はじめに
VisasQ Inc. Advent Calendar 2025 8日目の記事です。お手柔らかにお願いいたします。
(これは...デジャブ?)
みなさまは日々いろいろなWeb記事を読んでいると思いますが、あとで読み返したい記事を見つけた時にどうしているでしょうか?
例えばQiitaであればいいねする機能やストック機能を使い、マイページのいいねした記事やストックリストから記事を読み返すことができます。
しかし、そういったことができないサイトのWeb記事の場合はどうしていますか?
もちろんWeb記事をクリッピングして、スクラップしていますよね?
スクラップブック、作ってますよね?
私は自分だけのスクラップブックを作っています。
この記事では、私が作成した(もちろんバイブコーディング)、生成AIを利用して情報整理をする機能についてご紹介します。
アイコンを1クリックするだけで、保存した記事にAIが自動でタグと要約を付け、さらにもう1クリックで適切なフォルダへ記事ファイルを移動してくれるObsidianのプラグインです。
主なトピックとしては
- Obsidianのプラグイン作成
- 生成AIを趣味に活かした事例
- 情報整理の自動化
になります。
みなさまのスクラップブックの情報整理の効率化のヒントになれば幸いです。
(これは「Webクリップ AI要約」とかで検索すると結構記事がヒットします。他の記事のほうがわかりやすいかも)
プラグインの目的と機能
スクラップブックを作るという趣味は、自分だけの図書館を作りたいという欲求から始めました。
この作業は楽しいのですがそれなりに時間がかかります。
記事本文を読んで内容を理解し、適切なタグを考え、どのカテゴリに属するかを判断する。
一連の作業には時間がかかり、Web記事を読み情報を整理しておきたいが面倒だなあとなることもしばしば。
ツールはEvernote -> Pocket -> Notionと変遷していき、現在はObisidianを使っています。
Notion使用時にはNotionAIを活用し、記事の要約、記事のキーワードを設定するのをAIにやらせていました。
NotionAIは有料です。
年間契約で$105、当時のレートで15000円ぐらいでした。
いろいろと遊んでみた後、契約が切れるタイミングでObsidianに乗り換えました。
これにあたりObsidian上でも同等の機能を実現できることを目指しました。
作成したプラグインは以下の2つです。
-
AiTaggingAndSummarize: 特定フォルダ(未整理ファイル用)にあるMarkdownファイルの内容を読み込み、Gemini APIを用いて「tags」「category」「description」を自動生成し、YAMLフロントマターに書き込みます -
MoveByCategoryPlugin: 特定フォルダ内のMarkdownファイルをスキャンし、AiTaggingAndSummarizeによって付与された「カテゴリ」情報に基づいて、01_AI_テクノロジーや02_科学_研究といった適切なフォルダに自動で移動させます
両プラグインともに、Obsidianのリボンアイコンをワンクリックで実行可能です。
名前はそこそこちゃんとしています。この時はいい感じにAIが名付けてくれました。
Obisidian Web Clipper
Obisidian Web ClipperというChromeの拡張機能もあります。
実はこの拡張機能のみでAI要約やタグ付けができます。そのため、わざわざ自作でプラグインを作る必要がありません。
しかし、私がこの機能を使った当初はクリッピングできないWeb記事や、なんかうまくタグ付けができなかったなどの理由からこの拡張機能を使うのをやめた、と記憶しています。
今使ってみたら便利に使えるのかもしれません。しかしオペレーションを変えるのには腰が重いですね...
