前回 はデータ仮想化を利用したデータのクエリや取り込みを試しました。今回は SQL Server 2019 ビッグデータクラスター (BDC) の特徴でもある Spark を利用してみます。
Spark とは
Spark は大量データを効率よく処理できるため、ビッグデータを扱うプロジェクトではよく利用されています。Azure でも Azure Databricks や Azure HDInsight などで Spark をサポートしてきましたが、SQL Server 2019 ビッグデータクラスターでも利用可能となりました。
この記事では MSSQL Spark コネクタを使用して Spark から SQL Server に対する読み取りと書き込みを行う方法 を深堀します。ドキュメントの手順は一部古いため、手順が異なります。フィードバックしないとなぁ。
Azure Data Studio と Notebook
BDC へ接続して Spark ジョブを実行する方法はいくつかりますが、GUI でやりやすいため、Azure Data Studio と Notebook を使います。
Notebook はこれまでの SQL Server Management Studio のクエリ実行画面と異なり、クエリ(コード)と結果、またマークダウン形式での文章を保持できる仕組みです。詳細は今回使っている際に紹介しますが、コードを実行する機能だと思っておいてください。
シナリオ
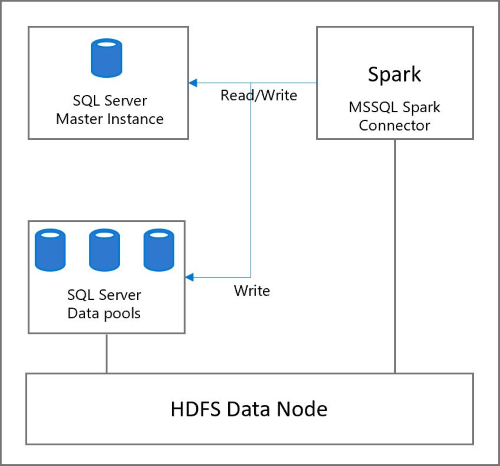
Spark の利用シナリオは多岐に渡りますが、基本はデータ処理を行う際に利用するため、データの読み込みと書き出しを行います。読み込み元や書き出し先はシナリオに合わせて自由に組み合わせできます。
