はじめに
DistributedLog(以下DL)とはTwitterがオープンソースとして公開したスケーラブルなメッセージングシステムです。

現在ではApache Incubatorプロジェクトとなっており、注目度の高いプロダクトです。
本記事ではDLの基礎についてドキュメントからかいつまんでまとめてみようかと思います。
現在ではドキュメントぐらいしか情報もなく、まだサンプルプログラムも実装していないので間違いがあったらごめんなさい。
データの扱われ方
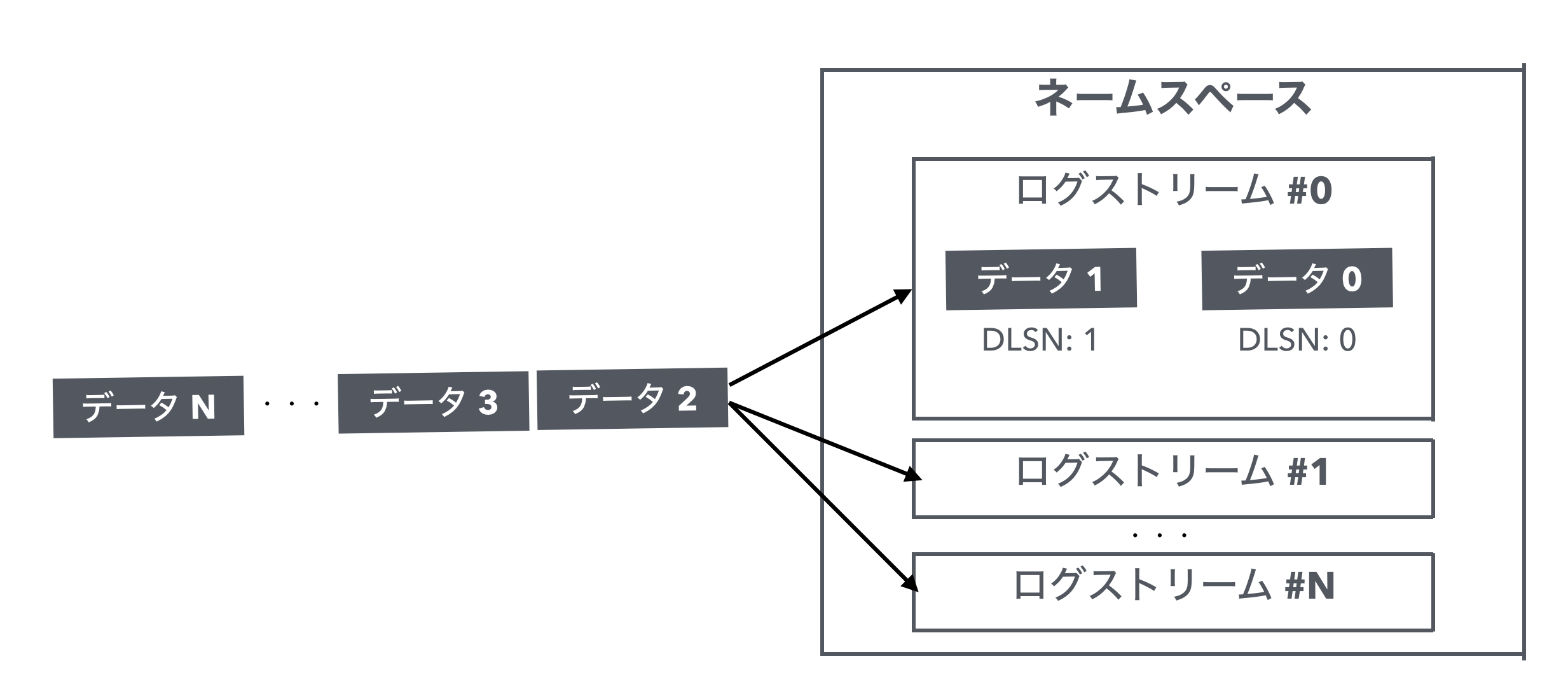
ログストリームとネームスペース
DLではログストリームと呼ばれる単位でデータを扱います。
またこのログストリームはネームスペースの配下として管理されます。
ひとつのネームスペース配下には複数のログストリームを作成することができ、クライアントはログストリームを指定してDLにデータの読み書きを行います。
書き込み際には複数のログストリームを明示的に指定することもできますし、ロードバランシングも可能となっているようです。
DLSNとTransactionId
ログストリームへ書き込まれたデータにはその順にそれぞれ一意となるシーケンス番号(DistributedLog Sequence Number, 略してDLSN)が付与されます。
データ読み取りの際はこの番号をもとにデータの読み取り位置を管理します。
さらに各レコードにはクライアントアプリケーションが利用するためのトランザクションIDも指定することができます。
こちらも同様にデータを読み取る際の位置を特定するためのものです。
DLは他のPub/Subシステムとは異なり、自身でどこまでデータが読み取られたかの位置情報を管理しません。そのためクライアント側で上記のシーケンスIDやトランザクションIDを利用して読み取り位置を管理する必要があります。
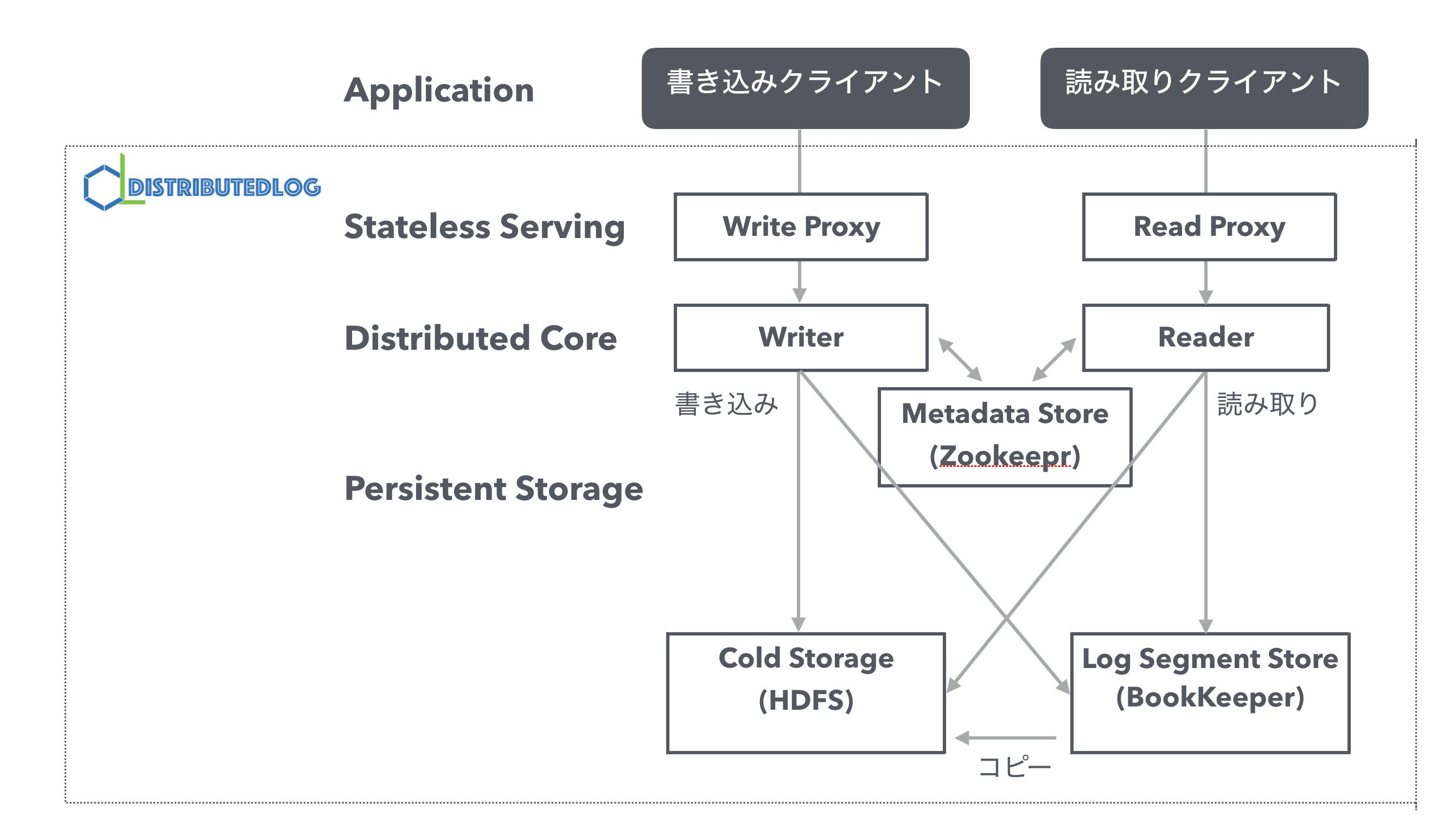
全体構成
ドキュメントでは大きく以下のレイヤーで分けられています。
- Stateless Serviing
- Distributed Core
- Persistent Storege
図にすると以下のようなかたちです。
Stateless Serviing
DLに読み書きを行うクライアントアプリケーションとデータの永続化を行うPersistent Storage(詳細は後述)の仲介を行うレイヤーです。
そのため、DLへのデータアクセスのための様々なやり取りを担います。
主に以下の機能がこのレイヤーに含まれています。
Write Proxy
DLに対してデータを書き込む際の受け口となるものです。
クライアントアプリケーションはこのWrite Proxyを経由してDLへデータを書き込みます。
DLのサーバ障害時などにおけるフェイルオーバーもWrite Proxyが透過的に行う仕組みとなっています。
Read Proxy
DLに対してデータを読み込む際の受け口となるものです。
DLへの読み取りを行うクライアントアプリケーションからの一斉処理をさばけるように、データをキャッシュします。
Distributed Core
Writer
実際にDLのデータストアへ書き込みを担うコア機能であり、書き込み時においてデータの順序を保証します。
そのため、それぞれのログストリームに書き込むを行うWriterはただひとつになるように調整されます。
Reader
実際にDLのデータストアからの読み取りを担うコア機能です。
前述した通り、DL自体はクライアントごとの読み取り位置を管理しないため、指定されたシーケンスIDまたはトランザクションIDをもとにデータの読み取りを開始します。
Persistent Storege
データの永続化を行うレイヤーです。さらに大きく3つの要素から構成されています。
Log Segment Store
前述したログストリーム上のデータは、実際にはログセグメントという単位でデータ配置され、そのログセグメントを配置するデータストアです。
書き込みが行なわれているログセグメントが閾値よりも大きくなったもしくは一定時間を過ぎると、次のログセグメントに書き込みが行なわれていきます。
Apache BookKeeperが利用されています。
Cold Storage
時間の経過したログセグメントを格納するためのデータストアです。アーカイブや過去データからのリカバリなどを目的に利用されます。
いっぱいになったログセグメントがここにコピーされていきます。
ここではHDFSが利用されています。
Metadata Store
ログストリームをそれを構成するログセメントの紐付け情報といったメタデータを管理するためのデータストアです。
それ以外にもデータの読み書き時における一貫性を制御するためのデータなども管理されます。
Apache Zookeeperが利用されています
つぎは
ざっくり概要についてドキュメントを追いながら簡単に整理してみました。
次はサンプルプログラムを動かしながら仕組みの詳細についてみていきます。