はじめに
リアルタイム文字起こしに求めたいこと
ローカルで推論できる高速な文字起こしモデルとして「faster-whisper」などがありますが、リアルタイムに音声を推論して文字起こしするには、適切にひとまとまりの音声を区切って音声認識をかけるため「Voice Activity Detection」=VADの工夫が重要です。
以下に理想のリアルタイム音声認識の図を示します。
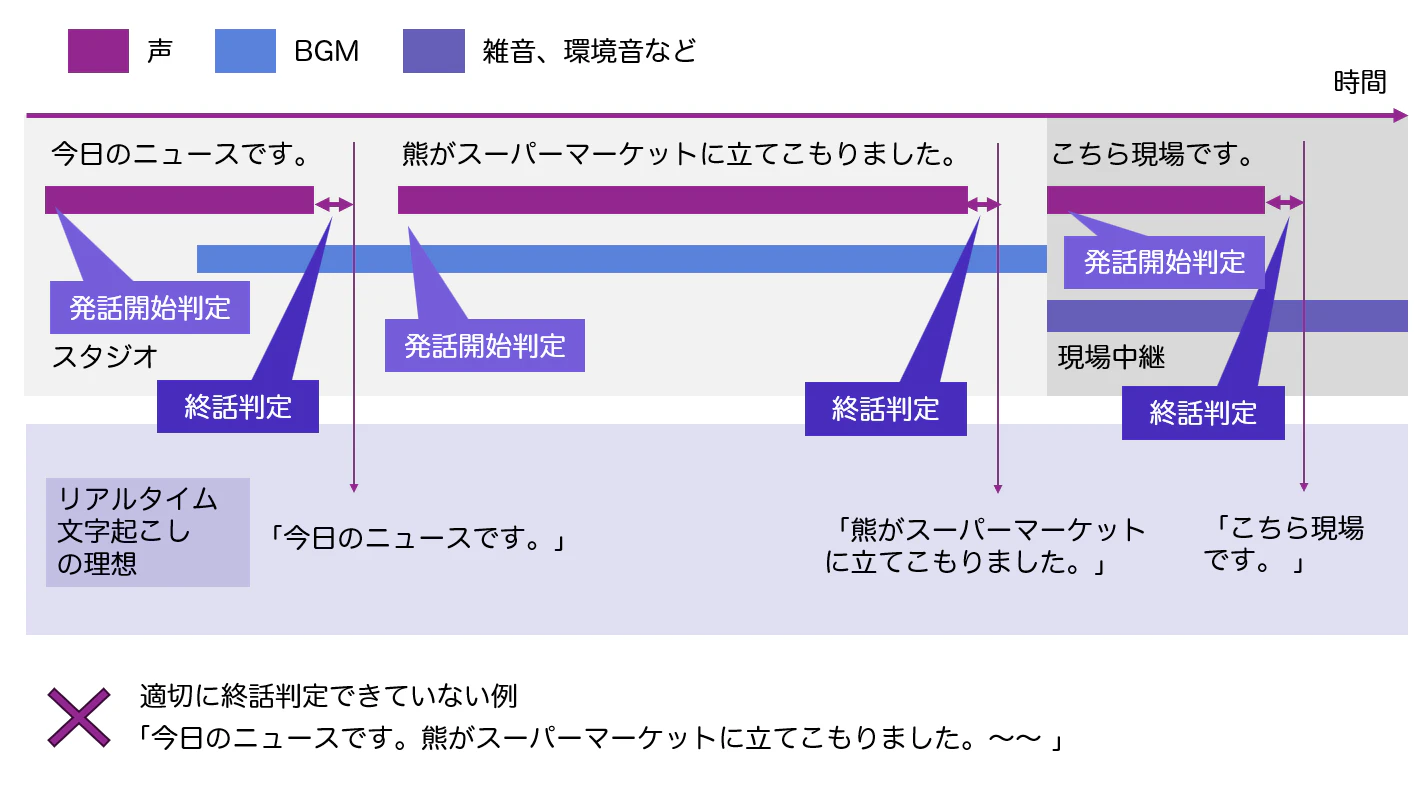
実際にTV番組やアニメ、ドラマなどでリアルタイム文字起こしのシーンを考えると、BGMや雑音、効果音などの声とは別の要素が多く入っている音声がほとんどです。
この記事では、このような音声を入力とし、適切に音声を区切ってリアルタイムに音声認識にかけることができるのか実験してみました。すでにさまざまなVADモデルが開発されており、ライブラリ経由で簡単に使うことができました。
実験内容
利用したVADモデル
-
py-webrtcvad
- https://github.com/wiseman/py-webrtcvad
- Pythonで使える最もシンプルなVADモデルで非常に高速に推定できますが、ある程度の音量があれば、BGMや雑音などの声以外にも反応してしまうようです。
-
YAMNet
- https://www.tensorflow.org/hub/tutorials/yamnet?hl=ja
- 音声セグメントを多クラス分類する高速推論可能なモデル。これ単体では音声分類タスクのモデルのためVAD用途ではありませんが、「声」関連のクラスのスコア使うことでVADとして機能させることができます。
-
SileroVAD
- https://github.com/snakers4/silero-vad
- こちらも高速に推論が可能なモデル。音声セグメントに含まれる音が「声かどうか」の判定に優れています。
実験環境
以下のPC環境を使い実験しました。
| 項目 | 詳細 |
|---|---|
| OS | Windows 11 24H2 |
| RAM | 64GB |
| CPU | AMD Ryzen 7 5700X |
| GPU | NVIDIA GeForce RTX 3090(VRAM 24GB) |
| Python | 3.10.8 |
| CUDA | 11.6 |
実装
音声バッファ、WebSocketアプリの基本実装は以下の記事を参考にさせていただきました。
実装概要
全体の構造と条件
-
リアルタイム音声処理
- WebSocket経由で音声データを受信し、リアルタイムで処理する
- 音声データはPCM形式(16-bit signed integers)で受信される
- サンプルレートはWebSocket接続時に指定され、音声セグメント受信後内部的に16kHzにリサンプリングされる
-
使用するVADモデルの選択
-
"YAMNet","SileroVad","webrtcvad"のいずれかを選択可能
-
-
音声バッファの管理
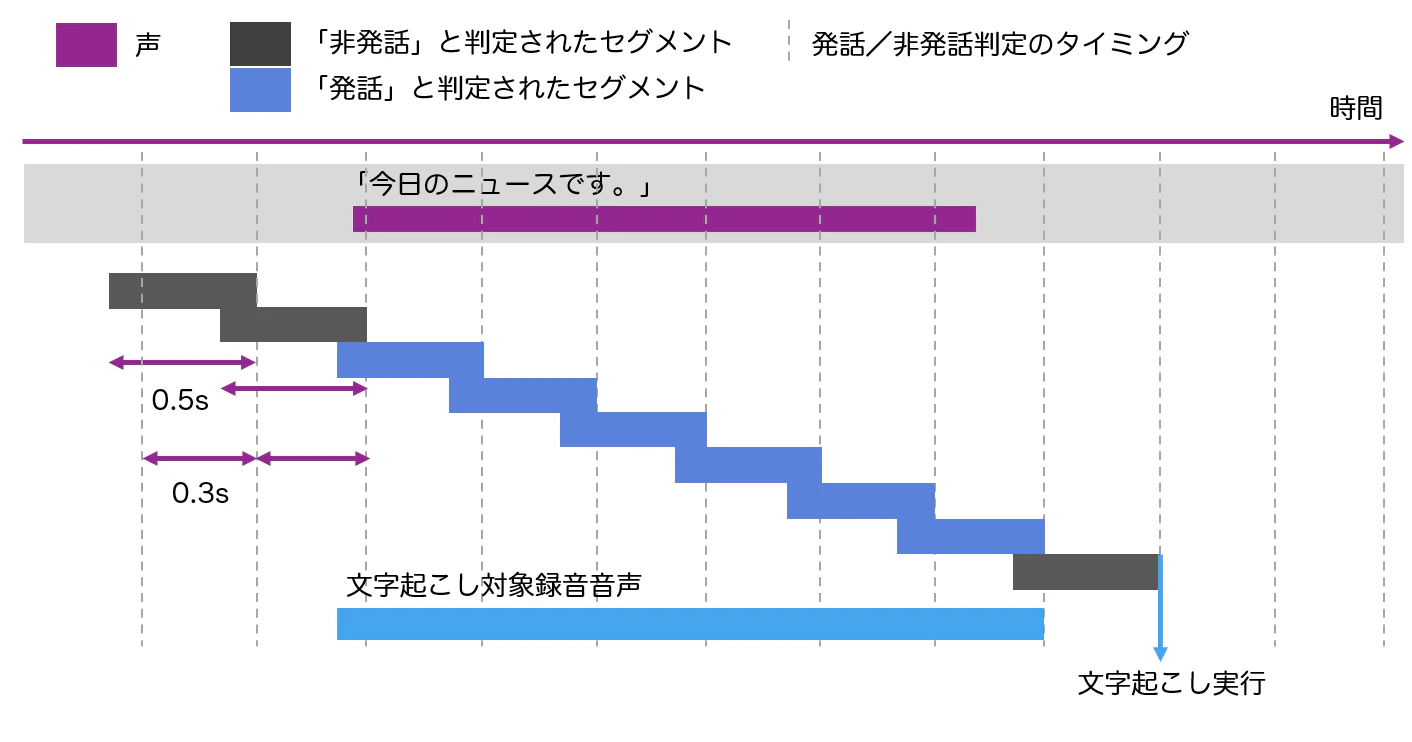
- 処理対象のバッファ長は0.5秒(デフォルト)
- 音声セグメントの発話/非発話の判定は0.3秒ごとに行い、バッファのうち最新の0.3秒のデータを利用
-
文字起こしの実行条件
- 非録音状態で発話を検知すると録音を開始
- そのとき、話始めの音声の取りこぼしを防ぐためバッファ全体を初期セグメントとして格納
- 非発話セグメントが検出されたらそこまでに録音された音声を文字起こしし、バッファをリセット
- 文字起こしは非同期で行い、コマンドライン上に文字起こしした結果を随時出力する。
-
文字起こしモデル (faster-whisper)
- Faster Whisperを使用。
- 録音音声を
float32形式の波形データに変換 - 言語は日本語(
language="ja") - faster-whisper内蔵のVADフィルタ(SileroVAD)は無効
発話検出、終話検出、文字起こしまでのイメージ
特にYAMNetの推論に時間がかかるため、今回はVADモデルにかかわらず音声バッファを0.5秒、発話/非発話判定のタイミングを0.3秒に統一しました。また、「非発話」と判定されたセグメント数ロジックや、これらの時間パラメータを調整することで、さらに終話検出をより高速・高精度に行えると思います。