事前準備
サンプルを実行するにあたり、いくつか準備をします。
1. 今回 Notebook で実行する ipynb ファイルを 2 つダウンロード。
mssql_spark_connector_user_creation.ipynb
mssql_spark_connector_sparkr.ipynb
2. データとして AdultCensusIncome.csv をダウンロード。
AdultCensusIncome.csv
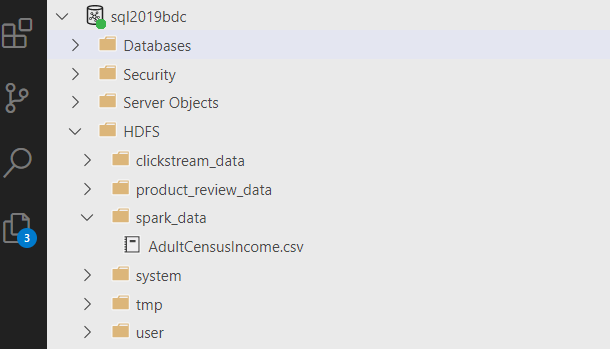
3. ADS から BDC に接続し、HDFS 配下に spark_data フォルダを作成して、ファイルをアップロード。
データベース、ユーザーなどの作成
まずはデータを取り込むための準備を行います。実行は T-SQL で行いますが、Notebook 上で実行します。
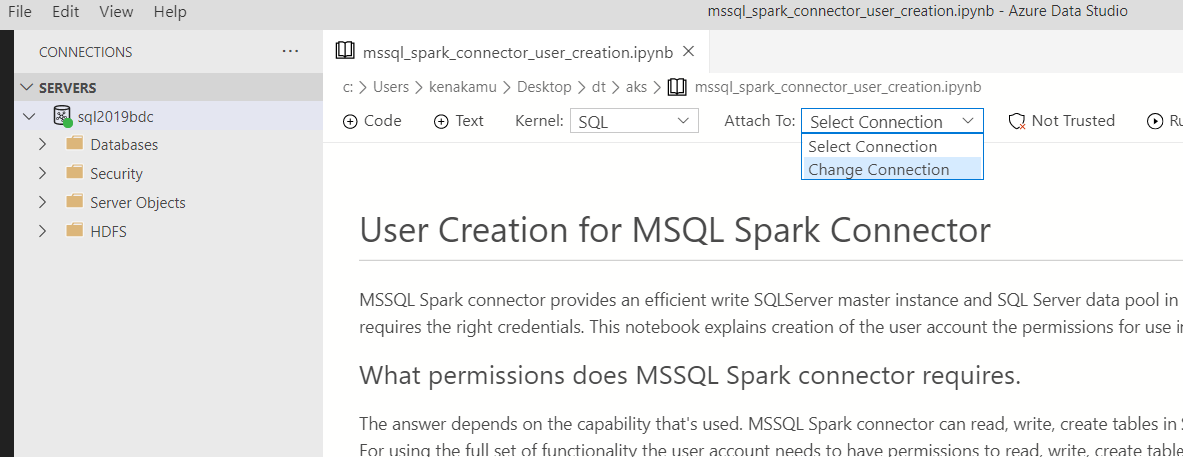
1. File | Open File より mssql_spark_connector_user_creation.ipynb を開き、[Attach To] から [Change Connection] を選択。
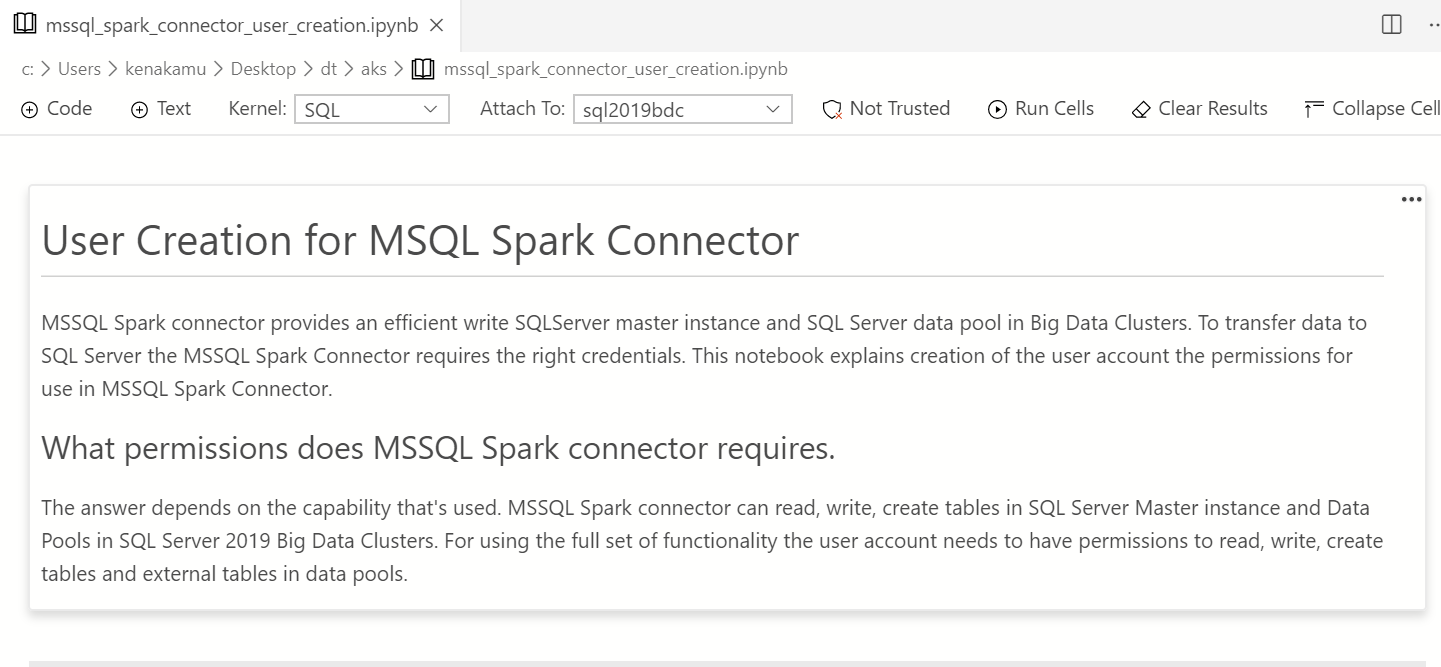
2. Notebook は複数のセルで構成されており、はじめのセルは説明が記載されている。ここに Notebook の中身が書かれているので一読。
3. 2つ目のセルの実行アイコンをクリック。

