はじめに
みなさんはSpreadSheetやExcelなどの図表ソフトでデータを扱う機会がどれくらいあるでしょうか?
多くの方が業務内で多くの時間をかけて使用されていると想定されます。
多くの時間をかける図表データをPythonで操作でき、かつ、ルーティンワークを自動化できれば業務効率化にきっと繋がります。
それでは、人気のPythonでSpreadSheetを操作してみましょう。
概要
本記事では、Google Drive内にあるSpreadSheetに対して「読み/書き/消去/フォーマット変更」を行うためのPython Classを公開します。
すでに巷ではgspreadという便利なPython Libはありますが、以下の目的でやってみましょう。
- Google APIの使い方に慣れる
- Format変更をRequestを通して実施してみる
今回はあえてClassを定義しインスタンス化して使用する例を提示します。
インスタンス化することで複数のSpreadSheetを同時に編集できますので是非試してみてください。
また、あくまでClassは例ですので、気になった方は自分でカスタマイズしてみてください。
前提
- 本記事ではPandasのDataframeで表を描写して視覚的にわかりやすくするため、Jupyter Notebookを使用しています。ただし、通常のPy fileで使用もできます。
- PythonからGoogle Sheets APIに認証できるように以下の記事を実施してください
- 下記の公式URLからtoken.pickleをダウンロードし、"spreadsheet_token.pickle"にリネームしてください
- 上記のtokenのダウンロードの仕方を解説付きで確認したい方は以下のURLを参考にしてください
手順
1. 以下のようなSpread Sheetを用意します
今回はA~E列、1~10行目に値を入力したSheetを用意しました。(WorkSheet名は'sample')

2. Jupyter Notebookでipynbを作成し、ステップに以下のClassをコピペし実行します
コードを見る
import re
import time
import json
import copy
import pickle
import os.path
from pprint import pprint
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
class SpreadSheetsApi:
def __init__(self,SPREADSHEET_ID,RANGE_NAME):
self.service = self.launch_api()
self.values = self.read_sheet(SPREADSHEET_ID,RANGE_NAME)
def launch_api(self):
SCOPES = ['https://www.googleapis.com/auth/spreadsheets']
creds = None
if os.path.exists('spreadsheet_token.pickle'):
with open('spreadsheet_token.pickle', 'rb') as token:
creds = pickle.load(token)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
'credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
with open('spreadsheet_token.pickle', 'wb') as token:
pickle.dump(creds, token)
service = build('sheets', 'v4', credentials=creds)
return service
def read_sheet(self,SPREADSHEET_ID,RANGE_NAME):
# Call the Sheets API
sheet = self.service.spreadsheets()
result = sheet.values().get(spreadsheetId=SPREADSHEET_ID, range=RANGE_NAME).execute()
self.values = result.get('values', [])
return self.values
def write_values(self,SPREADSHEET_ID,RANGE_NAME,value_list):
# Call the Sheets API(Overwrite Sheets)
ValueInputOption = 'RAW'
body = {
'values': value_list,
}
result = self.service.spreadsheets().values().update(spreadsheetId=SPREADSHEET_ID, range=RANGE_NAME,valueInputOption=ValueInputOption, body=body).execute()
self.values = self.read_sheet(SPREADSHEET_ID,RANGE_NAME)
def clear_contents(self, SPREADSHEET_ID, sheet_num,start_row):
# Call the Sheets API(Append Texts)
ValueInputOption = 'USER_ENTERED'
requests = []
requests.append({
"updateCells": {
"range": {
"sheetId": sheet_num,
"startRowIndex": start_row
},
"fields": "userEnteredValue"
}
})
body = { 'requests': requests }
response = self.service.spreadsheets().batchUpdate(spreadsheetId=SPREADSHEET_ID, body=body).execute()
self.values = self.read_sheet(SPREADSHEET_ID,RANGE_NAME)