VADモデルごとの発話/非発話判定条件
-
py-webrtcvad:音声セグメントをwebrtcvadに入力可能なフレーム(0.03, 0.02, 0.01秒のいずれかから選択)にさらに区切り推論し、1つでも「発話判定」が得られたら発話と判定する
-
YAMNet:声に関連するクラスの推定スコアの合計が0.1を上回ったら発話と判定する
- 今回は、事前の実験で声に対して多く出ていた"Speech", "Speech synthesizer", "Narration, monologue"の3種類のクラスを対象とした
-
SileroVAD:音声セグメントに対してget_speech_timestamps()を実行し、一つでも発話区間が検出されたら発話と判定する
文字起こしの表示について
文字起こしが行われたタイミングでその結果が一行でprintされますが、発話/非発話判定の精度により、複数文章の音声が一度に入力されてしまうことがあります。(なるべく避けたい要素)
これを可視化するため、faster-whisperによって複数の文章が出てきた場合は間に「→」の文字を出すことにしました。
ソースコード
import asyncio
import websockets
import csv
import numpy as np
from datetime import datetime
import json
from scipy.signal import resample
# YAMNetVad
import tensorflow as tf
import tensorflow_hub as hub
# py-webrtcvad
import webrtcvad
# SileroVad
from silero_vad import load_silero_vad, read_audio, get_speech_timestamps
import torch
# Whisper
from faster_whisper import WhisperModel
model = WhisperModel("medium", device="cuda", compute_type="float32")
class AudioBuffer:
def __init__(self, source_sample_rate, target_sample_rate):
self.source_sample_rate = source_sample_rate
self.target_sample_rate = target_sample_rate
self.audio_buffer = bytearray()
self.buffer_duration = 0.5 # バッファ長さ(s)
self.audio_data_for_transcrible = bytearray()
self.current_is_speech = False
self.recording = False
self.no_speech_count = 0
self.last_check_time = datetime.now()
self.no_speech_limit = 1
self.target_duration = 0.3 # 発話推論対象長さ(<= buffer_duration)
self.use_vad = "YAMNet" # ["YAMNet", "SileroVad", "webrtcvad"] から選択
# ===== 各VADモデルの定義 =====
# YAMNet
self.yamnet = hub.load('https://tfhub.dev/google/yamnet/1')
self.classes_speech_yamnet = ["Speech", "Speech synthesizer", "Narration, monologue"]
# webrtcvad
self.webrtcvad = webrtcvad.Vad(0)
self.frame_duration = 0.03 # フレームの長さ(0.03, 0.02, 0.01から選択)
