1. はじめに
はじめまして。ジールの@ken_miyashitaです。
2024年12月に表形式のデータを大規模に保存する「Amazon S3 Tables」が発表されました。従来のS3ストレージでは対応が難しかった、データ分析や大規模データセットの効率的な格納が可能になり、さまざまなユースケースでの利便性を向上させることが期待されています。
本記事では、「Amazon S3 Tables」の機能について検証し、Amazon QuickSightを使ったデータ可視化や分析の際の挙動についても触れていきます。本記事で使用するAWSサービスは以下の通りです。
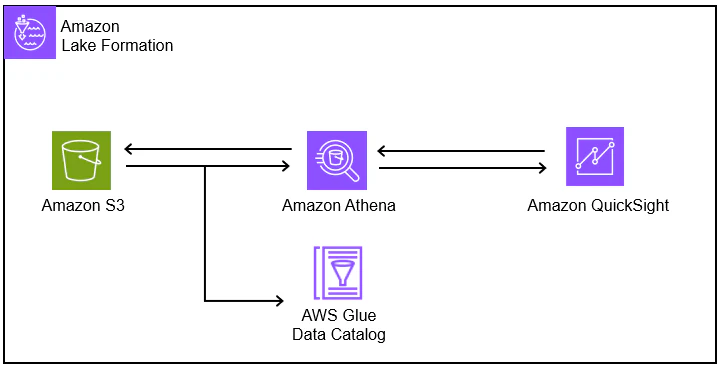
2. Amazon S3 Tablesとは
Amazon S3 Tablesは、Apache Icebergサポートが初めて組み込まれたクラウドオブジェクトストアです。
これはS3上に直接テーブルを作成し、SQLでデータを操作できるサービスです。従来のS3のファイルストレージと異なり、S3 TablesはApache Icebergサポートが組み込まれており、以下のような特徴を持ちます。
2-1. S3 Tablesの特徴
S3 Tablesの特徴は以下の通りです。
- S3上に直接テーブルを作成し、データ管理を一元化
- ACIDトランザクション対応により、信頼性の高いデータ処理が可能
- INSERT, UPDATE, DELETE, MERGEがSQLで実行可能(従来のAthenaは基本的に読み取り専用)
- AthenaやRedshift Spectrumと統合可能で、既存の分析基盤とも連携可能
- Apache Icebergフォーマットを活用し、高速なクエリとスナップショット管理が可能
- 単なるストレージではなくDWHに近い機能を持つデータレイク管理ツールとして活用可能
2-2. S3とS3 Tablesの相違点
S3とS3 Tablesの違いを表にまとめてみます。
| 観点 | S3 | S3 Tables |
|---|---|---|
| 格納方法 | ファイル(CSV/Parquetなど)をアップロード | テーブルを直接バケットに作成 |
| スキーマ | Glue Data Catalogで管理 | テーブル自体にスキーマを保持 |
| データ更新 | ファイルを手動で上書き | SQLでINSERT/UPDATEなどが可能 |
