前回は azdata 既定の構成で SQL Server 2019 ビッグデータクラスター (BDC) を既存の AKS にインストールして、サンプルデータをインポートしてみました。今回は azdata を使ったカスタムインストールを行います。
SQL Server 2019 BDC のコンポーネント
SQL Server 2019 BDC のアーキテクチャと各コンポーネントの説明は以下ページを参照してください。参照: SQL Server ビッグ データ クラスターとは
[SQL Server 2019 BDC アーキテクチャ]

コントローラー
BDC を制御するコンポーネントであり、主に以下のような機能があります。
- クラスタのライフサイクルの管理
- マスターインスタンスをはじめ各コンポーネントの管理
- 監視ツールやトラブルシューティングツールの提供
- セキュリティの管理
参照: SQL Server ビッグ データ クラスターのコントローラーとは
SQL Server マスターインスタンス
外部から接続できる TDS エンドポイントを提供し、ユーザーが BDC をこれまでの SQL Server と同じように使える機能を提供する心臓部分です。
- Azure Data Studio やアプリケーションなど、外部から見た場合の接続先
- システムデータベースとユーザーデータベースの管理
- 外部テーブルの詳細や PolyBase 経由の外部データアクセス、メタデータの管理
- 各コンポーネントの情報
- Machine Learning Services の実行
参照: SQL Server ビッグ データ クラスターのマスター インスタンスとは
コンピューティング プール
SQL Server on Linux ポッドを実行するノードであり、マスターからの PolyBase 分散クエリの処理を実行する、スケールアウト可能なプールです。
参照: SQL Server ビッグ データ クラスターのコンピューティング プールとは
データ プール
クラスター上で SQL Server ストレージとして機能するポッドで、SQL クエリや Spark ジョブの結果を格納することで、以降のクエリを高速化します。またパフォーマンス向上のためデータはデータプールのインスタンス間でシャードされます。

参照: SQL Server ビッグ データ クラスターのデータ プールとは
記憶域プール
クラスター上で HDFS のデータストレージとして機能する他、Spark の実行環境にもなります。HDFS および SQL Server 両方のエンドポイントでデータアクセスができるため柔軟です。

参照: SQL Server ビッグ データ クラスターの記憶域プールとは
エンドポイント
