はじめに
こんにちは。ここではAmazon Bedrockを使ったヘルプデスク用のチャットボットを構築して実際にヘルプデスク部門で使ってもらっている件について説明を書きます。Bedrockは、Amazonや主要なAI企業が提供する基盤モデル(FM)を統合APIを通じて利用できる完全マネージド型サービスです。単にプロトタイプを作ってみただけで終わらずに、実際に弊社のヘルプデスク部門に導入して利用してもらって、気がついたことや新たな課題も書きます。
ヘルプデスク業務の概要とチャットボットを導入する狙い
弊社ではいくつかのヘルプデスク業務がありますが、ここではマイクロソフト製品のサポート業務に関するヘルプデスクを扱います。弊社のヘルプデスク担当は弊社の社員からマイクロソフト製品に関する質問(使い方やトラブルの解決方法など)を受けて、回答を作成して質問者へ返します。回答を作成するためには、マイクロソフト製品に関する正しい知識を基に分かりやすい的確な文章をなるべく短時間に作成する必要があります。また、マイクロソフトからの公式情報を調べて回答を作成する必要があることもしばしばあります。回答を作成するためには少なくない時間と手間がかかります。また、慣れていない担当者の場合はより多くの時間がかかったり、品質を十分にするためにはベテラン社員の添削も必要になります。このような業務を効率化するために、担当者は質問をチャットボットに投げて品質の良いドラフト(回答の下書き)を得ることができれば、それに僅かな修正を加えるだけで質問者に十分な品質の回答を短時間で返すことができるようになります。生成AIは100%の精度の回答を書く事はできないため、質問者からの質問を担当を介さずに直接チャットボットから回答を質問者へ返すことはやりません。あくまでも回答を返すのは弊社ヘルプデスク担当者ですが、担当者がゼロから回答を作成するのではなくて生成AIにある程度の精度の高い回答(ドラフト)を作成してもらいそれを修正・確認して質問者に回答を返すことで迅速で正確な回答を返す事を実現したいです。チャットボット導入前と導入後のイメージを図に示します。
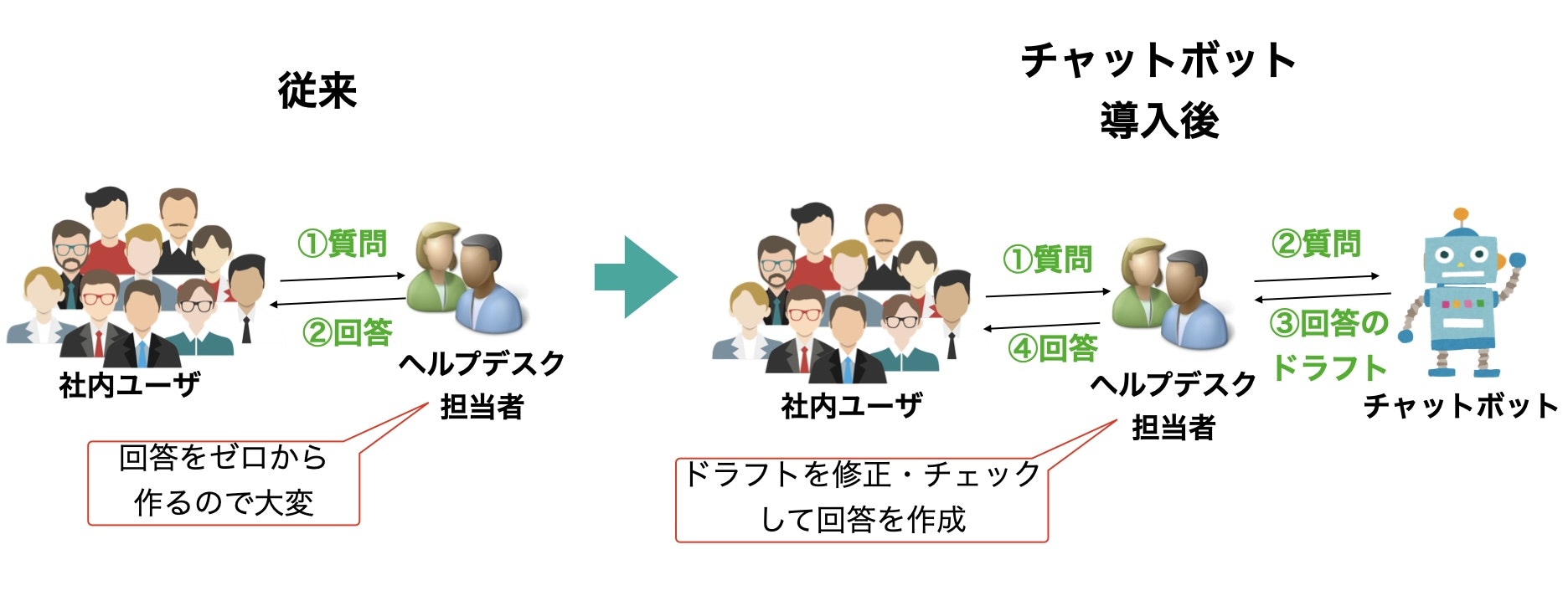
ヘルプデスク部署からの要求条件
弊社のマイクロソフト製品のヘルプデスクを担当している部署が欲しいチャットボットとしては以下のような要求条件を満たすものでした。
- 過去の質問と回答を参考にドラフトを生成して欲しい。つまり、同様な質問の場合は過去の回答をベースにドラフトを生成して欲しい
- セキュリティを担保してほしい:①過去の質問と応答をAWSにアップロードした場合外部へ漏洩することは防ぎたい②弊社の社員であっても担当者以外はチャットボットにアクセスできないように制限したい
- マイクロソフトの公式情報も参考にしてドラフトを生成して欲しい
- 普段teamsを業務で使っているのでUIがteamsだと使いやすい
