Parse(lattice):\t\t{0:0.000}sec\t{1:#,000}byte",
sw.Elapsed.TotalSeconds, GC.GetTotalMemory(false));
解析処理(Best解5件のNodeの出力)
ParseNBest関数で、Best解5件のNodeを出力できます。
//解析処理(Best解5件のNodeの出力)
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
sw.Reset();
GC.Collect();
sw.Start();
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
int i = 0;
IEnumerable<MeCabNode[]> results = tagger.ParseNBest(line);
foreach (MeCabNode[] node in results.Take(5))
{
if (++i == 5) break;
}
}
sw.Stop();
}
Console.WriteLine("ParseNBestToNode:\t{0:0.000}sec\t{1:#,000}byte",
sw.Elapsed.TotalSeconds, GC.GetTotalMemory(false));
3.2.MeCabIpaDicTaggerクラス(IPA辞書に特化)
辞書パスの設定方法
MeCabIpaDicTaggerクラスのCreate関数の引数により、呼び出し元の実行ファイルの相対パスで辞書が指定できます。IPA辞書を使う場合に特化したクラスですので、こちらの利用をお勧めいたします。
なお、Create関数の第1引数にDicDir が設定されていないとき、libnmecab.dll が格納されているパスの
ipadicディレクトリ直下を ipadic の辞書パスとします。
System.Reflection.Assembly executionAsm = System.Reflection.Assembly.GetExecutingAssembly();
string executingPath = System.IO.Path.GetDirectoryName(new Uri(executionAsm.CodeBase).LocalPath);
String dicDir = executingPath + @"\..\..\..\..\dic\ipadic"; // 辞書のパス
//解析準備処理
GC.Collect();
sw.Start();
MeCabIpaDicTagger tagger = MeCabIpaDicTagger.Create(dicDir);
sw.Stop();
// 各種解析処理・・・
tagger.Dispose();
解析処理(Nodeの出力)
taggerクラスのParse関数により、形態素解析を行えます。解析したノードは、MeCabIpaDicNodeの配列として返されます。これが、ver0.10とver0.07との第2の相違点です。
//解析処理(Nodeの出力)
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
sw.Reset();
GC.Collect();
sw.Start();
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
MeCabIpaDicNode[] nodes = tagger.Parse(line);
}
sw.Stop();
}
Console.WriteLine("ParseToNode:\t\t{0:0.000}sec\t{1:#,000}byte",
sw.Elapsed.TotalSeconds, GC.GetTotalMemory(false));
Parse関数で解析されたMeCabIpaDicNodeの配列は、IPA辞書固有の項目を返すメンバー関数によって、各項目を返します。
foreach (MeCabIpaDicNode node in nodes) // 形態素ノード配列を順に処理
{
this.ResultTextBox.Text += $"表層形:{node.Surface}\r\n";
this.ResultTextBox.Text += $"素性 :{node.Feature}\r\n";
this.ResultTextBox.Text += $"品詞:{node.PartsOfSpeech}\r\n";
this.ResultTextBox.Text += $"品詞細分類1:{node.PartsOfSpeechSection1}\r\n";
this.ResultTextBox.Text += $"品詞細分類2:{node.PartsOfSpeechSection2}\r\n";
this.ResultTextBox.Text += $"品詞細分類3:{node.PartsOfSpeechSection3}\r\n";