4. 結果が表示される。データベースができていることも確認。
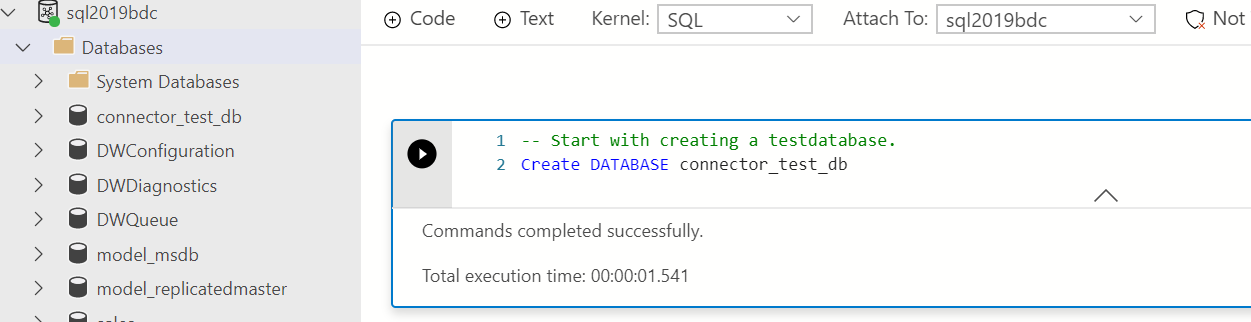
5. 2 つ目のセルも実行。ここではユーザーの作成および権限の付与を実行。
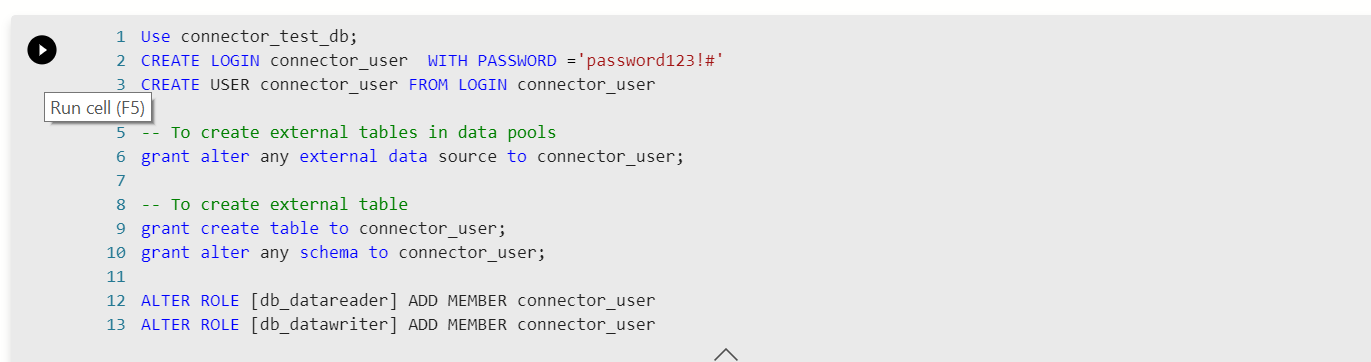
6. 3 つ目のセルを実行。ここでは外部データソースとして connector_ds を作成し、ダミー外部テーブルを作成。
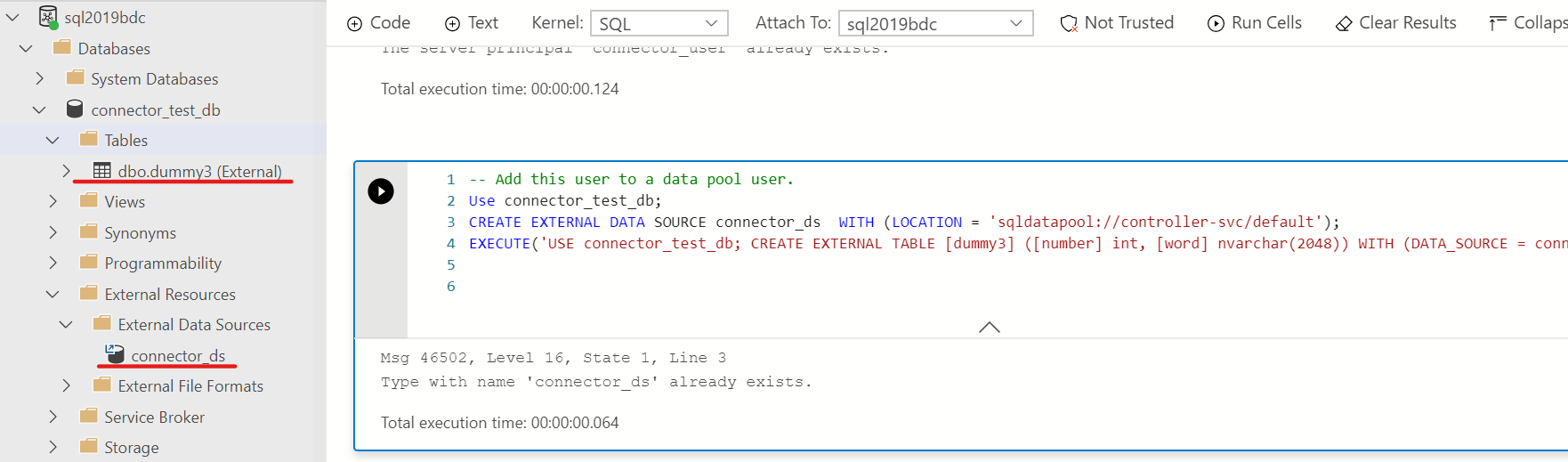
7. 最後のセルを実行。作成したユーザーに対してデータソースの権限を付与。
尚、Notebook は画面上部の [Run Cells] をクリックすると一括で実行も可能。
Spark を使ってマスターインスタンスの読み書き