また、私のプラグインは情報整理のみを行い、クリッピング機能は別のObsidianプラグインを利用しています。
クリッピング機能と情報整理の機能が分けられていることで、複数記事をクリッピングしておいて後から一括で情報を整理させることが可能です。
つまり1記事をAIに解釈をさせてからクリッピングするという流れでなく、とりあえずひたすらクリッピングだけして、風呂、歯磨き、皿洗いなどをしてる間に情報を整理する、といったルーティンができるということですね。
私はこのルーティンを気に入っています。
ツール
使用ツールは以前の記事でも触れていますが、今回も同様です。
- Obsidian
- Gemini API
- Python 3.x
- Node.js
すべて無料です。
無料でAIを利用し趣味を楽しむことができるなんて、いい時代ですね。
Obsidian
https://obsidian.md/
Obsidianは、ローカルなMarkdownファイルをベースとした強力な知識管理ツールです。
その魅力の一つは、コミュニティプラグインによる無限の拡張性にありますが、時には自分のニッチな要求を満たすプラグインが見つからないこともあります。
この記事では、まさにそうした状況から生まれた自作プラグインの話になります。
Gemini API
https://ai.google.dev/gemini-api/docs?hl=ja
Googleのアカウントを持っていれば使えるAPIです。
プラグイン上で利用するモデルはgemini 2.5 flashです。
複雑な計算や推力を求めない機能なのでproである必要はありません。
無料で1日あたり250リクエストできます。つまり、1日に約83記事(タグ付け、カテゴリ設定と要約で1記事3リクエスト)まで情報整理できます。
1日にクリッピングしたい記事の数なんてたかが知れてるので十分な量です![]()
Python
https://www.python.org/
GeminiAPIを利用するロジックをPythonで書いているので必要になります。
GeminiAPIを利用できる使い勝手のよいライブラリがあれば、言語は何でもいいです。
Node.js
https://nodejs.org/ja
プラグインのJavaScriptがPythonスクリプトを呼び出すために、Node.jsのchildprocessを利用しています。
他
おそらく環境構築で多分いろいろインストールしてますが覚えてないので割愛。
プラグインの設計
実際の開発経緯はPythonでスクリプト作る -> 動いたのでこれを利用してプラグインを作るという流れです。
行き当たりばったりです。
そんな感じでできあがったプラグインは、以下のコンポーネントで構成されています。
-
main.js(Obsidian Plugin):- ユーザーがリボンアイコンをクリック
- Node.jsの
child_processモジュールを使い、対応するPythonスクリプトをサブプロセスとして起動する - 処理の終了をObsidianの
Noticeで通知
-
process_all_md.py/move_files_by_category.py(Python Script):- 起動後、対象のディレクトリ内のMarkdownファイルをスキャンする
-
process_all_md.pyは、ai_tagging_single.py(タグとカテゴリ生成)とai_summary_single.py(要約生成)を呼び出し、YAMLフロントマターが未処理のファイルを対象に、内容をGemini APIに送信し、返ってきた概要・タグ・カテゴリをファイルに書き込む -