| トランザクション | 非対応 | IcebergでACIDトランザクション対応 |
| クエリ | AthenaやSpectrum経由 | 直接SQLで操作 |
| 最適化 | パーティション設計や形式で調整が必要 | Icebergによる自動最適化 |
| コスト | スキャン/クエリごとにコスト発生 | S3 Tablesのクエリ実行コスト |
上記特徴から、S3 Tablesは単なるストレージではなく、データレイクの管理・活用を大幅に強化するサービスのようですね。SQLでの操作やACIDトランザクションなど、まるでDWHに近い機能が備わっているように見えます。
3. 環境構築
環境構築をする際に、分かりやすい記事がありましたのでご参照ください。
では、実際にS3 Tablesにテーブルを作成してみます。
3-1. テーブルバケットを作成
S3のコンソールタブに「テーブルバケット」が追加されていることを確認
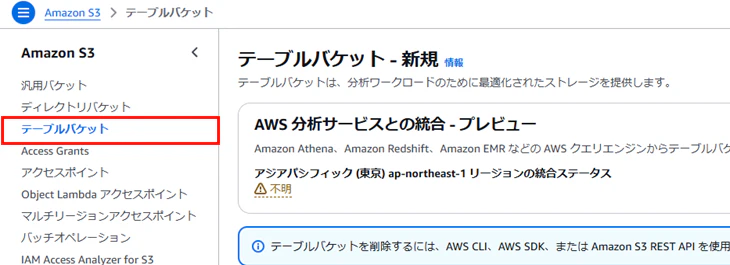
「テーブルバケットを作成」を押下
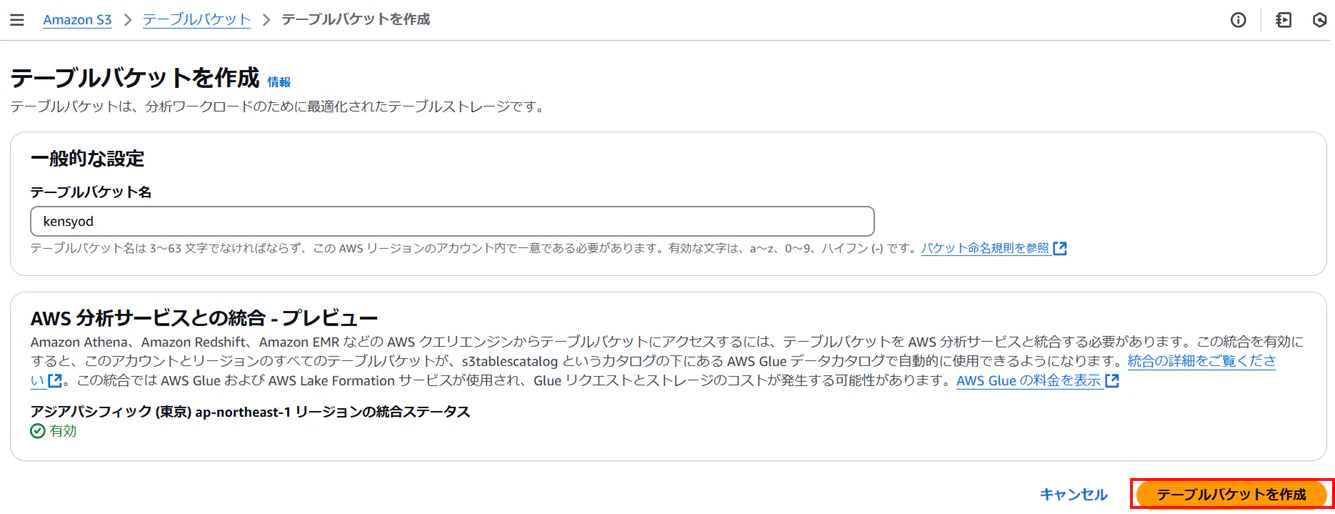
3-2. テーブルを作成
作成したテーブルバケット内にテーブルを作成します。
またテーブル作成方法は下記を参考にCLIで行います。
まずはスキーマ管理ができるようにするため、名前空間(namespace)を作成する
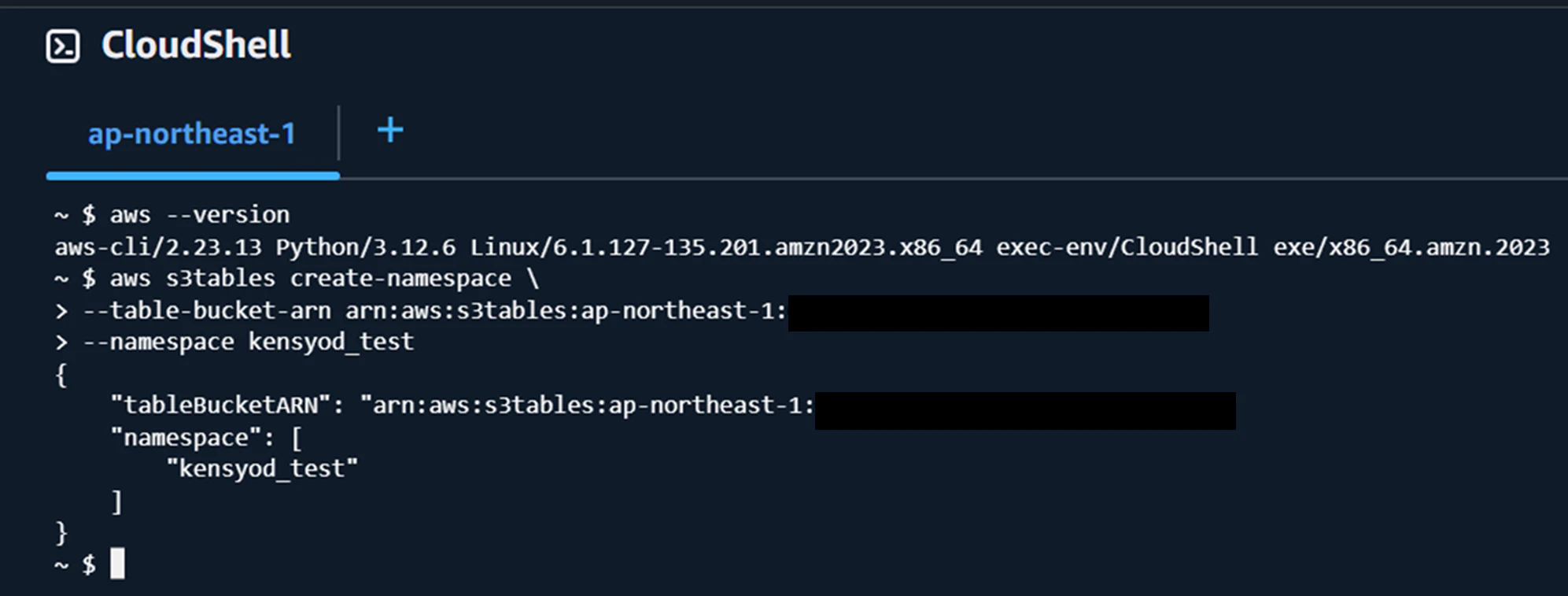
テーブル作成を行う(CLIコマンドでは成功の文章は出てこないので注意)

AWSコンソール上でもテーブルが作成されていることを確認する
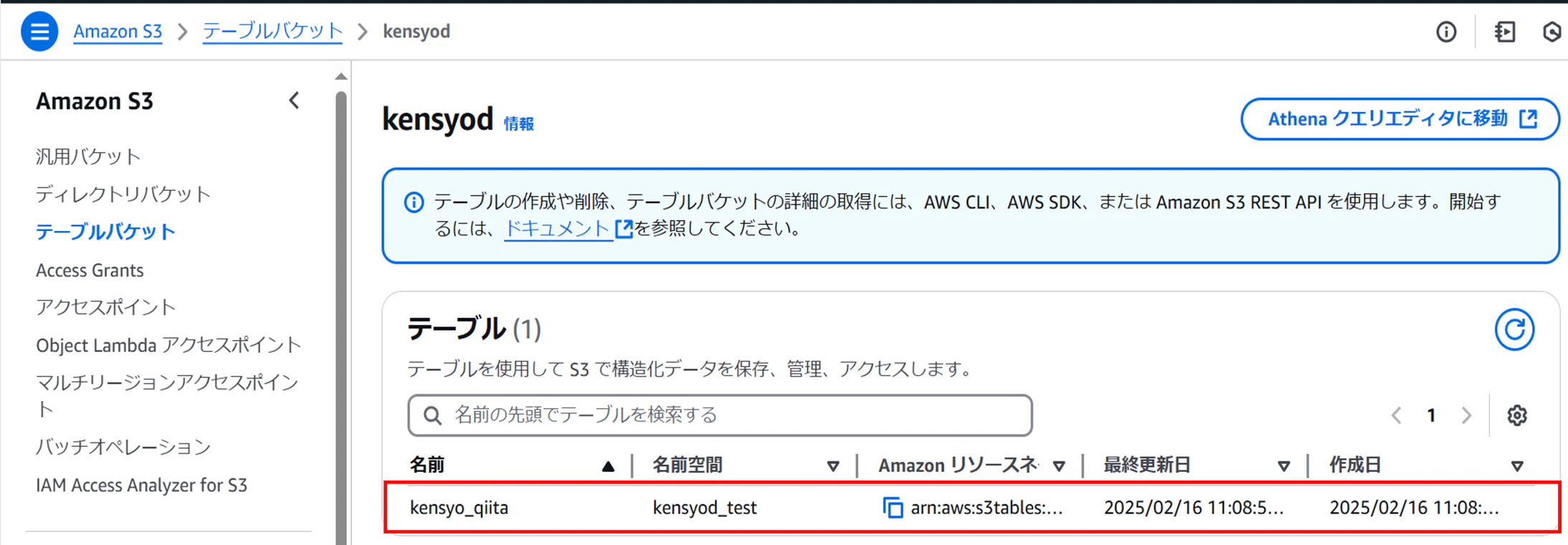
3-3. AWS分析サービスとの統合を有効化する
AWS分析サービスとの統合を有効化することで、分析を行う際に必要なカタログを参照できるようになり、クエリサービスが使用できるようになります。統合を有効化した際に下記リソースが同時に作成されます。
- Amazon Lake Formationのカタログ(s3tablescatalog)
- IAM ロール(S3TablesRoleForLakeFormation)
「統合を有効にする」が押下できない場合、下記のように表示される