1 つ目のシナリオでは HDFS にアップロードした CSV を読みこみ、マスターインスタンスへ書き込みを行います。
1. mssql_spark_connector.ipynb を開き、BDC に接続。初めの説明を一読。また今回 [Kernel] が [PySpark] であることを確認。
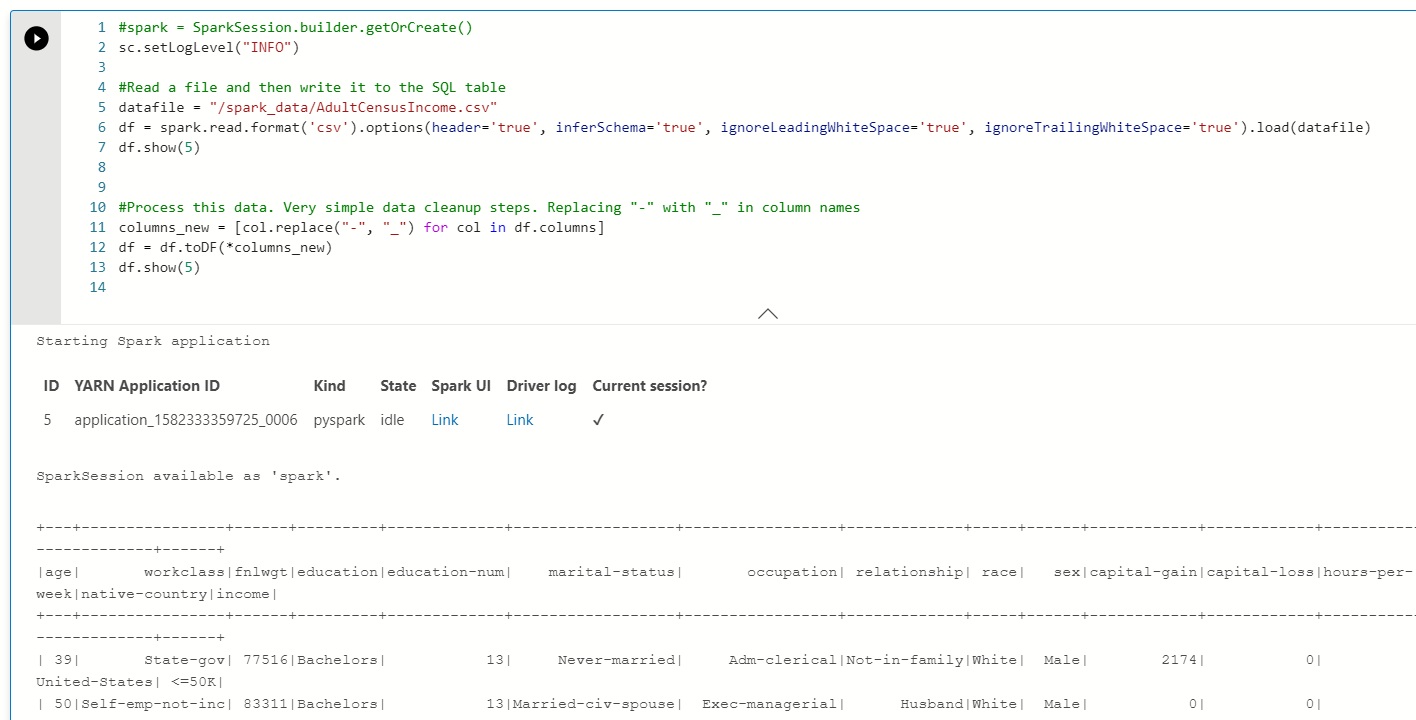
2. まず csv の読込み。結果ペインに Spark ジョブの情報と結果が表示される。
- dataFile でデータソースを指定
- df 変数にデータを読み込み
- df.show(5) で初めの 5 件を表示
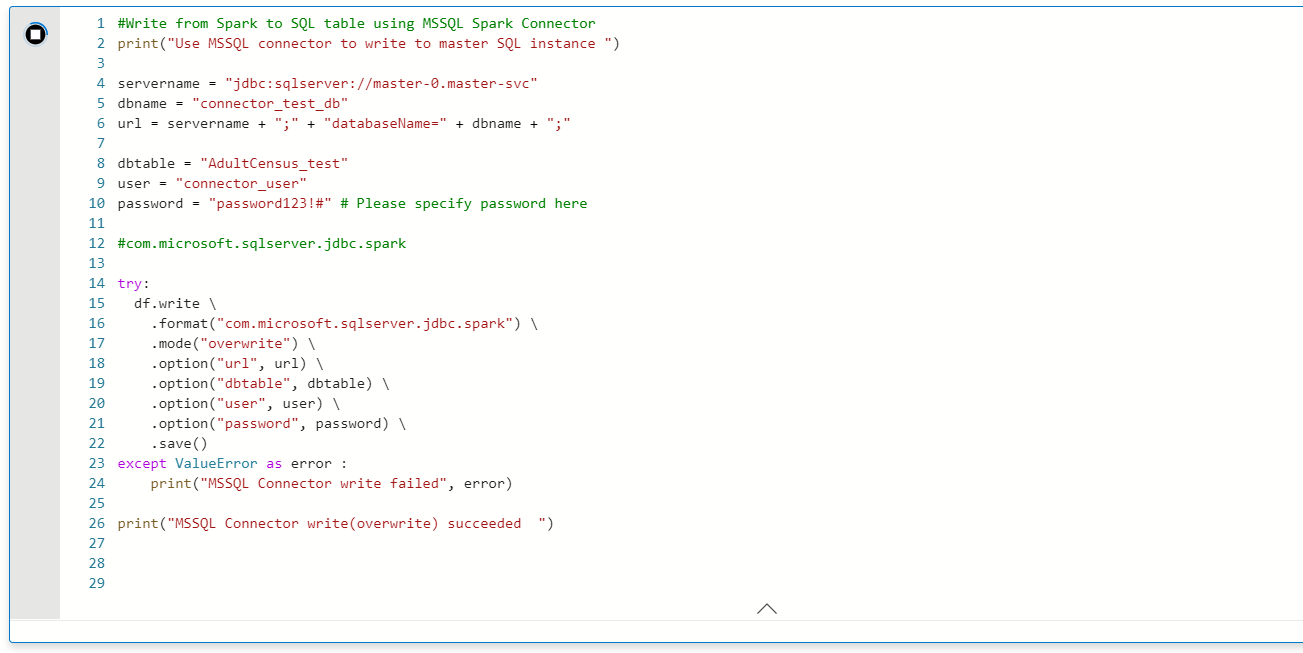
3. ここから Part 1 の内容となる。df に読み込んだデータを SQL マスターに書き込み。
