サンプルデータを試すで HDFS 上にある CSV をデータ仮想化でクエリする方法を見ていきましたが、今回は外部のリレーショナルデータベースをデータ仮想化機能でクエリしてみます。
以下記事では Oracle をクエリしますが、本記事では Azure SQL をクエリします。
参照:チュートリアル:SQL Server ビッグ データ クラスターから Oracle にクエリを実行する
Azure SQL の用意
クイック スタート:Azure portal、PowerShell、Azure CLI を使用して Azure SQL Database で単一データベースを作成します を参考にデータベースを作成します。
1. リソースグループを作成。
az group create --name azuresql --location japaneast
2. SQL Server を作成。
- 名前は kenakamuazuresql としているが、グローバルで一意のものを指定
- 任意のロケーション、ユーザー名、パスワードを指定
az sql server create --name kenakamuazuresql -g azuresql --location eastus --admin-user <adminname> --admin-password <password>
3. ファイアウォールルールを作成。
- 1 つ目はローカルクライアント用
- 2 つ目は Azure リソース用
az sql server firewall-rule create -g azuresql -s kenakamuazuresql -n AllowYourIp --start-ip-address <your ip address> --end-ip-address <your ip address>
az sql server firewall-rule create -g azuresql -s kenakamuazuresql -n AllowAzureAccess --start-ip-address 0.0.0.0 --end-ip-address 0.0.0.0
4. データベースを作成。
- スペックは任意で設定
- AdventureWorksLT サンプルデータベースを復元
az sql db create -g azuresql -s kenakamuazuresql --name azuresqldb --sample-name AdventureWorksLT --edition GeneralPurpose --family Gen5 --capacity 2
作成できるとリソースグループに SQL Server とデータベースが表示されます。
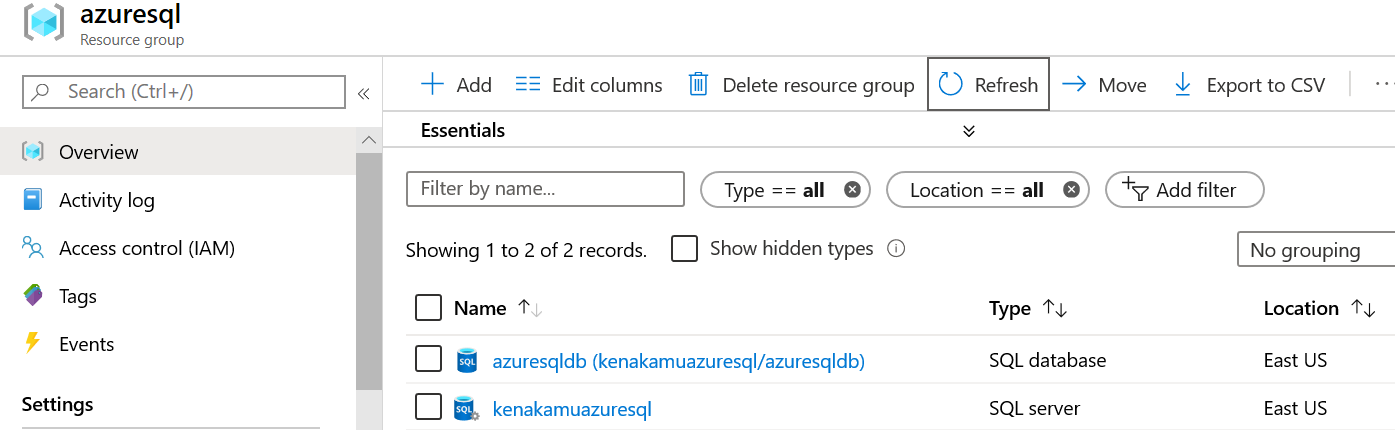
またサンプルデータベースを指定しているため、以下のようなテーブルが存在します。