self.frame_size = int(self.target_sample_rate * 2 * self.frame_duration)
# SileroVad
self.silerovad = load_silero_vad()
def class_names_from_csv(class_map_csv_text):
"""YAMNetクラス名一覧取得"""
class_names = []
with tf.io.gfile.GFile(class_map_csv_text) as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
class_names.append(row['display_name'])
return class_names
class_map_path = self.yamnet.class_map_path().numpy()
self.class_names = class_names_from_csv(class_map_path)
def add_data(self, data):
# リサンプリング
if self.source_sample_rate != self.target_sample_rate:
data = self.resample_audio(data, self.target_sample_rate)
self.audio_buffer.extend(data)
# バッファは常に最新のバッファ長さ分を格納
if len(self.audio_buffer) > int(self.target_sample_rate * self.buffer_duration * 2):
self.audio_buffer = self.audio_buffer[-int(self.target_sample_rate * self.buffer_duration * 2):]
if self.recording:
self.audio_data_for_transcrible.extend(data)
t = datetime.now()
if (t - self.last_check_time).total_seconds() >= 0.3:
# バッファから対象長さの音声を切り出しYamNetを推論
self.last_check_time = t
if len(self.audio_buffer) > int(self.target_sample_rate * self.target_duration * 2):
target_buffer = self.audio_buffer[-int(self.target_sample_rate * self.target_duration * 2):]
if self.use_vad == "YAMNet":
wav = np.frombuffer(target_buffer, dtype=np.int16)
waveform = wav / tf.int16.max
scores, embeddings, spectrogram = self.yamnet(waveform)
scores_np = scores.numpy()
class_scores = {cls: sc for cls, sc in zip(self.class_names, scores_np.mean(axis=0))}
score_speech = 0.0
for cls in self.classes_speech_yamnet:
score_speech += class_scores[cls]
self.current_is_speech = score_speech > 0.1
elif self.use_vad == "SileroVad":
wav = np.frombuffer(target_buffer, dtype=np.int16).astype(np.float32) / 32768.0
speech_timestamps = get_speech_timestamps(
torch.tensor(wav),
