はじめに
VisasQ Inc. Advent Calendar 2025 1日目の記事です。お手柔らかにお願いいたします。
みなさまは本や漫画、WEB記事など、さまざまなメディアで自分の知らない単語に遭遇した際には何をしていますか?
もちろん単語の意味を調べて、単語帳にその意味を記載しますよね?
単語帳、作ってますよね?
私は自分だけの英単語帳と専門用語の単語帳を作っています。
この記事では私が作成した(バイブコーディングした)、生成AIを利用して単語帳作成の効率化ができる機能についてご紹介します。
アイコンを1クリックするだけで、起票した単語の意味やカテゴリーなどが自動で記入されるObsidianのプラグインです。
主なトピックとしては、
- Obsidianのプラグイン作成
- 生成AIを趣味に活かした事例
- ObsidianのBases機能
になります。
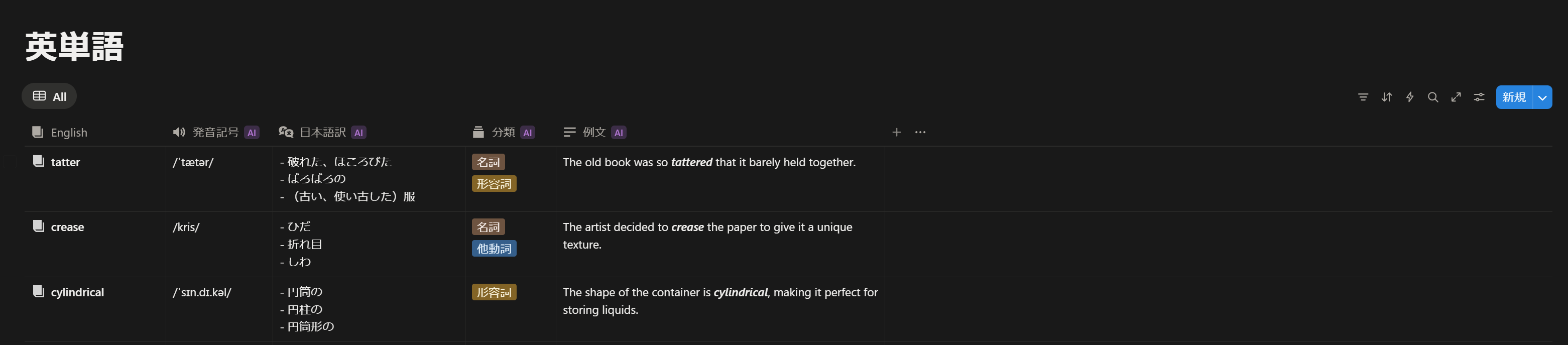
単語帳は以下のような感じです。


みなさまの単語帳作りの効率化の参考になれば幸いです。
(まあ、自分だけの単語帳を作るなんて趣味の人、そうはいないでしょうけどね…)
プラグインの目的と機能
単語帳を作成し始めた最初の頃は、単語を起票する作業が非常に煩雑でした。
単語の意味や発音記号、品詞、例文、単語の内容に基づいたカテゴリーなどの必要な情報を調べてコピペし、いい感じにまとめる作業はだるく、継続して起票していくのはなかなか大変です。
そこで去年からはNotionとNotionAIを利用して単語帳を作成していました。
単語を記入するだけで、あとは必要な情報が記載されていくようにしていました。
NotionAIは有料です。
年間契約で$105、当時のレートで15000円ぐらいでした。
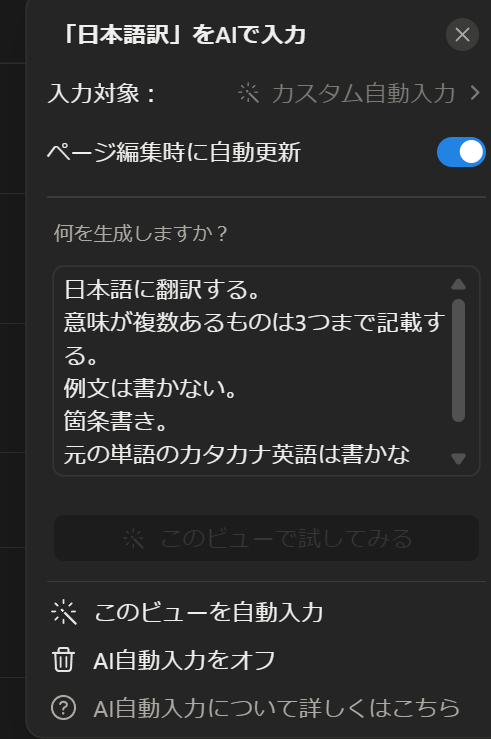
いろいろと遊んでみた後、契約が切れるタイミングでObsidianに乗り換えました。
これにあたりObsidian上でも同等の機能を実現できることを目指しました。
作成したプラグインは以下の2つです。
-
Vocabulary Updater- 特定フォルダ内にあるMarkdownのファイル名を英単語とみなし、Gemini APIを用いて「日本語訳」「発音記号」「品詞」「例文」を自動取得し、YAMLフロントマターに書き込みます
-
Term File Updater- 特定フォルダ内にあるMarkdownのファイル名を専門用語とみなし、Gemini APIを用いて「意味」「関連分野」「Wikipediaリンク」を自動取得し、YAMLフロントマターに書き込みます
両プラグインともに、Obsidianの左側に表示されるリボンアイコンをワンクリックで実行可能です。
わかってはいますが、AIに作らせてそれきりなので名前が超適当です。
vocabulary updater、term file updaterって名前、イマイチすぎる。
ツール
使用ツールは上記でも触れていますが、以下になります。
- Obsidian
- Gemini API
- Python
- Node.js
すべて無料です。
無料でAIを利用し趣味を楽しむことができるなんて、いい時代ですね。
Obsidian
https://obsidian.md/
Obsidianは、ローカルなMarkdownファイルをベースとした強力な知識管理ツールです。
