はじめに
この記事は、こんな人の不満を解決します(特に自分)
電子ピアノなどに収録されている楽器の音色や、持っている楽器の音からサウンドフォントを作りたいけど一つ一つのサンプリング作業が面倒くさすぎる!! という声を、以下に劇的に改善します。
- 1.録音ソフトで録音を開始
- 2.音色を選択し、間隔を開けて音階の異なる音を次々に弾く
- 3.録音を終了し、一つのWAVに書き出す
例:WavePad
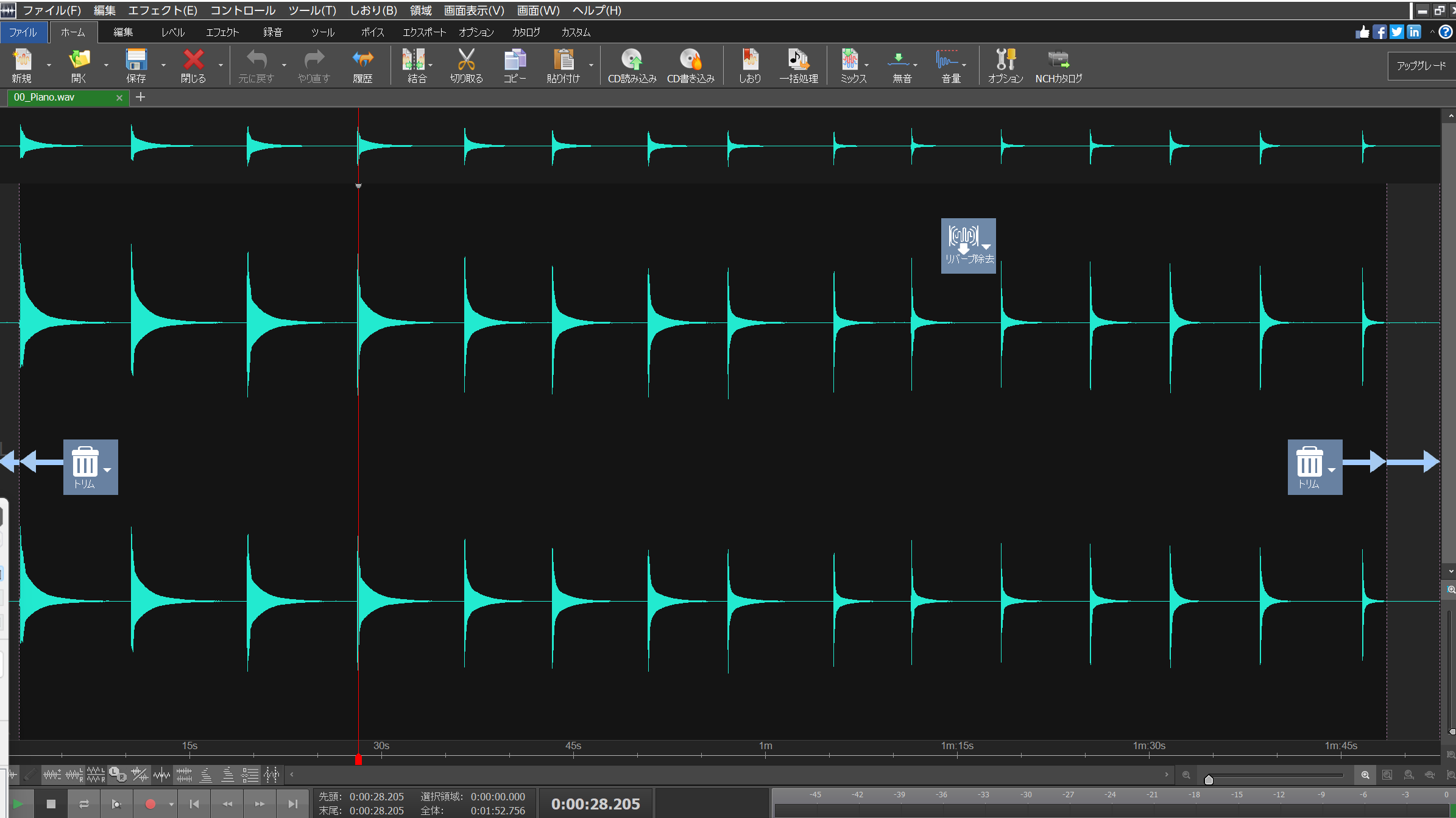
- 4.本ツールを実行する⇒自動で音階を認識し各音がファイル化される <- この部分を効率化!!
