やりたいこと
- kerasのConv2Dを理解したい
- それにより下記のようなコードを理解したい(それぞれの関数が何をやっているのか?や引数の意味を説明できるようになりたい)。
from keras import layers, models
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3)))
- そして画像分類モデルをpythonで実装したい(犬の写真と猫の写真を判別できるなど)
この記事を読んで理解できること
- 「畳み込みって何ですか?」がざっくりわかる。
- 「kerasのConv2D関数に渡す引数の値はどうやって決めればいいですか?」がざっくり分かる。
- 「カーネル」「フィルタ」「ストライド」の意味が理解できる。
Conv2Dとは?
「keras Conv2D」で検索すると「2次元畳み込み層」と出てくる。
では「2次元畳み込み層」とは何なのか?
なお「1次元畳み込みニューラルネットワーク」という言葉もある。
よって「1次元と2次元はどう違うのか?」を理解する前提として、
「畳み込みニューラルネットワーク」や「畳み込み」を理解する必要がある。
CNNとは?
Convolutional Neural Network のこと。
Convolutional : 畳み込み
Neural Network : ニューラルネットワーク
なので、CNNは「畳み込みニューラルネットワーク」である。
CNNについて理解を深める参考情報
https://www.atmarkit.co.jp/ait/articles/1804/23/news138.html
によると下記の通り。
- 「画像の深層学習」と言えばCNNというくらいメジャーな手法である。CNNはConvolutional Neural Networkの頭文字を取ったもので、ニューラルネットワークに「畳み込み」という操作を導入したものである。
- 畳み込み(convolution)とは、カーネル(またはフィルタ)と呼ばれる格子状の数値データと、カーネルと同サイズの部分画像(ウィンドウと呼ぶ)の数値データについて、要素ごとの積の和を計算することで、1つの数値に変換する処理のことである。この変換処理を、ウィンドウを少しずつずらして処理を行うことで、小さい格子状の数値データ(すなわちテンソル)に変換する。
基本的な考え方
そもそも「画像」とは何か?
jpgなどの画像ファイルは、横(width)と縦(height)、それぞれピクセル数が決まっている。
たとえば、width:300px で height:200px の写真があるとする。
1個のピクセルを■(正方形)で表現するならば
その写真は、300 x 200 = 60000個の■を並べたものである。
なので、width:5px かつ height:5px で、計25個の■が存在する場合は、下図のようになる。

さらに白黒写真の場合、
- それぞれの■がブラックまたはホワイトのいずれかである
- ブラックを■(黒塗り)で表現し、ホワイトを□(白抜き)で表現する
ならば「白背景に黒文字で×(バツ)を描く」場合、下図のようになる。