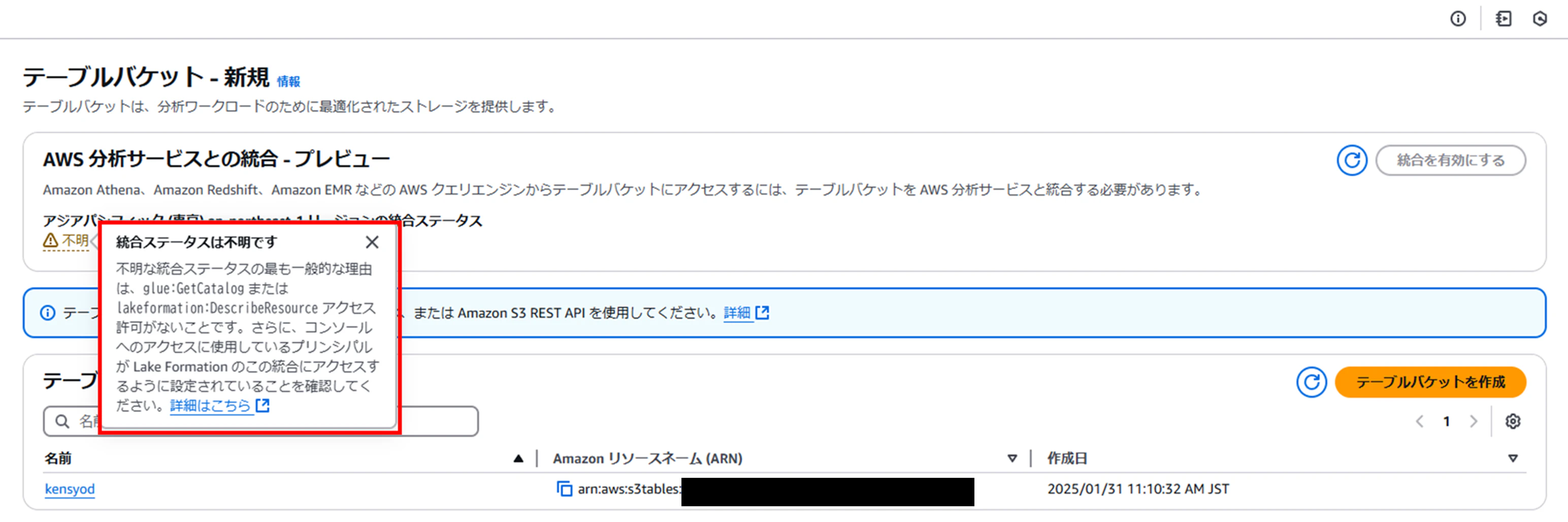
Lake Formationの管理者権限があれば押下可能になるため、管理者権限を付与する

再度テーブルバケットを見てみると、押下可能な状態となっている
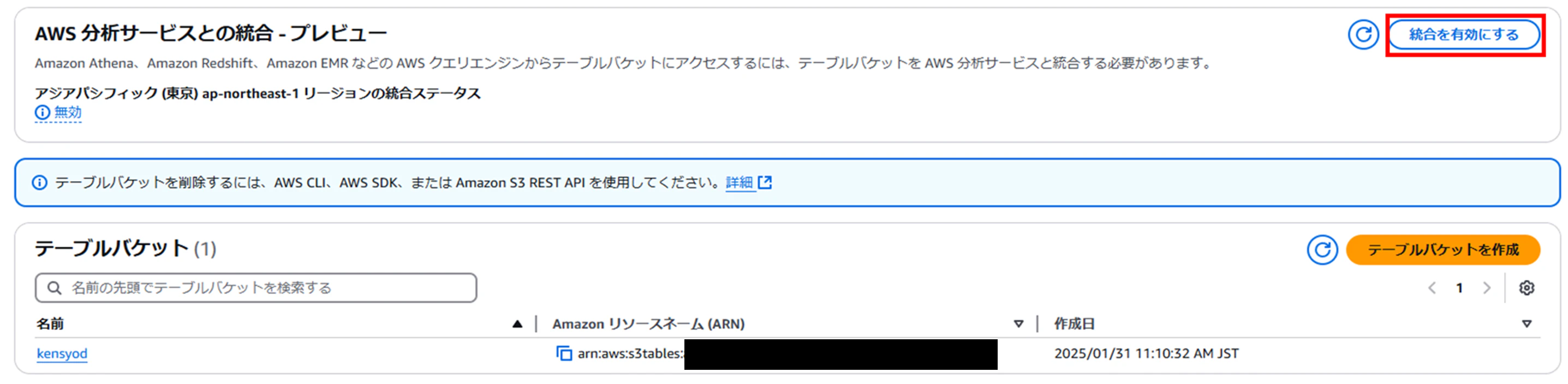
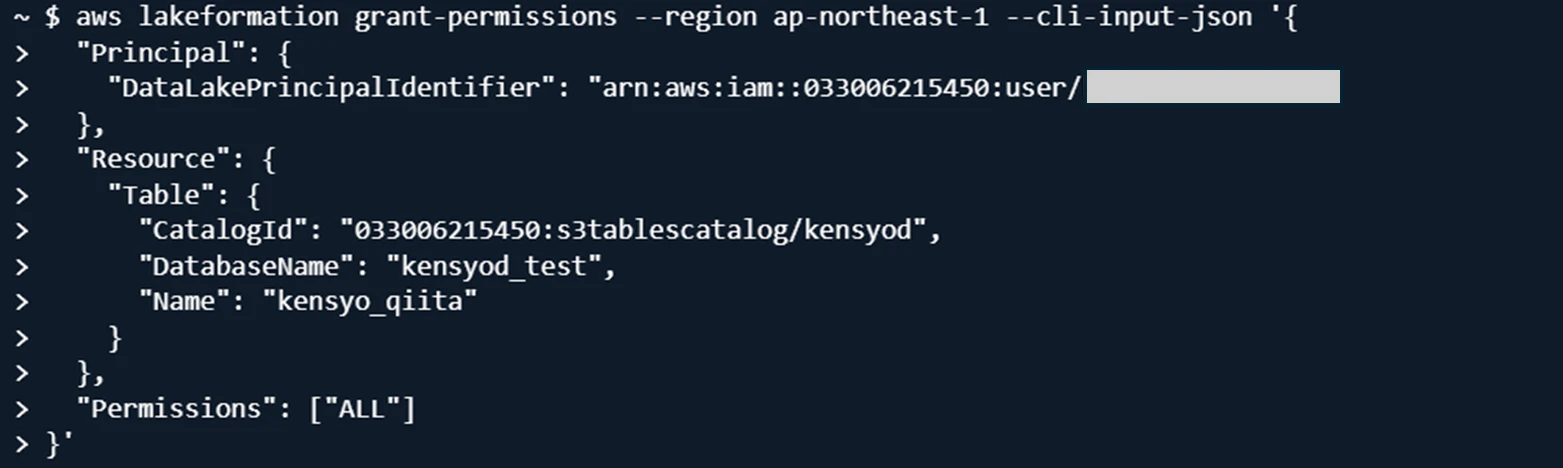
3-4. サービス間のアクセス許可設定
CLIを用いてLake FormationからS3 Tablesに対してアクセス許可を付与します。
3-5. Athenaでテーブルへデータを挿入する
Athenaにて先程作成したテーブルにINSERT文を実行します。
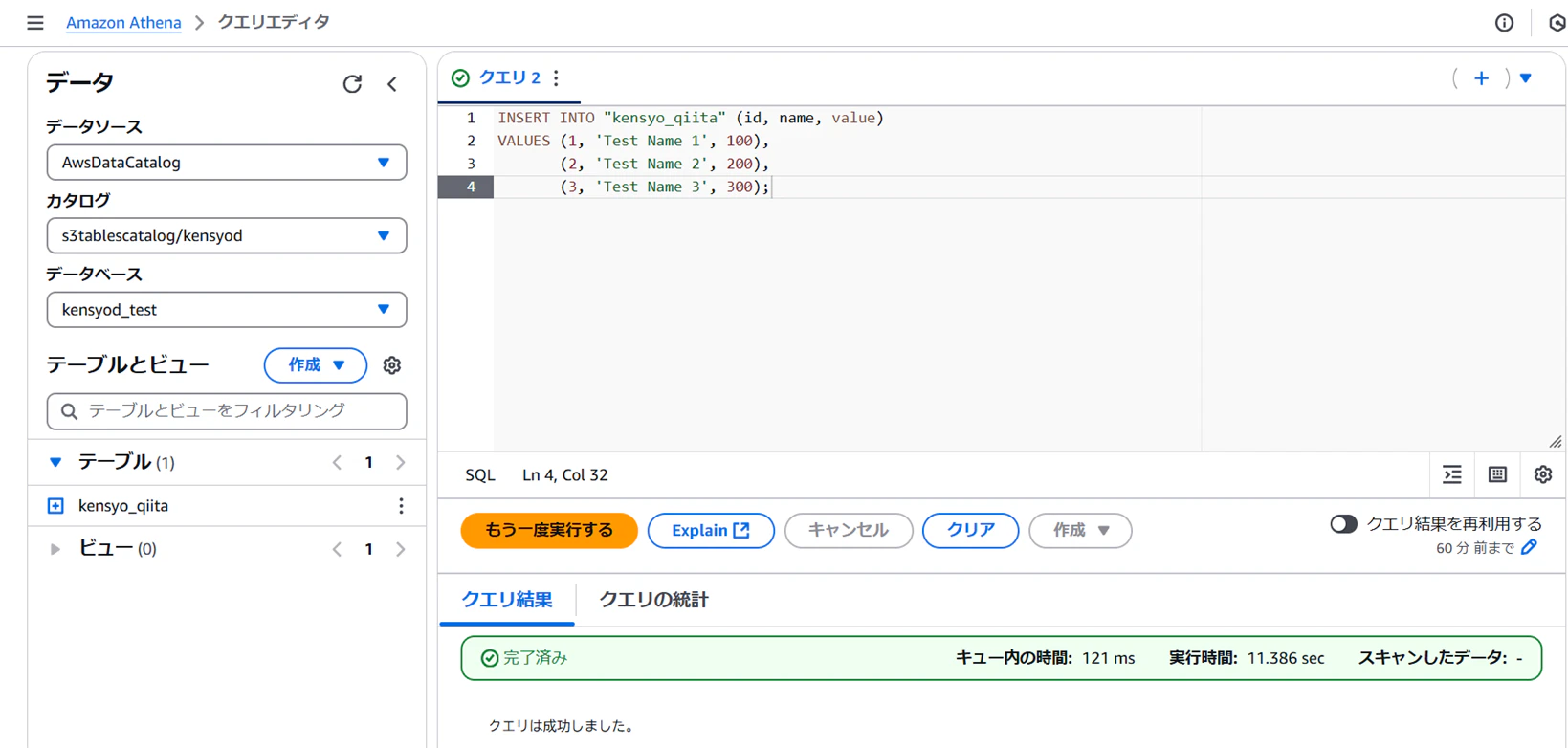
以上で環境構築は完了となります。
4. QuickSightのデータ可視化
S3 Tablesに作成したテーブルがQuickSightに反映・可視化ができるかを検証してみます。
4-1. IAMポリシー設定
まずはS3 Tablesへのアクセス許可を付与するため、QuickSightのIAMロールポリシー設定をします。
IAMコンソールからロールを開く
対象のロールを選択後、以下画面へ遷移する
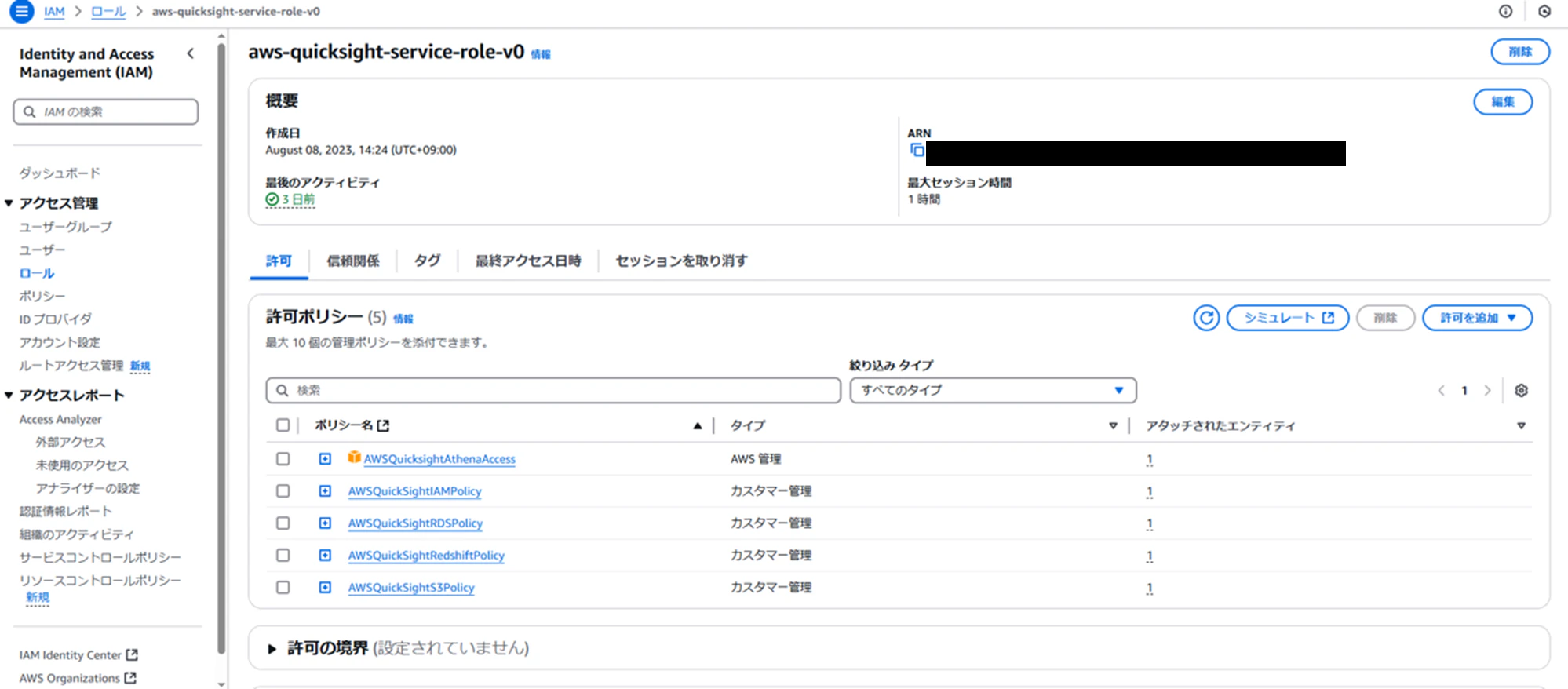
「許可を追加」→「インラインポリシーを作成」を押下

ポリシーエディタをJSONにする
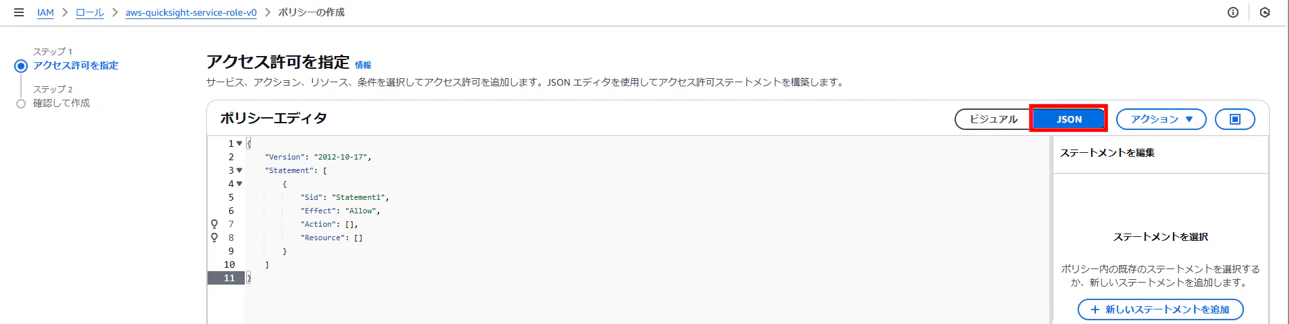
JSONをポリシーエディタに貼り付ける
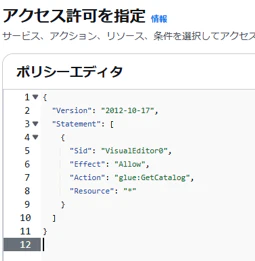
4-2. ARN (Amazon Resource Name) の確認
次に設定されているQuickSightユーザーのARNを確認していきます。
※ARNとは、AWSのリソースを一意に識別するための名前(識別子)
まずは下記コマンドをCloudShellで実行する
aws quicksight list-users --aws-account-id <アカウントID> --namespace default --region ap-northeast-1
実行したところ以下の結果となった
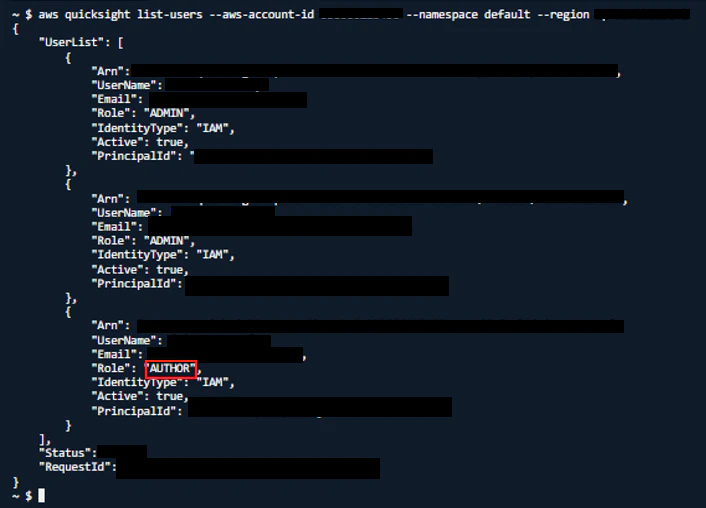
