こんにちは。
今回はOpenAIのモデル以外も触ってみようと思い、Azure AI Foundryのgrok-3で sql の動作を確認してみたので、メモを残しておきます。
ブログを読んでいる方でも試せるように、データベースはsqlite3のチュートリアルで公開されているデータベースを使用します。
Azure側の準備
AzureのポータルからAzure AI Foundaryを作成します。
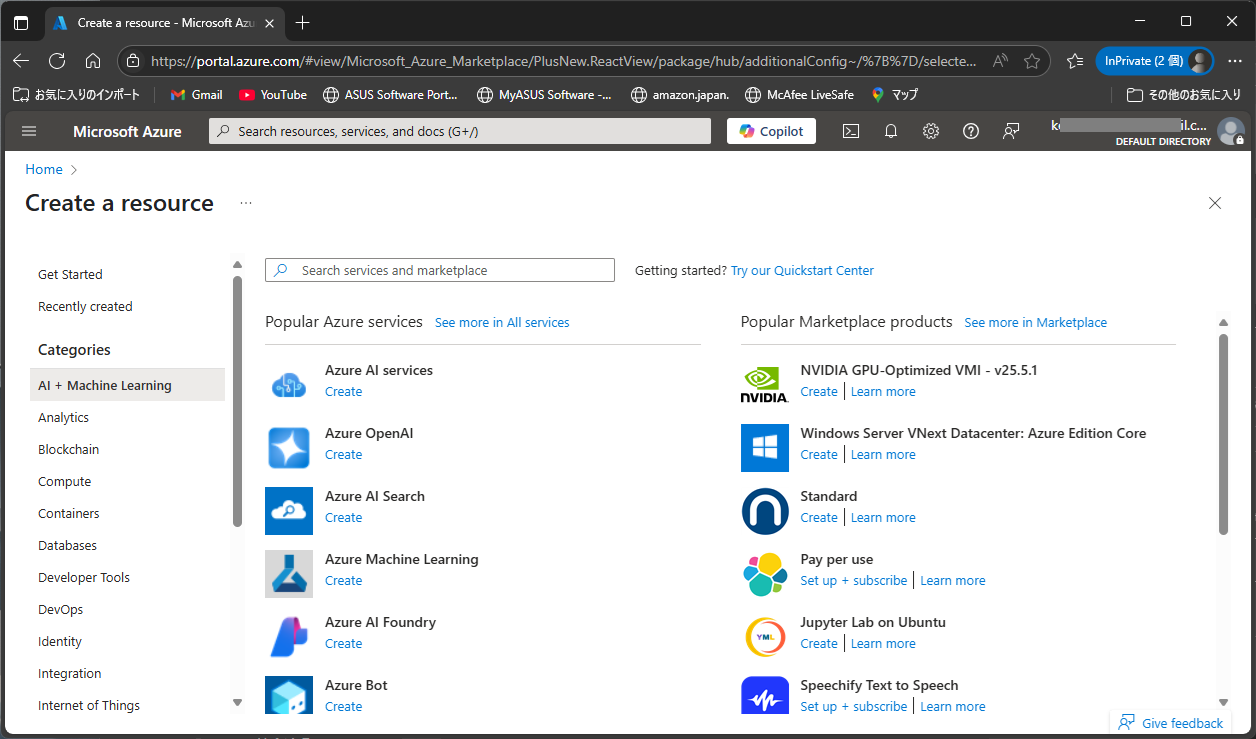
リソースの名前やプロジェクト名を設定して作成します。
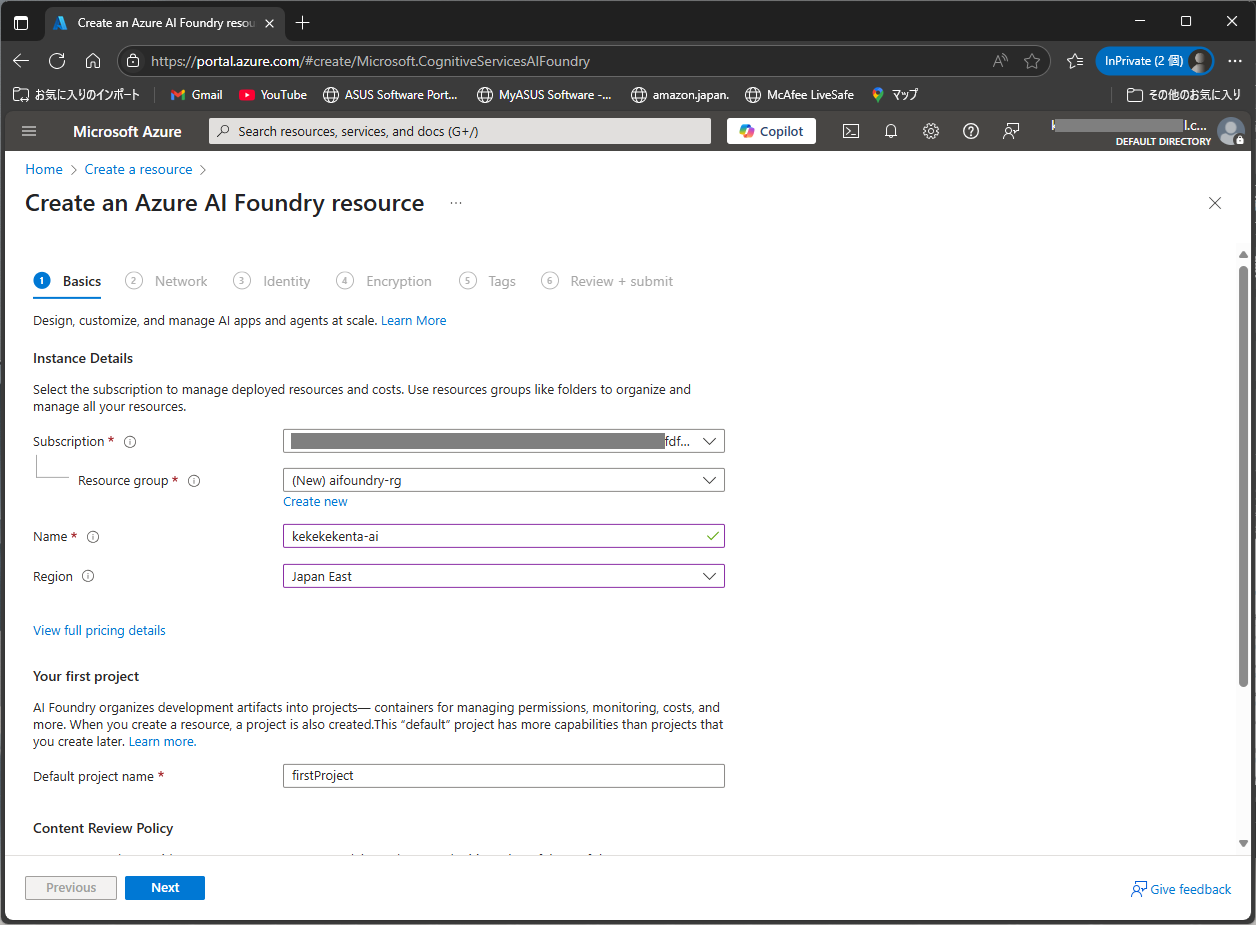
リソースが作成されたら、Azure AI Foundary portalに移動します。移動したらモデルカタログから試したいモデルを選択します。今回はgrok-3を使いますが、好きなモデルをデプロイしてください。
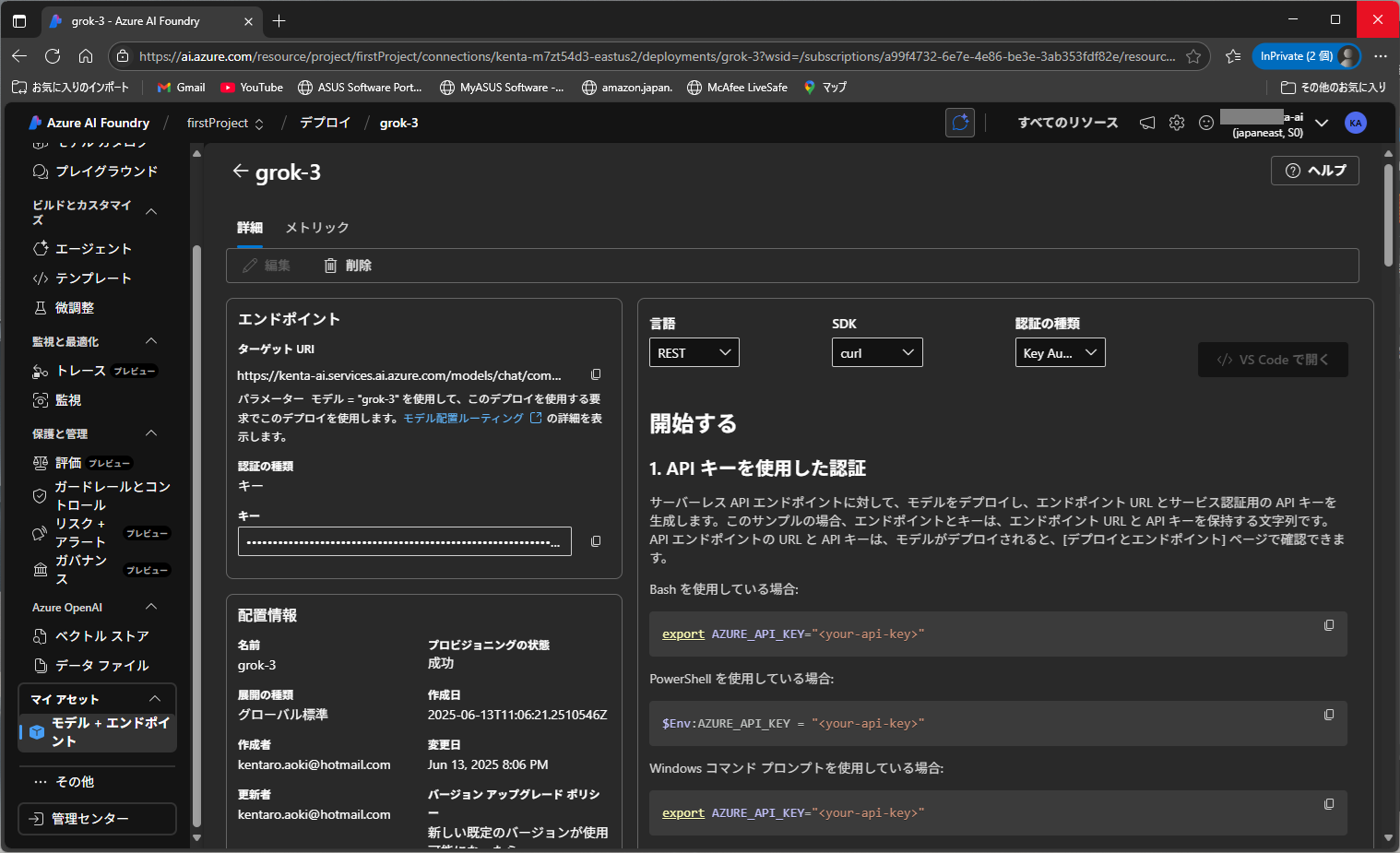