def change_format(self,SPREADSHEET_ID,sheet_num,value_list):
# Call the Sheets API(Append Texts)
ValueInputOption = 'USER_ENTERED'
requests = []
requests.append({
"repeatCell": {
"range": {
"sheetId": sheet_num,
"startRowIndex": 0,
"endRowIndex": 1,
"startColumnIndex": 0,
"endColumnIndex": len(value_list[0]),
},
"cell": {
"userEnteredFormat": {
"horizontalAlignment" : "CENTER",
"textFormat": {
"fontSize": 18,
"bold": True,
}
}
},
"fields": "userEnteredFormat(textFormat,horizontalAlignment)"
},
})
requests.append({
"updateBorders": {
"range": {
"sheetId":sheet_num,
"startRowIndex": 0,
"endRowIndex": len(value_list),
"startColumnIndex": 0,
"endColumnIndex": len(value_list[0])
},
"top": {
"style": "SOLID",
"width": 1,
},
"bottom": {
"style": "SOLID",
"width": 1,
},
"right": {
"style": "SOLID",
"width": 1,
},
"right": {
"style": "SOLID",
"width": 1,
},
"innerHorizontal": {
"style": "SOLID",
"width": 1
},
"innerVertical": {
"style": "SOLID",
"width": 1
},
}
}
)
requests.append({
"autoResizeDimensions": {
"dimensions": {
"dimension": "COLUMNS",
"startIndex": 0,
"endIndex": len(value_list[0])
}
}
})
body = { 'requests': requests }
response = self.service.spreadsheets().batchUpdate(spreadsheetId=SPREADSHEET_ID, body=body).execute()
3. 定義したClassを元に、前項1.のSpreadSheet ID(str)を引数にしてインスタンスを作成します
※SpreadSheet IDはSpread SheetのURLの"/edit"の直前に英数字で記載されています
spreadsheet_id ='XXXXXXXXXXX' # SpreadSheet IDをstringで定義
range_name ="sample" # 抽出したいWorksheet名を定義
test_ss = SpreadSheetsApi(SPREADSHEET_ID = spreadsheet_id, RANGE_NAME = range_name) # 当該のSpreadSheet/Worksheetの値を抽出するインスタンスを作成
このインスタンスを作成すると同時に、Spread Sheetから対象シートの値が抽出されます
4. Python ListをPandas Dataframeに変換し、読み取った値を確認
このインスタンスを作成すると同時に、SpreadSheetから全シートのElement(タイトル/本文/テーブル等)のリストが抽出されます。
今回の例だと、test_ss.valuesに抽出した値は格納されています。
import pandas as pd
# Pandas Dataframeに値のテーブルを変換
df = pd.DataFrame(test_ss.values,columns=['A','B','C','D','E'])
df.index = df.index + 1
 Spread Sheetと同じ内容が記載されていますね
Spread Sheetと同じ内容が記載されていますね
5. メソッドを使用して以下の値でSpread Sheetを書き換える
下記のexample_valueを今回の表に反映しようと思います。
example_value = [["A1","B1"],["A2","B2"]] #書き換える値
test_ss.write_values(SPREADSHEET_ID = spreadsheet_id, RANGE_NAME = range_name,value_list =example_value) #書き換えるためのメソッド
なお、Sheets APIでは2階層の多重リストでSheetの行列を表します。
1階層目のリストの並びがSheetの行を示し、2階層目のリストの並びが列になります。
**6. 書き変えた値が反映されているかを確認する
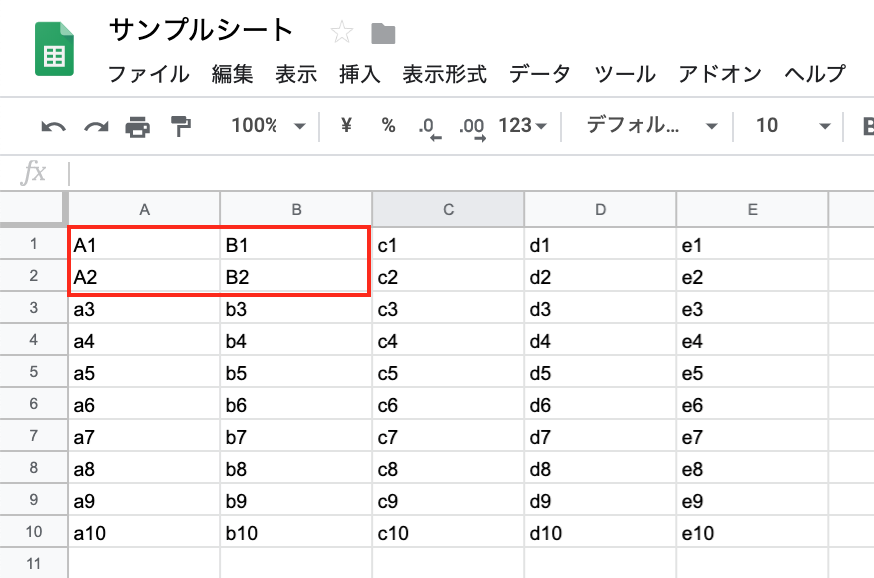
きっちり、1-2行目のA-B列だけ指定の値に書き換わっていますね。
7.フォーマットを書き換える
次に以下のコードで、値だけでなくフォーマットも書き換えてみましょう。
test_ss.change_format(sheet_num=0, SPREADSHEET_ID = spreadsheet_id, value_list=test_ss.values) #フォーマットの書き換え用メソッド
value_listを引数にとっているのは、フォーマット編集対象の行列数を読み込ませるためです。
8. 書き換えたフォーマットが反映されているかを確認する
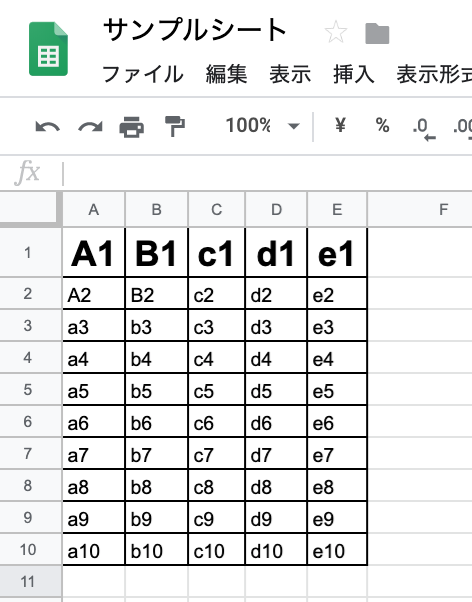
値が入っているところのみフォーマットが変更されていますね。
今回は罫線をリスト全体にかけ、1行目の文字を大きくBoldにしました。
お好みのフォーマットにしたい方はGoogle Sheets APIのReferenceを参考にrequest内容を書き換えてみてください。