上記赤枠の「AUTHOR」ユーザーが私のQuickSightユーザーであったため、こちらのユーザーのArnで設定を行います。QuickSightでデータセットを作るために、ユーザーの「"Arn":」以降が必要となるためメモしておきます。
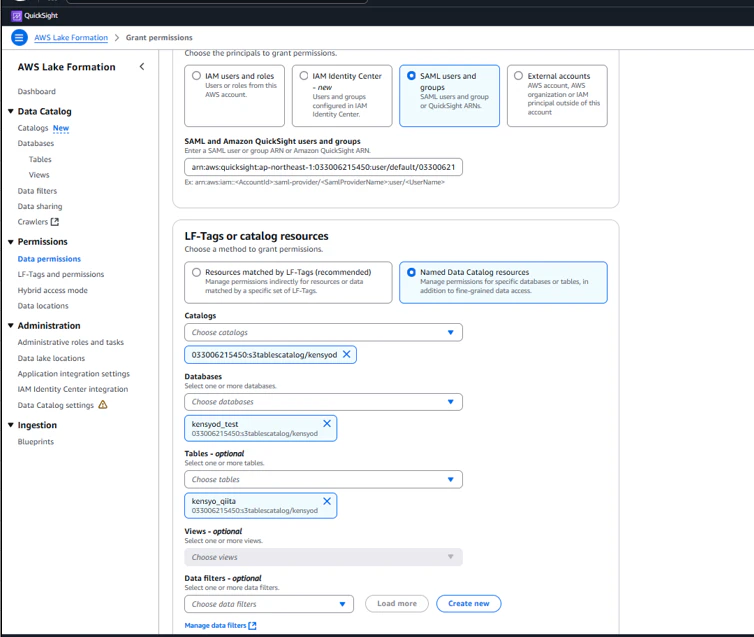
4-3. S3 Tablesのテーブルへの権限を付与
Lake Formationコンソールから、S3テーブルバケット内のテーブルへの権限を付与します。
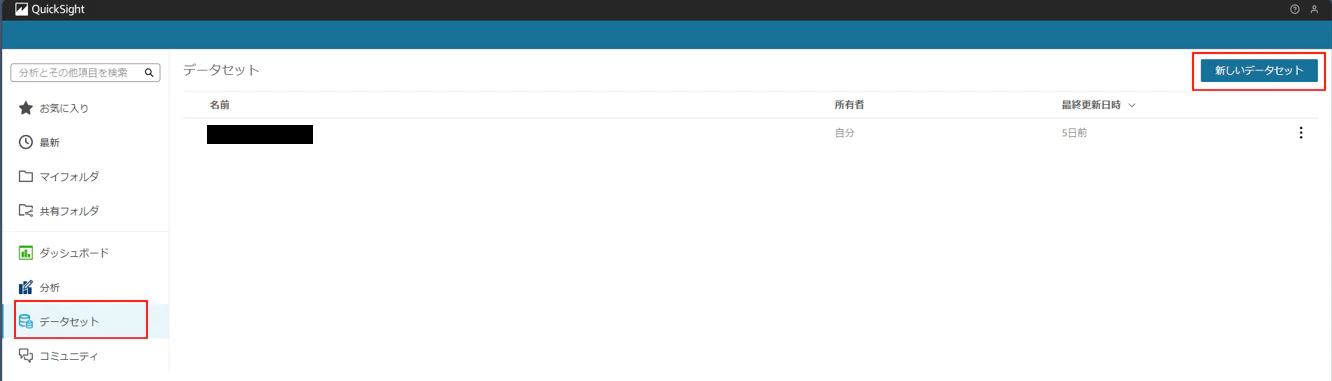
4-4. QuickSightにデータセットを作成する
QuickSightアカウントにサインイン後、画面左のデータセットから「新しいデータセット」を押下します。
「Athena」を選択
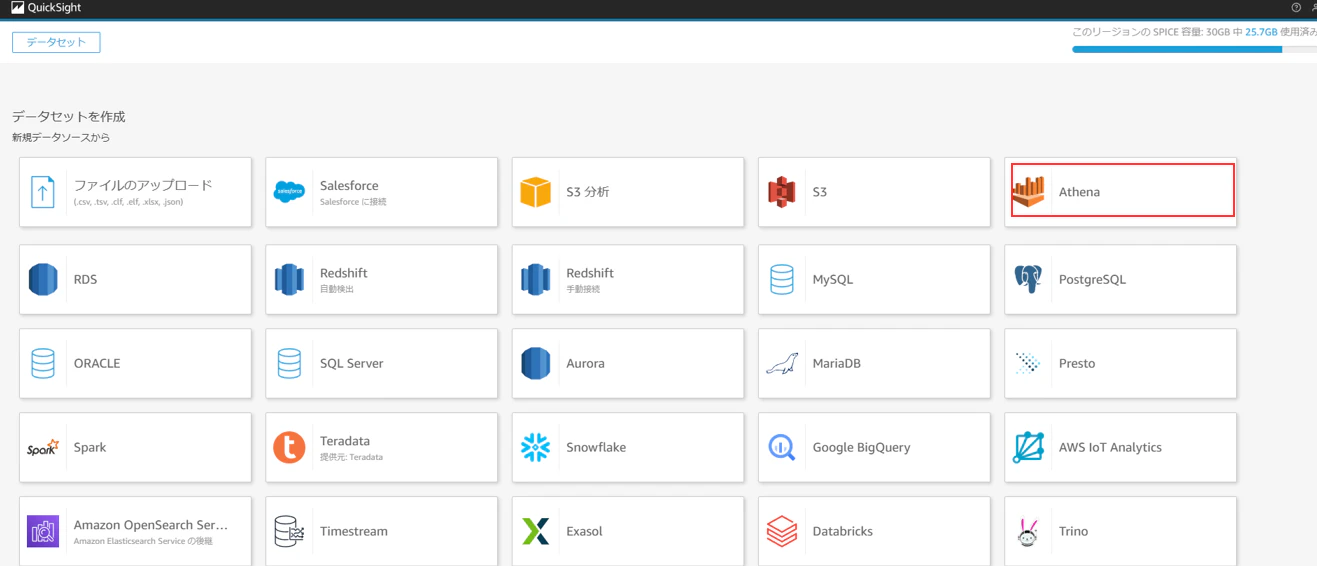
任意のデータソース名を入れて、「データソースを作成」を押下
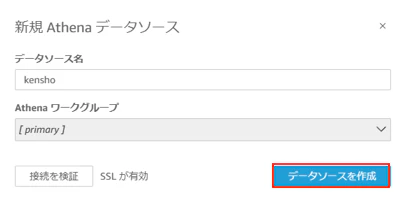
「カスタムSQLを使用」を押下
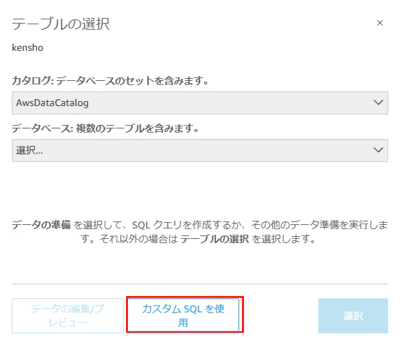
以下のカスタムSQLを設定する。
SELECT * FROM "s3tablescatalog/<S3テーブルバケット名>".<S3テーブルバケットの名前空間>.<S3テーブルバケットのテーブル>
これでデータセットが作成できました。
次に「データクエリを直接実行」に設定し、「Visualize」を押下します。
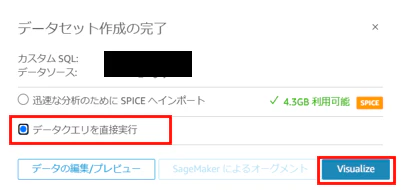
分析画面へ遷移
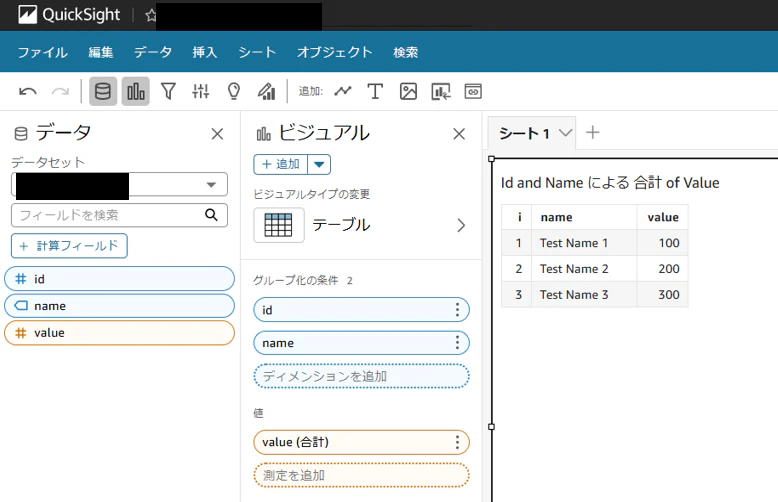
テーブルを作成し、S3 Tablesのデータが可視化できていることを確認
5. その他検証
5-1. テーブルレベルの権限
S3 TablesではGUIでテーブルレベルの権限を付与することができます。
実際に権限を付与・削除した状態でAthenaから挙動を確認してみます。
Lake Formationコンソールから「Data Catalog」→「Catalogs」→「s3tablescatalog」を押下
カタログ名を選択
「Actions」→「Grant」を押下