this.ResultTextBox.Text += $"活用形:{node.ConjugatedForm}\r\n";
this.ResultTextBox.Text += $"活用型:{node.Inflection}\r\n";
this.ResultTextBox.Text += $"原形:{node.OriginalForm}\r\n";
this.ResultTextBox.Text += $"読み:{node.Reading}\r\n";
this.ResultTextBox.Text += $"発音:{node.Pronounciation}\r\n";
this.ResultTextBox.Text += "\r\n";
}
this.ResultTextBox.Text += "EOF\r\n\r\n";
解析処理(latticeモードの文字列出力)
ParseToLattice関数で、latticeモードの文字列が取得できます。
//解析処理(latticeモードの文字列出力)
MeCabParam prm = new MeCabParam()
{
LatticeLevel = MeCabLatticeLevel.Two,
Theta = 1f / 800f / 2f
};
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
sw.Reset();
GC.Collect();
sw.Start();
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
MeCabLattice<MeCabIpaDicNode> ret = tagger.ParseToLattice(line, prm);
}
sw.Stop();
}
Console.WriteLine("Parse(lattice):\t\t{0:0.000}sec\t{1:#,000}byte",
sw.Elapsed.TotalSeconds, GC.GetTotalMemory(false));
解析処理(Best解5件のNodeの出力)
ParseNBest関数で、Best解5件のNodeを出力できます。
MeCabIpaDicNodeの配列のIEnumerableが返されます。
そして、IEnumerableのうちのBest解5件を、Take関数で取り出します。
//解析処理(Best解5件のNodeの出力)
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
sw.Reset();
GC.Collect();
sw.Start();
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
int i = 0;
IEnumerable<MeCabIpaDicNode[]> results = tagger.ParseNBest(line);
foreach (MeCabIpaDicNode[] node in results.Take(5))
{
if (++i == 5) break;
}
}
sw.Stop();
}
Console.WriteLine("ParseNBestToNode:\t{0:0.000}sec\t{1:#,000}byte",
sw.Elapsed.TotalSeconds, GC.GetTotalMemory(false));
PerformanceTestの移植
PerformanceTestは、NMeCab ver0.07 添付のサンプルコードです。これを ver0.10.2 に対応させました。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Diagnostics;
using System.IO;
using NMeCab;
using NMeCab.Specialized;
namespace PerformanceTest
{
class Program
{
static void Main(string[] args)
{
Properties.Settings settings = Properties.Settings.Default;
string targetFile = settings.TargetFile;
Encoding encoding = Encoding.GetEncoding(settings.TargetEncoding);
Stopwatch sw = new Stopwatch();
//開始指示を待機
Console.WriteLine("Press Enter key to start.");
Console.ReadLine();
Console.WriteLine("\t\t\tProcessTime\tTotalMemory");
String dicDir = "../../../../dic/ipadic"; // 辞書のパス
//解析準備処理
GC.Collect();
sw.Start();
MeCabIpaDicTagger tagger = MeCabIpaDicTagger.Create(dicDir);