move_files_by_category.pyは、カテゴリが設定されているファイルを対象に、定義済みのマッピングに基づいて適切なディレクトリへファイルを移動させる
開発・実行環境
趣味用のPCはWindowsなので、Windowsで環境を作ります。
Obsidian
公式サイトからDL、インスコしましょう。
初期設定も済ませます。Vaultと呼ばれるフォルダを設定するぐらいです。
有志の方々がいろいろとまとめているWeb記事がたくさんあるはずです。
次にVault内に未読のWeb記事を保存するディレクトリと、既読のWeb記事を保存するディレクトリを作成します。
私の場合、未読が99_Raw、既読が01_AI_テクノロジー, 02_科学_研究, 03_社会_文化, 04_ビジネス_キャリア, 05_健康_医療, 06_その他です。
これら6つのカテゴリに記事を分けるようになっています。
この6つのカテゴリは、もともと溜め込んでいた記事タイトルをAIに分析させ、全部の記事を大きく分類するとしたらどういうカテゴリ設定ができてるか、というプロンプトのもとできあがったカテゴリです。
クリッピングプラグイン
https://github.com/DominikPieper/obsidian-ReadItLater
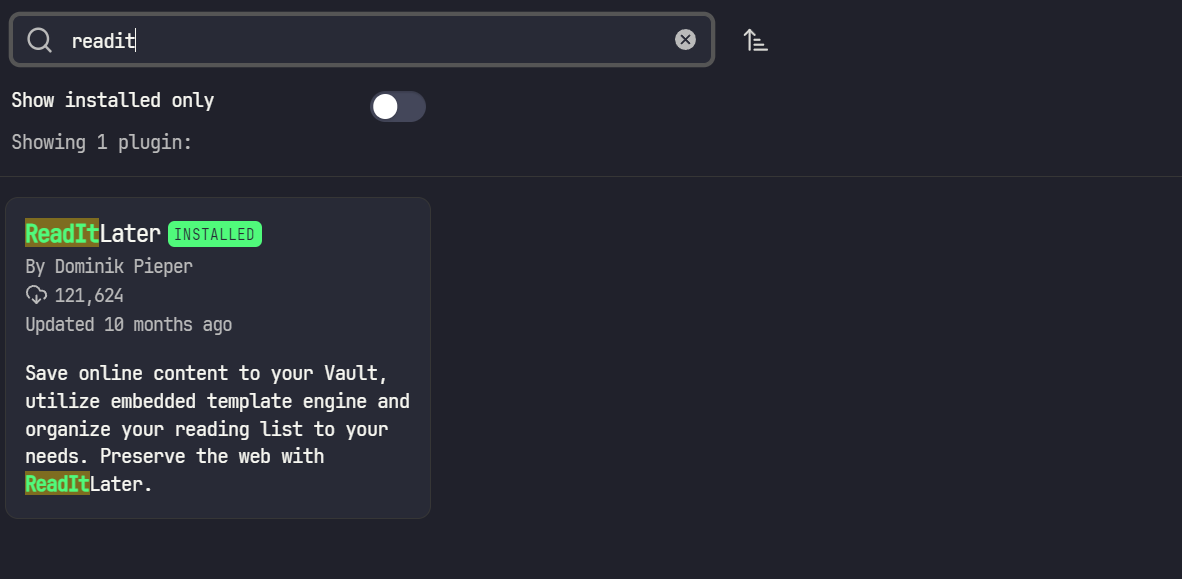
ReadItLaterを利用します。
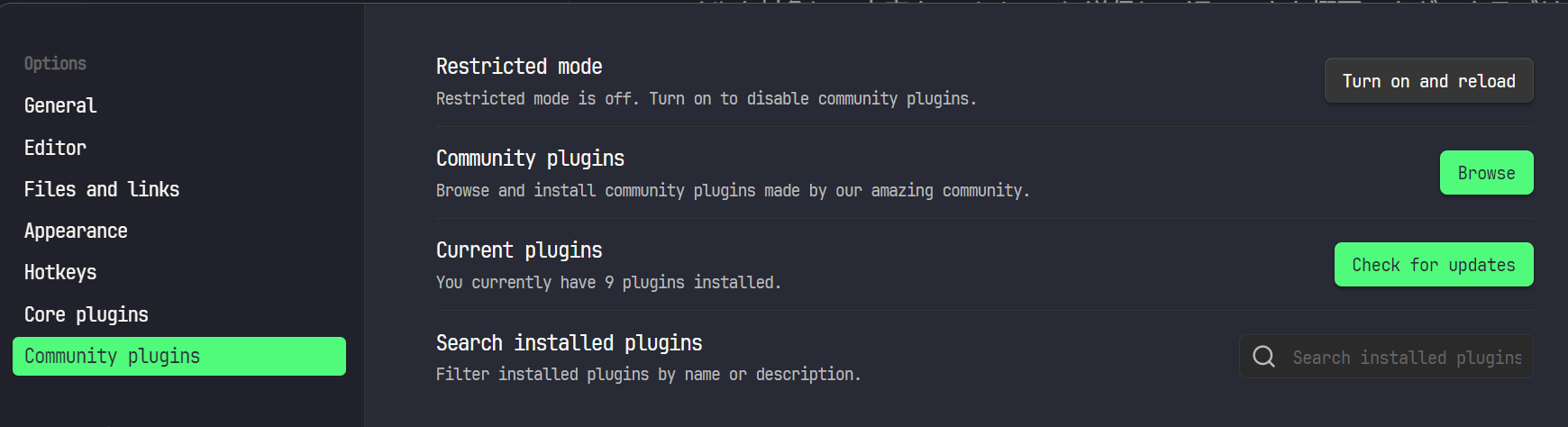
Options -> Community Plugin -> Browseから検索窓にプラグイン名を入れインストールします。
プラグイン自体の設定でInbox directoryを、作成した未読のWeb記事を保存するディレクトリを指定します。
他の設定はお好みにしましょう。

Gemini API
Google AI StudioからGemini APIキーを取得します。これもやり方を書いたWeb記事がたくさんあります。
Vaultのルートに.envファイルを作成し、以下のようにキーを記述しました。
GEMINI_API_KEY="ここにAPIキーを書く"
Python
「Windows Python 環境構築」で検索して環境を作りましょう。
(私は3.13.5を使用しています)
必要なライブラリ
-
google-generativeai- Gemini APIと通信するための公式ライブラリ
-
python-dotenv- APIキーを安全に管理するため
以下のコマンドでインストールします。
pip install google-generativeai python-dotenv
pipもWindowsでのインストールのやり方を検索して入れておきましょう。
Node.js
これもWindowsでのインストールの仕方を調べて入れます。
(私はv22.17.0を使用しています)
環境構築の手順は、前回の単語帳プラグインとほぼ同じです。
ディレクトリ構成
私の場合は以下のようになりました。
Vault Root/
├── .env
├── ai_summary_single.py
├── ai_tagging_single.py
├── move_files_by_category.py
├── process_all_md.py
├── 99_Raw/
│ ├── (Webクリップした記事などのMarkdownファイル群)
├── 01_AI_テクノロジー/
├── 02_科学_研究/
...