SQL Server 2019 BDC は TDS エンドポイント以外にも、各種サービスを内部/外部に公開します。エンドポイントはサービスをセキュアに公開するために利用されます。
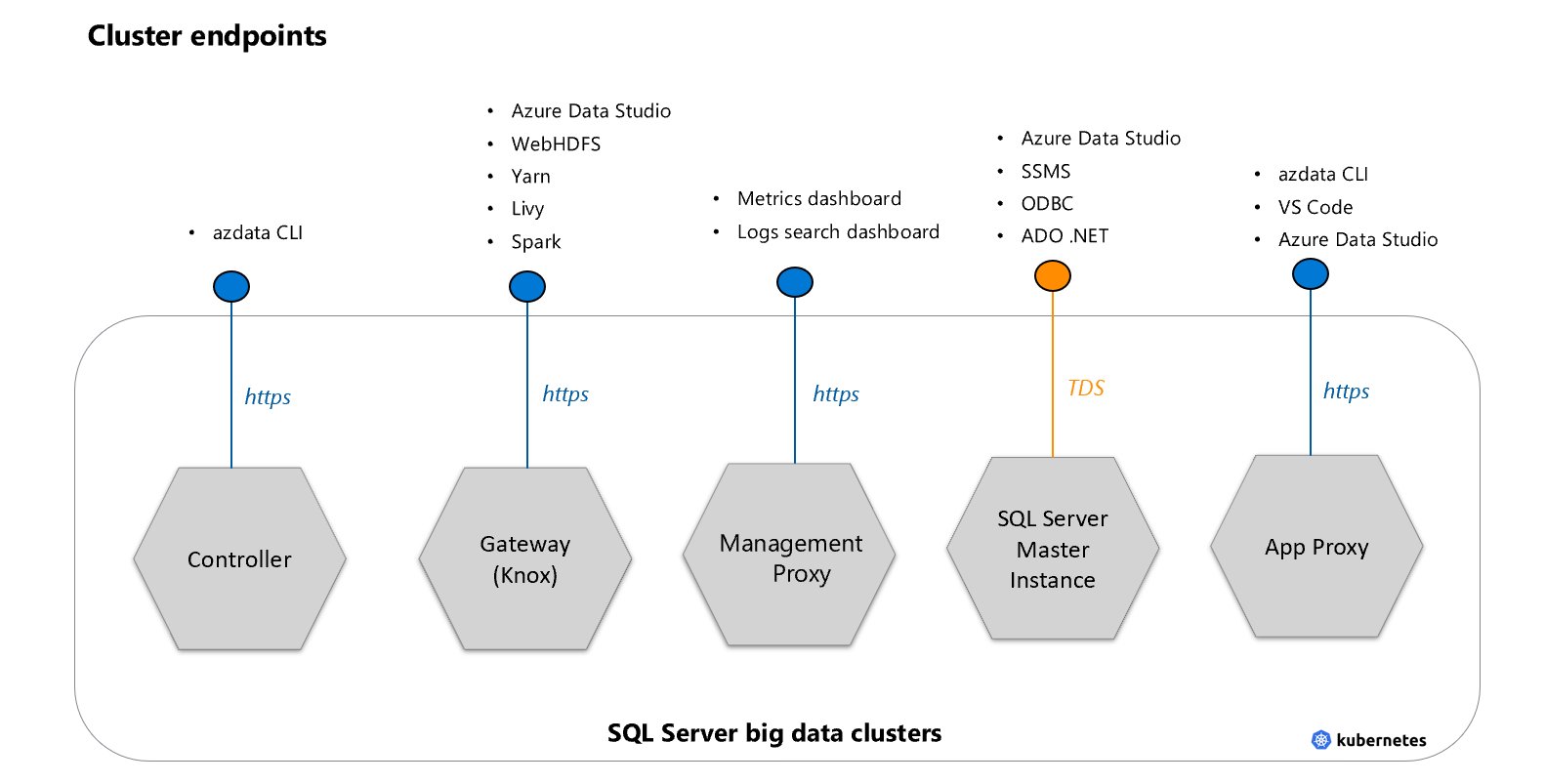
コントローラーエンドポイント
クラスターを管理するための REST API で azdata もこのエンドポイントを利用。
ゲートウェイ (Knox)
webHDFS や Spark などのサービスにアクセスするために使用されます。ADS から HDFS にアクセスする場合もこのエンドポイントに接続します。
管理プロキシ
ログ検索ダッシュボードとメトリック ダッシュボードにアクセスするために使用します。
マスター インスタンス
SSMS や Azure Data Studio、アプリケーションなどから接続する TDS エンドポイントです。
アプリケーション プロキシ
BDC 内に展開されたアプリケーションを管理するためのエンドポイントです。
azdata の構成ファイル
既存の構成ファイルを元にカスタムの構成ファイルを作成します。今回は aks-dev-test をコピーして始めます。
azdata bdc config init --source aks-dev-test --target custom
構成情報は以下 2 つの json に格納されます。
- control.json
- bdc.json
control.json
展開全体に関連する設定を保持します。
名前空間
k8s 用の名前空間を指定できます。既定で mssql-cluster です。
※小文字の英数字のみを使用し、スペースを含めない
{
"apiVersion": "v1",
"metadata": {
"kind": "Cluster",
"name": "mssql-cluster"
},
展開するコンポーネントのバージョンとレジストリ
展開するコンテナの情報指定します。プライベートレポジトリも利用が可能です。
参考: SQL Server ビッグ データ クラスターのオフライン展開を実行する
{
...
"spec": {
"docker": {
"registry": "mcr.microsoft.com",
"repository": "mssql/bdc",
"imageTag": "2019-GDR1-ubuntu-16.04",
"imagePullPolicy": "Always"
},
...
既定のストレージ設定
control.json で設定した storage 要素は bdc.json の各要素に適用される既定設定となっています。
- className: k8s で識別されるストレージの ClassName
- accessMode: 1 ポッドからのみアクセスできるよう ReadWriteOnce
{
...
"spec": {
...