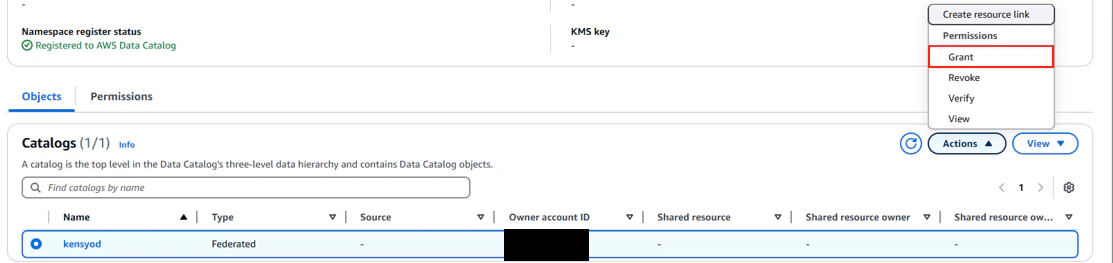
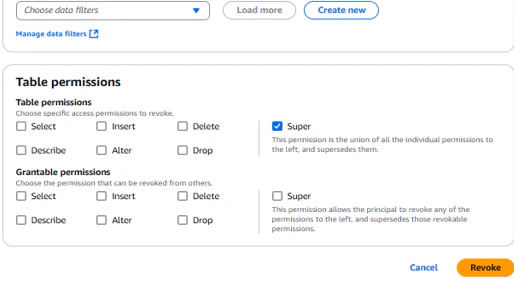
権限付与設定を実施
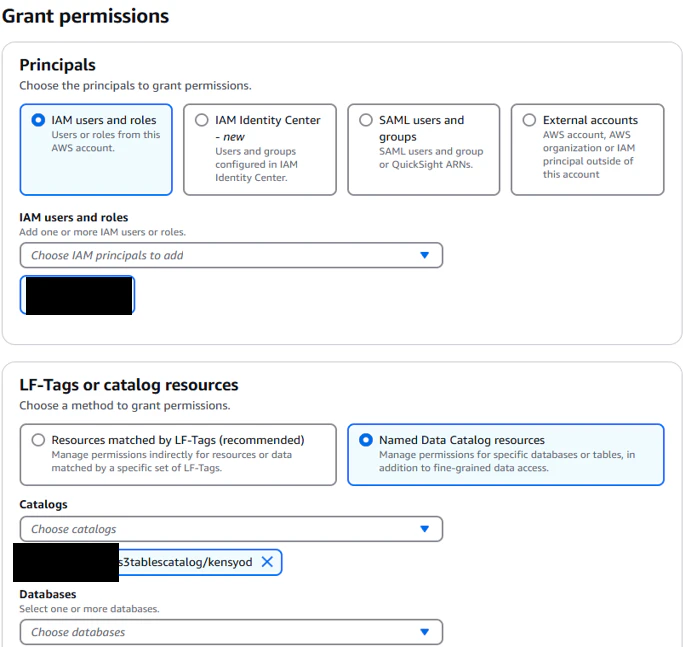
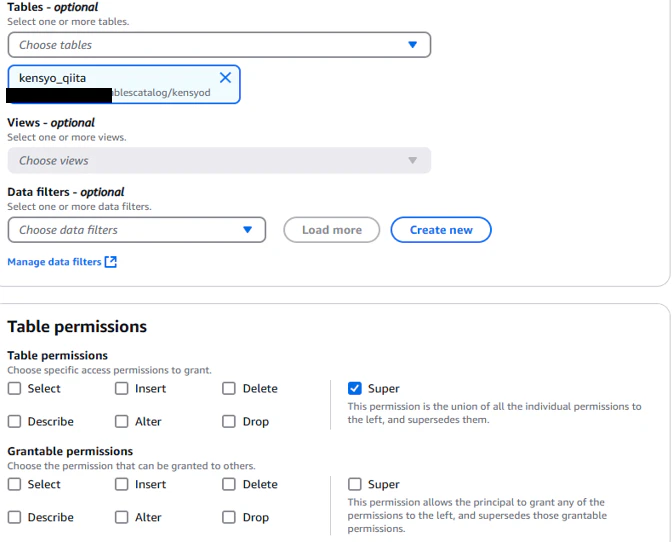
「Super」と強めの権限与えて権限を付与したため、Select文・Insert文・Delete文・Describe文・Alter文・Drop文を実行することができます。今回はSelect文・Insert文・Delete文を実行し、問題なく実行できるか確認してみます。
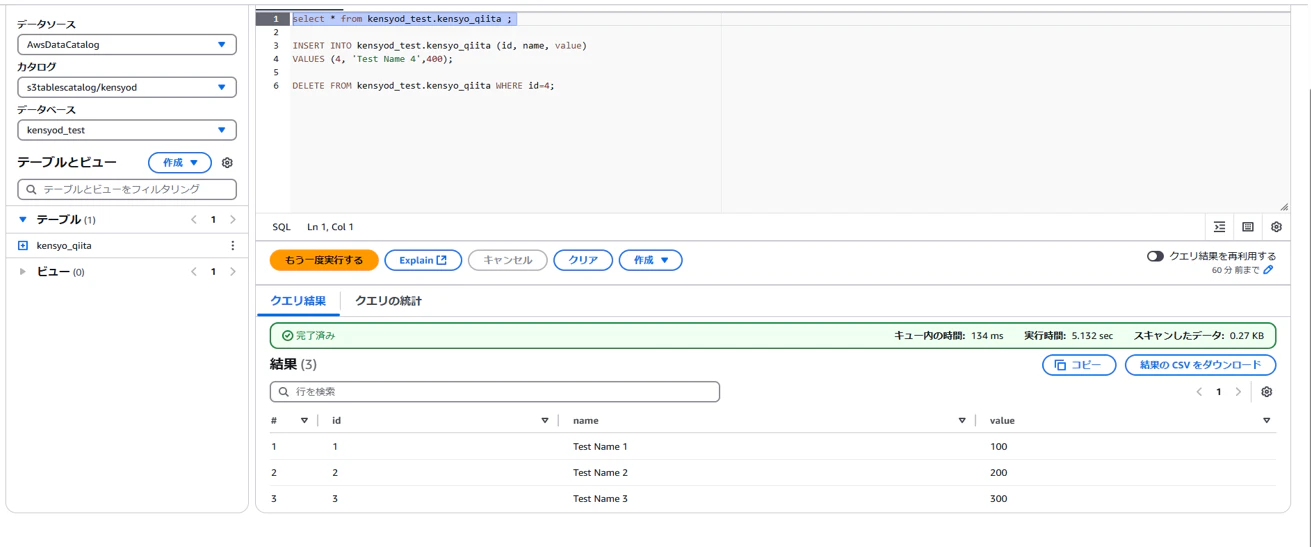
Select文実行
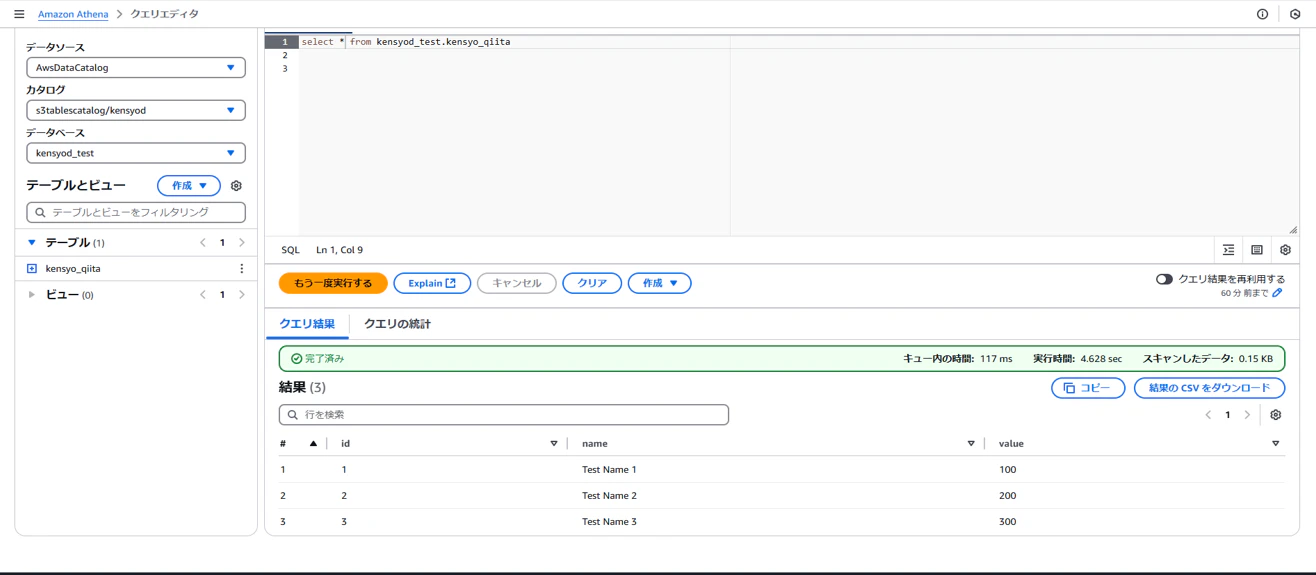
Insert文実行
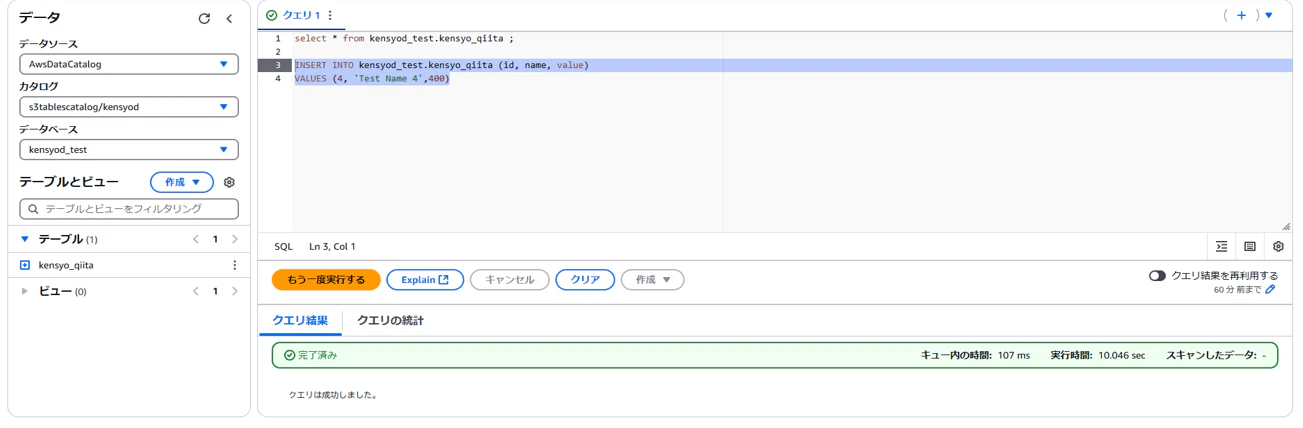
Insert文により、レコードが増えていることを確認

DELETE文実行
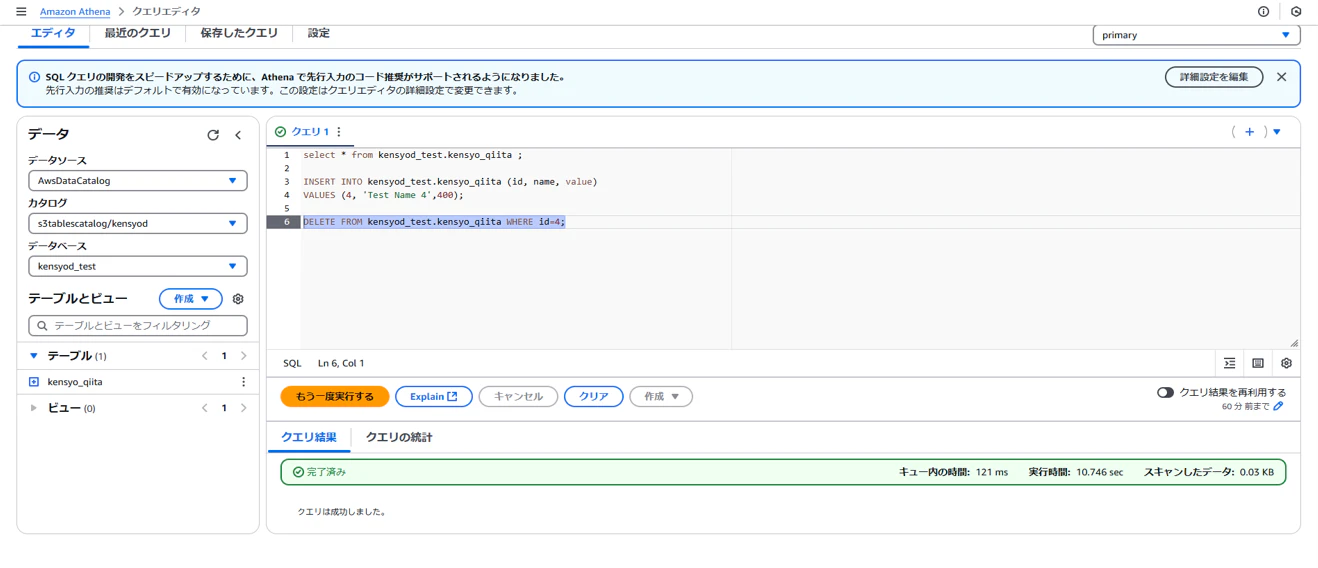
DELETE文により、対象のレコードが消えていることを確認
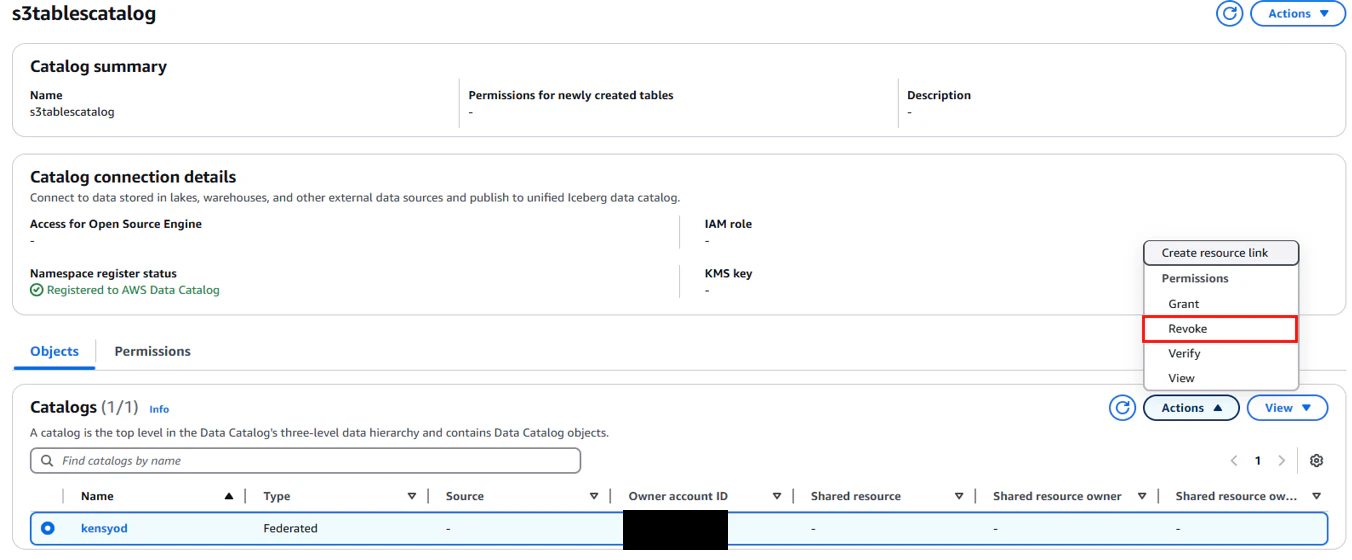
Lake Formationのs3tablescatalog画面に戻り、「Action」→「Revoke」で権限を剥奪する
権限付与の時と同じように設定する
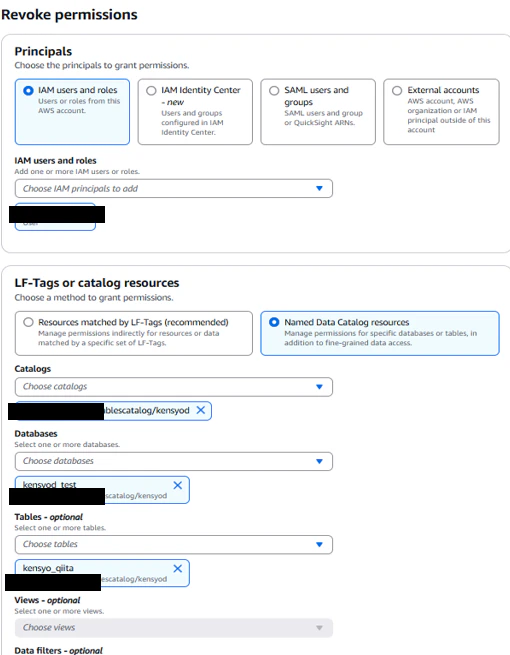
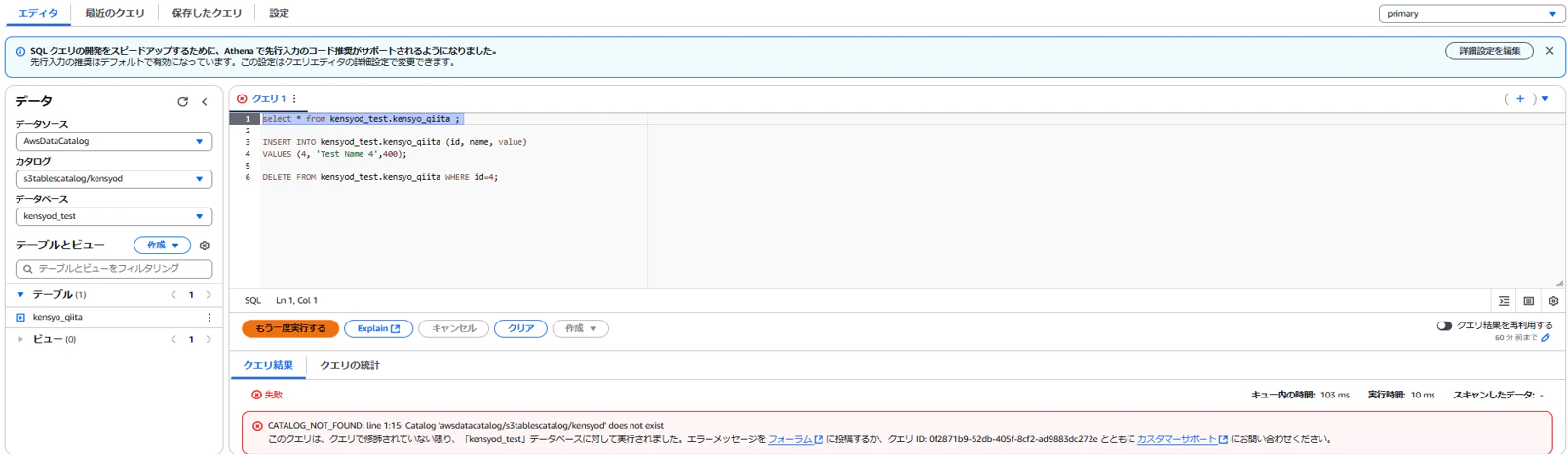
権限を剥奪後にSELECT文を実行したところエラーとなりましたので、テーブルレベルで権限制御可能であることが確認できました。
5-2. メンテナンス機能
S3 Tablesにはメンテナンス機能があります。その中に自動でスナップショットの取得やファイル削除などがあるため、下記メンテナンスジョブのステータス取得コマンドを参考に、メンテナンス機能の検証を行ってみます。
具体的に今回確認したいのは、下記の機能です。
1. 行レベルのトランザクション
2. スナップショット
3. ファイル自動削除
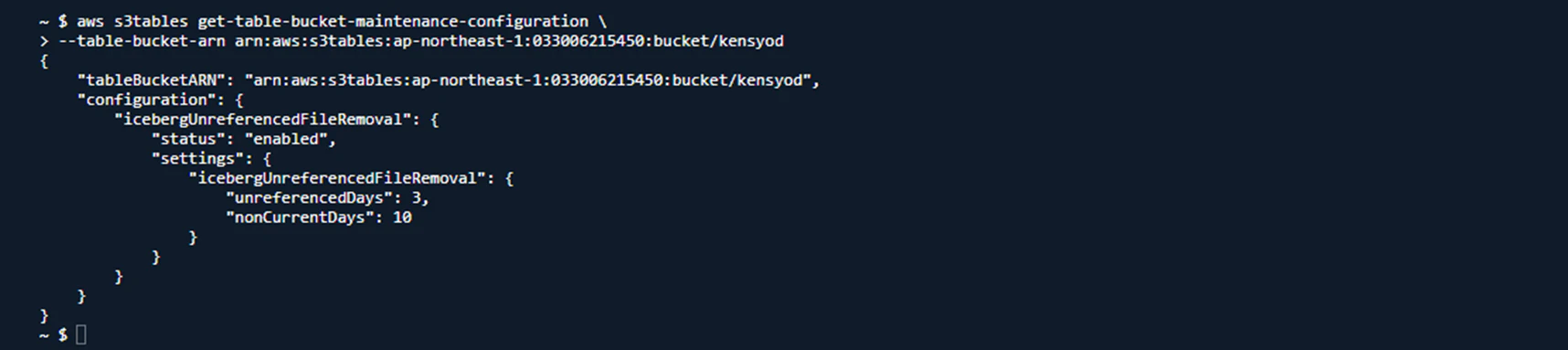