- df.write で jbdc 経由で書き出し
- overwrite モードを指定しているため、データは上書き
4. 次のセルでは append モードで書き込み。

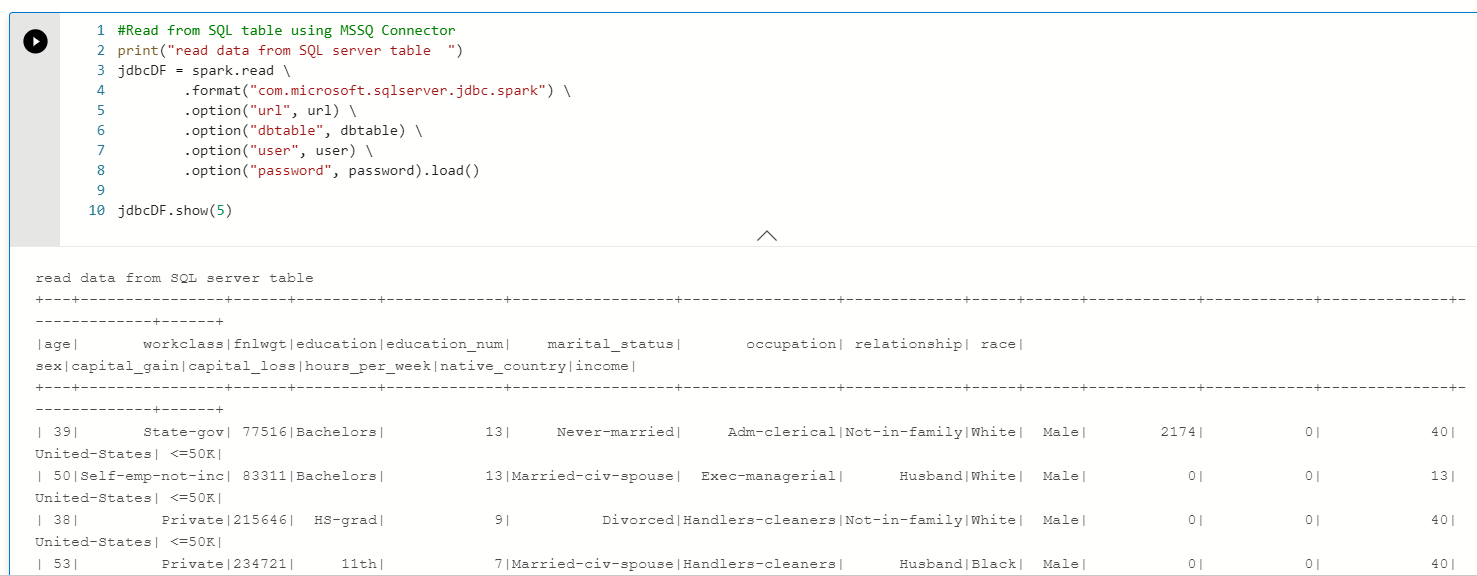
5. 最後に Spark を使ったデータの読み取りを実行。
- spark.read で jbdc 経由で読み込み
- show で表示
Spark を使ったデータプールへの読み書き
2 つ目のシナリオは外部テーブルに対するデータの読み書きを行います。外部テーブルであるため、結果としてデータプールにデータが保存されます。
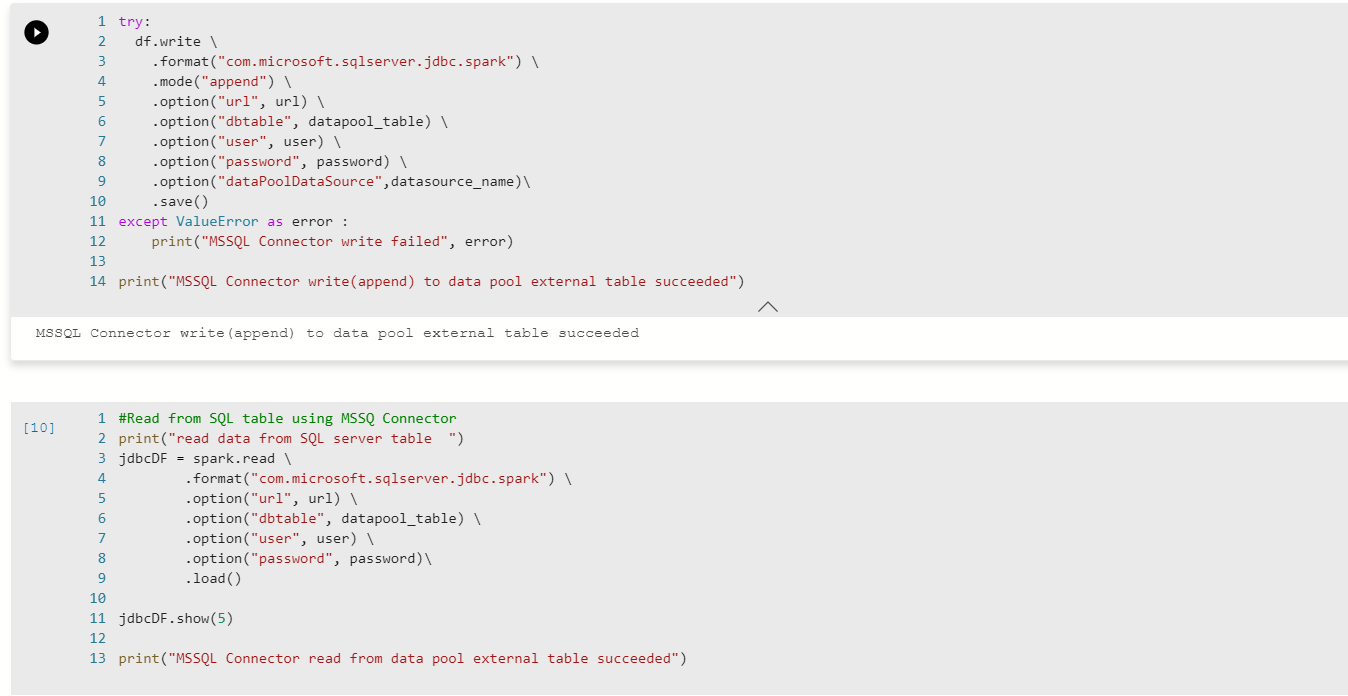
1. まずは overwrite でデータの上書き。
- option として dataPoolDataSource を指定

2. 残りのセルではデータの append と読み取りを実施。処理内容は同じ。
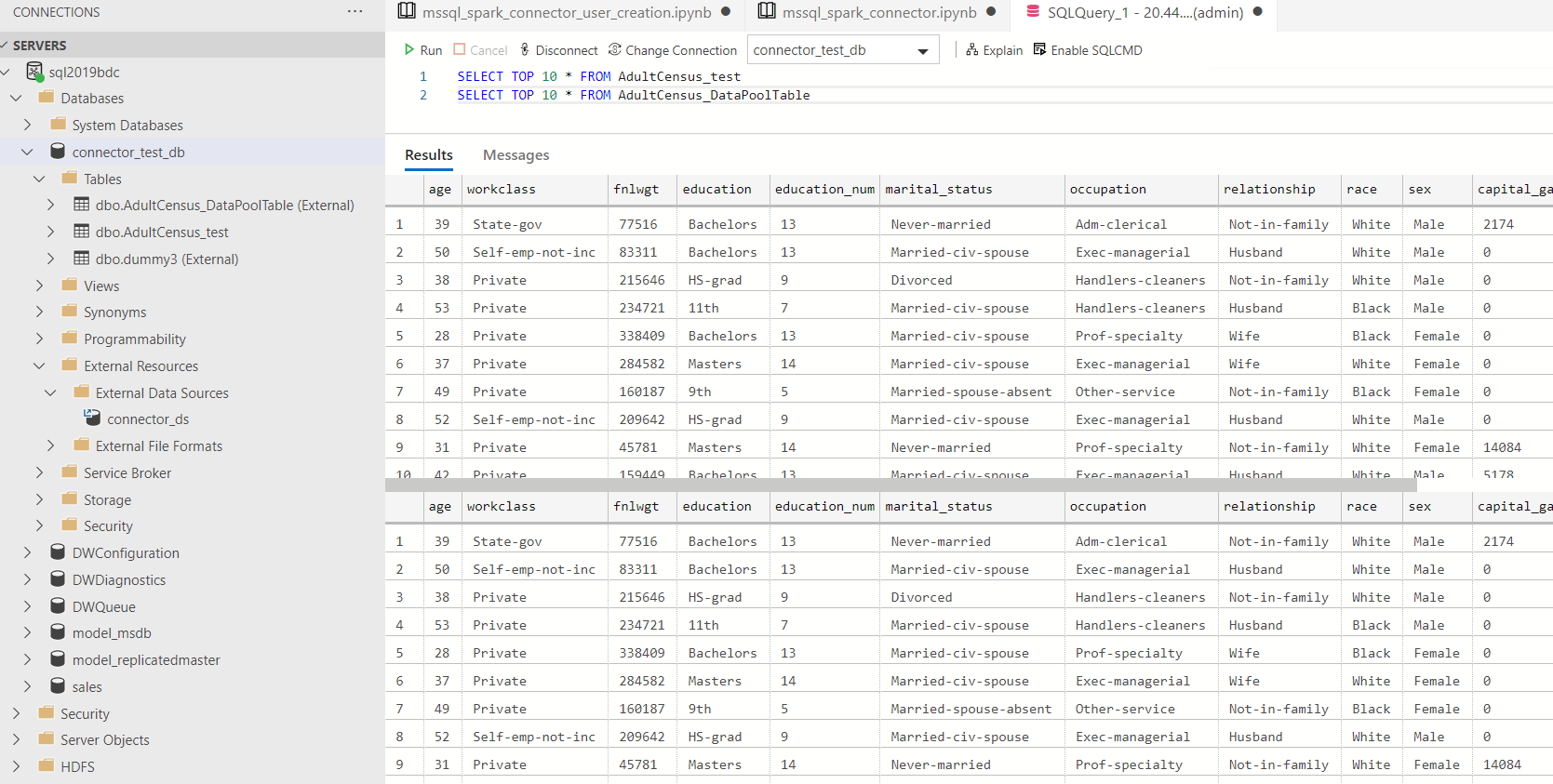
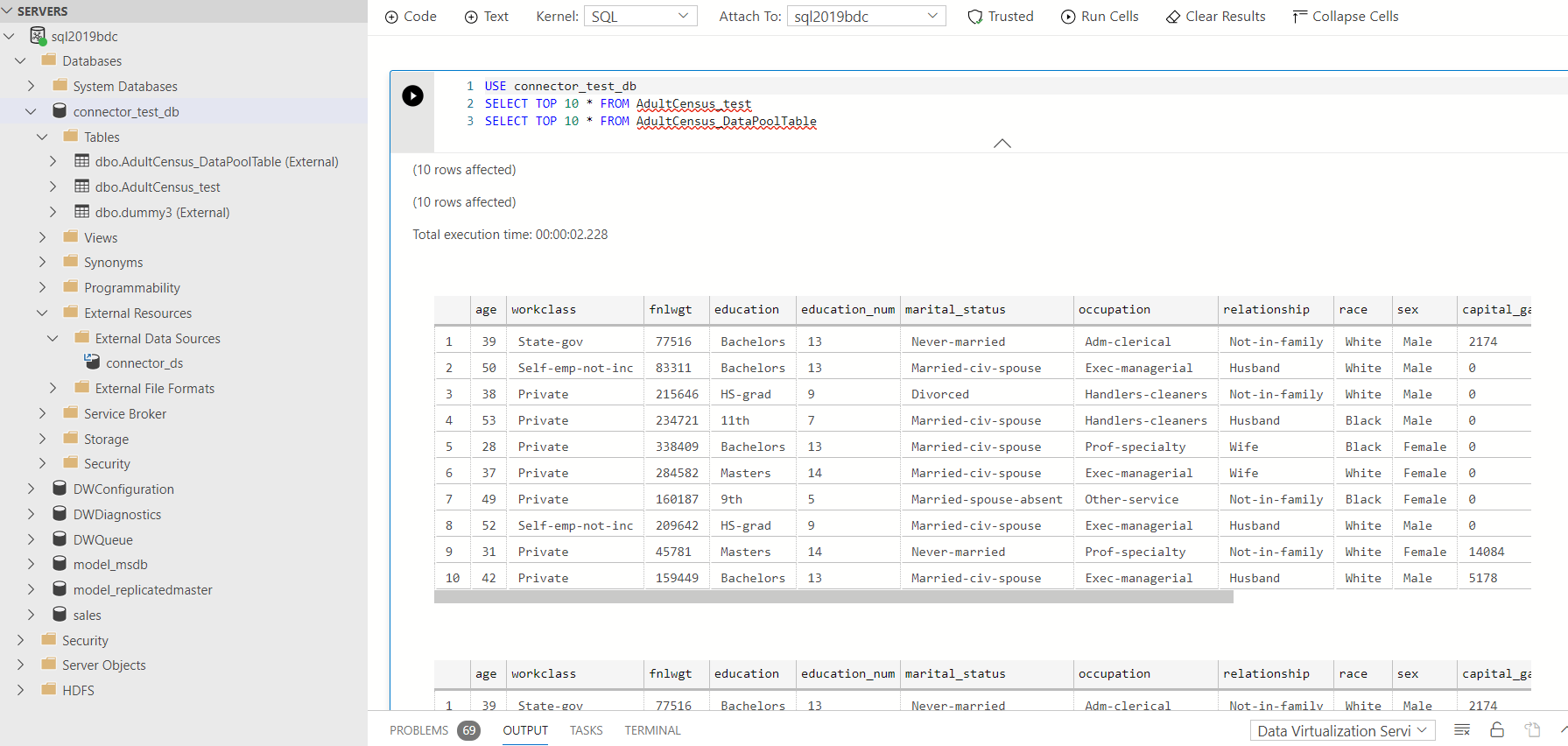
作成したデータをクエリ
クエリは Notebook 経由でもクエリエディター経由でも行えます。
[クエリエディター]
[Notebook]
まとめ
SQL Server 2019 BDC は全てが T-SQL で出来るという観点でよく語られますが、実は Spark エンジニアにとっても、これまでのスキルセットで SQL Server が使えるという事が分かりました。これから Spark も勉強しようと思います。