- 5.「Polyphone」などのサウンドフォントエディタで4の出力結果を読み込む
- 6.設定してサウンドフォントを書き出す
参考:サウンドフォントとは
楽譜作成ソフト「Finale」の紹介ページの文章を引用します。
サウンドフォントとは、MIDI楽器に変換されたオーディオサンプル集です。サウンドフォントは、FinaleのようなMIDIアプリケーションでプレイバック用に使用できます。Finaleには「SmartMusicソフトシンセ」というGeneral MIDIサウンドフォント(synthgms.sf2)が付属しており、デフォルトでは「SmartMusicソフトシンセ」がMIDIプレイバックに使用されます。Finaleで別のサウンドフォントを使用することもでき、また、SmartMusicソフトシンセを他のMIDI再生ソフトで使用することもできます。
簡単には、「楽器の音を収録した音声ファイル」を組み合わせて鳴らすことで、ソフトウェア音源にするための規格です。文字の「フォント」のように様々な音を好きに扱えることから「サウンドフォント」と名付けられたようです。
昔からある規格ですが、Appleの「Logic Pro」でも使えるほど、多くのDAWソフトで利用可能な汎用的な形式です。
実装アルゴリズム
注意
特に楽器の音をマイクで録音する場合は、なるべく環境音が入らないようにしてください。
うまく音が分割できない場合は、silence_thresholdの値を大きくすると改善するかもしれません
- 複数の音を録音したWAVファイルから、各音発音時のピークを検出
- 音の鳴り始めの位置を修正
- 各音を切り出し、高速フーリエ変換(FFT)を実行
- FFTで検出された音階をファイル名に付加して別々のWAVファイルに書き出す
実装
GPT-4にアシストしてもらいながら実装しました。
import numpy as np
import argparse
import math
from scipy.io import wavfile
import soundfile as sf
import os
from tqdm import tqdm
def frequency_to_midi(frequency):
midi_note = 69 + 12 * math.log2(frequency / 440.0)
midi_note = round(midi_note)
midi_note = max(0, min(127, midi_note))
return midi_note
def midi_to_note(midi_note):
note_names = ["C", "C#", "D", "D#", "E", "F", "F#", "G", "G#", "A", "A#", "B"]
octave = midi_note // 12 - 1
note = midi_note % 12
return note_names[note] + str(octave)
def find_peaks(data, peak_threshold=10000, distance=44100, silence_threshold=0):
ret = []
i_last_peak = -distance
for i in range(len(data)):
if data[i] >= peak_threshold and i - i_last_peak >= distance:
# Peak detected
for j in range(i, i_last_peak if i_last_peak > 0 else 0, -1):
if data[j] < silence_threshold:
ret.append(j)
i_last_peak = j
break
ret.append(i)
return ret
def split_wav_file(args):
input_file = args.input_file
output_dir = args.output_dir
peak_threshold = args.peak_threshold
silence_threshold = args.silence_threshold
analyze_note = args.analyze_note
mono = args.mono
os.makedirs(output_dir, exist_ok=True)
# Load input WAV
samplerate, data = wavfile.read(input_file)
data_original = data
# If stereo or more channels, using first channel
if len(data.shape) > 1:
# data = data.mean(axis=1)
data = data[..., 0]
# Find peaks
peaks = find_peaks(data, peak_threshold=peak_threshold, distance=samplerate * 3, silence_threshold=silence_threshold)
# Split by per peaks
for i in range(len(peaks)-1):
start, end = peaks[i], peaks[i+1]
chunk = data[start:end]
chunk_original = data_original[start:end]
if len(chunk) == 0:
continue
if analyze_note:
freq = np.fft.rfftfreq(len(chunk), d=1./samplerate)
fft = np.abs(np.fft.rfft(chunk))
peak_freq = freq[np.argmax(fft)]
midi_note = frequency_to_midi(peak_freq)
note = midi_to_note(midi_note)
# Create new file
new_filename = f"{os.path.splitext(os.path.basename(input_file))[0]}_{i:02d}_{midi_note}_{note}.wav"
else:
new_filename = f"{os.path.splitext(os.path.basename(input_file))[0]}_{i:02d}.wav"
new_filepath = os.path.join(output_dir, new_filename)
# Save as a WAV file
chunk = chunk_original[..., 0] if mono else chunk_original
sf.write(new_filepath, chunk, samplerate, format="WAV", subtype='PCM_16')
def main():
parser = argparse.ArgumentParser(description='Split a WAV file into separate files for each note.')