self.silerovad,
return_seconds=True,
)
self.current_is_speech = len(speech_timestamps) > 0
elif self.use_vad == "webrtcvad":
is_speech = False
for i in range(0, len(data) - self.frame_size + 1, self.frame_size):
frame = data[i:i + self.frame_size]
if len(frame) == self.frame_size:
if self.webrtcvad.is_speech(frame, self.target_sample_rate):
is_speech = True
break
self.current_is_speech = is_speech
if not self.recording and self.current_is_speech:
self.recording = True
self.audio_data_for_transcrible = self.audio_buffer
if not self.current_is_speech:
self.no_speech_count += 1
else:
self.no_speech_count = 0
def reset(self):
self.no_speech_count = 0
self.recording = False
self.audio_data_for_transcrible = bytearray()
return
def resample_audio(self, data, target_sample_rate):
"""音声データを指定されたサンプルレートにリサンプリング"""
# PCMデータをfloatに変換
pcm_data = np.frombuffer(data, dtype=np.int16).astype(np.float32) / 32768.0
duration = len(pcm_data) / self.source_sample_rate
target_length = int(duration * target_sample_rate)
resampled_data = resample(pcm_data, target_length)
resampled_pcm = np.int16(resampled_data * 32768)
return resampled_pcm.tobytes()
async def audio_handler(websocket):
print("WebSocket connection established, starting real-time transcription.")
audio_buffer = None
try:
while True:
data = await websocket.recv()
if isinstance(data, str):
message = json.loads(data)
if 'sampleRate' in message:
sample_rate = message['sampleRate']
audio_buffer = AudioBuffer(source_sample_rate=sample_rate, target_sample_rate=16000)
print(f"Sample rate received: {sample_rate} -> 16000 Hz")
elif isinstance(data, bytes):
if audio_buffer:
audio_buffer.add_data(data)
if audio_buffer.recording and audio_buffer.no_speech_count == audio_buffer.no_speech_limit:
await transcribe_audio(audio_buffer)
audio_buffer.reset()
else:
print("Audio buffer not initialized yet.")