sw.Stop();
Console.WriteLine("OpenTagger:\t\t{0:0.000}sec\t{1:#,000}byte",
sw.Elapsed.TotalSeconds, GC.GetTotalMemory(false));
//ファイル読込だけの場合
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
sw.Reset();
GC.Collect();
sw.Start();
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
}
sw.Stop();
}
Console.WriteLine("ReadLine:\t\t{0:0.000}sec\t{1:#,000}byte",
sw.Elapsed.TotalSeconds, GC.GetTotalMemory(false));
//解析処理(Nodeの出力)
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
sw.Reset();
GC.Collect();
sw.Start();
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
MeCabIpaDicNode[] nodes = tagger.Parse(line);
}
sw.Stop();
}
Console.WriteLine("ParseToNode:\t\t{0:0.000}sec\t{1:#,000}byte",
sw.Elapsed.TotalSeconds, GC.GetTotalMemory(false));
//解析処理(latticeモードの文字列出力)
MeCabParam prm = new MeCabParam()
{
LatticeLevel = MeCabLatticeLevel.Two,
Theta = 1f / 800f / 2f
};
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
sw.Reset();
GC.Collect();
sw.Start();
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
MeCabLattice<MeCabIpaDicNode> ret = tagger.ParseToLattice(line,prm);
}
sw.Stop();
}
Console.WriteLine("Parse(lattice):\t\t{0:0.000}sec\t{1:#,000}byte",
sw.Elapsed.TotalSeconds, GC.GetTotalMemory(false));
//解析処理(Best解5件のNodeの出力)
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
sw.Reset();
GC.Collect();
sw.Start();
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
int i = 0;
IEnumerable<MeCabIpaDicNode[]> results = tagger.ParseNBest(line);
foreach (MeCabIpaDicNode[] node in results.Take(5))
{
if (++i == 5) break;
}
}
sw.Stop();
}
Console.WriteLine("ParseNBestToNode:\t{0:0.000}sec\t{1:#,000}byte",
sw.Elapsed.TotalSeconds, GC.GetTotalMemory(false));
//対象の情報
using (StreamReader reader = new StreamReader(targetFile, encoding))
{
long charCount = 0;
long lineCount = 0;
long wordCount = 0;
for (string line = reader.ReadLine(); line != null; line = reader.ReadLine())
{
charCount += line.Length;
lineCount++;
MeCabIpaDicNode[] nodes = tagger.Parse(line);
foreach (MeCabIpaDicNode node in nodes) wordCount++;
}
Console.WriteLine();
Console.WriteLine("Target: {0} {1:#,000}byte {2:#,000}char {3:#,000}line ({4:#,000}word)",