└── .obsidian/
└── plugins/
├── AiTaggingAndSummarize/
│ ├── main.js
│ └── manifest.json
└── MoveByCategoryPlugin/
├── main.js
└── manifest.json
コーディングの詳細
開発はすべて生成AIに任せました。
AiTaggingAndSummarize
main.js
const { exec } = require('child_process');
const path = require('path');
module.exports = class MyPlugin extends require('obsidian').Plugin {
async onload() {
console.log('MyPlugin loaded');
// 1. AIタグ・サマリー付与用リボン&コマンド
this.addRibbonIcon('tags', 'AI Tagging and Summary (all)', async () => {
await this.runProcessAll();
});
this.addCommand({
id: 'ai-tagging-and-summary-all',
name: 'AI Tagging and Summary (all)',
callback: async () => {
await this.runProcessAll();
}
});
}
async runProcessAll() {
try {
const pluginPath = this.app.vault.adapter.basePath;
const processAllScriptPath = path.join(pluginPath, 'process_all_md.py');
console.log(`Process all script path: ${processAllScriptPath}`);
await this.executePythonScript(processAllScriptPath, 'Process All Files');
new Notice('AI tagging and summary completed!');
} catch (error) {
console.error('Error in process_all_md.py:', error);
new Notice('Error in AI tagging/summary. Check console for details.');
}
}
executePythonScript(scriptPath, scriptType) {
return new Promise((resolve, reject) => {
exec(`python "${scriptPath}"`, (error, stdout, stderr) => {
if (error) {
console.error(`${scriptType} Error:`, error.message);
reject(error);
return;
}
if (stderr) {
console.error(`${scriptType} Stderr:`, stderr);
reject(new Error(stderr));
return;
}
console.log(`${scriptType} script output:`, stdout);
resolve(stdout);
});
});
}
onunload() {
console.log('MyPlugin unloaded');
}
};
manifest.json
{
"id": "ai-tagging-and-summarize",
"name": "AI Tagging and Summarize",
"version": "1.0.0",
"minAppVersion": "0.15.0",
"description": "A plugin to tag and summarize using AI.",
"author": "kei",
"authorUrl": "",
"isDesktopOnly": false
}
ai_summary_single.py
自分で考えたプロンプトを使っているはずです。
本当はAIに練らせたもののほうがいいです。しかし、今のレスポンスでも満足しているので修正していないです。
また、最初はコマンドラインで1ファイルずつ実行する想定で作っているので、そのようなコードになっています。
import os
import google.generativeai as genai
import time
import sys
from dotenv import load_dotenv
# .envファイルを読み込む
load_dotenv()
# 設定
api_key = os.getenv("GEMINI_API_KEY")
if not api_key:
raise ValueError("GEMINI_API_KEYが.envファイルに見つかりません。")
genai.configure(api_key=api_key)
model = genai.GenerativeModel('gemini-2.5-flash')
def safe_print(*args, **kwargs):
sep = kwargs.get('sep', ' ')
end = kwargs.get('end', '\n')
msg = sep.join(str(a) for a in args)
try:
print(msg, end=end)
except UnicodeEncodeError:
print(msg.encode('cp932', errors='replace').decode('cp932'), end=end)
def add_summary_to_md(source_content, summary):
"""
既存のdescriptionプロパティがあれば削除し、新しい要約を追加する。
Parameters:
- source_content (str): The original content of the note.
- summary (str): The summary text to add.
Returns:
- str: The note content with updated 'description' metadata.
"""
# Check if the content has metadata
if source_content.strip().startswith('---'):
parts = source_content.strip().split('---', 2)
metadata_str = parts[1]
content = parts[2]
else:
metadata_str = ''
content = source_content
metadata_lines = metadata_str.strip().split('\n') if metadata_str.strip() else []
new_metadata_lines = []
# descriptionプロパティを削除
for line in metadata_lines:
if not line.strip().startswith('description:'):
new_metadata_lines.append(line)
# 新しい要約を追加
new_metadata_lines.append(f'description: "{summary}"')
new_metadata_str = '\n'.join(new_metadata_lines)
return f"---\n{new_metadata_str}\n---\n{content}".strip()
def has_metadata(source_content, key):
"""
コンテンツに指定されたメタデータプロパティが存在するかチェックする
Parameters:
- source_content (str): The content to check
- key (str): The metadata key to check for (e.g., 'description')
Returns:
- bool: True if metadata exists, False otherwise
"""
if not source_content.strip().startswith('---'):
return False
parts = source_content.strip().split('---', 2)
if len(parts) < 2:
return False
metadata_str = parts[1]
metadata_lines = metadata_str.strip().split('\n')
for line in metadata_lines:
if line.strip().startswith(f'{key}:'):
return True
return False
def has_description(source_content):
"""
コンテンツにdescriptionプロパティが存在するかチェックする
Parameters:
- source_content (str): The content to check
Returns:
- bool: True if description exists, False otherwise
"""
return has_metadata(source_content, 'description')
def main():
# コマンドライン引数からファイルパスを取得
if len(sys.argv) > 1:
file_path = sys.argv[1].strip()
else:
file_path = input("要約を追加したいMarkdownファイルのパスを入力してください: ").strip()
if not os.path.isfile(file_path):
safe_print("ファイルが見つかりません: ", file_path)
return
with open(file_path, 'r', encoding='utf-8') as f:
source_content = f.read()
# 既存のdescriptionがある場合はスキップ
if has_description(source_content):
safe_print(f"Skipping {file_path} - description already exists")
return
# Geminiで要約生成
try:
prompt = f"""次のノート内容を深く分析し、簡潔に要約してください。200文字前後の文で、重要なポイントを押さえた要約を日本語で返してください。余計なテキストは含めずに要約のみを返してください。テキストに改行を入れないでください。テキストの文末表現は常体で返してください\n\n{source_content}"""
response = model.generate_content(prompt)
summary = response.text.strip()
time.sleep(10) # レート制限のため10秒待機
except Exception as e:
safe_print(f"Error processing {file_path}: {e}")
return
new_content = add_summary_to_md(source_content, summary)
with open(file_path, 'w', encoding='utf-8') as f:
f.write(new_content)
safe_print(f"Processed: {file_path}")
if __name__ == "__main__":
main()
ai_tagging_single.py
これも自分で考えたプロンプトを使っているはずです。
結構タグのためのキーワードを抽出するのが難しく、試行錯誤のあとが見えます。
import os
import google.generativeai as genai
import time
import sys
from dotenv import load_dotenv
# .envファイルを読み込む
load_dotenv()
def safe_print(*args, **kwargs):
sep = kwargs.get('sep', ' ')
end = kwargs.get('end', '\n')
msg = sep.join(str(a) for a in args)
try:
print(msg, end=end)
except UnicodeEncodeError:
print(msg.encode('cp932', errors='replace').decode('cp932'), end=end)
def add_category_to_md(source_content, category):
"""
既存のcategoryプロパティがあれば削除し、新しいcategoryを追加する。
カテゴリーは "#カテゴリー名" のようにダブルクオーテーションで囲み、先頭に # を付与する。
Parameters:
- source_content (str): The original content of the note.