外部テーブルの作成
では早速 Azure SQL に対して外部テーブルを作成してみます。
1. サンプルデータベースである sales に外部テーブルを作成するため、データベースを選択。
USE sales
2. 接続に使う認証情報を作成。
- ここでは azuresqluser としたが、資格情報名は任意
- ユーザー名とパスワードを指定
CREATE DATABASE SCOPED CREDENTIAL [azuresqluser] WITH IDENTITY = N'<user name>', SECRET = N'<password>';
3. データソースを作成。
- ここでは kenakamuazuresql としたが、データソース名は任意
- sqlserver:// 以降に実際の SQL Server 名を指定
- 先ほど作成した資格情報名を指定
CREATE EXTERNAL DATA SOURCE [kenakamuazuresql] WITH (LOCATION = N'sqlserver://kenakamuazuresql.database.windows.net', CREDENTIAL = [azuresqluser]);
4. 外部テーブルを作成。
- 先ほど作成したデータソース名を指定
CREATE EXTERNAL TABLE [dbo].[Product]
(
[ProductID] INT NOT NULL,
[Name] NVARCHAR(50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[ProductNumber] NVARCHAR(25) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[Color] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS,
[StandardCost] MONEY NOT NULL,
[ListPrice] MONEY NOT NULL,
[Size] NVARCHAR(5) COLLATE SQL_Latin1_General_CP1_CI_AS,
[Weight] DECIMAL(8, 2),
[ProductCategoryID] INT,
[ProductModelID] INT,
[SellStartDate] DATETIME2(3) NOT NULL,
[SellEndDate] DATETIME2(3),
[DiscontinuedDate] DATETIME2(3),
[ThumbNailPhoto] VARBINARY(MAX),
[ThumbnailPhotoFileName] NVARCHAR(50) COLLATE SQL_Latin1_General_CP1_CI_AS,
[rowguid] UNIQUEIDENTIFIER NOT NULL,
[ModifiedDate] DATETIME2(3) NOT NULL
)
WITH (LOCATION = N'[azuresqldb].[SalesLT].[Product]', DATA_SOURCE = [kenakamuazuresql]);
5. テーブルが作成されたことと、クエリの結果が返ることを確認。

GUI 経由での外部テーブルの作成
GUI を使うとより簡単に外部テーブルを作成できます。以下は Oracle の例ですが、SQL Server でも基本同じです。
リレーショナル データ ソースで外部テーブル ウィザードを使用する
尚、上記で紹介した外部テーブル作成クエリは、このウィザードで自動生成したクエリをベースにしています。
PolyBase のクエリ最適化
PolyBase 経由でクエリをした場合、どのようなクエリが Azure SQL 側で実行されるか確認します。ここでは Product テーブルより ProductId が 680 のレコードを取得します。考えられるシナリオは以下の 2 パターンです。
- Azure SQL 側にも正しい検索条件が渡され、1 件のレコードだけが返ってくる
- Azure SQL ではすべてのレコードを取得しており、BDC 側で 1 件のレコードがフィルターされる
当然前者のシナリオがパフォーマンスとして好ましいです。
SQL Profiler と Azure SQL のダイレクトクエリー
まずは Azure SQL を直接クエリーした場合です。
1. Azure Data Studio に SQL Profiler をインストール。

2. Azure Data Studio で Azure SQL に接続して New Query を表示。クエリを記述。(まだ実行しない)
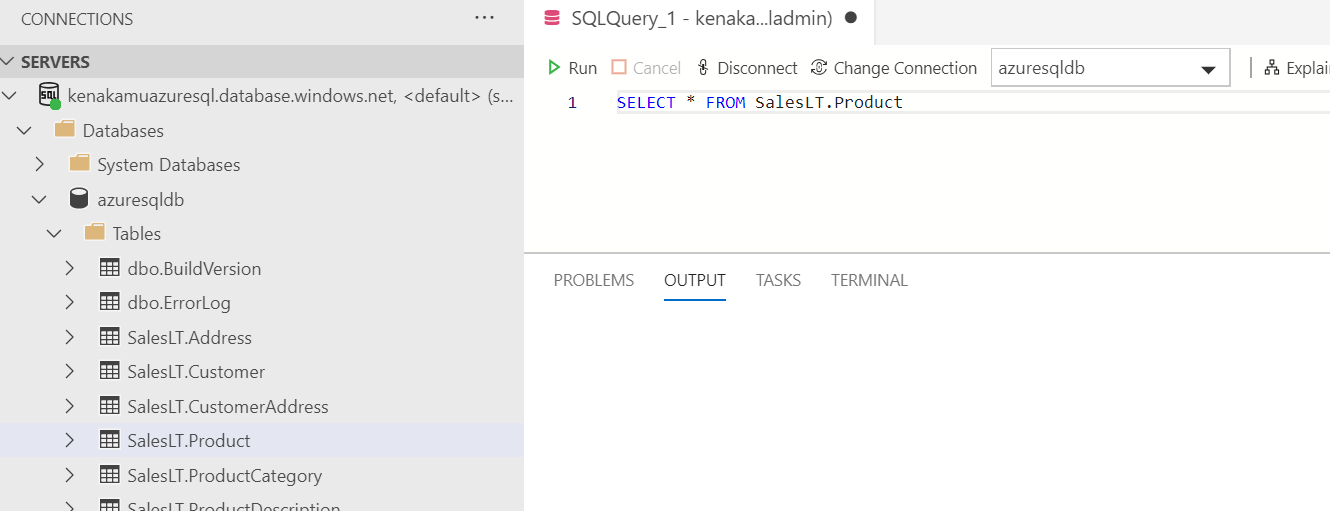
3. View | Command Palette より Profiler と入力し、Launch Profiler を選択。
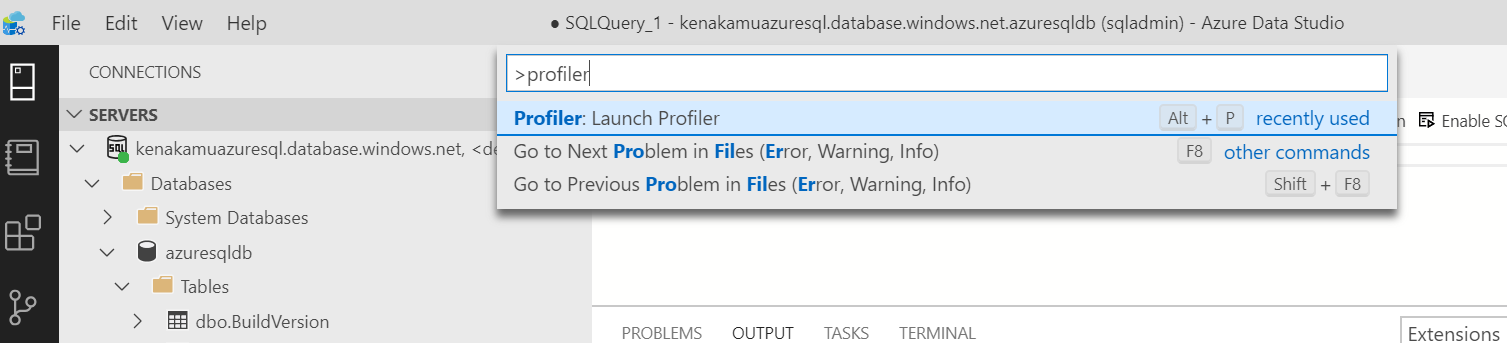
4. Standard_Azure テンプレートが選択されている状態で「Start」をクリック。

5. クエリウィンドウに戻り、クエリを実行。

6. プロファイラーウィンドウに戻りクエリを確認。

7. クエリウィンドウに戻り、インデックスを使うクエリを実行。

8. プロファイラーの結果からページリードが減ったことを確認。

外部テーブルからのクエリー
1. SQL Server 2019 BDC より外部クエリとして同じテーブルをクエリー。
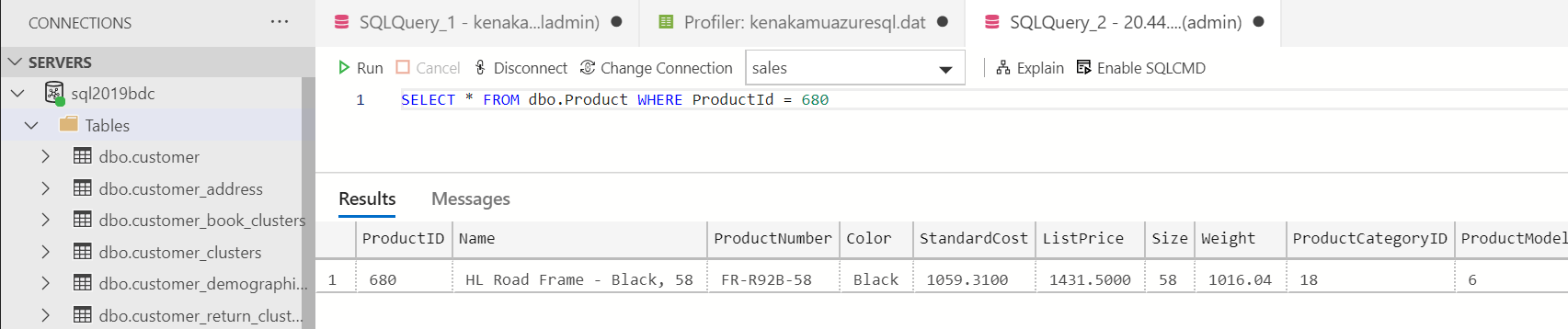
2. プロファイラーの結果より Azure SQL 側では ProductId が 680 のレコードだけが取得できていることを確認。

データプールの利用
外部テーブルを使った場合、毎回 Azure SQL にクエリが発行されます。これは最新のデータを取得するという観点では最適ですが、以下のシナリオではデータプールのクエリ結果をキャッシュした方が効率が良いです。
- データの更新頻度が低く、結果の精度をそこまで求められない
- データの更新頻度に関わらず、ある時点のスナップショットでよい
上記を満たす場合は、チュートリアル: Transact-SQL を使用して SQL Server のデータ プールにデータを取り込む を参照してデータプールにデータをキャッシュできます。
まとめ
外部テーブルの機能を使えば、HDFS でも Oracle でも Azure SQL でも全て同じようにクエリができます。今後より多くのデータソースがサポートされるようなので、楽しみです。