その魅力の一つは、コミュニティプラグインによる無限の拡張性にありますが、時には自分のニッチな要求を満たすプラグインが見つからないこともあります。
この記事では、まさにそうした状況から生まれた自作プラグインの話になります。
Obsidianで自分だけの単語帳を作るのに不可欠な機能、それがBasesです。
ObsidianのBases機能は、Markdownファイル群を構造化されたデータベースのように扱うことができます。
これにより、ファイルの内容を一覧表示し、特定のプロパティ(YAMLフロントマターで定義されたキーと値のペア)に基づいてソート、フィルタリング、および表示をカスタマイズできます。
これを単語帳に応用すると、各単語のMarkdownファイルがデータベースのエントリ(≒レコード)となり、「単語」「日本語訳」「発音記号」「品詞」「例文」といったプロパティをBasesビューで直接管理・視覚化できます。
ちなみにこの機能は課金ユーザーに先行公開されたもので、一般ユーザーには2025/8/18に公開されました。
ありがとう!Obsidian!
Gemini API
https://ai.google.dev/gemini-api/docs?hl=ja
Googleのアカウントを持っていれば使えるAPIです。
プラグイン上で利用するモデルはgemini 2.5 flashです。
複雑な計算や推力を求めない機能なのでproである必要はありません。
無料で1日あたり250リクエストできます。つまり、1日に250単語まで起票できます。
1日に遭遇する未知の単語の数なんてたかが知れてるので十分な量です![]()
Python
https://www.python.org/
GeminiAPIを利用するロジックをPythonで書いているので必要になります。
GeminiAPIを利用できる使い勝手のよいライブラリがあれば、言語は何でもいいです。
Node.js
https://nodejs.org/ja
プラグインのJavaScriptがPythonスクリプトを呼び出すために、Node.jsのchildprocessを利用しています。
他
おそらく環境構築で多分いろいろインストールしてますが覚えてないので割愛。
プラグインの設計
アーキテクチャを設計する上で、「なぜObsidianプラグイン内で直接APIを叩かないのか?」 という点を考慮しました。
JavaScriptから直接APIを叩くことも可能ですが、今回は以下の理由から、処理のコアをPythonに委ねる構成を選択しました。
-
ライブラリの充実:
google-generativeaiという公式のPythonライブラリが非常に使いやすかった - 開発効率: 煩雑なAPIリクエストやデータ処理を、普段から使い慣れているPythonで迅速に実装したかった
-
関心の分離: Obsidianプラグイン(
main.js)はUIと処理のトリガーに徹し、実際のロジックはPythonスクリプトが担うことで、責務を明確に分離しました
…
らしいです。
上記の文章はGeminiにプラグインを分析させ書かせてみました![]()
実際は以下の通りです。
- とりあえずPythonでGeminiAPIを呼び出して、与えられた単語に対して必要な情報を返すスクリプト作ってみるかぁ
- 業務でPython使ってるしPythonでいっか
- どうせAIにコーディングさせるから何でもいいんだけどね
- (AI作成中…)
- できた!コマンドで呼び出してちゃんと動いた!