デプロイが完了したら、マイアセットからエンドポイントとキーを取得しておきます。
Python環境の準備
Pyhtonが動作するLinux環境を用意してください。私は、Windows 11 の wsl2 の Ubuntu 24.04 コンテナに miniconda python 3.13.2 をインストールしています。
今回は、以前の記事で紹介した実験的なコードを使っていきます
まず、githubから今回使用するコードを取得して、モデルのエンドポイントを設定してください。
git clone --recursive https://github.com/KentaroAOKI/python_code_interpreter.git
cd python_code_interpreter
pip install -r requirements.txt
cp .env.sample .env
vi .env
Azure側の準備で取得したエンドポイントとキーを設定してください。Open AI推論エンドポイントを使用してgrok-3を使用します。
DEPLOYMENT_NAME='grok-3'
# Azure OpenAI
# If your environment is Azure OpenAI, set the following
AZURE_OPENAI_API_KEY='<your azure openai key>'
AZURE_OPENAI_ENDPOINT='https://<your endpoint>.openai.azure.com/'
OPENAI_API_VERSION='2025-01-01-preview'
次に、sqlite3のチュートリアルからデータベースをダウンロードします。
cd sample_data
wget wget https://www.sqlitetutorial.net/wp-content/uploads/2018/03/chinook.zip
unzip chinook.zip
cd ..
