はじめに

音声のリアルタイム文字起こしは、さまざまな業界でニーズが高まっており、特に効率的かつ高精度な処理が求められています。
昨今、音声入力を元に多様なサービスが展開されています。たとえば、
- ビジネスミーティングでは、音声をリアルタイムでテキスト化し、自動で議事録を作成するケースが増えています
- また、カスタマーサポート分野では、顧客とオペレーターの通話内容をリアルタイムで解析し、オペレーターが効率的に対応できるよう支援するユースケースも広がっています
faster-whisperは、Whisperモデルをベースにした軽量かつ高速な音声認識ライブラリです。Whisperの持つ高精度な音声認識能力を保持しつつ、最適化によって速度を大幅に向上させている点が特徴です。特にGPUを活用したリアルタイムの音声処理に強みがあり、エッジデバイスやクラウド環境でも効率的に動作します。
small、medium、large-v3など複数のモデルを提供しており、精度と速度のトレードオフがあります。たとえば、
- smallモデルは低リソース環境でも動作しますが、長い文脈を持つ複雑な会話では精度が劣る可能性があります
- 一方、large-v2やlarge-v3はその高精度さで複雑な会話やノイズが多い環境下でも信頼性の高い結果を提供しますが、より高いGPUリソースを必要とします
この記事では、A10 GPU環境で最上位のlarge-v3モデルをホスティングし、PCマイクからリアルタイムに音声を送信⇒GPUサーバ側で受信してリアルタイム文字起こしを行う方法について解説します。
OCI上でVM A10の構築
OCI上でA10 GPU搭載の仮想マシンを構築する手順について説明していきます。まずはVMインスタンスからVM.GPU.A10.1を選択します(選択できない場合は事前にサービス制限引き上げリクエストを出しておきます)
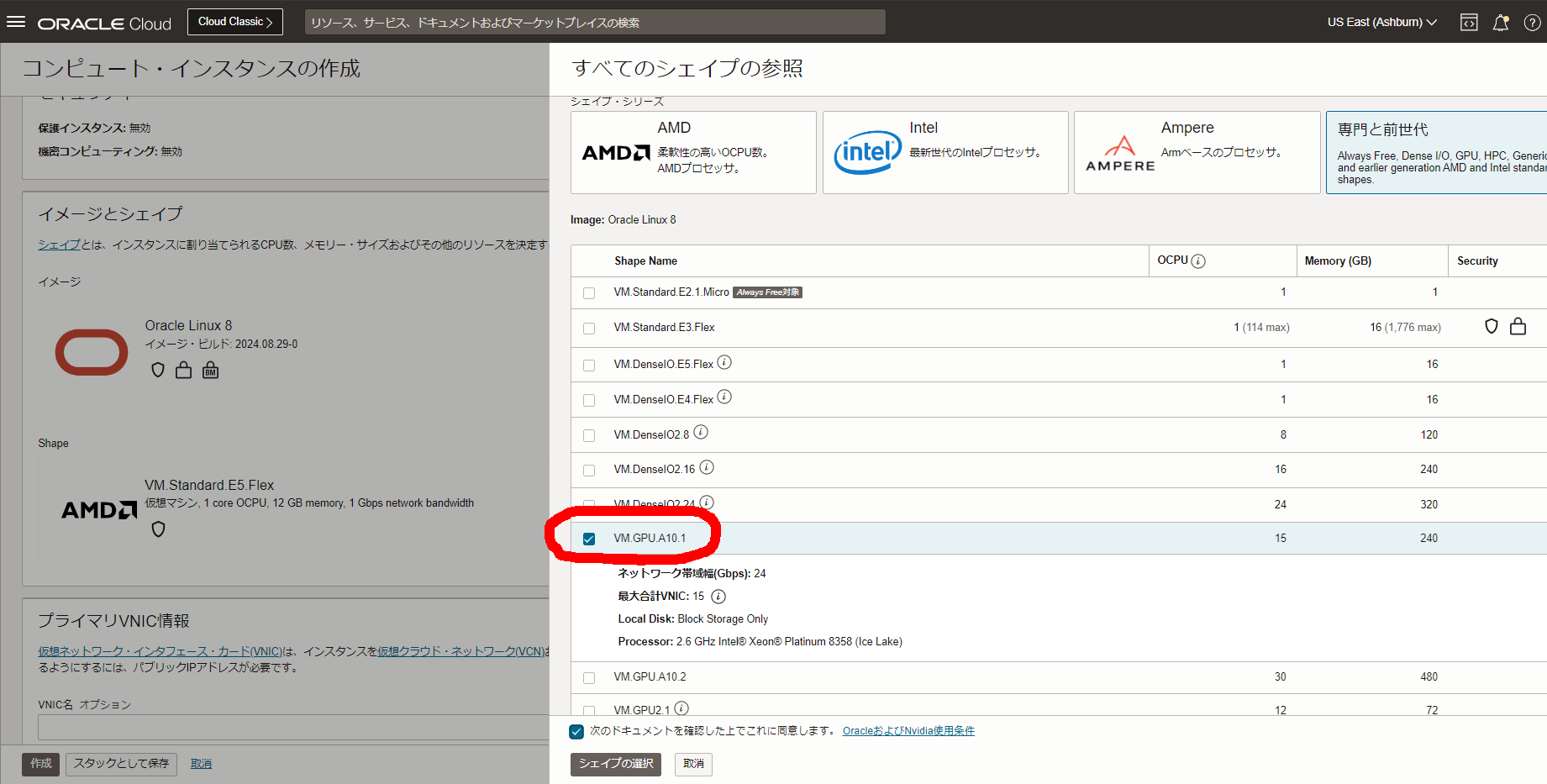
イメージはマーケットプレイスからnvidiaで検索し、NVIDIA GPU-Optimized VMI(無料)を選択します。
選択するとこのようになります。
事前に作成済みのVCNサブネット、および既存公開鍵を設定(or新規にDL)してインスタンスを作成します。
1,2分で作成完了し実行中となります。
ログイン後、nvidia-smiを実行します。
ubuntu@gputest-instance-20240926-1914:~$ nvidia-smi
Thu Sep 26 10:27:30 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A10 On | 00000000:00:04.0 Off | 0 |
| 0% 35C P0 54W / 150W | 0MiB / 23028MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
ubuntu@gputest-instance-20240926-1914:~$
各種ライブラリのインストール
今回のデモで必要となる下記ライブラリ群をインストールしていきます:
- CUDA Toolkit 12.6
- cuDNN 8
CUDA Toolkit
NVIDIAページからインストールします。
下記ページで示されるコマンドを順に実行していきます。
cuDNN 8
faster whisperが8を使用するため(こちらの環境起因かもしれませんが)、下記コマンドでバージョン8をインストールします。
※またはNVIDIAのアーカイブページから上記と同様にインストールでもOKです
sudo apt install libcudnn8*
Python各種モジュール
pythonは3.10がデフォルトで入っているため、ここからvenv環境で下記pipを実行して入れてきます。
python3 -m venv venv
source venv/bin/activate
pip install scipy webrtcvad websockets faster_whisper
ポート穴あけ
サンプルで5000番ポートを使うため、VCNのセキュリティリストにANYからの疎通を許可しておきます。
また、下記コマンドによりVMのファイアウォール設定を穴あけします
※rebootのたびにリセットされますので必要であれば別途永続化をしてください
sudo iptables -I INPUT -p tcp --dport 5000 -j ACCEPT
【クライアント側】Websocketで音声データを送信
ブラウザのAPIを使ってPCのマイクから音声データを取得し、それをWebSocketを通じて先ほどのGPUサーバーに送信します。GUIは簡素なテストHTMLです。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Real-Time Audio Stream to Server</title>
</head>
<body>
<h1>Real-Time Audio Stream to Server</h1>
<button id="start">Start Recording</button>
<button id="stop">Stop Recording</button>
<script>
let audioContext;
let processor;
let ws;
let isRecording = false;
let sampleRate;
document.getElementById("start").addEventListener("click", async () => {
try {
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
audioContext = new (window.AudioContext || window.webkitAudioContext)();
sampleRate = audioContext.sampleRate;
const input = audioContext.createMediaStreamSource(stream);
processor = audioContext.createScriptProcessor(4096, 1, 1);
input.connect(processor);
processor.connect(audioContext.destination);
ws = new WebSocket("ws://(your_gpu_global_IP):5000/audio");
ws.onopen = () => {
console.log("WebSocket is open");
ws.send(JSON.stringify({ sampleRate: sampleRate }));
};
ws.onclose = () => {
console.log("WebSocket is closed");
};
processor.onaudioprocess = function (e) {
if (!isRecording) return;
const inputData = e.inputBuffer.getChannelData(0);
const pcmData = floatTo16BitPCM(inputData);
if (ws && ws.readyState === WebSocket.OPEN) {
ws.send(pcmData);
}
};
isRecording = true;
console.log("Recording started");
} catch (err) {
console.error("Error accessing microphone:", err);
}
});
document.getElementById("stop").addEventListener("click", () => {
isRecording = false;
if (processor) {
processor.disconnect();
}
if (audioContext) {
audioContext.close();
}
if (ws && ws.readyState === WebSocket.OPEN) {
ws.close();
}
console.log("Recording stopped");
});
function floatTo16BitPCM(input) {
const output = new DataView(new ArrayBuffer(input.length * 2));
for (let i = 0; i < input.length; i++) {
let s = Math.max(-1, Math.min(1, input[i]));
output.setInt16(i * 2, s < 0 ? s * 0x8000 : s * 0x7FFF, true);
}
return output.buffer;
}
</script>
</body>
</html>
【サーバ側】リアルタイム文字起こし
WebSocketを通じて送信された音声データを元に、faster-whisperを使ってリアルタイム文字起こしを行い、その結果を確認します。5000番ポートで先ほどのwebsocket音声データを受け付け、無音期間を検出したタイミングで文字起こし結果を都度出力していきます。
import asyncio
import websockets
import io
from faster_whisper import WhisperModel
import numpy as np
import json
from scipy.signal import resample
import webrtcvad
# Whisperモデルのロード
model = WhisperModel("large-v3", device="cuda", compute_type="float32")
class AudioBuffer:
def __init__(self, sample_rate):
self.sample_rate = sample_rate
self.audio_data = bytearray()
self.vad = webrtcvad.Vad(0) # 感度レベル(0〜3)
self.frame_duration = 30 # フレームの長さ(ms)
self.frame_size = int(self.sample_rate * 2 * self.frame_duration / 1000) # バイト数(16bitなので×2)
self.silence_duration = 0.0 # 無音期間(秒)
self.silence_limit = 0.3 # 無音と判定する秒数
self.is_speaking = False
def add_data(self, data):
self.audio_data.extend(data)
self.check_silence(data)
def get_audio(self):
return self.audio_data
def reset(self):
self.audio_data = bytearray()
self.silence_duration = 0.0
self.is_speaking = False
def check_silence(self, data):
is_speech = False
# フレームごとにVADを適用
for i in range(0, len(data) - self.frame_size + 1, self.frame_size):
frame = data[i:i + self.frame_size]
if len(frame) == self.frame_size:
if self.vad.is_speech(frame, self.sample_rate):
is_speech = True
break # 音声が検出されたらループを抜ける
if not is_speech:
# 無音期間を増加
duration = len(data) / (self.sample_rate * 2) # 秒に変換
self.silence_duration += duration
if self.silence_duration >= self.silence_limit and self.is_speaking:
self.is_speaking = False
else:
# 音声が検出された場合
self.silence_duration = 0.0
self.is_speaking = True
async def audio_handler(websocket, path):
print("WebSocket connection established, starting real-time transcription.")
audio_buffer = None
try:
while True:
data = await websocket.recv()
if isinstance(data, str):
message = json.loads(data)
if 'sampleRate' in message:
sample_rate = message['sampleRate']
audio_buffer = AudioBuffer(sample_rate)
print(f"Sample rate received: {sample_rate} Hz")
elif isinstance(data, bytes):
if audio_buffer:
audio_buffer.add_data(data)
# 無音が一定期間続き、かつ話していた場合に文字起こしを行う
if not audio_buffer.is_speaking and len(audio_buffer.audio_data) > 0:
await transcribe_audio(audio_buffer)
audio_buffer.reset()
else:
print("Audio buffer not initialized yet.")
except websockets.ConnectionClosed:
print("WebSocket connection closed")
if audio_buffer and len(audio_buffer.audio_data) > 0:
# 残りのデータを文字起こし
await transcribe_audio(audio_buffer)
async def transcribe_audio(audio_buffer):
# PCMデータをfloatに変換
pcm_data = np.frombuffer(audio_buffer.get_audio(), dtype=np.int16).astype(np.float32) / 32768.0
# リサンプリング(必要であれば)
if audio_buffer.sample_rate != 16000:
duration = len(pcm_data) / audio_buffer.sample_rate
target_length = int(duration * 16000)
resampled_data = resample(pcm_data, target_length)
else:
resampled_data = pcm_data
# 音声エネルギーと音量の平均値を計算
energy, rms = calculate_audio_energy_and_rms(resampled_data)
# エネルギーが所定未満の場合、出力しない
if energy < 30:
# print(f"Audio Energy: {energy} is less than 1, skipping transcription.")
return
# 文字起こしを実行
segments, info = model.transcribe(
resampled_data,
language="ja",
vad_filter=True,
beam_size=5,
best_of=5
)
# 結果を出力
for segment in segments:
print(f"[{segment.start:.2f} - {segment.end:.2f}] {segment.text} AudioEnergy: {energy}")
# print(f"Audio Energy: {energy}, RMS (Volume): {rms}")
def calculate_audio_energy_and_rms(audio_data):
"""音声データのエネルギーとRMSを計算"""
energy = np.sum(audio_data ** 2) # エネルギーは振幅の二乗の総和
# rms = np.sqrt(np.mean(audio_data ** 2)) # RMSは二乗平均平方根
rms = 0
return energy, rms
# サーバーの開始
start_server = websockets.serve(audio_handler, "0.0.0.0", 5000)
# イベントループの実行
asyncio.get_event_loop().run_until_complete(start_server)
asyncio.get_event_loop().run_forever()
上のファイルを実行すると、指定したfaster whisperモデルが初回の場合、DLが開始されます。
python whisper.py
1点補足ですが、faster whisperを試している中で、「ご視聴ありがとうございました」等の誤検出をすることがあります。おそらく微小なノイズ等を出力してしまうため、音声データの振幅を計算して小さいものは除去するようにしています。
※値はマイク音量等によりますので適宜環境により設定が必要です
if energy < 30:
検証
最後にここまでで設定した内容で検証してみます。
自分のPCから下記文章を読んで、whisperのモデルを変えてみて出力された文字列の精度を見てみましょう。
ちなみに出力スピードですが、一番大きいlarge-v3でもサクサク出力されます。
あのー、予約の変更をお願いしたいんですけども、
診察券番号は123456789です。
名前は山田太郎で、携帯番号は090-1234-5678です。
今予約しているのが、10月1日(ついたち)の10時なんですけども、それをえーっと10月5日(いつか)14時に変更できますか?
あと後ほどですね、以前対応してもらった麻酔科とあと形成外科の担当の方から折り返し電話をいただきたいのでお願いします。
実施した結果です。
まずlarge-v3からです。ほぼ正確に出力できていて、フィラー除去もあります。
[0.00 - 2.94] 予約の変更をお願いしたいんですけども
[0.00 - 4.34] 診察券番号は123456789です。
[0.00 - 6.84] 名前は山田太郎で、携帯番号は090-12345678です。
[0.00 - 8.44] 今予約しているのが10月1日の10時なんですけども、それを10月5日14時に変更できますか?
[0.00 - 8.72] あと後ほどですね、以前対応してもらった麻酔科と、あと形成外科の担当の方から、折り返し電話をいただきたいのでお願いします。
つづいてmediumです。数値が少し間違っているのと、麻酔科⇒マスイカ、形成外科⇒形成技科になってますが精度は全般まずまず良いですね。
[0.00 - 5.44] 予約の変更をお願いしたいんですけども
[0.00 - 8.44] 診察券番号は123456489です
[0.00 - 15.64] 名前は山田太郎で、携帯番号は090-1234-5648です。
[0.56 - 19.56] 今予約しているのが、10月1日の10時なんですけども、それを10月5日、14時に変更できますか?
[0.00 - 3.16] あとのちょうどですね
[3.16 - 8.60] 以前対応してもらったマスイカと
[8.60 - 13.00] あと形成技科の担当の方から
[13.00 - 20.28] 折り返し電話をいただきたいのでお願いします
最後にsmallです。精度はかなり悪いですね。。
[0.00 - 8.78] あのユエクの変更をお願いしたいんですけれども
[0.00 - 13.24] 新設計の番号は12345679です
[0.00 - 4.18] おまえあおまえもやもまたたるで
[0.00 - 4.00] 携帯番号は
[4.00 - 7.00] 090
[0.00 - 9.40] 1・3・4・5・6・4・チャッチです
[0.00 - 4.24] いまいわくしてるのが
[0.00 - 7.06] じゅうがついてじゅうじゅうじゅんなんですけれども
[0.00 - 13.54] それを10月日か14時に変更で決まりますか
[0.00 - 3.24] あとの両方ちょうどですね
[4.50 - 11.38] 以前対応してもらったまっすかと
[0.00 - 6.36] あと、形成感の担当の方だから
[6.36 - 12.32] 織り返しでいただきたいので
[12.32 - 15.44] お願いしまます
終わり
今回は、faster-whisperとGPUを使用して、リアルタイム文字起こしを行う方法を紹介しました。A10 GPUのパワーを活用することで、精度の高いリアルタイム文字起こしをサクサク実行できました。リアルタイムで音声がテキスト化されるため、会議やインタビューなど、時間をかけずに内容を把握できる場面で特に効果を発揮します。また、スピーディーな処理が可能なため、大量の音声データにも対応でき、業務効率化やコスト削減に繋がるのも大きなメリットです。これ以外にも様々なユースケースがあると思います!
興味を持った方は、ぜひ試してみてください!