- で、これをもっと簡単に実行できるようにしたいなぁ、batファイルでも作るかな
- あ、Obsidianって自作のプラグインも入れられるのか、じゃあプラグインにしよ
- (AI作成中…)
- できた!Obsidianで読み込んだらアイコンも表示されてる!すごい!
つまり、設計方針は「行き当たりばったり」です。
そんな感じでできあがったプラグインは、以下の2つのコンポーネントで構成されています。
-
main.js(Obsidian Plugin)- ユーザーがリボンアイコンをクリック
- 処理の開始をObsidianの
Noticeで通知 - Node.jsの
child_processモジュールを使い、Pythonスクリプトをサブプロセスとして起動する - Vaultの絶対パスをPythonスクリプトに引数として渡す
- 処理の終了をObsidianの
Noticeで通知
-
update_vocabulary.py/update_term_files.py(Python Script)- 起動後、指定されたディレクトリ内のMarkdownファイルをスキャンする
- 処理対象のファイル(YAMLフロントマターの
単語:が空)を特定する - ファイル名から抽出した単語/用語を元に、Gemini APIに問い合わせる
- APIからJSON形式で返却された情報を受け取る
- 受け取った情報を元に新しいYAMLフロントマターを構築し、対象のファイルを書き換える
開発・実行環境
趣味用のPCはWindowsなので、Windowsで環境を作ります。
Obsidian
公式サイトからDL、インスコしましょう。
初期設定も済ませます。Vaultと呼ばれるフォルダを設定するぐらいです。
有志の方々がいろいろとまとめているWeb記事がたくさんあるはずです。
次にVault内に単語のファイルを保存するディレクトリを作成します。
私の場合、英単語帳と専門用語単語帳の2つのディレクトリを作りました。
Base(重要)
最後にBaseを作成します。これが単語帳の要です。
コマンドパレットを開き(Ctrl + P)、Create new baseを選択すると、BaseがVaultのルートディレクトリ内にできあがります。
作成初期の段階では、Vault内にあるファイルすべてが一覧で表示される状態になっています。これを調整します。
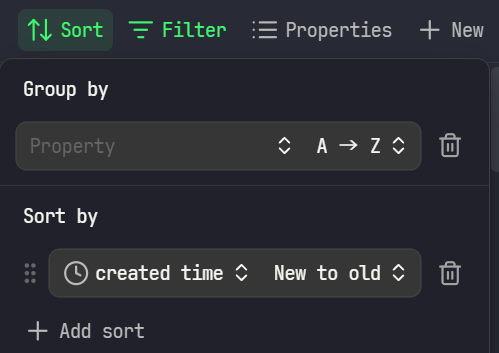
Sort
お好みで並び順を設定してください。
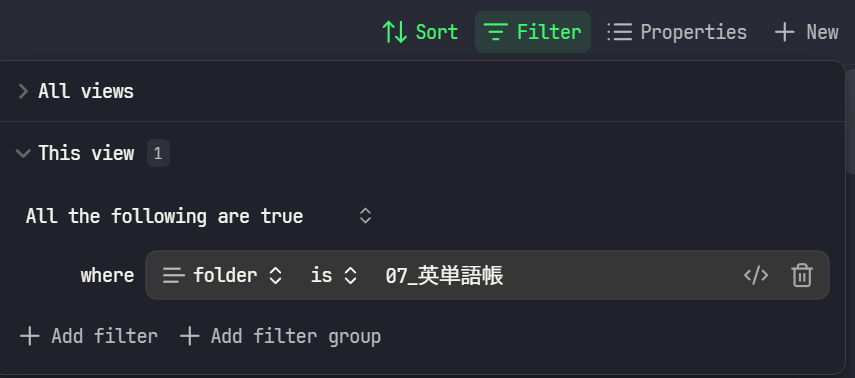
Filter
This viewのfilter条件として、All the following are trueで where folder is 単語帳のディレクトリ名と設定します。
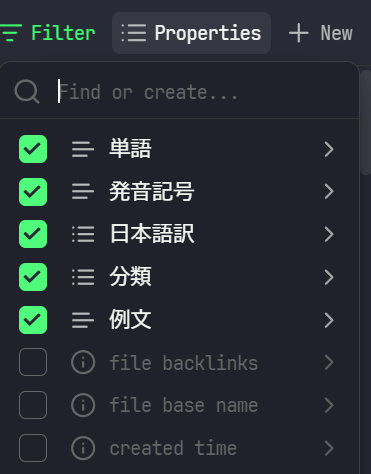
Properties
初期はfile nameのみにチェックが入っています。
これを自分好みに調整しましょう。
Propertiesを開いた際の一番下にあるAdd Formulaから自由にPropetyを追加できます。
Gemini API
Google AI StudioからGemini APIキーを取得します。これもやり方を書いたWeb記事がたくさんあります。
Vaultのルートに.envファイルを作成し、以下のようにキーを記述しました。
GEMINI_API_KEY="ここにAPIキーを書く"
Python
「Windows Python 環境構築」で検索して環境を作りましょう。
(私は3.13.5を使用しています)
必要なライブラリ
-
google-generativeai- Gemini APIと通信するための公式ライブラリ
-
python-dotenv- APIキーを安全に管理するため
以下のコマンドでインストールします。
pip install google-generativeai python-dotenv
pipもWindowsでのインストールのやり方を検索して入れておきましょう。
Node.js
これもWindowsでのインストールの仕方を調べて入れます。
(私はv22.17.0を使用しています)
ディレクトリ構成
私の場合は以下のようになりました。
Vault Root/
├── .env
├── update_vocabulary.py
├── update_term_files.py
├── 07_英単語帳/
│ ├── (英単語のMarkdownファイル群)
├── 08_単語帳/
│ ├── (専門用語のMarkdownファイル群)
└── .obsidian/
└── plugins/