except websockets.ConnectionClosed:
print("WebSocket connection closed")
if audio_buffer and len(audio_buffer.audio_data) > 0:
# 残りのデータを文字起こし
await transcribe_audio(audio_buffer)
pass
async def transcribe_audio(audio_buffer):
# PCMデータをfloatに変換
pcm_data = np.frombuffer(audio_buffer.audio_data_for_transcrible, dtype=np.int16).astype(np.float32) / 32768.0
# 文字起こしを実行
segments, info = model.transcribe(
pcm_data,
language="ja",
vad_filter=False,
beam_size=5,
best_of=5
)
# 結果を出力
print("→".join([segment.text for segment in segments]))
async def main():
async with websockets.serve(audio_handler, "localhost", 5000):
print("WebSocket server started on ws://localhost:5000")
await asyncio.Future()
if __name__ == "__main__":
try:
asyncio.run(main())
except KeyboardInterrupt:
exit(0)
実験結果
- 今回はオーディオミキサー「MG12XU」を使い、PC音声をその場でループバックさせることで文字起こしをさせています。
- OSのステレオミキサーや仮想マイクのソフトウェアでも可能です。
雑音が小さいシーン
以下のニュース特集の冒頭一部分を使って実験させていただきました。
TVer TBS NEWS DIG Powered by JNN「クリスマス最新おもちゃ調査【Nスタ】」より
BGMがないため文字起こししやすいと比較的思われる音声ですが、街頭で雑音を含むインタビューシーンがありました。
実際の出力結果
YAMNetベースのVAD
今日、都内のおもちゃ屋さんに行くと
クリスマスの雰囲気
ほんと鬼に素敵ですね
あ、おもちゃがたくさん置かれています。
たくさんのおもちゃ 担当者に今年の人気商品を教えてもらいました
こちらが今人気のジップストリングです。
世界50カ国以上で今ブームとなっている
ブーストリングです
長方形の箱に
長いロープがついています。
・・・(略)
- 本来一つの文章にしてほしいところが別のセグメントに分かれたり、複数の文章がまとまってしまうことがちらほらありましたが、認識された文章はかなり正確です。
- 終話検出もできており、文章ごとに話し終わったタイミングでリアルタイムに文字起こしできました。
SileroVAD
おもちゃ屋さん
会社屋さんに行くと。
こちらクリスマスターズです。
クリスマスの
本当に素敵ですね
いいですね
おもちゃが
3を借りています
今年の人気商品を教えてもらいました
こちらが今人気のジップストリングです
・・・(略)
今回の設定では取りこぼしが多く、ぶつぶつとセグメントが切れてしまいました。その結果間違った変換も多く、終話判定を伸ばすロジックの改善が必要そうです。
Webrtcvad
最後まで視聴してくださって 本当にありがとうございます
今日、都内のおもちゃ屋さんに行くと→こちらクリスマスの雰囲気、本当に素敵ですね→あ、おもちゃがたくさん置かれています→たくさんのおもちゃ→担当者に今年の人気商品を教えてもらいました
こちらが今人気のジップストリングです→・・・(略)
- 声以外の雑音も発話判定とみなしてしまい、冒頭に存在しない文言が文字起こしされたり、その後の文章がすべてひとまとまりになってしまいました。
- BGMや雑音を含むシチュエーションでのリアルタイム文字起こしにはあまり効果がないように見えました。(結局すべて録音が完了した後に文字起こしをしているのと同等になってしまった)
- Webrtcvadが有効なシーンとしては、発話している時間以外は雑音がなく、文章ごとに長い無音があるような音声については使えると思います。
考察
YAMNetを使ったオリジナルのVADロジックがかなり単純にもかかわらず、リアルタイムの文字起こしに効果的であることが分かりました。
以降、YAMNetを使ったオリジナルのVADの出力結果を紹介します。
BGM、効果音・雑音が混じるシーン
特にバラエティー番組、アニメやドラマは複数の登場人物の発話が次々入れ替わったり、効果音やBGMなど、リアルタイム文字起こしには難しい音が混じっていることが多いと思います。BGMや効果音が混じっていても終話検出を正しく行い、一つの文章を話し終わったときにその都度文字起こしできることが理想です。
TVer 名探偵コナン #1144「ホテル連続爆破事件(前編)」より
YAMNetを使った文字起こし結果
ラッキー!
絶版になってる掘り出し物の
私物の推理小説が3冊も買えた!
はっはっは
わざわざ遠出してこの本屋さんまで来て 正解だったなぁ
でもなんでこんな本屋さんに来たんだっけ?
そうだ、確かランが
コナンくんって本好きだよね?
なんで?
だったら、ハイド町まで行けばいい本屋さんがあるらしいよ
ほんと?
・・・(略)
考察
ほかにもいくつかBGMのある音声で試してみましたが、登場人物ごと・一つの文章ごとに区切ってリアルタイムに音声認識できた例が多く、実用性がありそうな印象でした。
さいごに
今回は、気軽に使えるVADモデルを使ってリアルタイムに文字起こしができるかを実験しました。
特にYAMNetを使うと、声とそれ以外の音(BGM、効果音、環境音など)を判定しやすいため、いろいろな音が混じる状況下でもリアルタイムの文字起こしに使えそうです。
参考文献
- 音声認識モデルfaster-whisper+gpu(a10)でリアルタイム文字起こしにトライ
- py-webrtcvad
- YAMNet
- SileroVAD