targetFile, reader.BaseStream.Position, charCount, lineCount, wordCount);
}
tagger.Dispose();
//終了したことを通知
Console.WriteLine();
Console.WriteLine("Finish!");
Console.WriteLine("Press Enter key to close.");
Console.ReadLine();
}
}
}
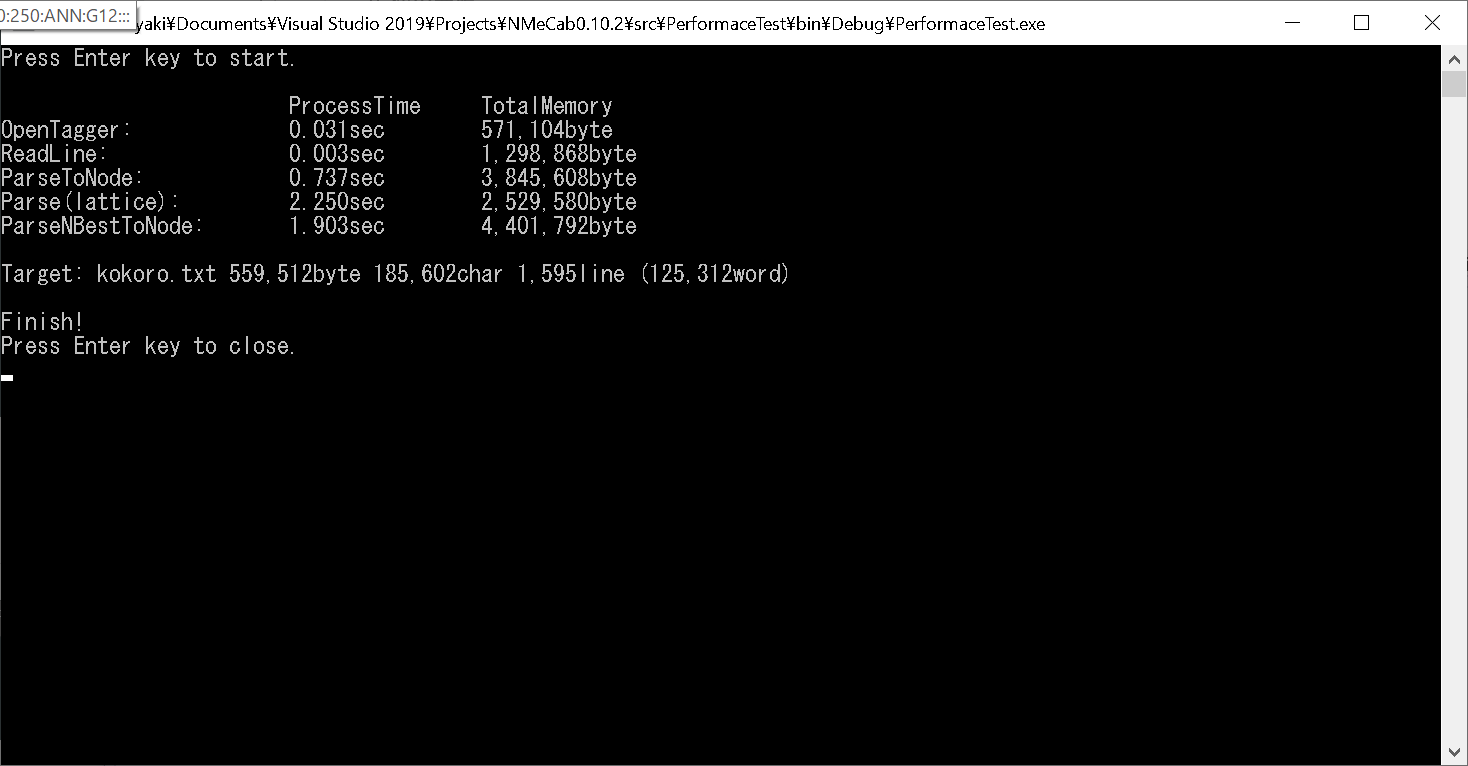
動作結果を以下に示します。
基礎的な使い方
MeCabIpaDicTaggerクラスを生成したのち、文字列を Parse関数で解析すると、
MeCabIpaDicNodeの配列が返り値として戻されます。
これの表層形/読み/品詞/品詞細分類1-3/活用形/活用型/原形/読み/発音を取り出して処理します。
using System;
using NMeCab.Specialized;
class Program
{
static void Main()
{
System.Reflection.Assembly executionAsm = System.Reflection.Assembly.GetExecutingAssembly();
string executingPath = System.IO.Path.GetDirectoryName(new Uri(executionAsm.CodeBase).LocalPath);
String dicDir = executingPath + @"\..\..\..\..\dic/ipadic"; // 辞書のパス
using (MeCabIpaDicTagger tagger = MeCabIpaDicTagger.Create(dicDir)) // IPAdic形式用のTaggerインスタンスを生成
{
MeCabIpaDicNode[] nodes = tagger.Parse("私の名前は中野です。"); // 形態素解析を実行
foreach (MeCabIpaDicNode node in nodes) // 形態素ノード配列を順に処理
{
Console.WriteLine($"表層形:{node.Surface}");
Console.WriteLine($"読み :{node.Reading}"); // 個別の素性
Console.WriteLine($"品詞 :{node.PartsOfSpeech}"); // 〃
Console.WriteLine($"品詞細分類1:{node.PartsOfSpeechSection1}"); // 〃
Console.WriteLine($"品詞細分類2:{node.PartsOfSpeechSection2}"); // 〃
Console.WriteLine($"品詞細分類3:{node.PartsOfSpeechSection3}"); // 〃
Console.WriteLine($"活用形:{node.ConjugatedForm}"); // 〃
Console.WriteLine($"活用型:{node.Inflection}"); // 〃
Console.WriteLine($"原形 :{node.OriginalForm}"); // 〃
Console.WriteLine($"読み :{node.Reading}"); // 〃
Console.WriteLine($"発音 :{node.Pronounciation}"); // 〃
Console.WriteLine();
}
}
Console.Read();
}
}
上記プログラムの出力は以下です。
表層形:私
読み :ワタシ
品詞 :名詞
品詞細分類1:代名詞
品詞細分類2:一般
品詞細分類3:*
活用形:*
活用型:*
原形 :私
読み :ワタシ
発音 :ワタシ
表層形:の
読み :ノ
品詞 :助詞
品詞細分類1:連体化
品詞細分類2:*
品詞細分類3:*
活用形:*
活用型:*
原形 :の
読み :ノ
発音 :ノ
表層形:名前
読み :ナマエ
品詞 :名詞
品詞細分類1:一般
品詞細分類2:*
品詞細分類3:*
活用形:*
活用型:*
原形 :名前
読み :ナマエ
発音 :ナマエ
表層形:は
読み :ハ
品詞 :助詞
品詞細分類1:係助詞
品詞細分類2:*
品詞細分類3:*
活用形:*
活用型:*
原形 :は
読み :ハ
発音 :ワ
表層形:中野
読み :ナカノ
品詞 :名詞
品詞細分類1:固有名詞
品詞細分類2:地域
品詞細分類3:一般
活用形:*
活用型:*
原形 :中野
読み :ナカノ
発音 :ナカノ
表層形:です
読み :デス
品詞 :助動詞
品詞細分類1:*
品詞細分類2:*
品詞細分類3:*
活用形:特殊・デス
活用型:基本形
原形 :です
読み :デス
発音 :デス
表層形:。
読み :。
品詞 :記号
品詞細分類1:句点
品詞細分類2:*
品詞細分類3:*
活用形:*
活用型:*
原形 :。
読み :。
発音 :。
NMeCabで UniDic を使用する際の備忘録を以下の記事に記載しました。