同様に、プラス記号(+)なら、

であり、マイナス記号(―)なら、

であり、イコール記号(=)なら、

である。
「小さな区分に着目して特徴を調べる」という考え方
白背景に黒文字でバツ

という画像データに対して「小さな区分に着目して特徴を調べる」とどうなるか?
たとえば赤枠および青枠で囲った部分に着目してみる。

この領域は、いずれも
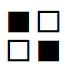
である。つまり「赤枠部分と青枠部分は特徴が同じである」ということが分かる。
ここで、
のような「特徴を示すデータ(特徴検出器)」のことを
カーネル
と呼ぶ(フィルタと呼んだりもする。意味は同じである)。
言い換えると「5 x 5」の元画像の特徴を把握したければ、
元画像を細かく分割して、それぞれを「2 x 2」のカーネルと比較していけばよい、ということである。
これが「画像を判定する」とか「画像の特徴や他画像との違いを識別する」という考え方になる。
「畳み込み」とは何か?
Conv2Dを理解するためには「2次元畳み込み層」を理解する必要がある。
そのためには、まず「畳み込み層」を理解する必要がある。
では「畳み込み」とは何なのか?
ざっくり言うと、下記のとおり。
- 元画像とカーネル(フィルタ)を比較して計算し、その計算(行列演算)結果を出力して並べていく処理のことを「畳み込み」という。
- 畳み込んだ出力結果を「特徴マップ」と呼ぶことがある。
- 畳み込みによって出力されたデータは、元画像のデータよりも小さくなる。
5 x 5 の元画像と 3 x 3 のカーネル(フィルタ)で「畳み込み」をした出力結果(特徴マップ)は 9マス(3 x 3) になる
5 x 5 の元画像に対して、3 x 3 のカーネルで畳み込みを実行する場合、
1マスずつズラしていく(このことを「ストライド(ズラすピクセル数)が1である」という)
なら、合計9回の行列計算を実施することになる。
そのため、計算結果を出力して並べたら、9回分つまり「特徴マップは9マス」となる。
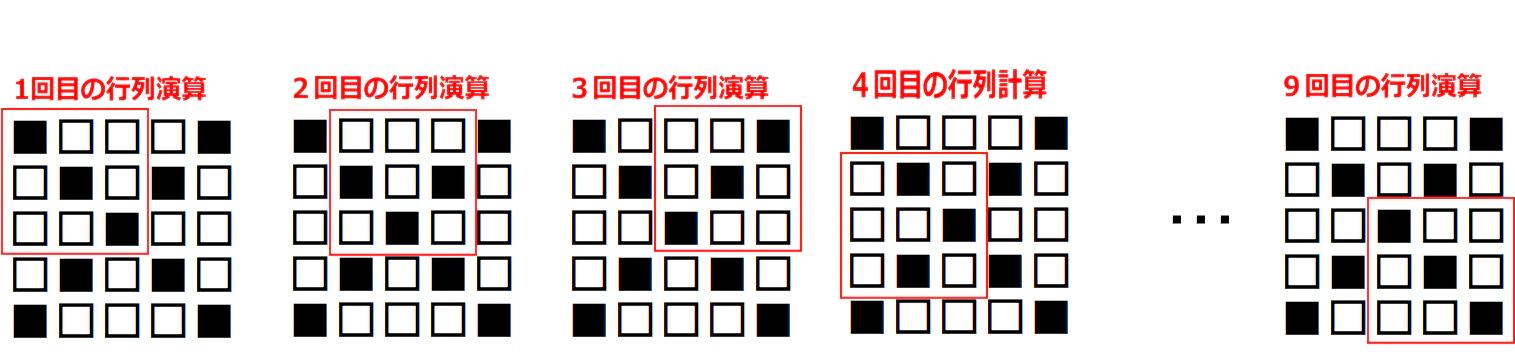
赤枠はカーネルと比較する対象、つまり「着目する領域(ウインドウ、と呼んだりする)」である。
元画像の左上から右下へ向かって1マス(1ピクセル)ずつズラして行列演算を繰り返していく。
この場合、9回の演算を実施するので、特徴マップは9マス(3 x 3)になる。
1ピクセルずつズラして計算することを「ストライドが1である」という。
2ピクセルずつズラして計算するならを「ストライドが2である」という。
具体的な計算例
上図の「1回目の行列演算」を、実際にやってみる。
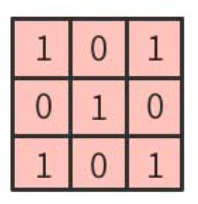
行列計算の手順は下記。左図の赤枠部分(ウインドウ)と、右図(カーネル)とを行列演算する。

ちなみに、ここで挙げたカーネルは一例であり、
実際の畳み込みでは「カーネルの縦横サイズは3x3以外にも、任意に指定できる」
かつ「カーネルは一種類だけではなく、複数種類使って畳み込む」という点に注意する(詳細は後述)。
さて、行列演算は
- 元画像の一部(ウインドウ)とカーネルを比べて、同じ位置にある要素同士を掛け算する
- その掛け算で求めた各値を全部足す
ことにより、出力結果が求まる。
分かりやすくするために、数値を入れてみる。
ここでは、
黒を -1
白を 1
とする。

左上のマスから右下のマスに向かって、順番に(全部で9回)計算していくと、下記のようになる。
-1 x 1 = -1(上段の左同士を掛け算する)
1 x 1 = 1(上段のセンター同士を掛け算する)
1 x 1 = 1(上段の右同士を掛け算する)
1 x -1 = -1(中段の左同士を掛け算する)
-1 x -1 = 1(中段のセンター同士を掛け算する)
1 x -1 = -1(中段の右同士を掛け算する)
1 x 1 = 1(下段の左同士を掛け算する)
1 x 1 = 1(下段のセンター同士を掛け算する)
-1 x 1 = -1(下段の右同士を掛け算する)
左辺が「元画像の一部における一つのマスの値」であり、
右辺が「カーネルにおける一つのマスの値」である。
そして、答えを「全部足す」と、
SUM(-1, 1, 1, -1, 1, -1, 1, 1, -1)
であるから、結果は 1 である。
この 1 は「特徴マップの左上」に並べるので、
特徴マップは下記になる。