まずは下記コマンドを実行し、ステータスと最終実行時間を取得(ON/OFFと実行時間の確認)
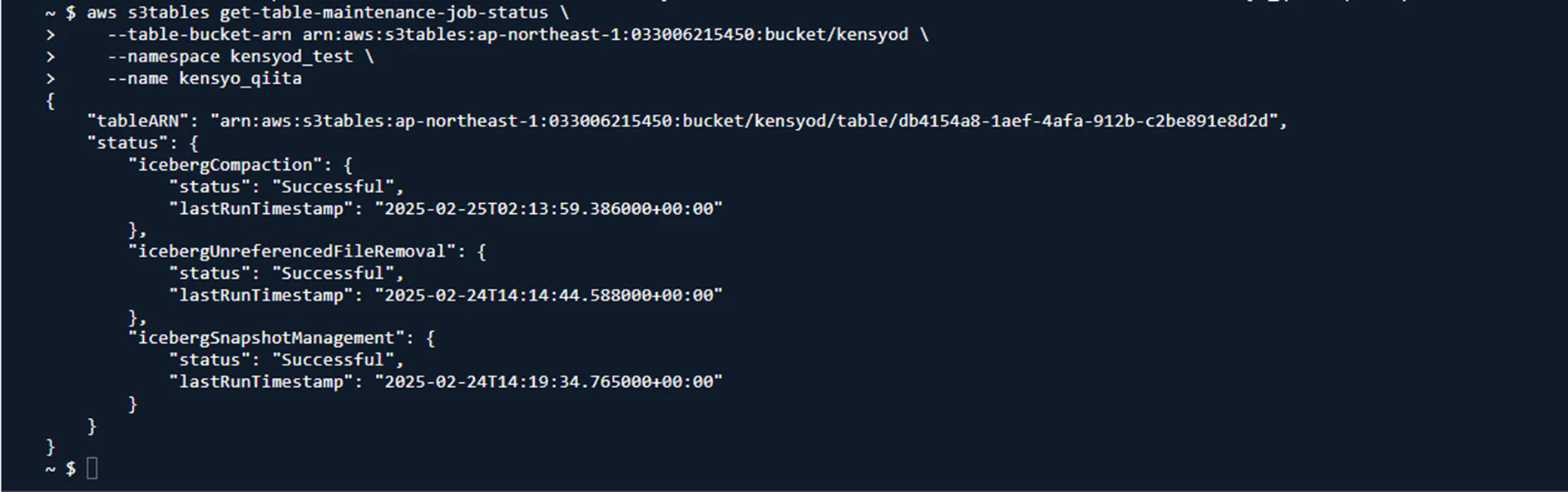
取得情報は以下の通りです。
- 最終圧縮日
- 最終ファイル削除日
- 最終スナップショット日
デフォルトでは全てONになっているため、正常に稼働していることを確認できました。
まずはファイル削除設定がどうなっているか確認します。
現在の設定は以下の通り、「非参照状態まで:3日/削除まで:非参照状態で10日」になっています。
5-2-1. 行レベルのトランザクション
メンテナンス機能の一環として、S3 Tablesでは行レベルのトランザクションが可能となっています。
実際にSQLを用いて1行追加したり、削除したりして挙動を確認してみます。
- INSERT
- INSERT後のデータ
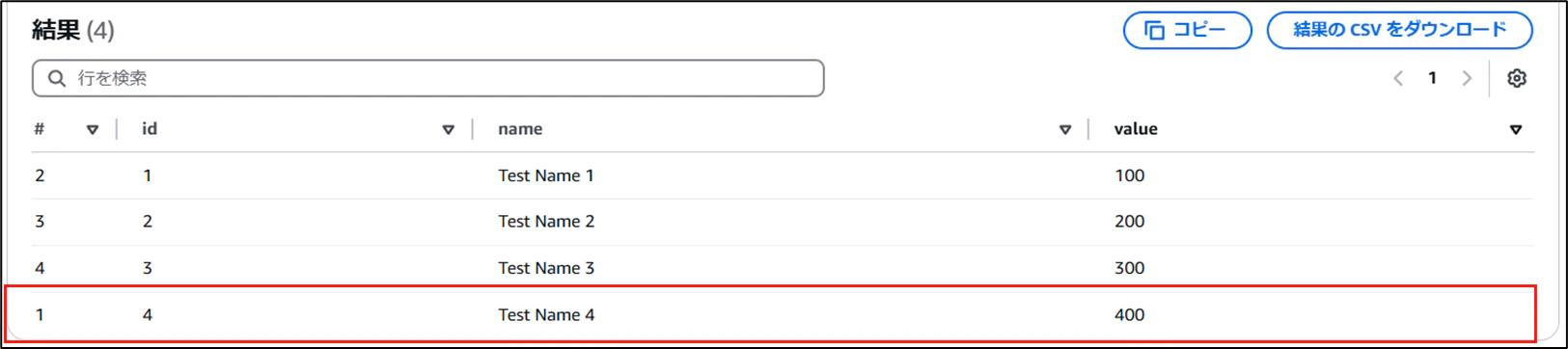
- DELETE
- DELETE後のデータ
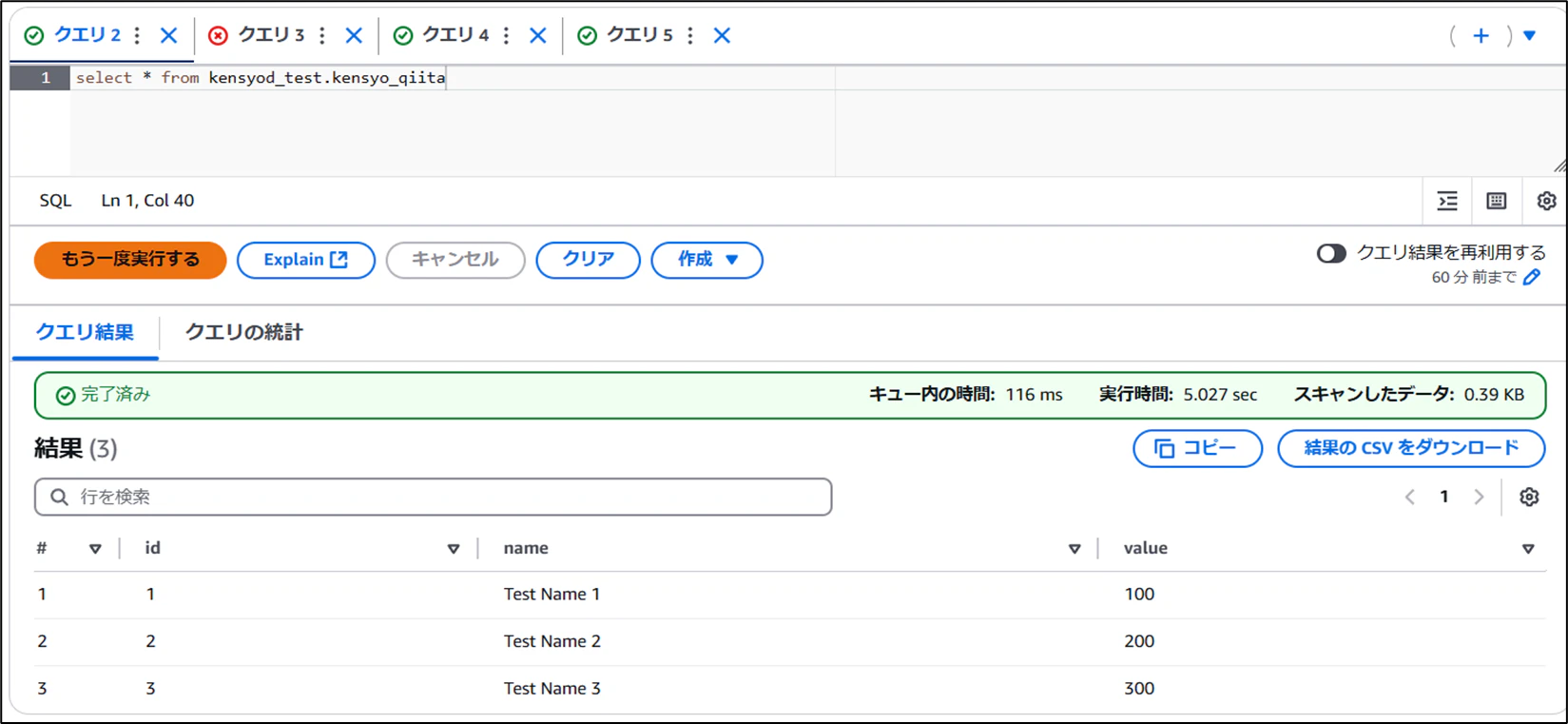
- スナップショットの確認
問題なく実行できることを確認できました。まるでRDBMSを操作しているような感覚です。
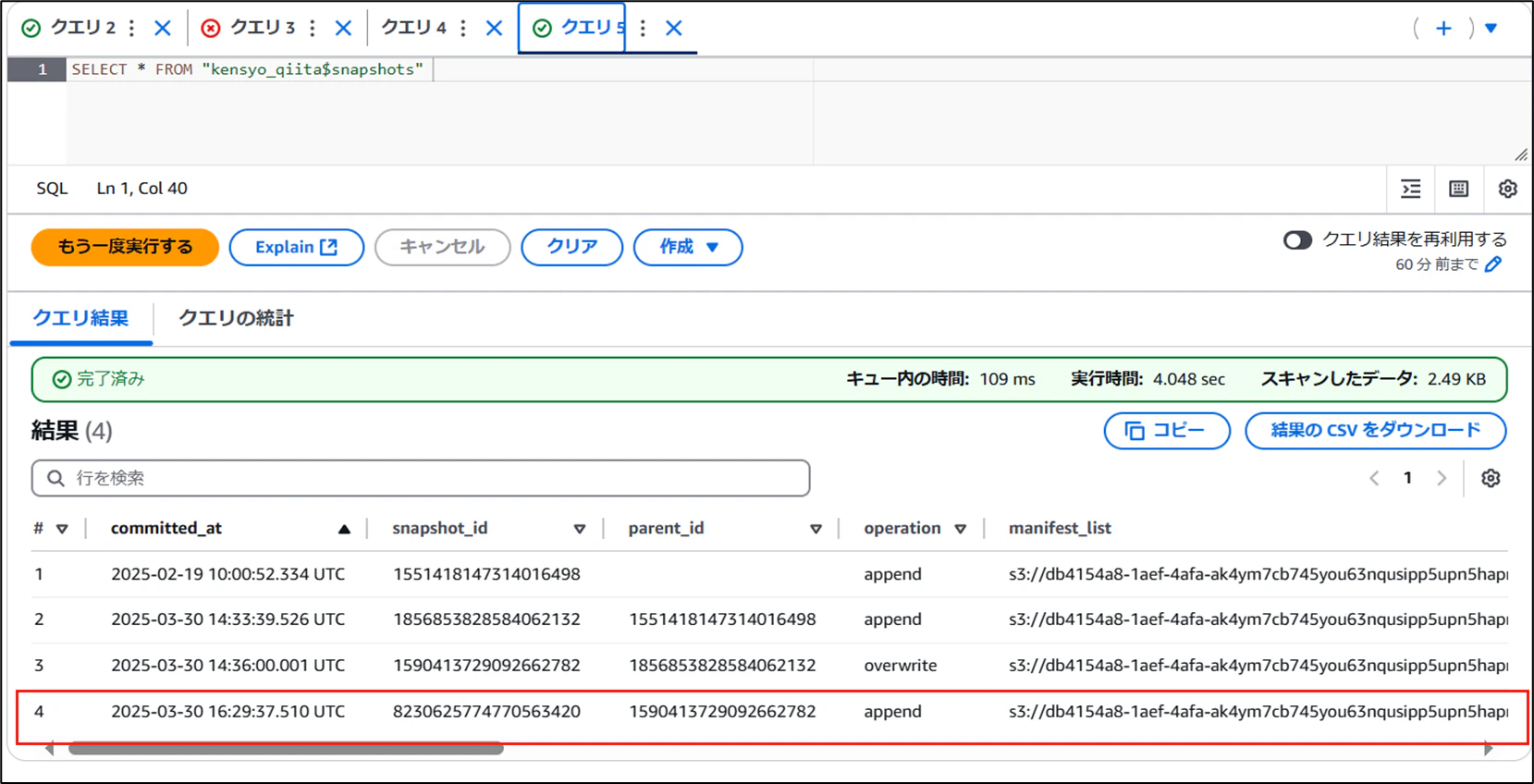
5-2-2.スナップショット
S3 Tablesでは自動でスナップショットを作成してくれるようです。そのため誤操作をした場合でもテーブルを復元可能ですので、実際に検証してみます。
- 最初のデータを確認
- 全てのデータを削除
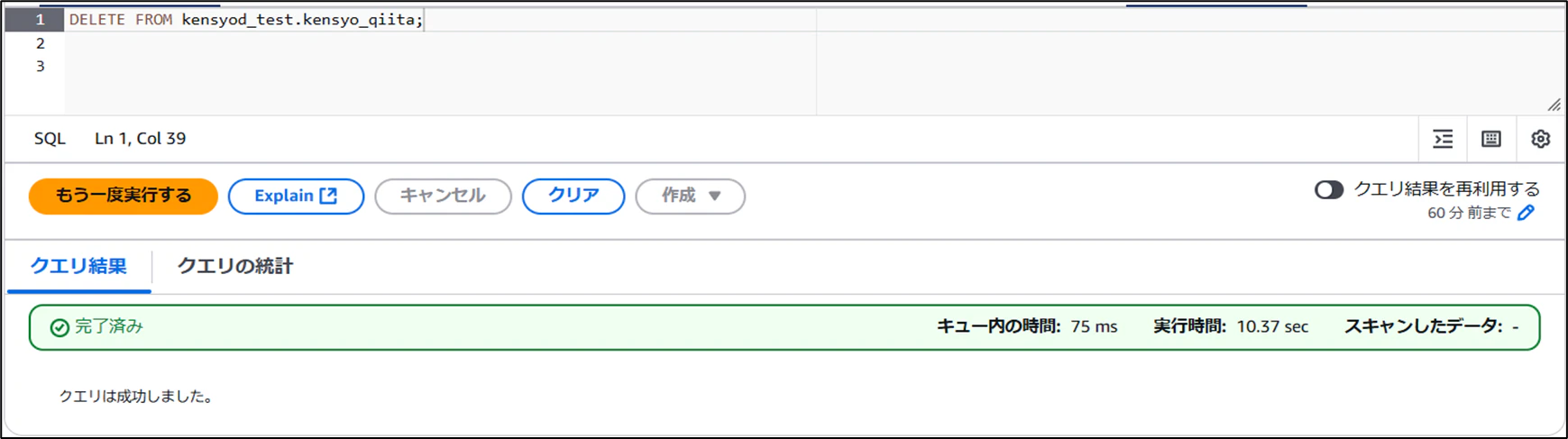
- 削除後のデータを確認
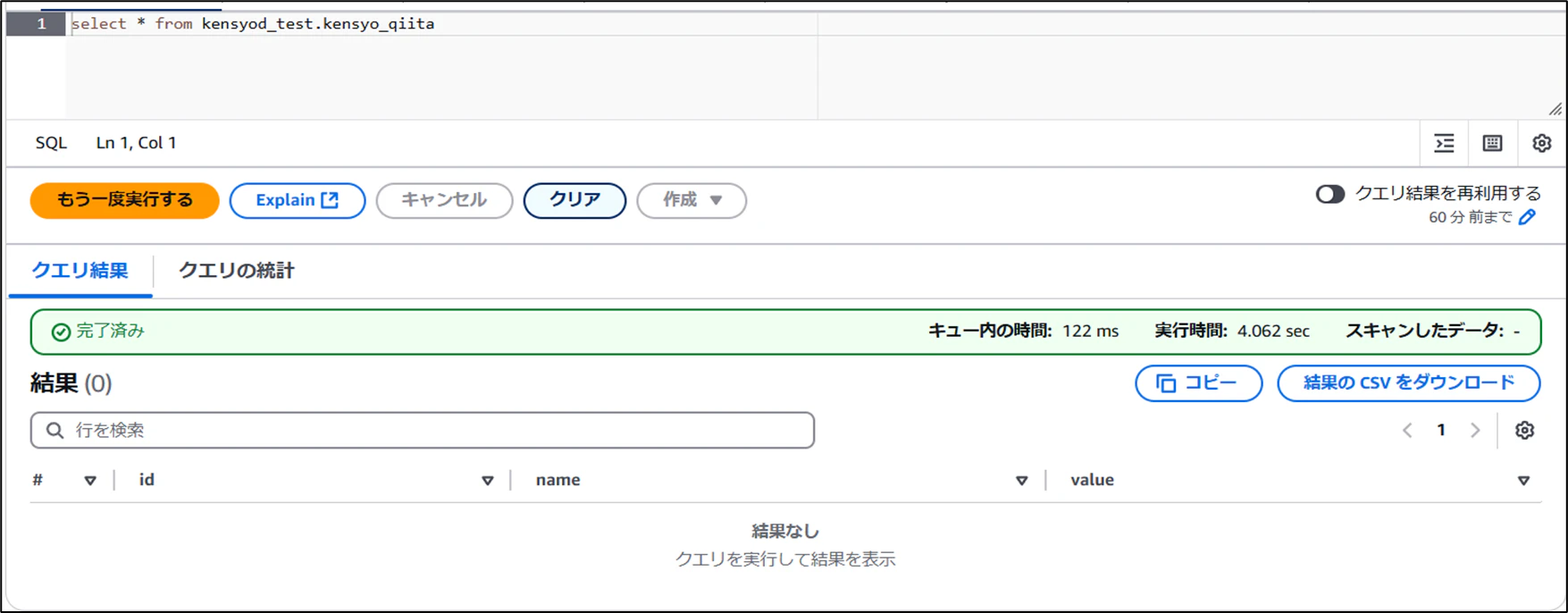
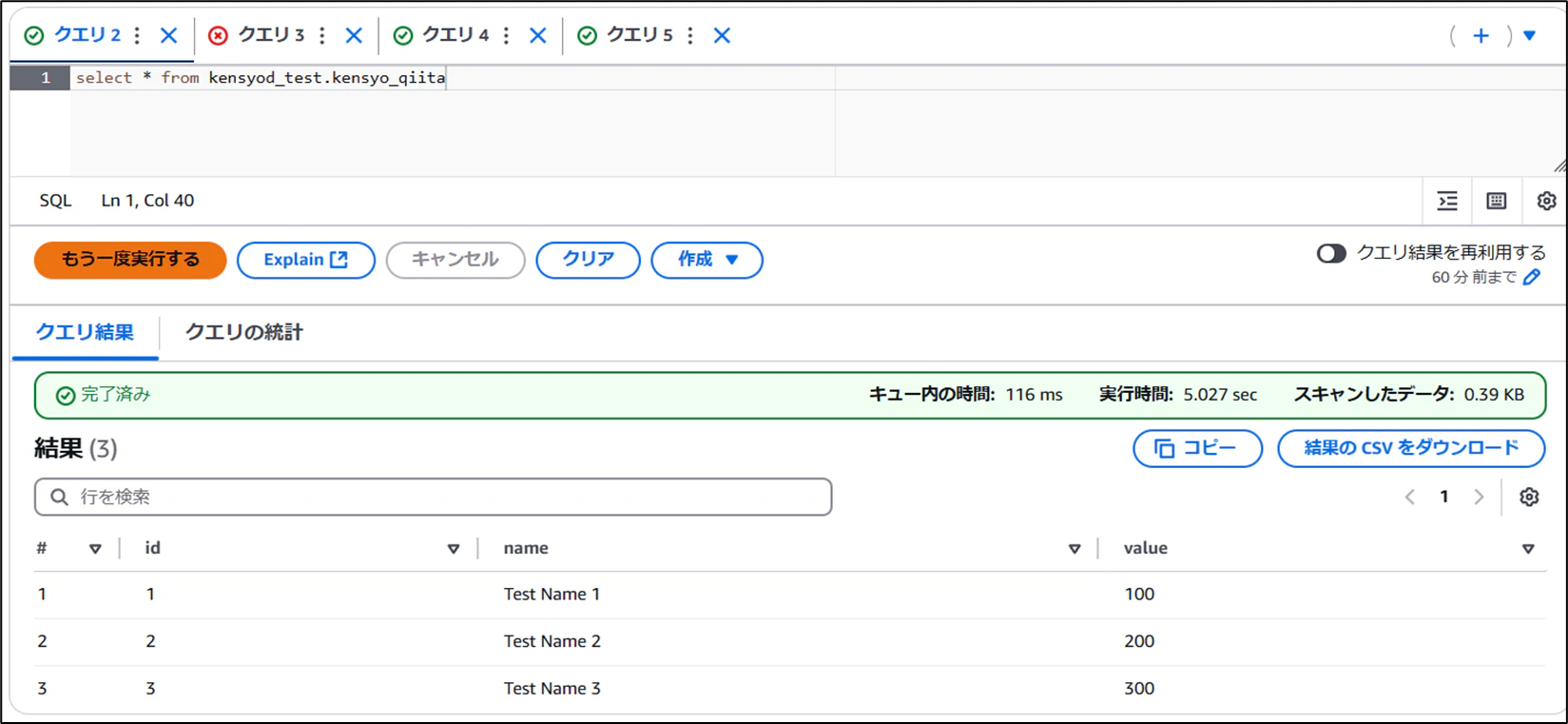
- スナップショットで復元
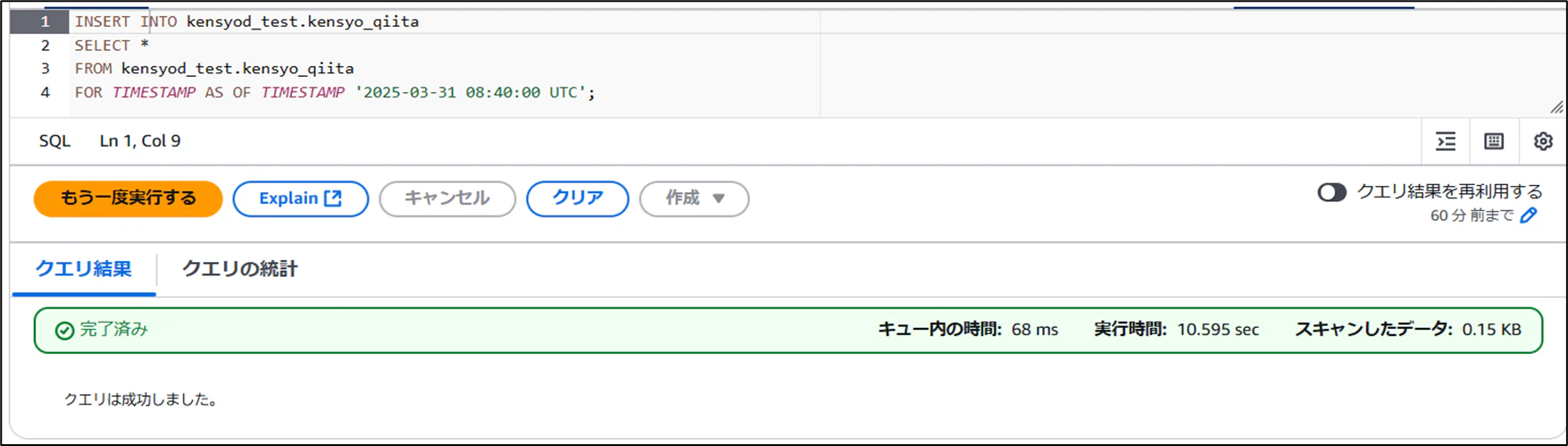
- 復元後のデータを確認
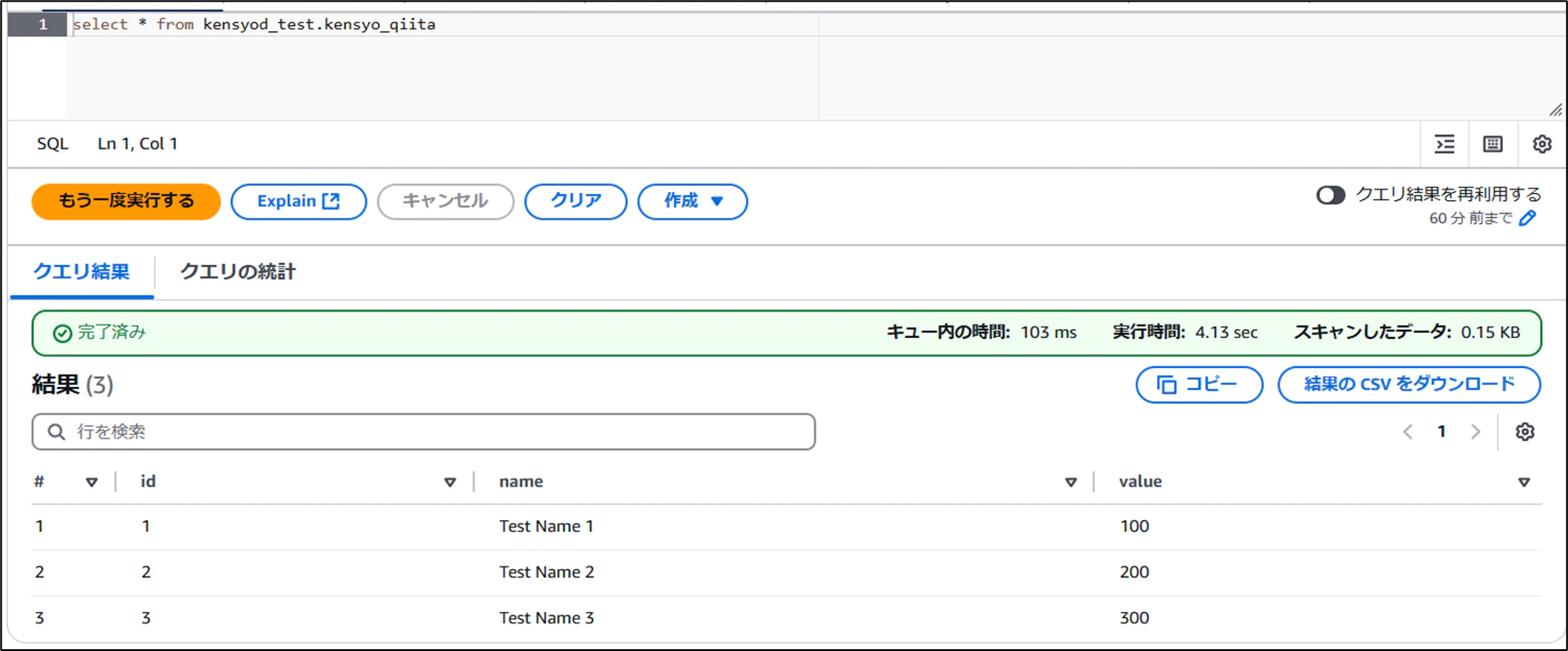
無事復元できました。SQLで復元したいスナップショットを指定することで、指定のバージョンに戻すことができます。
5-2-3. ファイル自動削除