parser.add_argument('--input_dir', type=str, required=True, help='The directory of input WAV files.')
parser.add_argument('--output_dir', type=str, default="./output/", help='The directory to save the output WAV files.')
parser.add_argument('--analyze_note', action="store_true", help='Analyze key using fft')
parser.add_argument('--mono', action="store_true", help='Output mono WAV')
parser.add_argument('--peak_threshold', type=int, default=10000)
parser.add_argument('--silence_threshold', type=int, default=0)
args = parser.parse_args()
wavs = [p for p in os.listdir(args.input_dir) if p.endswith((".wav"))]
for wav in tqdm(wavs):
args.input_file = os.path.join(args.input_dir, wav)
split_wav_file(args)
if __name__ == '__main__':
main()
使い方
- スクリプトをダウンロードします。
- Pythonがインストールされている環境でスクリプトを実行します。
- コマンドラインから以下のように引数を指定してスクリプトを実行します。
python script.py --input_dir /path/to/input --output_dir /path/to/output --analyze_note --mono --peak_threshold 10000 --silence_threshold 0
スクリプトが実行され、指定した入力ディレクトリ内のWAVファイルがそれぞれの音に分割され、FFTを使って音階が検出されます。分割された各音は、音階がファイル名に付加された状態で出力ディレクトリに保存されます。
コマンド引数の意味
-
--input_dir: 入力WAVファイルが保存されているディレクトリのパスを指定します。この引数は必須です。 -
--output_dir: 分割された音を保存するディレクトリのパスを指定します。デフォルトは./output/です。 -
--analyze_note: このオプションが指定されると、FFTを使って音階を分析し、分析結果を出力ファイル名に付加します。 -
--mono: このオプションが指定されると、出力WAVファイルはモノラルになります。 -
--peak_threshold: ピークを検出するための閾値を指定します。デフォルトは10000です。 -
--silence_threshold: 音が鳴った時鳴り始めのサンプルを検出する際、無音とみなす音量を指定します。デフォルトは0です。この値を大きくすると、雑音を含む音声に対処できます。
実際に使ってみた
この実装を「sample_splitter_for_soundfont.py」として保存し、同じフォルダに作った「input」フォルダに「00_Piano.wav」を保存した場合
python sample_splitter_for_soundfont.py --input_dir input --output_dir output --analyze_note --mono
処理が完了されると、outputフォルダに別々のWAVファイルが保存されます。
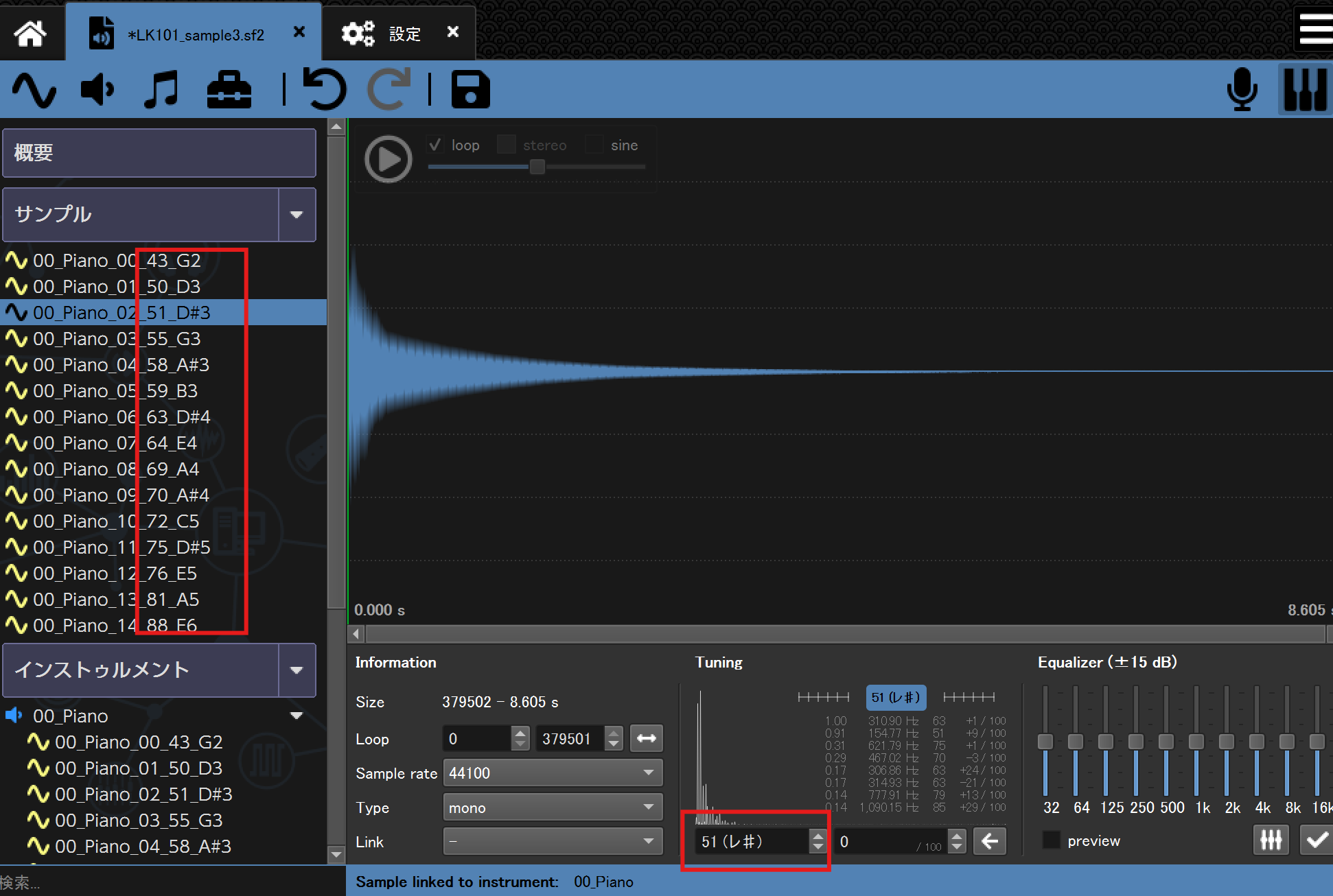
Polyphoneなどのサウンドフォントエディタで、サンプルとしてこれらのファイルを選択してインポートすると、自動的に音名を認識してインストゥルメントの作成を効率化できます。
ファイル名に付加された音名がroot keyとして反映されます↓
複数のサンプルファイルを選択してインストゥルメントを作成すると、自動的に各サンプルの発音範囲がマッピングされます↓
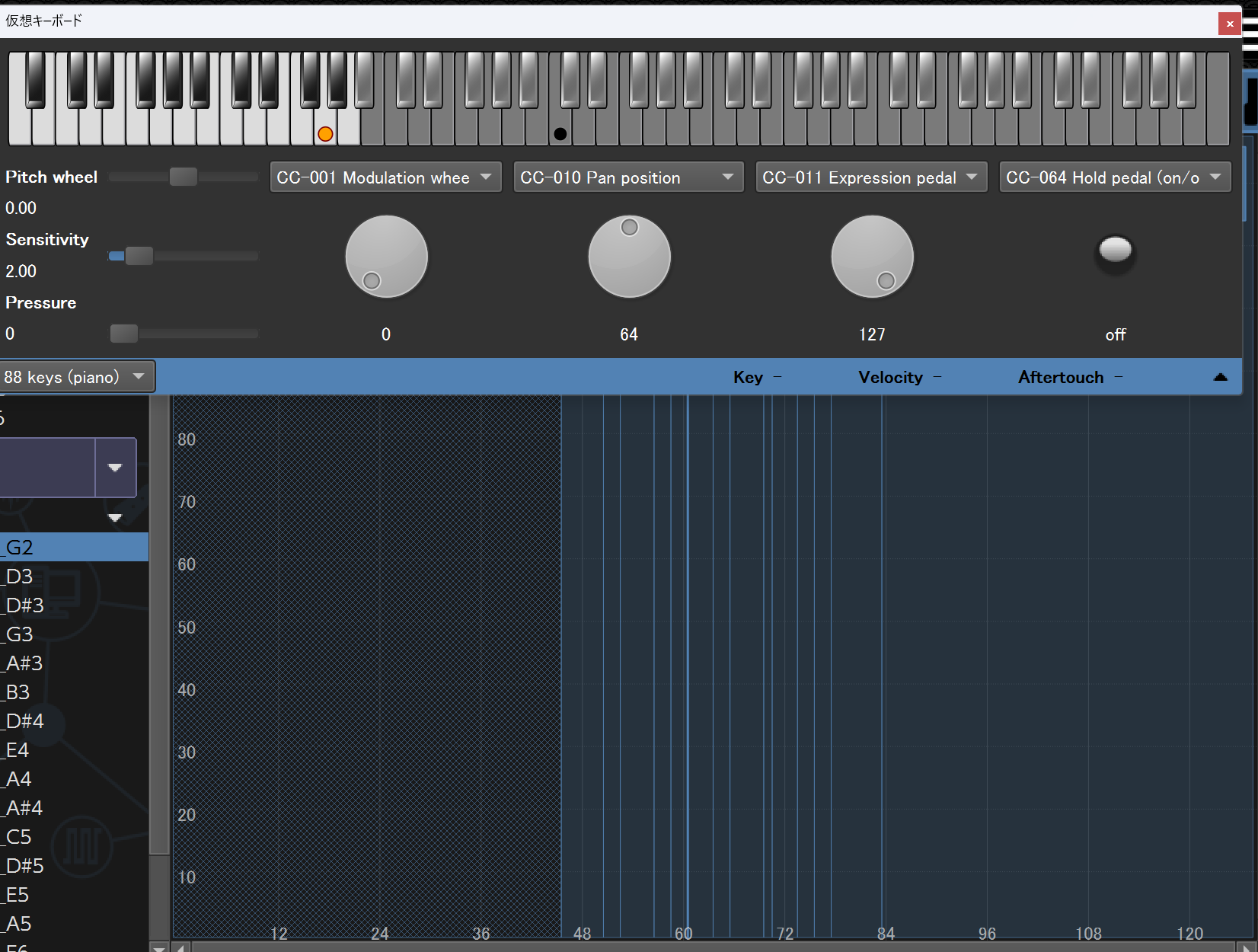
パラメータを調整してプリセットを作成すれば、オリジナルのサウンドフォントが完成!
おわりに
サウンドフォントの作成を効率化する方法を紹介しました。
「できる限り効率化してサウンドフォントを作りたいんだ!!」という同じ気持ちを持っている方の参考になれば幸いです!
この実装を行った経緯の話
自分が小さいころに使っていた、ほぼ20年前に発売された子供向け電子ピアノ「CASIO 光ナビゲーションキーボード LK-101」というものがあります。

収録されている曲の中には、
- 人生のメリーゴーランド(「ハウルの動く城」より)
- DANZEN! ふたりはプリキュア(Ver. Max Heart)
- さくらんぼ
- 世界に一つだけの花
- マツケンサンバII
といった、当時リリースされた人気曲が多く収録されたモデルです。不思議と、20代後半になった今もこのキーボードの音は忘れられないものです。
このキーボードの発売年とほぼ同じく、プリキュアも去年の「ひろがるスカイ!プリキュア」で20周年となり、初代から勢ぞろいした小冊子つきの特装版コミックも出ていたりするほど懐かしの曲だったりします。
「マツケンサンバII」もTikTokなどで最近再燃していますが、小学生のころにリリースされ耳たこ状態に聞きすぎている世代で、忘れることはありません。
20年たった今、これらの曲が収録されたキーボードの音源を聞きたくても、曲目がこのラインナップになっているモデルは「LK-101」しかありません。
ただでさえ、現在は廃盤で流通量が少ないモデルにもかかわらず、なんと「ジモティー」で同じ県内で出品している方を運良く発見し、こどもが使わなくなったというその方から譲っていただきました。非常にきれいに使っていたようで20年物とは思えません。この度は本当にありがとうございます!!
知らず知らずのうちに親に捨てられていた(もしかすると自分が捨てていいと言ったのかもしれませんが)、いつ家からなくなったかわからない懐かしのキーボードが手元に戻ってきたのには感動しますね。
「小学生のころ聞いた音を、電子ピアノが壊れたとしても永遠に残せるようにしておこう」
「MIDI入出力に対応していないこの楽器をサウンドフォント化していろんな曲を鳴らしてみたい」
という思いから実装してみました。
他にも、SC-88 ProやMU100など、もはや同い年レベルの年季の入ったハードウェア音源も所有しているので、こちらもサウンドフォント化して永遠に残したいと思います。