このように計算を続けていけば、特徴マップの残り8マスにも数値が入る。
このような計算を実施することが「畳み込む」ことである。
別の言い方をすれば「畳み込みとは、元画像とカーネルを行列計算して、その結果を特徴マップに出力していく作業」である。
しかし、このような畳み込み(行列計算)を手動でやるのは大変である。
よって、kerasのConv2Dのような関数を使って計算する。
kerasの関数である Conv2D() に渡す引数の意味
冒頭のサンプルコードについて。
from keras import layers, models
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3)))
この中で使われている Conv2D()
Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3))
の引数が何を意味するのか調査する。
4つの引数を渡している。
Conv2D(
32,
(3,3),
activation="relu",
input_shape=(150,150,3)
)
kerasの公式ドキュメント
https://keras.io/ja/layers/convolutional/#conv2d
の記載は以下の通り。
keras.layers.Conv2D(
filters,
kernel_size,
strides=(1, 1),
padding='valid',
data_format=None,
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None
)
まずは第一引数から見ていく。
公式ドキュメントの記載は下記の通り。
filters : 整数で、出力空間の次元(つまり畳み込みにおける出力フィルタの数)。
このコードでは、32 を渡している。
つまり「出力フィルタ数は32」を指定している。
では「出力フィルタ」とは何なのか?
そもそも「フィルタ」とは何か?
畳み込みにおける「カーネルとは何か?」については前述した。
ここで「カーネル」のことを「フィルタ」と呼ぶ場合もあることを知っておく必要がある。
つまり、第一引数の filters は「フィルタ」であり「カーネル」であるから、
カーネルに関する設定値であることが分かる。
https://qastack.jp/stats/154798/difference-between-kernel-and-filter-in-cnn
では、下記のような質疑応答がなされている。
-
質問:畳み込みニューラルネットワークの「カーネル」と「フィルタ」の違いは何ですか?
-
回答:同じ意味です。カーネルのことをフィルタと呼んだりします。
よって、結論としては
- カーネルは「フィルタ」であり「特徴検出器」である。すべて同じ意味である。
となる。
であれば「出力フィルタ数が32」は「出力カーネル数が32」という意味である。
畳み込みのおさらい
5x5の入力画像

に対して、3x3のフィルタ(カーネルとも呼ぶ)
にて畳み込みをする場合。
下図のように1マスずつズラして計算するなら、合計9回の計算を実施するので、答え(特徴マップ)は9マス(3x3)になる。
(ちなみに、このような1マスずつスライドする畳み込みのことを「ストライドが1である」と表現する。
ストライドの値が大きくなるほど、計算の回数は少なくなる)
ストライドとは?
何マスずつズラして計算するか?の、ズラす値。
ストライドが1なら

となる。
ストライドが2なら

となる。
では、下記条件における畳み込みで、特徴マップの縦横は何x何になるか?
- 入力画像は 25 x 25 である。
- フィルタ(カーネル)は 5 x 5 である。
- ストライドは 2 である。
答えは 11 x 11 となる。
スプレッドシートなどで方眼を書いて実際に手でズラしながら数えてみると理解できる。
25 x 25 の方眼がある。これを入力画像とする。
重なっているピンク枠(5x5)がフィルタ(カーネル)である。
ストライドが 2 なので、2マスずつズラして計算していく。
11回目の計算で右端にたどり着く。
縦も同様なので、特徴マップは 11 x 11 となる。