- category (str): The category to add.
Returns:
- str: The note content with updated 'category' metadata.
"""
# Check if the content has metadata
if source_content.strip().startswith('---'):
parts = source_content.strip().split('---', 2)
metadata_str = parts[1]
content = parts[2]
else:
metadata_str = ''
content = source_content
metadata_lines = metadata_str.strip().split('\n') if metadata_str.strip() else []
new_metadata_lines = []
skip = False
for i, line in enumerate(metadata_lines):
if skip:
# category: の下の行をスキップ
if not line.strip().startswith('- '):
skip = False
else:
continue
if line.strip().startswith('category:'):
# category: 行をスキップ
skip = True
continue
new_metadata_lines.append(line)
# 新しいcategoryを追加
new_metadata_lines.append('category:')
# カテゴリー名をダブルクオーテーションで囲み、先頭に#を付与
new_metadata_lines.append(f' - {category}')
new_metadata_str = '\n'.join(new_metadata_lines)
return f"---\n{new_metadata_str}\n---\n{content}".strip()
def add_tags_to_md(source_content, tags_str):
"""
既存のtagsプロパティがあれば削除し、新しいtagsのみをYAMLリスト形式で追加する。
各タグは "#タグ名" のようにダブルクオーテーションで囲み、先頭に # を付与する。
Parameters:
- source_content (str): The original content of the note.
- tags_str (str): A comma-separated string of new tags to add。
Returns:
- str: The note content with updated 'tags' metadata (YAMLリスト形式)。
"""
# Check if the content has metadata
if source_content.strip().startswith('---'):
parts = source_content.strip().split('---', 2)
metadata_str = parts[1]
content = parts[2]
else:
metadata_str = ''
content = source_content
metadata_lines = metadata_str.strip().split('\n') if metadata_str.strip() else []
new_metadata_lines = []
skip = False
for i, line in enumerate(metadata_lines):
if skip:
# tags: の下のリスト行をスキップ
if not line.strip().startswith('- '):
skip = False
else:
continue
if line.strip().startswith('tags:'):
# tags: 行をスキップし、次のリスト行もスキップ
skip = True
continue
new_metadata_lines.append(line)
# 新しいtagsのみを追加
new_tags = [t.strip() for t in tags_str.split(',') if t.strip()]
new_metadata_lines.append('tags:')
for tag in new_tags:
tag_str = f'"#{tag}"'
new_metadata_lines.append(f' - {tag_str}')
new_metadata_str = '\n'.join(new_metadata_lines)
return f"---\n{new_metadata_str}\n---\n{content}".strip()
def has_metadata(source_content, key):
"""
コンテンツに指定されたメタデータプロパティが存在するかチェックする
Parameters:
- source_content (str): The content to check
- key (str): The metadata key to check for (e.g., 'category', 'tags')
Returns:
- bool: True if metadata exists, False otherwise
"""
if not source_content.strip().startswith('---'):
return False
parts = source_content.strip().split('---', 2)
if len(parts) < 2:
return False
metadata_str = parts[1]
metadata_lines = metadata_str.strip().split('\n')
for line in metadata_lines:
if line.strip().startswith(f'{key}:'):
return True
return False
def has_category(source_content):
"""
コンテンツにcategoryプロパティが存在するかチェックする
Parameters:
- source_content (str): The content to check
Returns:
- bool: True if category exists, False otherwise
"""
return has_metadata(source_content, 'category')
def has_tags(source_content):
"""
コンテンツにtagsプロパティが存在するかチェックする
Parameters:
- source_content (str): The content to check
Returns:
- bool: True if tags exist, False otherwise
"""
return has_metadata(source_content, 'tags')
# 設定
api_key = os.getenv("GEMINI_API_KEY")
if not api_key:
raise ValueError("GEMINI_API_KEYが.envファイルに見つかりません。")
genai.configure(api_key=api_key)
model = genai.GenerativeModel('gemini-2.5-flash')
def main():
# コマンドライン引数からファイルパスを取得
if len(sys.argv) > 1:
file_path = sys.argv[1].strip()
else:
file_path = input("タグ付けしたいMarkdownファイルのパスを入力してください: ").strip()
if not os.path.isfile(file_path):
safe_print("ファイルが見つかりません: ", file_path)
return
with open(file_path, 'r', encoding='utf-8') as f:
source_content = f.read()
# 既存のcategoryとtagsの両方がある場合は完全にスキップ
if has_category(source_content) and has_tags(source_content):
safe_print(f"Skipping {file_path} - both category and tags already exist")
return
# Geminiでタグ抽出(tagsがない場合のみ)
if not has_tags(source_content):
try:
prompt = f"""次のノート内容を深く分析し、記事の核心となるキーワードを5つ抽出してください。
【抽出条件】
- 記事の主要テーマを表すキーワードであること
- 具体的なキーワードと抽象的なキーワードの両方を抽出すること
- 例えば、イルカについての記事なら`イルカ`以外に`動物`といったように、より上位の概念を表すキーワードも抽出すること
- 単語が半角スペースで区切られるものだった場合は`_`でつなぐこと
- 1単語で1つのキーワードとすること
- 例えば神話や伝説についての記事だった場合に`神話_伝説`ではなく、`神話`と`伝説`でそれぞれのキーワードとして抽出すること
- 記事が英語の場合、可能な限り対応する日本語のキーワードにすること
- キーワードはカンマ区切りのリストで返すこと
- 余計なテキストは含めないこと
\n\n{source_content}
"""
response = model.generate_content(prompt)
tags_str = response.text.strip()
time.sleep(10) # レート制限のため10秒待機
except Exception as e:
safe_print(f"Error processing tags for {file_path}: {e}")
return
else:
safe_print(f"Skipping tags processing for {file_path} - tags already exist")
tags_str = None
# Geminiでカテゴリー抽出(categoryがない場合のみ)
if not has_category(source_content):
try:
category_prompt = f"""次のノート内容から、以下の6つのカテゴリーのうち最も適切な1つを選んでください:
1. AI_テクノロジー
2. 科学_研究
3. 社会_文化
4. ビジネス_キャリア
5. 健康_医療
6. その他
カテゴリー名のみを返してください。余計なテキストは含めないでください。\n\n{source_content}"""
category_response = model.generate_content(category_prompt)
category = category_response.text.strip()
time.sleep(10) # レート制限のため10秒待機
except Exception as e:
safe_print(f"Error processing category for {file_path}: {e}")
return
else:
safe_print(f"Skipping category processing for {file_path} - category already exists")
category = None
# タグとカテゴリーを追加(存在するもののみ)
new_content = source_content
if tags_str is not None:
new_content = add_tags_to_md(new_content, tags_str)
if category is not None:
new_content = add_category_to_md(new_content, category)
with open(file_path, 'w', encoding='utf-8') as f:
f.write(new_content)
safe_print(f"Processed: {file_path}")
if __name__ == "__main__":
main()
process_all_md.py
タグ付けと要約の処理を分けていたため、それを呼び出すスクリプトです。
import os
import sys
import time
from pathlib import Path
import ai_tagging_single
import ai_summary_single
def safe_print(*args, **kwargs):
sep = kwargs.get('sep', ' ')
end = kwargs.get('end', '\n')
msg = sep.join(str(a) for a in args)
try:
print(msg, end=end)
except UnicodeEncodeError:
print(msg.encode('cp932', errors='replace').decode('cp932'), end=end)
def process_directory(directory_path):
"""
指定されたディレクトリ内のすべてのMarkdownファイルを処理する
Parameters:
- directory_path (str): 処理対象のディレクトリパス
"""
# ディレクトリ内のすべての.mdファイルを取得
md_files = list(Path(directory_path).glob('**/*.md'))
total_files = len(md_files)
safe_print(f"Found {total_files} markdown files in {directory_path}")
# 各ファイルを処理
for i, file_path in enumerate(md_files, 1):
safe_print(f"\nProcessing file {i}/{total_files}: {file_path}")
# タグ付け処理
try:
safe_print("Processing tags and category...")
sys.argv = [sys.argv[0], str(file_path)]
ai_tagging_single.main()
except Exception as e:
safe_print(f"Error in tag processing: {e}")
# 要約処理
try:
safe_print("Processing summary...")