sqlite3のデータベースのデータを調べてみる
チュートリアルのsqlite3データベースから、最も多くのトラックを持つアルバムの名前を調べてみます。python_code_interpreter.py のメッセージを以下に変更します。
message = "./sample_data/chinook.db のsqlite3データベースから、最も多くのトラックを持つアルバムの名前を調べてください。"
実行します。
python python_code_interpreter.py
追加の質問があれば、実行の途中で入力してください。終了するときはexitと入力します。
grok-3の結果をこちらに置いておきました。
アルバムごとのトラック数をカウントして2番目にトラック数が多いアルバムを取得するクエリも書いてくれます。
query = '''
SELECT a.Title, COUNT(t.TrackId) as TrackCount
FROM albums a
JOIN tracks t ON a.AlbumId = t.AlbumId
GROUP BY a.AlbumId, a.Title
ORDER BY TrackCount DESC
LIMIT 1 OFFSET 1
'''
グラフも書いてくれますね。
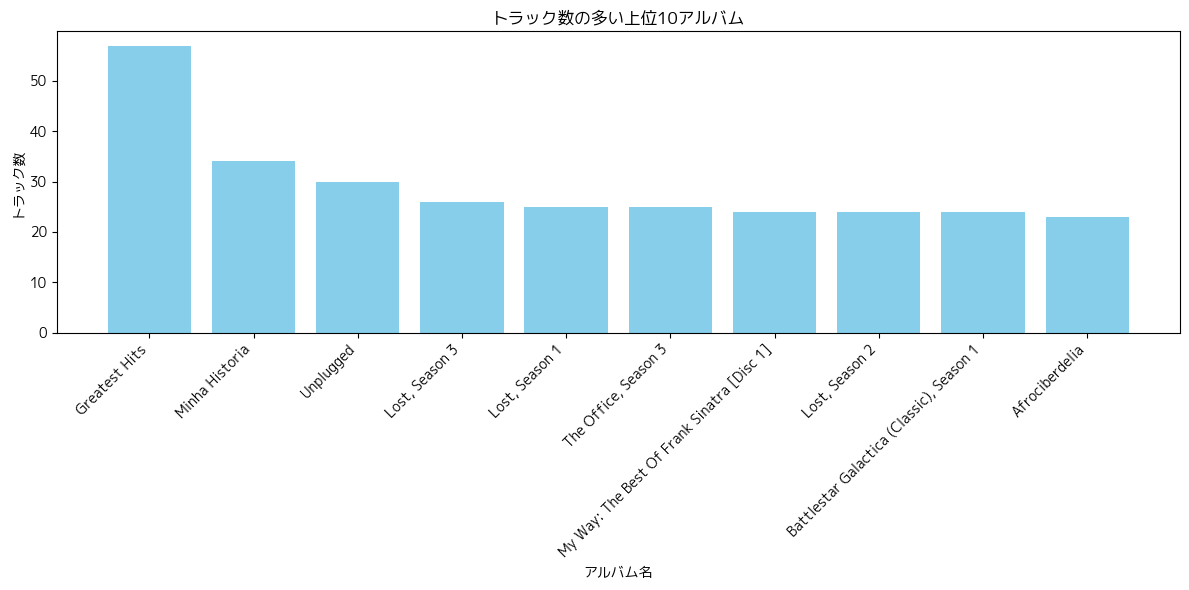
ついでに、gpt-4.1の結果も置いておきます。
エラーが出た後に、テーブルの一覧を取得してやり直すところとかいいですねー。
import sqlite3
db_path = './sample_data/chinook.db'
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# テーブル一覧取得
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
cursor.close()
conn.close()
tables
データベースには「albums」「tracks」などのテーブルが存在しています。
先ほどのクエリで使った「Album」「Track」は正しくは「albums」「tracks」と小文字になっています。
これを踏まえて、最も多くのトラックを持つアルバム名を調べます。
ついでに、o4-miniの結果も置いておきます。
o4-miniは、依頼に忠実ですね。
実行するたびに結果に辿り着く手法が違うので、何度も試してみると面白いと思います。また、モデルごとの特徴も見えてきますね。
さいごに
grok-3いいですね。人間がわかりやすいような結果を返してきてくれます。今回は有名なチュートリアルだったため、データベースの構造を確認せずSQLを作成していましたが、エラーになったときはどのような動作をするのか気になるところです。
(gpt-4.1やo4-miniなどOpenAIのモデルは、エラー時にテーブルの構造を確認するので安心して使ってます)