├── vocabulary-updater/
│ ├── main.js
│ └── manifest.json
└── term-file-updater/
├── main.js
└── manifest.json
コーディングの詳細
開発は全部生成AIに書かせました。多分gemini CLIを使ったはず。
どういうプロンプトを書いたかはもう覚えてません。
Vocabulary Updater(英単語のほう)
main.js
プラグインのエントリーポイントです。child_processを使ってPythonスクリプトを呼び出します。
'use strict';
const obsidian = require('obsidian');
const child_process = require('child_process');
const path = require('path');
class VocabularyUpdaterPlugin extends obsidian.Plugin {
async onload() {
// Add a ribbon icon
this.addRibbonIcon('refresh-cw', 'Update vocabulary files', () => {
this.runUpdateScript();
});
// Add a command to the palette
this.addCommand({
id: 'update-vocabulary-files',
name: 'Update vocabulary files',
callback: () => this.runUpdateScript()
});
}
runUpdateScript() {
const vaultPath = this.app.vault.adapter.getBasePath();
const scriptPath = path.join(vaultPath, 'update_vocabulary.py');
new obsidian.Notice('Vocabulary update started...');
const pythonCommand = 'python';
const process = child_process.spawn(pythonCommand, [scriptPath]);
let output = '';
process.stdout.on('data', (data) => {
console.log(`stdout: ${data}`);
output += data.toString();
});
let errorOutput = '';
process.stderr.on('data', (data) => {
console.error(`stderr: ${data}`);
errorOutput += data.toString();
});
process.on('close', (code) => {
if (code === 0) {
new obsidian.Notice('Vocabulary update finished successfully!');
console.log('Vocabulary update script finished successfully.');
} else {
new obsidian.Notice('Vocabulary update failed. Check the developer console for errors.');
console.error(`Vocabulary update script exited with code ${code}`);
console.error('Error output:', errorOutput);
}
});
process.on('error', (err) => {
new obsidian.Notice('Failed to start the update script. Is Python installed and in your PATH?');
console.error('Failed to start subprocess.', err);
});
}
}
module.exports = VocabularyUpdaterPlugin;
manifest.json
{
"id": "vocabulary-updater",
"name": "Vocabulary Updater",
"version": "1.0.0",
"minAppVersion": "0.12.0",