sys.argv = [sys.argv[0], str(file_path)]
ai_summary_single.main()
except Exception as e:
safe_print(f"Error in summary processing: {e}")
# レート制限のため少し待機
time.sleep(2)
def main():
# 処理対象のディレクトリ
target_directory = r"対象のディレクトリパス"
if not os.path.isdir(target_directory):
print(f"Directory not found: {target_directory}")
return
safe_print(f"Starting processing of markdown files in: {target_directory}")
process_directory(target_directory)
safe_print("\nAll files processed.")
if __name__ == "__main__":
main()
MoveByCategoryPlugin
main.js
const { exec } = require('child_process');
const path = require('path');
const { Plugin, Notice } = require('obsidian');
module.exports = class MoveByCategoryPlugin extends Plugin {
async onload() {
console.log('loading MoveByCategoryPlugin');
// リボンアイコン
this.addRibbonIcon('folder', 'Move Files by Category', async () => {
await this.runMoveByCategory();
});
// コマンド
this.addCommand({
id: 'move-files-by-category',
name: 'Move Files by Category',
callback: async () => {
await this.runMoveByCategory();
}
});
}
async runMoveByCategory() {
try {
const pluginPath = this.app.vault.adapter.basePath;
const moveFilesScriptPath = path.join(pluginPath, 'move_files_by_category.py');
console.log(`Move files script path: ${moveFilesScriptPath}`);
await this.executePythonScript(moveFilesScriptPath, 'Move Files by Category');
new Notice('File movement by category completed!');
} catch (error) {
console.error('Error in move_files_by_category.py:', error);
new Notice('Error in file movement. Check console for details.');
}
}
executePythonScript(scriptPath, scriptType) {
return new Promise((resolve, reject) => {
exec(`python "${scriptPath}"`, (error, stdout, stderr) => {
if (error) {
console.error(`${scriptType} Error:`, error.message);
reject(error);
return;
}
if (stderr) {
console.error(`${scriptType} Stderr:`, stderr);
reject(new Error(stderr));
return;
}
console.log(`${scriptType} script output:`, stdout);
resolve(stdout);
});
});
}
onunload() {
console.log('unloading MoveByCategoryPlugin');
}
};
manifest.json
{
"id": "move-by-category-plugin",
"name": "Move By Category Plugin",
"version": "1.0.0",
"minAppVersion": "0.15.0",
"description": "This plugin moves files to a specified folder based on their category.",
"author": "kei",
"authorUrl": "",
"isDesktopOnly": false
}
move_files_by_category.py
これはAIを利用しない、ただのファイル移動スクリプトです。
import os
import shutil
from pathlib import Path
def safe_print(*args, **kwargs):
sep = kwargs.get('sep', ' ')
end = kwargs.get('end', '\n')
msg = sep.join(str(a) for a in args)
try:
print(msg, end=end)
except UnicodeEncodeError:
print(msg.encode('cp932', errors='replace').decode('cp932'), end=end)
def get_category_from_metadata(file_path):
"""
ファイルのメタデータからcategoryプロパティを取得する
Parameters:
- file_path (Path): 対象ファイルのパス
Returns:
- str: categoryの値(存在しない場合はNone)
"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
if not content.strip().startswith('---'):
return None
parts = content.strip().split('---', 2)
if len(parts) < 2:
return None
metadata_str = parts[1]
metadata_lines = metadata_str.strip().split('\n')
for line in metadata_lines:
if line.strip().startswith('category:'):
# 次の行を取得(リスト形式の場合)
next_line = metadata_lines[metadata_lines.index(line) + 1].strip()
if next_line.startswith('- '):
# ダブルクオーテーションを除去
category = next_line[2:].strip().strip('"')
return category
return None
return None
except Exception as e:
safe_print(f"Error reading metadata from {file_path}: {e}")
return None
def get_target_directory(category):
"""
カテゴリーに対応する移動先ディレクトリを取得する
Parameters:
- category (str): カテゴリー名
Returns:
- str: 移動先ディレクトリのパス(カテゴリーが不明な場合はNone)
"""
category_mapping = {
'AI_テクノロジー': r'ディレクトリパス\01_AI_テクノロジー',
'科学_研究': r'ディレクトリパス\02_科学_研究',
'社会_文化': r'ディレクトリパス\03_社会_文化',
'ビジネス_キャリア': r'ディレクトリパス\04_ビジネス_キャリア',
'健康_医療': r'ディレクトリパス\05_健康_医療',
'その他': r'ディレクトリパス\06_その他'
}
return category_mapping.get(category)
def ensure_directory_exists(directory):
"""
ディレクトリが存在しない場合は作成する
Parameters:
- directory (str): ディレクトリのパス
"""
if not os.path.exists(directory):
os.makedirs(directory)
safe_print(f"Created directory: {directory}")
def move_file(file_path, target_dir):
"""
ファイルを移動する
Parameters:
- file_path (Path): 移動元ファイルのパス
- target_dir (str): 移動先ディレクトリのパス
"""
try:
# 移動先ディレクトリが存在しない場合は作成
ensure_directory_exists(target_dir)
# 移動先のパスを生成
target_path = os.path.join(target_dir, file_path.name)
# ファイルが既に存在する場合は、ファイル名に連番を付与
counter = 1
while os.path.exists(target_path):
name, ext = os.path.splitext(file_path.name)
target_path = os.path.join(target_dir, f"{name}_{counter}{ext}")
counter += 1
# ファイルを移動
shutil.move(str(file_path), target_path)
safe_print(f"Moved: {file_path.name} -> {target_path}")
except Exception as e:
safe_print(f"Error moving file {file_path}: {e}")
def process_directory(source_directory):
"""
指定されたディレクトリ内のすべてのMarkdownファイルを処理する
Parameters:
- source_directory (str): 処理対象のディレクトリパス
"""
# ディレクトリ内のすべての.mdファイルを取得
md_files = list(Path(source_directory).glob('**/*.md'))
total_files = len(md_files)
safe_print(f"Found {total_files} markdown files in {source_directory}")
# 各ファイルを処理
for i, file_path in enumerate(md_files, 1):
safe_print(f"\nProcessing file {i}/{total_files}: {file_path}")
# カテゴリーを取得
category = get_category_from_metadata(file_path)
if category is None:
safe_print(f"Skipping {file_path.name} - no category found")
continue
# 移動先ディレクトリを取得
target_dir = get_target_directory(category)
if target_dir is None:
safe_print(f"Skipping {file_path.name} - unknown category: {category}")
continue
# ファイルを移動
move_file(file_path, target_dir)
def main():
# 処理対象のディレクトリ
source_directory = r"ディレクトリパス\99_Raw"
if not os.path.isdir(source_directory):
safe_print(f"Source directory not found: {source_directory}")
return
safe_print(f"Starting file movement from: {source_directory}")
process_directory(source_directory)
safe_print("\nAll files processed.")
if __name__ == "__main__":
main()
プラグインを動かすまで
実際の使用フローは以下の通りです。
- クリッピングしたい記事のURLをクリップボードにコピーします
-
ReadItLaterのアイコンをクリック、未読ディレクトリにmdファイルが生成されます - 記事を読みます
- すべて読み終わったら、
AI Tagging & Summarizeのアイコンをクリックします、AIの処理を待ちます - 処理が終わると、ファイルのフロントマターに「tags」「category」「description」が自動で追記されます
-
Move by Categoryのアイコンをクリックします -
99_Rawフォルダ内のファイルが、設定されたカテゴリに基づいて適切なフォルダへ自動で移動します
記事を読むタイミングはまちまちで、タグ付け&要約の後に読むこともあります。
良い点と改善点
良い点
- 効率化
- 記事を読んだ上で行う情報整理が不要
- シンプルな操作
- 一度設定すれば、Obsidian上での操作はワンクリックで完了
改善点
- 初期設定の複雑さ
- Node.js, Python, APIキーなど、非エンジニアにとっては導入のハードルが高い
- リファクタ
- するべき箇所たくさん、でも動いてるからヨシ!
要約の功罪
AIに要約をやらせることで記事の概要を把握するのに役立つ一方で、要約を読んで満足してしまうこともあります。
私はショート動画によってポップコーン・ブレインになり、長文が読めなくなってしまっているのかもしれないと自覚し反省してます。
まとめ
手抜き記事でした![]()
自分の記事である、1クリックで知識をストック!Gemini API × Obsidianで実現する自分だけの単語帳の構成丸写しです。内容をちょいちょい変えただけでした。
この記事では、自作したObsidianプラグインの紹介を通じて、
- Obsidianのプラグイン作成
- 生成AIを趣味に活かした事例
- 情報整理の自動化
についてお話ししました。
自分だけのスクラップブックを作ることの何が楽しいのでしょうか。
理由としては、「◯◯みたいなことが書かれた記事を以前読んだよなぁ」と思い立ったときに、自分のスクラップブックを漁り記事を見つけ、ついでに周辺でヒットする記事も読み返して...みたいな感じで繋がりから情報を再学習していくことができるところです。
と、それっぽいことを書きましたが、実際はファイル群を眺めて「俺のスクラップブック、充実してきてるな!」 とニマニマするだけです。
また、ObisidianにはGraph Viewという機能があります。
mdファイルに書かれた内部リンクやタグを紐づけて可視化する機能です。
これを眺めて「ヘアーボールがどんどんごちゃごちゃになってるな!」とニマニマします。
まったく意味がないです。
でも 趣味ってそんなもんでいい じゃないですか。

この記事が、Obsidianの活用を進めていきたい方や、生成AIを自分の趣味に活用したい方にとって、何かしらのヒントになれば幸いです。