Conv2D関数に渡す引数をどうやって決めればいいのか
以上の知識を前提として、畳み込みの実行に必要なパラメータを考える。
具体的には、下記の問いに答える必要がある。
- 質問(1): 畳み込みで利用したいカーネル(フィルタ)の縦横ピクセル数は、何x何ですか?
- 質問(2): 畳み込みで識別したい画像(つまり入力画像)の縦横ピクセル数は、何x何ですか?
- 質問(3): ストライドの値はいくつですか?(何ピクセルですか?)
他にも問いはあるだろうが、このような問いに答えることが、すなわち「関数に渡す引数の値を決めること」である。
フィルタ(カーネル)の縦横サイズの決め方について
https://child-programmer.com/ai/keras/conv2d/
の記載を抜粋する。
Conv2D(16, (3, 3)の解説
:「3×3」の大きさのフィルタを16枚使うという意味です(16種類の「3×3」のフィルタ)。
「5×5」「7×7」などと、中心を決められる奇数が使いやすいようです。
フィルタ数は、「16・32・64・128・256・512枚」などが使われる傾向にあるようですが、
複雑そうな問題ならフィルタ数を多めに、簡単そうな問題ならフィルタ数を少なめで試してみるようです。
ここで、フィルタに関する値は
- 1つのフィルタの縦横サイズは、何x何ピクセルか?(ピクセル値)
と
- その縦横サイズのフィルタを、何枚使うのか?(枚数)
があるので混同しないように注意する。
縦横サイズについては、これまで解説したとおり。
下記の例では、フィルタの縦横サイズは「5 x 5」である(ピンク塗の領域は5x5=25ピクセルの正方形である)。

では「フィルタ数(何枚使うのか?その枚数)」は、どういう意味か?
畳み込みを実施するにあたり、フィルタの種類は1種類ではない。
「1種類」では「1つの特徴」を示すに過ぎない。
たとえば、3x3のフィルタがあった場合、フィルタの種類としては、たとえば

など、いろいろ存在しうる。これが「フィルタの種類」であり「フィルタの枚数」つまり「フィルタ数」である。
まとめると、
Conv2D(16, (3, 3)
は「縦横ピクセル3x3のフィルタを、16枚(16種類)使って畳み込みをしなさい」
という命令である。
「フィルタ数」に関する補足
「複数のフィルタ、たとえば16種類(16枚)のフィルタを使って畳み込む」ことの意味について深く知りたい場合は
https://products.sint.co.jp/aisia/blog/vol1-16
に記載の「畳み込み層(Convolutional layer)」を参照のこと。
抜粋すると下記。
- フィルタは自動作成され、学習により変わってゆく(誤差逆伝搬)。
- フィルタの数だけ特徴マップが出力される。
「フィルタの数だけ特徴マップが出力される」ということは、
16種類(16枚)のフィルタで畳み込みを実施したら、
16個の「特徴マップ」が出力される、という意味である。
ここでは説明を簡単にするために
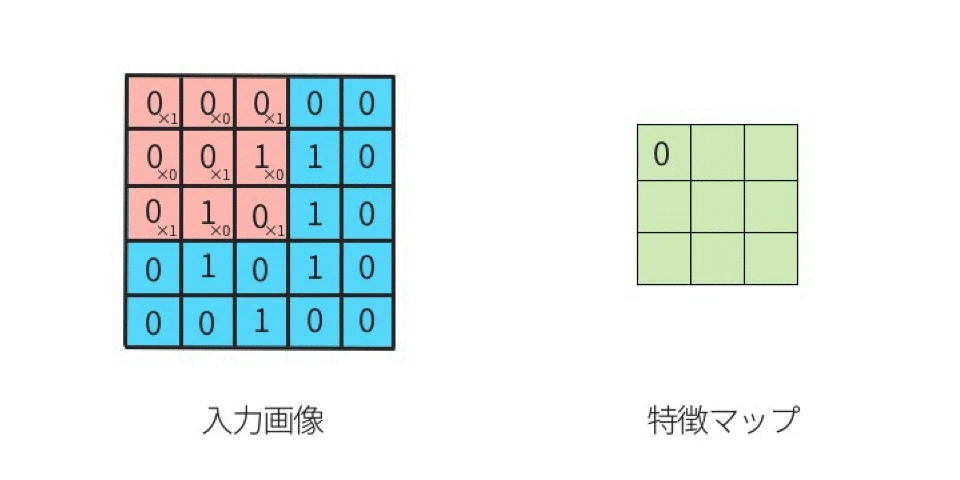
「3枚のフィルタで畳み込みを実施する」ケースを考える。
たとえば下図は、フィルタ(ピンク塗り領域)が2x2であり、
特徴マップ(グリーン塗り領域)は3x3である。