スナップショットの過度な保存を防ぐため、自動削除を行う機能があります。そのためスナップショットの削除インターバルを変更し、削除されているスナップショットで復元不可になるのかを検証してみます。
- 削除インターバルを1日に変更
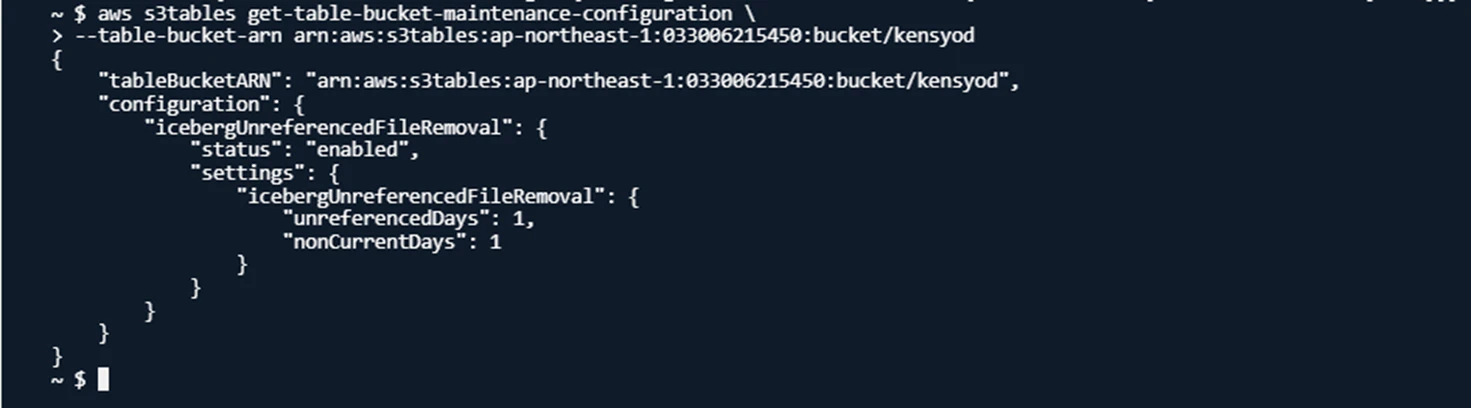
これにより、非参照状態まで1日/削除までさらに1日となります。
数日後、SQLで3日前のものスナップショットが取得できないことを確認してみます。
- 2日前のスナップショットを確認
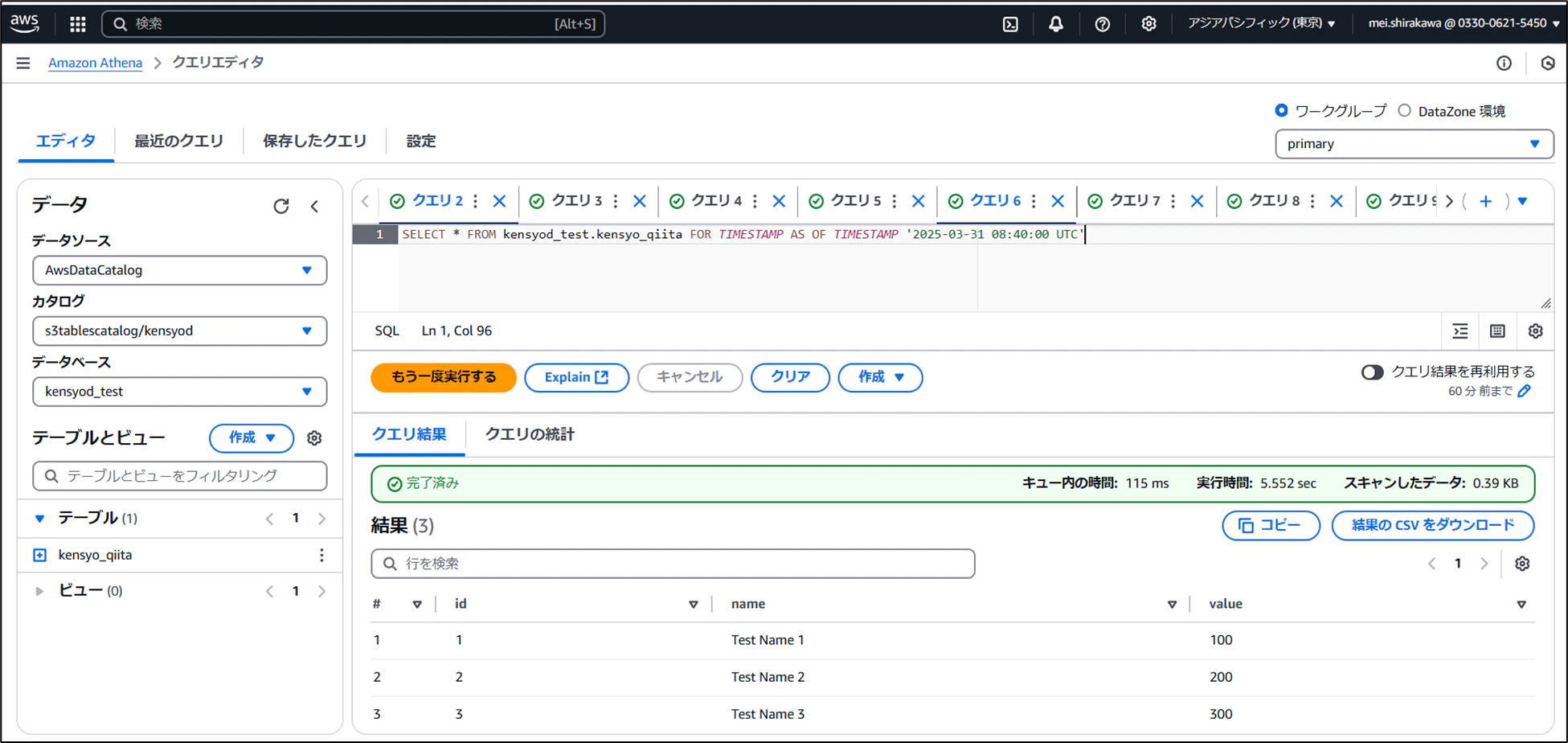
- 3日前のスナップショットを確認
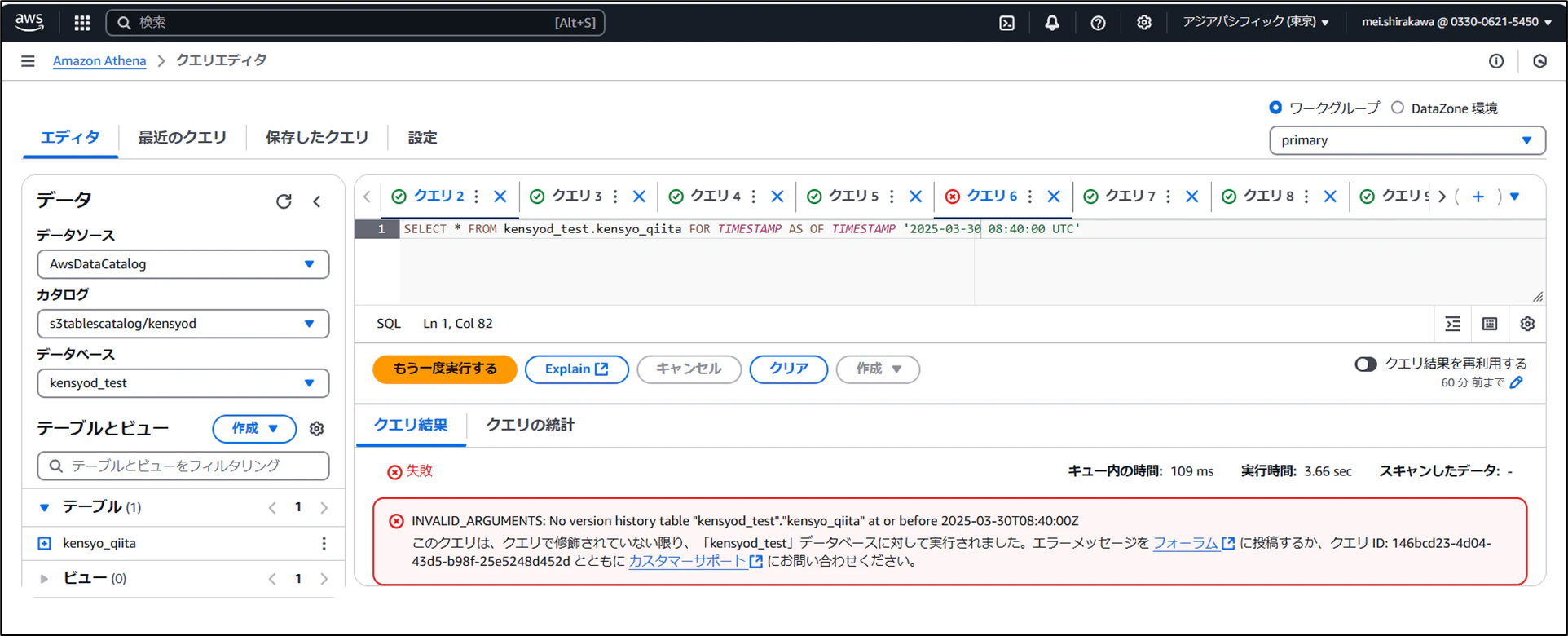
3日前のスナップショットは削除されているため参照できませんでした。
デフォルトでは非参照でも2週間ほどは持つので、要件によって設定を変更するのが良さそうです。
5-3. 機能と料金
ここまでの検証により、S3 TablesのテーブルをQuickSightに反映させることができ、またS3 Tablesの各種機能について触れてきました。
ここで、以下の公式サイトを参考にS3とS3 Tablesの料金についてまとめてみます。
※本検証におけるコスト比較は、東京リージョンの料金体系をもとに代表的な価格指標(例:1GBあたりの単価など)を整理しております。そのため実際の料金は利用状況やリージョンにより異なります。
| 項目 | S3 | S3 Tables |
|---|---|---|
| 基本ストレージ | $0.023/GB | $0.0288/GB |
| データ圧縮 | 対応なし | $0.05/GB |
| データコンパクション | 対応なし | $0.0037/1,000オブジェクト |
| オブジェクトモニタリング | 対応なし | $0.025/1,000オブジェクト |
| PUT/COPY/POST/LISTリクエスト | $0.005/1,000リクエスト | $0.0047/1,000リクエスト |
| GETリクエスト | $0.0004/1,000リクエスト | $0.00037/1,000リクエスト |
| クエリ実行 | - | 別途発生(クエリエンジン利用時) |
結果として、単なるストレージ用途であればS3のほうがコストパフォーマンスに優れます。一方、クエリ頻度が高い・大規模データ分析を行うユースケースでは、S3 Tablesを使うことでパフォーマンス改善や運用効率化が期待できます。