"storage": {
"data": {
"className": "default",
"accessMode": "ReadWriteOnce",
"size": "15Gi"
},
"logs": {
"className": "default",
"accessMode": "ReadWriteOnce",
"size": "10Gi"
}
},
AKS では既定で default と managed-premium が提供されていて、これらを利用する場合は動的に作成されるため、ディスクを事前に用意する必要がない一方、VM で作成されたディスクをアタッチできる必要があります。VM はサイズによってアタッチできるディスクの数に上限があるため、要確認です。また永続ストレージを利用しないとポッド再起動時にデータをロストします。
AKS のストレージについては SQL Server 2017 を AKS で使う - ストレージの準備 にも記事があります。
[AKS ストレージクラスの情報]
>kubectl describe sc default
Name: default
IsDefaultClass: Yes
Annotations: kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"storage.k8s.io/v1beta1","kind":"StorageClass","metadata":{"annotations":{"storageclass.beta.kubernetes.io/is-default-class":"true"},"labels":{"kubernetes.io/cluster-service":"true"},"name":"default"},"parameters":{"cachingmode":"ReadOnly","kind":"Managed","storageaccounttype":"Standard_LRS"},"provisioner":"kubernetes.io/azure-disk"}
,storageclass.beta.kubernetes.io/is-default-class=true
Provisioner: kubernetes.io/azure-disk
Parameters: cachingmode=ReadOnly,kind=Managed,storageaccounttype=Standard_LRS
AllowVolumeExpansion: <unset>
MountOptions: <none>
ReclaimPolicy: Delete
VolumeBindingMode: Immediate
Events: <none>
>kubectl describe sc managed-premium
Name: managed-premium
IsDefaultClass: No
Annotations: kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"storage.k8s.io/v1beta1","kind":"StorageClass","metadata":{"annotations":{},"labels":{"kubernetes.io/cluster-service":"true"},"name":"managed-premium"},"parameters":{"cachingmode":"ReadOnly","kind":"Managed","storageaccounttype":"Premium_LRS"},"provisioner":"kubernetes.io/azure-disk"}
Provisioner: kubernetes.io/azure-disk
Parameters: cachingmode=ReadOnly,kind=Managed,storageaccounttype=Premium_LRS
AllowVolumeExpansion: <unset>
MountOptions: <none>
ReclaimPolicy: Delete
VolumeBindingMode: Immediate
Events: <none>
参照: Kubernetes 上の SQL Server ビッグ データ クラスターでのデータ永続化
エンドポイント
5 つあるエンドポイントのうちコントローラーと管理プロキシは control.json で指定します。
{
...
"spec": {
...
"endpoints": [
{
"name": "Controller",
"serviceType": "LoadBalancer",
"port": 30080
},
{
"name": "ServiceProxy",
"serviceType": "LoadBalancer",
"port": 30777
}
]
}
}
bdc.json
BDC の各コンポーネントの詳細は bdc.json で指定します。
クラスタ名の変更
BDC のクラスタ名を指定できます。既定では mssql-cluster です。
{
"apiVersion": "v1",
"metadata": {
"kind": "BigDataCluster",
"name": "mssql-cluster"
},
...
リソースの各要素
spec.resources には各コンポーネントに関する設定があります。その中でスケールの設定や既定の記憶域設定の上書きを行います。
スケールの設定
k8s のポッド数を replicas に設定します。以下コンピューティングプールのスケールを 2 に設定した例です。
{
...
"spec": {
"resources": {
...
"compute-0": {
"metadata": {
"kind": "Pool",
"name": "default"
},
"spec": {
"type": "Compute",
"replicas": 2
}
},
...
記憶域の上書き
control.json で設定されている記憶域と異なるものを利用する場合、spec に storage セクションを追加します。以下の例はデータプールと記憶域プールに対して、managed-premium クラスと別の容量を設定しています。
{
...
"spec": {
"resources": {
...
"data-0": {
"metadata": {
"kind": "Pool",
"name": "default"
},
"spec": {
"type": "Data",
"replicas": 2,
"storage": {
"data": {
"size": "100Gi",
"className": "managed-premium",
"accessMode": "ReadWriteOnce"
},
"logs": {
"size": "32Gi",
"className": "managed-premium",
"accessMode": "ReadWriteOnce"
}
}
}
},
"storage-0": {
"metadata": {
"kind": "Pool",
"name": "default"
},
"spec": {
"type": "Storage",
"replicas": 2,
"storage": {
"data": {
"size": "500Gi",
"className": "managed-premium",
"accessMode": "ReadWriteOnce"
},
"logs": {
"size": "32Gi",
"className": "managed-premium",
"accessMode": "ReadWriteOnce"
}
}
}
}
...
エンドポイント
SQL マスターインスタンスやゲートウェイなど、エンドポイントを持つものは spec に endpoints 設定を保持します。ポート変えたい場合はここを変更します。
{
...