teamsはマイクロソフト製品ですが、それ以外は全てBedrockを使って構築することを考えました。
アーキテクチャの検討
上記要求条件を基にして以下の図のようなアーキテクチャを考えました。
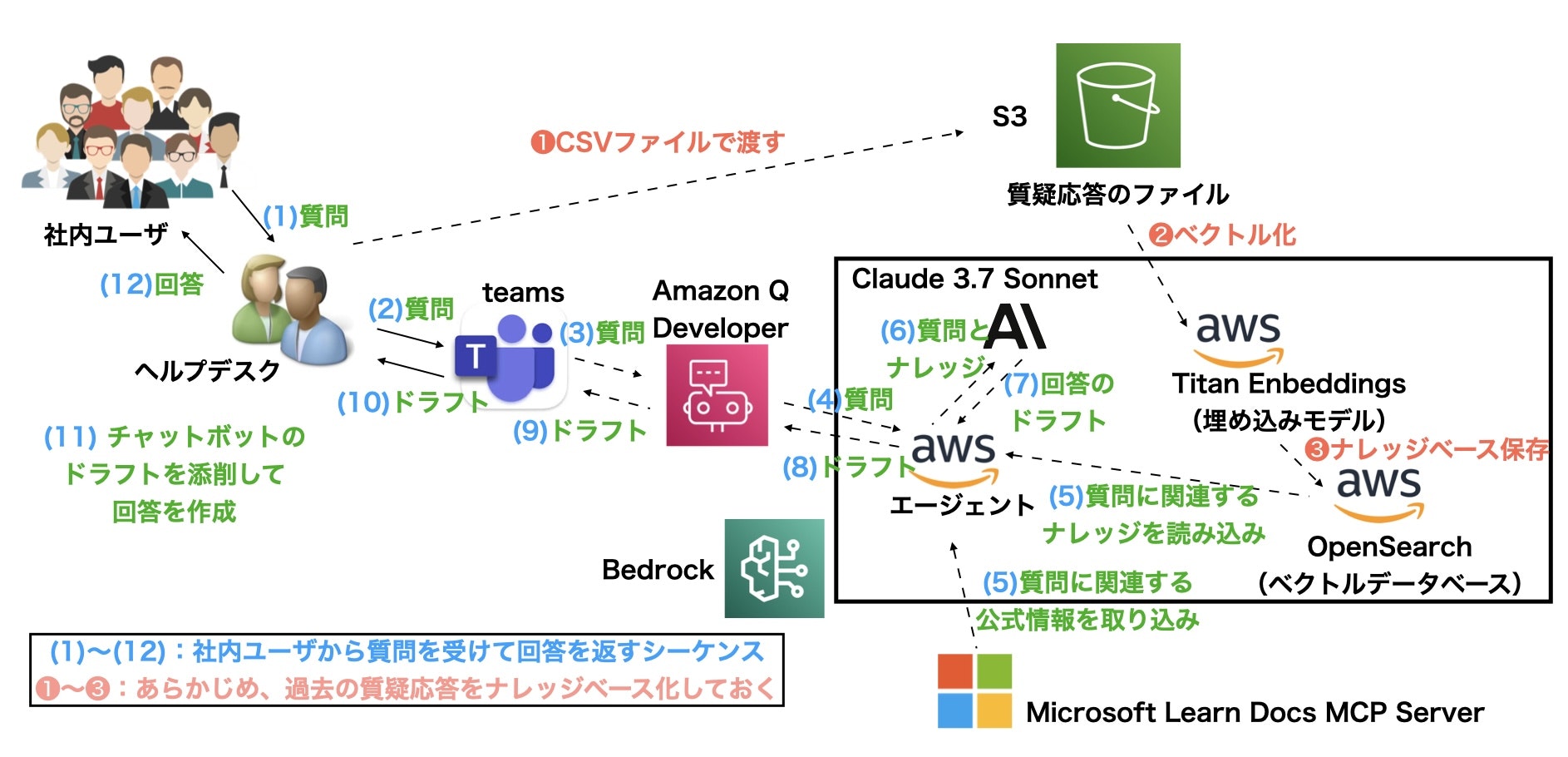
Amazon Bedrockの他にはS3、Q Developerを使います。また、UIであるteamsとMCPサーバはマイクロソフト製です。このチャットボットを作成した時(2025年前期)ではClaude4シリーズはBedrockでは使えなかったため、Claude3.7を使いました。
検討の詳細
1. 過去の質問と回答をナレッジベースにする検討
過去の質問と回答はヘルプデスク部門で作成しCSVファイルにまとめてもらいました。そのファイル名をこの記事ではhelpdesk.csvと呼びます。これをナレッジベースにします。S3にアップロードした上で、ベクトル化を行います。ベクトル化を行うモデルはAmazon Titan Text Embeddings V2を使いました。ベクトル化したデータはAmazon OpenSearch Serverlessを利用しました。実は、今回、Amazonの色々なモデルを使いましたが、このOpenSearchが最も高価なサービスで、24時間で約7ドルくらいかかります。このコストを抑えたい場合は他の選択肢を検討する必要があります。
質問と回答は、日々、増加していきます。新しい質問と回答を含んだファイルhelpdesk-new.csvをアップロードした際にはナレッジベースも更新(再同期)したいです。S3のトリガを設定することでファイルをアップロードするとベクトルデータベースが自動的に最新化するようにしました。この最新化の最中でも、チャットボットはサービスが止まらないことも確認しました。
後日、ファイルを削除した場合にも自動的に再同期できるようにトリガを修正しました。
2. セキュリティの検討
①外部からの不正アクセスの防止
S3を適切に設定すれば、高いセキュリティを実現できます。例えば、デフォルトではパブリックアクセスをブロックするように設定されていますが、ブロックを解除すると外部からアクセスされてしまう可能性があります。S3へのアップロードはhttpsで暗号化して送信します。また、S3への保存は、デフォルトでは暗号化されて保存されます。つまり、デフォルトではデータは暗号化されますしそもそも外部からアクセスできないようになってます。これを間違えて解除しないように適切に使っていれば問題ないです。
しかし、別のレベルのセキュリティ低下の懸念として、S3の使い方を間違えるようなヒューマンエラーによって情報漏洩する可能性もあるかと思います。例えば、A組織の情報に間違えてB組織の情報を加えることでA組織にB組織の情報が漏洩してしまうという懸念があります。これをなるべく避けるためには、例えば、A組織とB組織の情報は別のバケットに保存するように設定する方が良いかと思います。同じバケットの中に保存すると、間違って混ざりやすいかと思います。また、バケットを分ければ、バケットごとに制限を変更する運用も良いかと思います。
②弊社社員でも担当者以外は制限をかけたい
AWSではユーザやロールを制限することで内部からのアクセスも制限する事ができます。また、今回はteamsをUIに使うので、チャットボットを利用する専用のチャネルをteams内に作成し、ユーザのそのチャネルへのアクセスを制限することで弊社担当者のみがアクセスできるようになります。
3. MCPサーバを利用してマイクロソフトの公式情報から情報を獲得する検討
マイクロソフトの公式情報から質問の回答に使える情報を引き出す方法としては、以下の2点を検討しました。
(1) マイクロソフトの公式情報を公開しているWEBページからナレッジベースを作成する
これは、上記1. のCSVファイルからナレッジベースを作る場合と同様、マイクロソフトの公式情報を公開しているホームページのURLからナレッジベースを作ります。つまり、指定したURL以下のすべてのページの情報をAmazon Titan Text Embeddings V2でベクトル化し、Amazon OpenSearch Serverlessに情報を蓄えます。
(2) マイクロソフトのMCPサーバを利用する
マイクロソフトはマイクロソフトの最新の技術情報を提供してくれるMCPサーバを公開していますので、これを利用する方法です。
(1)の場合、公開されている情報、つまり、ホームページの記述内容が変わったり追記されたりした場合、新たにナレッジベースの更新を行う作業が必要になります。自動的には更新できませんから、ヘルプデスク担当の誰かがホームページの更新を即座に気が付く必要があり、そして、即座に更新する必要があります。これを怠ると、古い情報を基にしたドラフトになってしまします。また、Amazon OpenSearch Serverlessは24時間でおよそ7ドル程度の費用が必要でしたが、上記helpdesk.csv用のOpenSearchとこの公開情報用のOpenSearchが必要なり、コストは倍になります。現状は、CSVファイルの情報とURLで指定したホームページの情報とを統合して一つのOpenSearchに保存することはできません。
(2) の場合、公開された情報が更新された直後からMCPサーバは最新の情報を返すことができます。また、MCPサーバは無償で利用可能であり、OpenSearchの利用コストを省くことができます。しかし、注意点として、MCPサーバは日々進化しており、利用できるツールが変わったり、予期せずダウンしていて使えないことも稀にあるようです。また、MCPサーバへの接続はBedrockのエージェントのaction groupでのLambda関数の作成が必要となり、簡単ではありません。MCPサーバへの接続方法は別の記事で書こうかと思います。
以上、利点と欠点がそれぞれにありますが、MCPサーバを利用する方がメリットは大きいと判断して、MCPサーバを使うことを選択しました。
4. teamsをインターフェースにする検討
Amazon Q Developerはエージェントのインターフェースとしてteamsを接続する機能があります。これを利用しました。
ヘルプデスク部門で実際に使用して出た感想や問題点
現在、弊社のマイクロソフトに関するヘルプデスク業務で実際に利用されており、従来の担当者がゼロから回答を作成するより効率が上がっているようで継続して利用してもらっています。
更なる改良に向けて
実際にヘルプデスク業務で使用していると、新たな要求が生まれてきました。例えば、あるマイクロソフト製品を使っていてエラーが出た場合、エラーメッセージが出た画面のスクリーンショットを撮りその画像ファイルを添付した上で「添付画像のようなエラーが出たのですが、どうしたら解決できますか?」というような質問に対する回答の作成を更に効率化できないか?というものです。現状は、添付画像の中のエラーメッセージをヘルプデスク担当者が目視で取り出し、チャットボットにエラーメッセージを含めて「⚪︎⚪︎⚪︎というエラーメッセージの解決策は?」と送信しています。添付画像と質問文両方を対処できれば、このエラーメッセージをヘルプデスク担当者が目視で抜き出すという一手間は必要なくなります。しかし、調査してみたところ、現状のBedrockにはこれを簡単に実現する方法はなさそうです。AWSの技術者にも聞いてみましたが、簡単に実現する方法は無いようです。
実際に起きた二つの問題
ヘルプデスク部門で継続して使っていると、以下の二つの問題が発生しました。
(1) 「\n」を含むドラフトが稀に生成されてteamsの画面に表示されてみにくい

稀にですが、文章の中に「\n」が表示されてしまい、見にくいという問題です。私は再現試験を実施しましたが、再現することはありませんでした。ヘルプデスク部門でも再現しなくなったということで何も対処せずに問題が解決しましたが、ネットなどの記事によるとClaudeの不具合の可能性があります。おそらくはClaudeの開発元のAnthropic社で改善が施されたため、再現はしなくなったと思われます。
(2) タイムアウトが発生し、teams に「CHATBOT has exceeded the timeout limit handling this request」と表示されて異常終了した
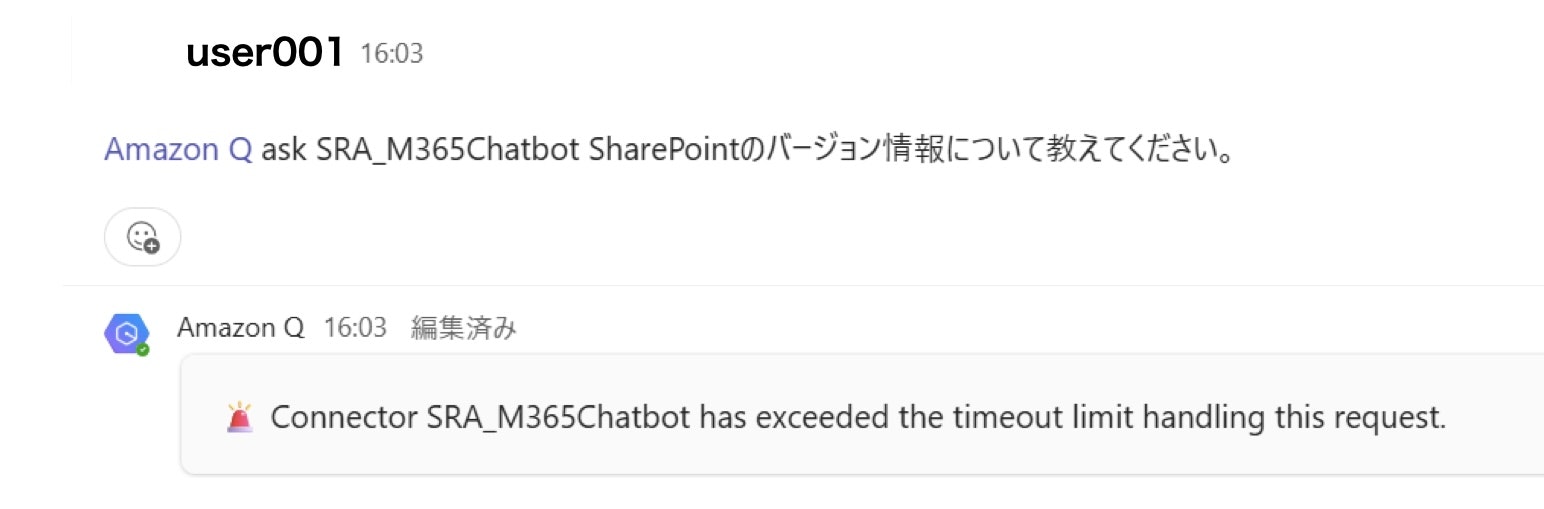
チャットボットのどこかでタイムアウトが発生して正常に応答が返ってこないエラーです。この問題も、再現試験を行ないましたが再現しませんでした。