5-4. メリット・デメリット
ここまでの検証によりS3 Tablesは「データ操作」や「行レベルのトランザクション」などDWHのように使用できることが分かりました。ここで、S3 Tablesを使用するメリット・デメリットを大まかにまとめていきます。
【メリット】
・SQLでデータ更新ができ、DWHのように扱える
・ETLが不要
・データ管理をS3に一元化できる
・メンテナンス機能が充実している
【デメリット】
・データ挿入もSQLで行うため、工数がかかる
・高度なデータ変換や前処理はSQLだけでは対応が難しい
・GUIで可能な操作が少ないため難しい
上記のことから「便利ではあるけど操作の部分で不便な点がある」というのが所感です。権限やメンテナンスなど機能も多彩であるためメリットは多く感じられますが、GUI操作の選択肢も少ないため、最初は難しく感じてしまうかと思います。
5-5. ビジネス上での活用方法
実際にビジネス上でどのように活用できるのかを考えてみます。
前述のメリット・デメリットを考慮するのは前提ですが、下記のような状況であればS3 Tablesの導入を検討して良いかと思います。
- 既にAmazon S3を活用している
- DWHのコスト削減を考えている
- ETLプロセスを簡素化したい
- 管理負担を減らしたい
おわりに
今回はAmazon S3 Tablesについて検証を行いました。S3といえばストレージという従来のイメージを覆すような機能が追加され、今後はRDSやRedshiftに代わってS3 Tablesの運用を検討することも可能になりそうです。
特に、AthenaからSQLで直接データ更新ができる点は魅力的でした。ただし、テーブル操作はすべてSQLで行う必要があるため、現状ではデータの挿入が手間になる点が課題として残る印象です。
今後の機能追加として最も期待したいのは、S3上のファイルにクエリを実行し、その結果を直接S3 Tablesに保存・操作できる仕組みです。この点が改善されれば、より柔軟なデータ管理が可能になり、活用の幅も広がるかと思うので、今後のアップデートに期待したいと思います。
参考文献
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください: