はじめに
pythonのスクレイピングをやってみたく、さらに実用的な普段不満に思うことを解決しようと着手しました。
(ちょっと卑猥かもしれない動機です)
毎回、飲むメンツでは3次会くらいに相席屋にいこうとなるのですが、毎回課題となることがあります。
課題1:異性の多い店舗に行きたいが比較一覧できるサイトがない
「3次会にいこう!」となるのですが、どこの店舗にどれだけ男女比率があるのか一瞬でわかるサイトがなく毎回店舗検索してHPで確認して違う店舗のサイト見てと繰り返していて僕らは女性の多い店舗を探していち早く行きたいのにものすごく時間がかかる。
課題2:店舗毎に情報はあるものの探しにくい
都道府県から店舗を探し、店舗名のページに訪問。そこの情報で男女比率が出ているので見る。期待の結果ではない場合は違う店舗を検索。違う店舗のページに行くの繰り返しでめんどくさい。単純に男女比率で行く店舗を決めたいだけなのに前の店舗でみた数字を覚えてないためまた探すの繰り返し。
課題3:行き先は近くの店舗ではなく異性の多い店舗に行きたいだけ
特定の店舗に行くことが決まり、ただ単に男女比率だけ見たいなら既存のサイトでいいかもしれないが、結局は確率論なので女性の多い店舗に行きたい。
どうソリューションしていくのか
事前に店舗にいる男女比率の情報があるので情報をうまく拾い上げて、自サイトでランキング付けして店舗名、住所、サイトのリンクをアウトプットするだけ。
使用技術の選定
元々はPython触ってみたいってだけだったのでPythonはとりあえず確定。
そのほかのフロントは一番なんでも情報がある3つの言語に絞り込む。
選定ってほどでもないですけど、理由はこんな感じですw
※注意ポイント
スクレイピングはあまりにも度が過ぎると多数の人に迷惑をかける行為なので一番慎重にトライしてください。
本当はAPI叩くのがもっとも練習に適してると思うので初めての人は何かのAPIをまず叩いてみてください。
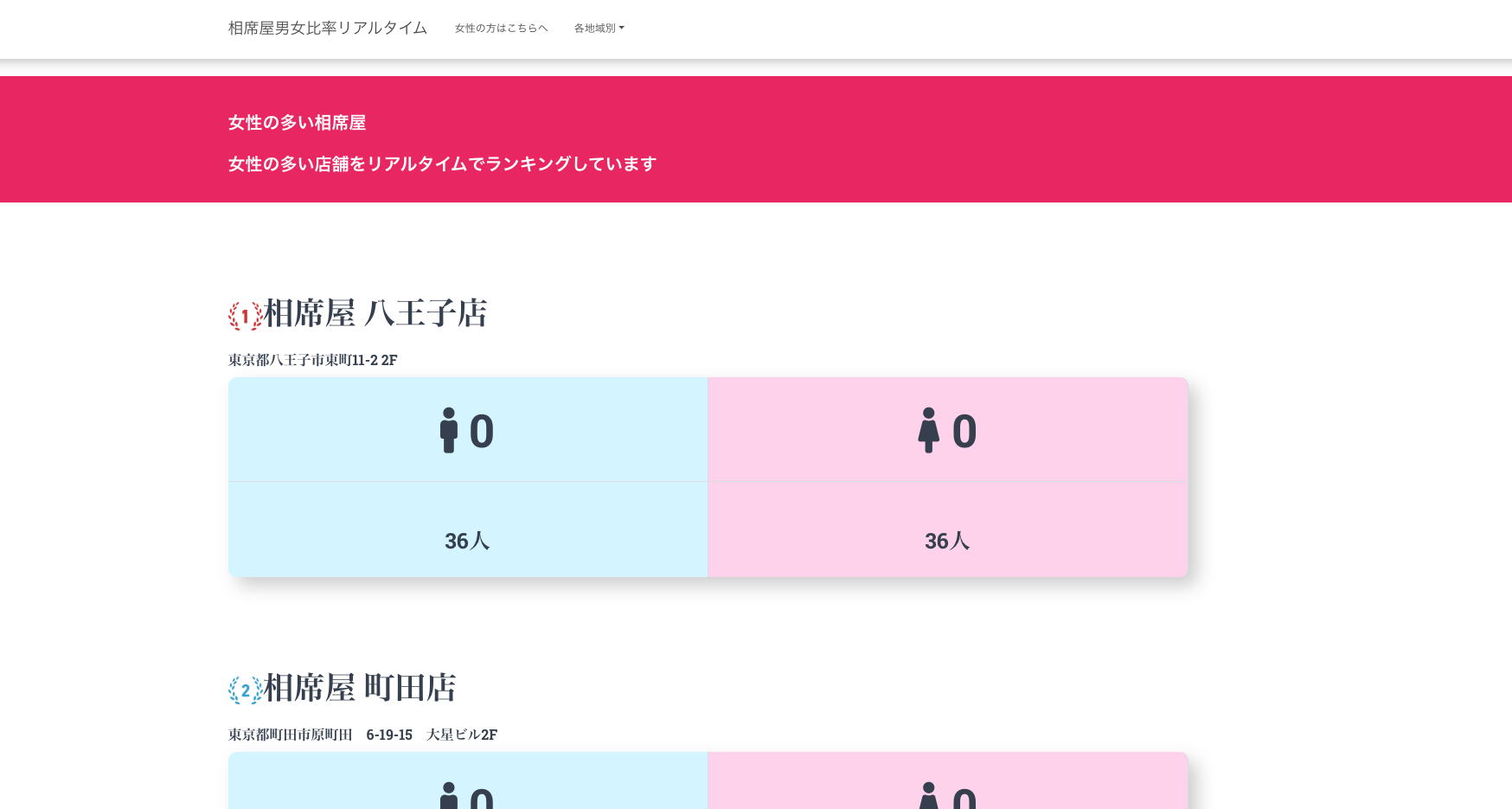
一応完成サイトです。
※サーバーを変えたのでアクセスできません。改めて改修したら新しいの載せます。
では作ってみよう!
Pythonにより必要情報の取得準備
macユーザーならおそらくPythonが入ってるので好きなエディタを開き(好きなファイル名).pyでファイルを作成してください。
ファイルの作成が完了したらターミナルを開きファイルのあるディレクトリまで移動してください。
その後に使う外部モジュールをインストールしていきます。
Requestsについては下記URLと簡単な概要をみてください。
pip install requests
Requestsは、 Python の HTTP 通信ライブラリです。 Requests を使うとWebサイトの情報取得や画像の収集などを簡単に行うことができます。Python には標準で urllib というライブラリが存在しますが、 Requests はそれよりもシンプルに、人が見て分かりやすくプログラムを記述することができます。
日本語の公式ドキュメント
lxmlについては下記URLと簡単な概要をみてください。
pip install lxml
lxml とは、 Python で xml や html を扱うためのライブラリです。スクレイピングと言って、Webサイトの html を解析して情報を抽出するプログラムを作成する場合などに多く用いられます。
ドキュメント
準備ができたら実際にコードを書いてみる
import requests
import lxml.html
import json
target_url = ('欲しい情報が掲載されているURL')
r = requests.get(target_url)
html = lxml.html.fromstring(r.content)
htmltag = html.xpath("欲しいURL情報があるXpath")
for item in htmltag:
url = item.get('href')
print(url)
はい。とりあえずこれでaタグのhrefを取ってこれました。
て感じです。めちゃくちゃ簡単。
※xpathについては下記URLみてみてください。
欲しい情報がもっとある。という時には続けて書いてみてください
import requests
import lxml.html
import json
target_url = ('欲しい情報が掲載されているURL')
r = requests.get(target_url)
html = lxml.html.fromstring(r.content)
htmltag = html.xpath("欲しいURL情報があるXpath")
for item in htmltag:
url = item.get('href')
##取得したURLをさらに開いてURL内にあるテキスト情報を取得してくる。
re = requests.get(url)
html = lxml.html.fromstring(re.content)
shopName = html.xpath("欲しいURL情報があるXpath")
shop = str(shopName[0].text)
print(shop)
すいません。rとかreとか雑ですけど、ここはちゃんと定義してください。
あとあとめんどくさいと思うので。
取得した情報をJSONに書き込み。
気づいた人は気づいたかもしれないですけど、import jsonがあるのはこのためです。
import requests
import lxml.html
import json
##この空のリスト作るの重要です。複数の辞書をJSONに書き込む場合は空のリストに入れてからじゃないとうまくいかないです。
list =[]
target_url = ('欲しい情報が掲載されているURL')
r = requests.get(target_url)
html = lxml.html.fromstring(r.content)
htmltag = html.xpath("欲しいURL情報があるXpath")
for item in htmltag:
url = item.get('href')
##取得したURLをさらに開いてURL内にあるテキスト情報を取得してくる。
re = requests.get(url)
html = lxml.html.fromstring(re.content)
shopName = html.xpath("欲しいURL情報があるXpath")
shop = str(shopName[0].text)
print(shop)
##JSONに書き込む準備します。正直、辞書とかよくわからないのですがこんな感じにしたらうまくJSONにできました。
##今回は一個の辞書をJSONに書き込むとしたらリストいらないかもしれないですけど、一応。
jisho = {'shop':shop}
list.append(jisho)
with open('filename.json', 'a' ) as file:
json.dump(jisho, file, ensure_ascii=False, indent=4, separators=(',', ': '))
これで書き込みできると思います。
時々、空白ができてて厄介になるのでそれはstripとかで検索して削除してください。
with openした後にjsonそして'a'が謎だと思うんですけど、'a'の場合は新規でファイル作る時。
ではすでにファイルある時は'w'でOKです。
情報が取得できたら次はJSでParseします。
ちょっとJSはpython触ってたらある程度できると信じてるので割愛してもいいですか?
書き始めたら止まらなくなります。
参考にしたのは下記サイト
JavaScriptでのJSONのパーシング - JSONの読み込みと値の取得 (JavaScript プログラミング)
javascriptを使ってランキングの順位を表示する仕組みを実装したい。
HTML,CSSが下記サイトのデザインを参考にしました
終わりに
多分、できる人ならもっと短時間でできる可能性がありますが一番時間かかったのはフロントのデザイン選定。
うまく比較できるようなデザインが見つからずにこんな感じでした。
後はcronもやりたいのですが、まだ確実ではないのでできたら追記していきます。
すぐにcronできたのでこちらも紹介していきます。
さくらサーバーでpython実行です。
初めてのQiitaでした。