この件はおそらくはチャットボットがマイクロソフトのMCPサーバへ問い合わせが必要な質問時に起きているらしいと思っています。また、別の実験で知りましたが、マイクロソフトのMCPサーバは応答を返すまでに20秒程度かかります。さらに、私が作ったMCPサーバへの接続のコード中でMCPサーバの応答待ちタイムアウトを25秒に設定していることから、このタイムアウトの上限に引っかかったことが原因かと推測しています。
この問題から感じたこと
問題が発生すると、ログを出力したいと思います。上記(1)については、Claudeに渡すプロンプトの中身やClaudeが生成した中身などをログに出したいです。上記(2)については、MCPサーバに渡すリクエストの中身やMCPサーバからの応答の中身などです。しかし、Bedrockではサクッと簡単にこれらのログを出力する方法がありません。AWSでは以下のような理由からClaudeへの入力・出力ログをサクッと簡単に取る仕組みは、デフォルトではありません。理由はセキュリティとコストの観点があります。
(1) セキュリティ:プロンプトに機密情報などが含まれた場合、これをログに保存することで機密情報の漏洩につながるリスクがあります。特に、金融、医療、公共サービスなどでは生成AIの入出力ログは残さない強い要件があるそうです。従って、AWSではサクッと簡単にログを出力できないようです。しかし、CloudWatch LogsやS3などを使うことでログ出力を設定することは可能です。
(2) コスト:ログは大量になってしまう可能性がありますが、CloudWatch Logsを使うにしてもS3を使うにしても料金が発生します。簡単にログが取れて予想外に高い料金が発生するのを防ぎたい狙いもあるようです。
まとめ
以上で、Bedrockを使ってヘルプデスク用のチャットボットを作成し、実際にヘルプデスク部門で使ってもらって分かったことについて説明しました。現在、継続的に使ってもらっていますが、以下のような新たな課題が見つかりました。
(1) 添付画像ファイル付きの質問にも回答できるようにしたい
(2) MCPサーバへの接続が複雑(設定だけでなく、コーディングも必要)
(3) ログを簡単に出力できない(出力するように構築する事は可能だが、セキュリティやコストに注意しなければならない)
Bedrockは今回作成したようなチャットボットをサクッと構築するためには非常に有用だと思います。ただ、最後で説明したように、細かなチューニングを行おうとするとなかなか大変だと思いました。これに対してLangChainは非常に柔軟性があるということがメリットであるため、上記ポイントがLangChainではどうなるかなども検討しています。これについては、別の記事に書きたいと思います。
[追記1]: LangChainを使ったチャットボットの記事はこちらをご覧ください。
[追記2]: 本記事で紹介したチャットボットでMCPサーバと接続する方法についてはこちらをご覧ください。