"description": "Updates vocabulary files by running a Python script.",
"author": "Gemini",
"authorUrl": "",
"isDesktopOnly": true
}
update_vocabulary.py
AIへの問い合わせとファイル更新を行うメインロジックです。
特に、AIに意図通りの形式(JSON)で出力させるためのプロンプトが重要です。
プロンプトもAIに作らせましょう。確かClaudeに作らせたような気がします。
import os
import glob
import json
import time
import google.generativeai as genai
from dotenv import load_dotenv
# .envファイルを読み込む
load_dotenv()
api_key = os.getenv("GEMINI_API_KEY")
if not api_key:
raise ValueError("GEMINI_API_KEYが.envファイルに見つかりません。")
genai.configure(api_key=api_key)
model = genai.GenerativeModel('gemini-2.5-flash')
def get_word_info_from_ai(word):
"""AIを使用して単語の情報を取得する"""
print(f"AIで単語情報を検索中: {word}")
prompt = f"""英単語 '{word}' について、以下の情報を調べてJSON形式で返してください。
- 日本語訳 (japanese_translations): 最大3つの一般的な訳語をリストで。
- 発音記号 (pronunciation): IPA(国際音声記号)で。
- 品詞 (part_of_speech): 最も一般的な品詞を1つ (例: \"名詞\", \"動詞\")。
- 例文 (example_sentence): その単語を使った簡単な英語の例文と、その日本語訳。
JSON以外の余計な説明は含めないでください。
例:
{{
"japanese_translations": ["例", "見本"],
"pronunciation": "/ɪɡˈzæmpəl/",
"part_of_speech": "名詞",
"example_sentence": {{ "en": "This is an example.", "ja": "これは一例です。" }}
}}
"""
try:
response = model.generate_content(prompt)
# レスポンスからJSON部分を抽出する
json_text = response.text.strip().replace("```json", "").replace("```", "").strip()
info = json.loads(json_text)
return info
except Exception as e:
print(f"AIからの情報取得中にエラーが発生しました ({word}): {e}")
return None
def main(directory):
"""
指定されたディレクトリ内のすべてのMarkdownファイルを処理する。
"""
markdown_files = glob.glob(os.path.join(directory, '*.md'))
for filepath in markdown_files:
try:
with open(filepath, 'r', encoding='utf-8') as f:
content = f.read()
lines = content.split('\n')
is_target = False
# YAMLフロントマター内で `単語:` の値が空かチェック
in_front_matter = False
for line in lines:
if line.strip() == '---':
in_front_matter = not in_front_matter
continue
if in_front_matter and line.strip().startswith('単語:'):
if len(line.split(':')) < 2 or not line.split(':')[1].strip():
is_target = True
break # 単語キーを見つけたらチェック終了
if is_target:
filename = os.path.basename(filepath)
word = os.path.splitext(filename)[0]
print(f"処理中のファイル: {filename}")
info = get_word_info_from_ai(word)
time.sleep(5) # APIのレート制限を考慮
if info:
translations = '\n'.join([f" - {t}" for t in info.get('japanese_translations', [])])
pronunciation = info.get('pronunciation', '')
pos = info.get('part_of_speech', '')
example_en = info.get('example_sentence', {}).get('en', '')
example_ja = info.get('example_sentence', {}).get('ja', '')
example_str = f"{example_en} ({example_ja})" if example_en and example_ja else example_en
new_content = f"""---
単語: {word}
日本語訳:
{translations}
発音記号: {pronunciation}
分類:
- {pos}
例文: {example_str}
---
"""
with open(filepath, 'w', encoding='utf-8') as f:
f.write(new_content)
print(f"更新完了: {filename}")
else:
print(f"スキップ(情報取得失敗): {filename}")
# else:
# print(f"スキップ(処理不要): {os.path.basename(filepath)}")
except Exception as e:
print(f"ファイル処理中にエラー: {os.path.basename(filepath)} - {e}")
if __name__ == "__main__":
# 対象ディレクトリを固定
target_directory = "英単語帳のディレクトリのフルパスをここに書く"
if os.path.isdir(target_directory):
main(target_directory)
else:
print(f"エラー: ディレクトリが見つかりません {target_directory}")
Term File Updater(専門用語のほう)
上記のVocabulary Updaterとほぼ一緒ですが、一応全部記載しておきます。
main.js
'use strict';
const obsidian = require('obsidian');
const child_process = require('child_process');
const path = require('path');
class TermFileUpdaterPlugin extends obsidian.Plugin {
async onload() {
// Add a ribbon icon
this.addRibbonIcon('book-text', 'Update term files', () => {
this.runUpdateScript();
});
// Add a command to the palette
this.addCommand({
id: 'update-term-files',
name: 'Update term files',
callback: () => this.runUpdateScript()
});
}
runUpdateScript() {
const vaultPath = this.app.vault.adapter.getBasePath();
const scriptPath = path.join(vaultPath, 'update_term_files.py');
new obsidian.Notice('Term file update started...');
const pythonCommand = 'python';
const process = child_process.spawn(pythonCommand, [scriptPath]);
process.stdout.on('data', (data) => {
console.log(`stdout: ${data}`);