フィルタ(ピンク塗り領域)の種類が1つだけなら、
特徴マップ(グリーン塗り領域)も1つしか出力されない。
しかし、フィルタを3種類準備したら、
それぞれの種類で行列計算を行うため、
特徴マップもそれぞれ異なる結果になるゆえに、3つの特徴マップが出力される。

冒頭のサンプルコードを見てみる
冒頭のサンプルコード
from keras import layers, models
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3)))
では、
Conv2D(32,(3,3)
と書かれている。
これは「3x3のフィルタ(カーネル)を、32種類(32枚)用いて、畳み込みをしなさい」という命令である。
以上で、
- 質問(1): 畳み込みで利用したいカーネル(フィルタ)の縦横ピクセル数は、何x何ですか?
に対する答えの決め方(引数の渡し方)は理解できた。
引き続き、
- 質問(2): 畳み込みで識別したい画像(つまり入力画像)の縦横ピクセル数は、何x何ですか?
を考察する。
input_shape とは何か?
https://child-programmer.com/ai/keras/conv2d/
から抜粋すると下記。
input_shape=(28, 28, 1)の解説
:縦28・横28ピクセルのグレースケール(白黒画像)を入力しています。
つまり、冒頭サンプルコードの
input_shape=(150,150,3)
なら
「入力画像の縦横ピクセルは 150 x 150 である」
となる。では 3 は何を意味するのか?
公式ドキュメント
https://keras.io/ja/layers/convolutional/#conv2d
には
RGB画像ではinput_shape=(128, 128, 3)となります.
とある。
白黒画像なら1
RGBなら3
であるため、色の数(RGBならレッド、グリーン、ブルーの3種類)と考えられる。
普通の写真(.jpg)ならRGBなので、3を設定しておけば問題ないだろう。
activation とは何か?
サンプルコード
model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3)))
に書かれている
activation="relu"
はどういう意味か?
https://child-programmer.com/ai/keras/conv2d/
での説明は下記。
activation=relu の解説
:活性化関数「ReLU(Rectified Linear Unit)- ランプ関数」。
フィルタ後の画像に実施。入力が0以下の時は出力0。入力が0より大きい場合はそのまま出力する。
https://keras.io/ja/layers/convolutional/#conv2d
での説明は下記。
activation: 使用する活性化関数の名前(activationsを参照)
何も指定しなければ,活性化は一切適用されません
つまり、
activation="relu"
は「活性化関数としてReLUを使いなさい」という命令になる。
活性化とは?
活性化するための関数が「活性化関数」である。では「活性化」とは?
活性化を理解するための文脈を集めたら下記の通り。
- 活性化関数は、ニューラルネットワークに欠かせないものである。 https://qiita.com/omiita/items/bfbba775597624056987
- 活性化関数のデファクトスタンダートは「ReLU」である。 https://qiita.com/omiita/items/bfbba775597624056987
- 活性化関数を用いるのは、モデルの表現力を増すためである。 https://ai-trend.jp/basic-study/neural-network/activation_function/
- 代表的な活性化関数として「ステップ関数」「シグモイド関数」「ReLU関数」などがある。 https://ai-trend.jp/basic-study/neural-network/activation_function/
まとめると、
「活性化関数を指定すればモデルの表現力が増す(賢いAIが作れる)から活性化関数を指定しましょう」そして「標準的に使われるのはReLUですよね」といった感じ。
ストライドの指定について
- 質問(3): ストライドの値はいくつですか?(何ピクセルですか?)
だが、これは
strides = 1
のように指定する。詳細は
https://keras.io/ja/layers/convolutional/#conv2d
を参照。
まとめ
以上のとおり、
model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(150,150,3)))
が何をやっているのか? それぞれの引数は何を意味するのか?
がざっくり理解できた。
この章の目的は「kerasのConv2D(2次元畳み込み層)を理解すること」なので、
いったんここまでにする。
Sequential() や MaxPooling2D() については別の章で調査していく。