"spec": {
"resources": {
...
"gateway": {
"spec": {
"replicas": 1,
"endpoints": [
{
"name": "Knox",
"serviceType": "LoadBalancer",
"port": 30443
}
]
}
},
...
サービス設定
spec.services には、各サービスで使うリソースが記述されています。サービスに関連づいているリソース全てに同じ設定をする場合、個別に設定せず spec.services.settings で一括構成ができます。
高可用性設定
上記の設定の他高可用性設定も bdc.json で設定しますが、こちらは別の記事で紹介します。
azdata でカスタム構成を利用した展開
今回は以下の設定を使って構成を行います。
- 名前空間とクラスタ名を bdc-cluster に変更
- データプールと記憶域プールに対して個別の記憶域設定を指定
- コンピューティングプールのレプリカを 2 に変更
{
"apiVersion": "v1",
"metadata": {
"kind": "Cluster",
"name": "bdc-cluster"
},
"spec": {
"docker": {
"registry": "mcr.microsoft.com",
"repository": "mssql/bdc",
"imageTag": "2019-GDR1-ubuntu-16.04",
"imagePullPolicy": "Always"
},
"storage": {
"data": {
"className": "default",
"accessMode": "ReadWriteOnce",
"size": "15Gi"
},
"logs": {
"className": "default",
"accessMode": "ReadWriteOnce",
"size": "10Gi"
}
},
"endpoints": [
{
"name": "Controller",
"serviceType": "LoadBalancer",
"port": 30080
},
{
"name": "ServiceProxy",
"serviceType": "LoadBalancer",
"port": 30777
}
]
}
}
{
"apiVersion": "v1",
"metadata": {
"kind": "BigDataCluster",
"name": "bdc-cluster"
},
"spec": {
"resources": {
"nmnode-0": {
"spec": {
"replicas": 1
}
},
"sparkhead": {
"spec": {
"replicas": 1
}
},
"zookeeper": {
"spec": {
"replicas": 0
}
},
"gateway": {
"spec": {
"replicas": 1,
"endpoints": [
{
"name": "Knox",
"serviceType": "LoadBalancer",
"port": 30443
}
]
}
},
"appproxy": {
"spec": {
"replicas": 1,
"endpoints": [
{
"name": "AppServiceProxy",
"serviceType": "LoadBalancer",
"port": 30778
}
]
}
},
"master": {
"metadata": {
"kind": "Pool",
"name": "default"
},
"spec": {
"type": "Master",
"replicas": 1,
"endpoints": [
{
"name": "Master",
"serviceType": "LoadBalancer",
"port": 31433
}
],
"settings": {
"sql": {
"hadr.enabled": "false"
}
}
}
},
"compute-0": {
"metadata": {
"kind": "Pool",
"name": "default"
},
"spec": {
"type": "Compute",
"replicas": 2
}
},
"data-0": {
"metadata": {
"kind": "Pool",
"name": "default"
},
"spec": {
"type": "Data",
"replicas": 2,
"storage": {
"data": {
"size": "100Gi",
"className": "managed-premium",
"accessMode": "ReadWriteOnce"
},
"logs": {
"size": "32Gi",
"className": "managed-premium",
"accessMode": "ReadWriteOnce"
}
}
}
},
"storage-0": {
"metadata": {
"kind": "Pool",
"name": "default"
},
"spec": {
"type": "Storage",
"replicas": 2,
"settings": {
"spark": {
"includeSpark": "true"
}
},
"storage": {
"data": {
"size": "150Gi",
"className": "managed-premium",
"accessMode": "ReadWriteOnce"
},
"logs": {
"size": "50Gi",
"className": "managed-premium",
"accessMode": "ReadWriteOnce"
}
}
}
}
},
"services": {
"sql": {
"resources": [
"master",
"compute-0",
"data-0",
"storage-0"
]
},
"hdfs": {
"resources": [
"nmnode-0",
"zookeeper",
"storage-0",
"sparkhead"
],
"settings": {}
},
"spark": {
"resources": [
"sparkhead",
"storage-0"
],
"settings": {
"spark-defaults-conf.spark.driver.memory": "2g",
"spark-defaults-conf.spark.driver.cores": "1",
"spark-defaults-conf.spark.executor.instances": "3",
"spark-defaults-conf.spark.executor.memory": "1536m",
"spark-defaults-conf.spark.executor.cores": "1",
"yarn-site.yarn.nodemanager.resource.memory-mb": "18432",
"yarn-site.yarn.nodemanager.resource.cpu-vcores": "6",
"yarn-site.yarn.scheduler.maximum-allocation-mb": "18432",
"yarn-site.yarn.scheduler.maximum-allocation-vcores": "6",
"yarn-site.yarn.scheduler.capacity.maximum-am-resource-percent": "0.3"
}
}
}
}
}
1. azdata コマンドで展開を実行。
SET AZDATA_USERNAME=admin
SET AZDATA_PASSWORD=<password>
azdata bdc create --config-profile custom --accept-eula yes
2. 展開が終わるまで待機。15-30分程度かかるのでコーヒーでも飲みながら Introducing SQL Server 2019 | Data Exposed を見る。

展開されたサービスの確認
展開が完了したら早速各種コンポーネントの状況を確認しましょう。
AKS から確認
名前空間の確認
- bdc-cluster 名前空間があることを確認
>kubectl get namespaces
NAME STATUS AGE
bdc-cluster Active 78m
default Active 47h
kube-public Active 47h
kube-system Active 47h
ポッドの確認
- コンピューティングポッドが 2 つあることを確認
>kubectl get pods --namespace=bdc-cluster
NAME READY STATUS RESTARTS AGE
appproxy-tjvjr 2/2 Running 0 63m
compute-0-0 3/3 Running 0 63m
compute-0-1 3/3 Running 0 63m
control-b6chc 3/3 Running 0 78m
controldb-0 2/2 Running 0 78m
controlwd-jfbbm 1/1 Running 0 76m
data-0-0 3/3 Running 0 63m
data-0-1 3/3 Running 0 63m
gateway-0 2/2 Running 0 63m
logsdb-0 1/1 Running 0 76m
logsui-m2hd6 1/1 Running 0 76m
master-0 3/3 Running 0 63m
metricsdb-0 1/1 Running 0 76m
metricsdc-9sbzf 1/1 Running 0 76m
metricsui-6h4cs 1/1 Running 0 76m
mgmtproxy-856h8 2/2 Running 0 76m
nmnode-0-0 2/2 Running 0 63m
sparkhead-0 4/4 Running 0 63m
storage-0-0 4/4 Running 0 63m
storage-0-1 4/4 Running 0 63m
PersistentVolume の確認
- 異なるサイズの PV があることを確認
>kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
...
pvc-c18558b8-1bd7-11ea-9062-26efe99880fd 10Gi RWO Delete Bound bdc-cluster/logs-nmnode-0-0 default 64m
pvc-c1872731-1bd7-11ea-9062-26efe99880fd 15Gi RWO Delete Bound bdc-cluster/data-nmnode-0-0 default 64m
...
pvc-c41622db-1bd7-11ea-9062-26efe99880fd 100Gi RWO Delete Bound bdc-cluster/data-data-0-1 managed-premium 64m
pvc-c418e23d-1bd7-11ea-9062-26efe99880fd 32Gi RWO Delete Bound bdc-cluster/logs-data-0-1 managed-premium 64m
...
pvc-d2bb3c06-1bd7-11ea-9062-26efe99880fd 150Gi RWO Delete Bound bdc-cluster/data-storage-0-0 managed-premium 64m
pvc-d2bda280-1bd7-11ea-9062-26efe99880fd 50Gi RWO Delete Bound bdc-cluster/logs-storage-0-0 managed-premium 64m
...
ADS で接続
SQL Server 2019 BDC 用の DMV がある為、そちらで情報を確認します。
以下にいくつか例を出しますが、他にもたくさんある為、いろいろ試してください。
SELECT * FROM sys.dm_exec_compute_pools
SELECT * FROM sys.dm_exec_compute_nodes
SELECT * FROM sys.dm_exec_compute_node_status
SELECT * FROM sys.dm_cluster_endpoints
SELECT * FROM sys.dm_db_data_pools
SELECT * FROM sys.dm_db_storage_pools
クラスタの削除
次回に備えてまたクラスタは削除しておきます。
azdata bdc delete -n bdc-cluster
また使わない場合は AKS の仮想マシンスケールセットを停止しておいてください。
まとめ
今回は azdata で利用できる構成ファイルについて詳細を見ていきました。次回は高可用性の展開を見ていきます。