});
let errorOutput = '';
process.stderr.on('data', (data) => {
console.error(`stderr: ${data}`);
errorOutput += data.toString();
});
process.on('close', (code) => {
if (code === 0) {
new obsidian.Notice('Term file update finished successfully!');
console.log('Term file update script finished successfully.');
} else {
new obsidian.Notice('Term file update failed. Check console.');
console.error(`Term file update script exited with code ${code}`);
console.error('Error output:', errorOutput);
}
});
process.on('error', (err) => {
new obsidian.Notice('Failed to start the update script. Is Python installed?');
console.error('Failed to start subprocess.', err);
});
}
}
module.exports = TermFileUpdaterPlugin;
manifest.json
{
"id": "term-file-updater",
"name": "Term File Updater",
"version": "1.0.0",
"minAppVersion": "0.12.0",
"description": "Updates term files by running a Python script.",
"author": "Gemini",
"authorUrl": "",
"isDesktopOnly": true
}
update_term_files.py
import os
import sys
import glob
import json
import time
import google.generativeai as genai
from dotenv import load_dotenv
# .envファイルを読み込む
load_dotenv()
api_key = os.getenv("GEMINI_API_KEY")
if not api_key:
raise ValueError("GEMINI_API_KEYが.envファイルに見つかりません。")
genai.configure(api_key=api_key)
model = genai.GenerativeModel('gemini-2.5-flash')
def get_term_info_from_ai(term):
"""AIを使用して専門用語の情報を取得する"""
print(f"AIで用語情報を検索中: {term}")
prompt = f"""専門用語 '{term}' について、以下の情報を調べてJSON形式で返してください。
- 意味 (meaning): 250文字程度で簡潔な説明。文末表現は常体。
- 分類 (fields): この用語が関連する学問分野を最大3つ、リストで。
- wikipedia (wikipedia_url): 日本語版Wikipediaの記事が存在する場合、そのURL。存在しない場合は空文字列("")。
JSON以外の余計な説明は含めないでください。
例:
{{
"meaning": "コンピュータが自ら学習し、データからパターンやルールを見つけ出す技術の一分野。",
"fields": ["情報工学", "人工知能", "統計学"],
"wikipedia_url": "https://ja.wikipedia.org/wiki/機械学習"
}}
"""
try:
response = model.generate_content(prompt)
# レスポンスからJSON部分を抽出する
json_text = response.text.strip().replace("```json", "").replace("```", "").strip()
info = json.loads(json_text)
return info
except Exception as e:
print(f"AIからの情報取得中にエラーが発生しました ({term}): {e}")
return None
def main(directory):
"""
指定されたディレクトリ内のすべてのMarkdownファイルを処理する。
"""
markdown_files = glob.glob(os.path.join(directory, '*.md'))
for filepath in markdown_files:
try:
with open(filepath, 'r', encoding='utf-8') as f:
content = f.read()
lines = content.split('\n')
is_target = False
# YAMLフロントマター内で `単語:` の値が空かチェック
in_front_matter = False
for line in lines:
if line.strip() == '---':
in_front_matter = not in_front_matter
continue
if in_front_matter and line.strip().startswith('単語:'):
if len(line.split(':')) < 2 or not line.split(':')[1].strip():
is_target = True
break
if is_target:
filename = os.path.basename(filepath)
term = os.path.splitext(filename)[0]
print(f"処理中のファイル: {filename}")
info = get_term_info_from_ai(term)
time.sleep(5) # APIのレート制限を考慮
if info:
meaning = info.get('meaning', '').strip()
fields = '\n'.join([f" - {f}" for f in info.get('fields', [])])
wiki_url = info.get('wikipedia_url', '')
new_content = f"""---
単語: {term}
意味: {meaning}
分類:
{fields}
wikipedia: {wiki_url}
---
"""
with open(filepath, 'w', encoding='utf-8') as f:
f.write(new_content)
print(f"更新完了: {filename}")
else:
print(f"スキップ(情報取得失敗): {filename}")
# else:
# print(f"スキップ(処理不要): {os.path.basename(filepath)}")
except Exception as e:
print(f"ファイル処理中にエラー: {os.path.basename(filepath)} - {e}")
if __name__ == "__main__":
# 対象ディレクトリを固定
target_directory = "単語帳のディレクトリのフルパスをここに書く"
if os.path.isdir(target_directory):
main(target_directory)
else:
print(f"エラー: ディレクトリが見つかりません {target_directory}")
プラグインを動かすまで
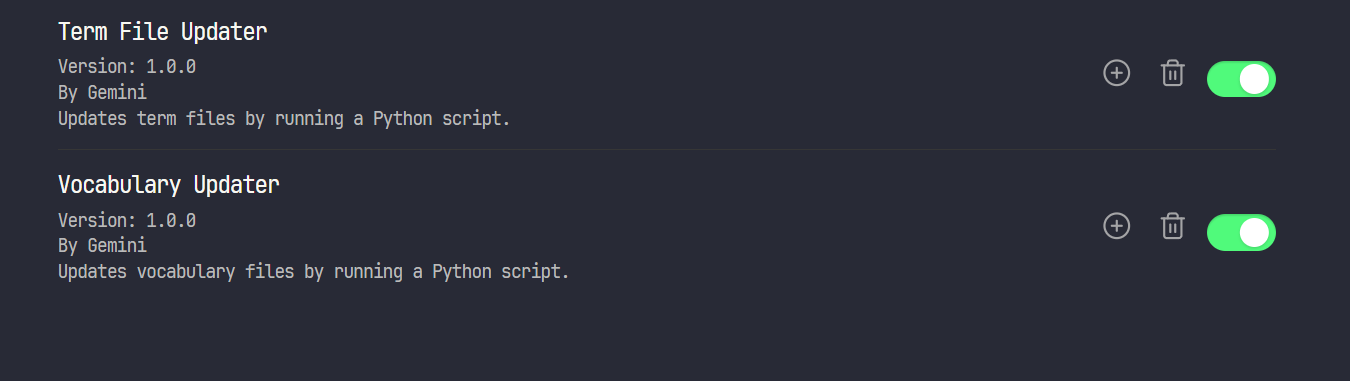
プラグインは左下の歯車アイコン -> Community plugins内に表示されているはずです。
表示されない場合はObisidianを再起動してみてください。
使用フロー
実際の使用フローはシンプルです。
-
作成したBaseを開き、右上にある
+Newボタンをクリックします -
起票する単語を記入し、入力モーダルの外側をクリックします
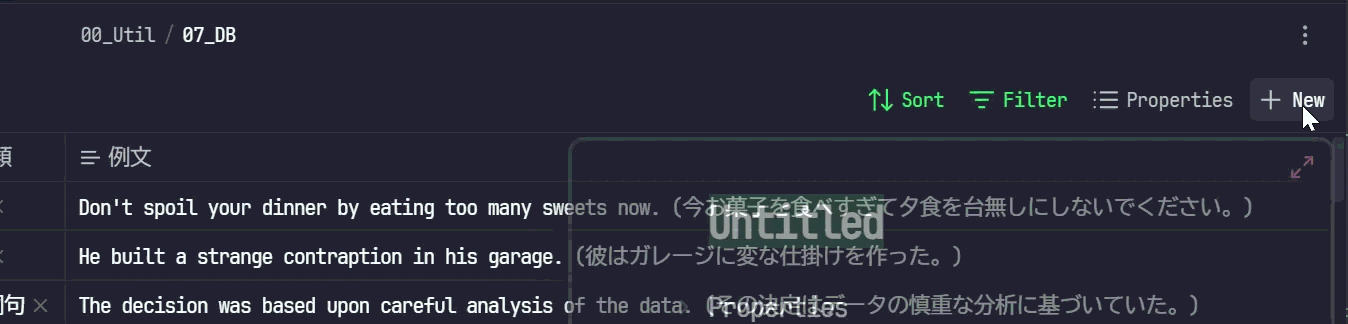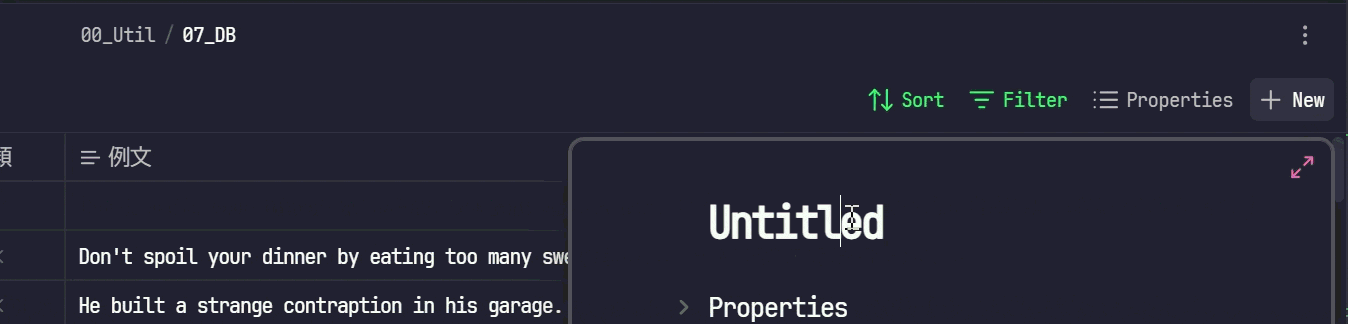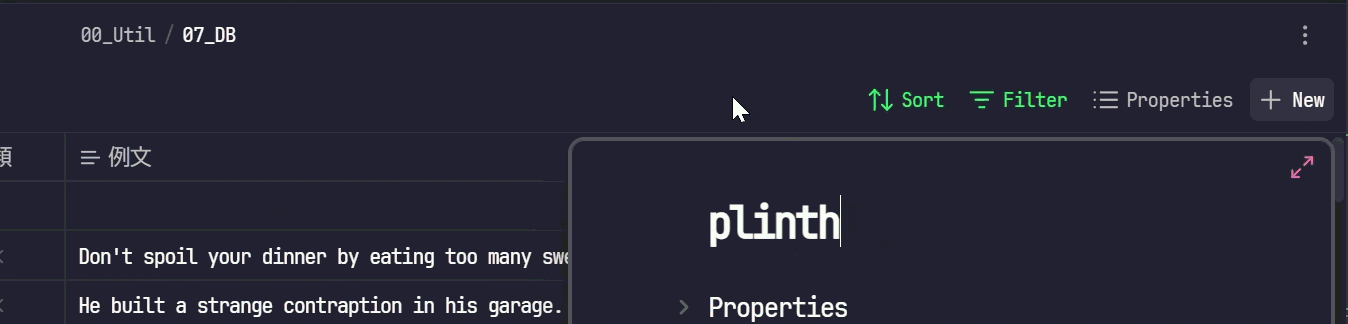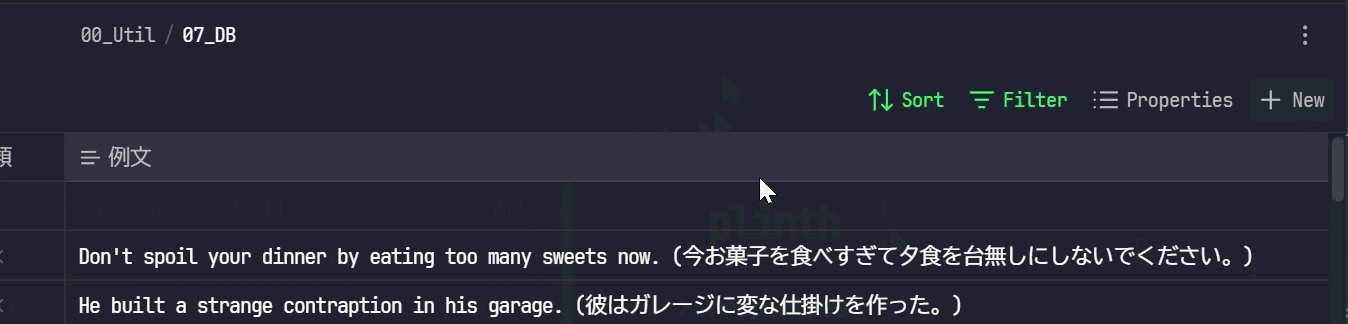
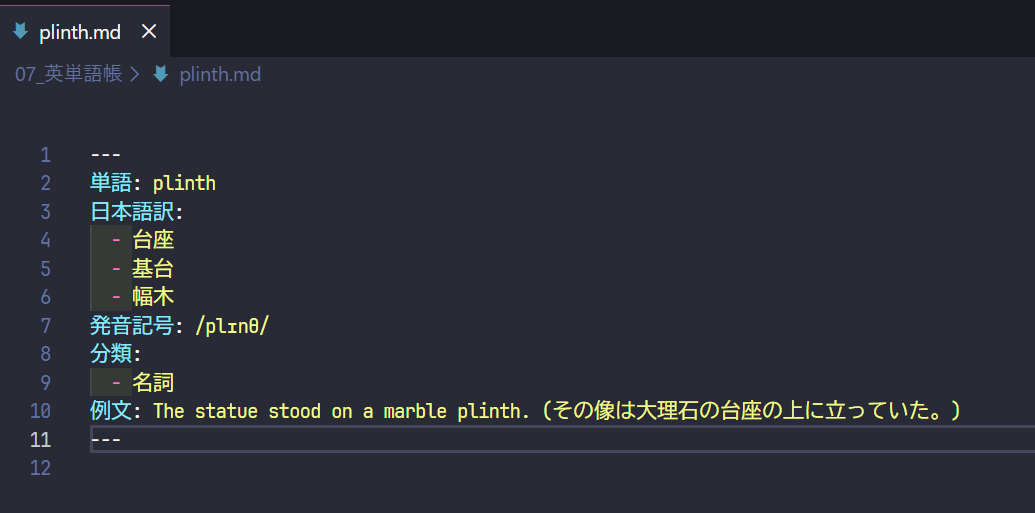
- これでmdファイルが作成されます。中身は以下のようにBaseのPropertiesに設定したPropertyがYAMLのフロントマターとして記載されます。

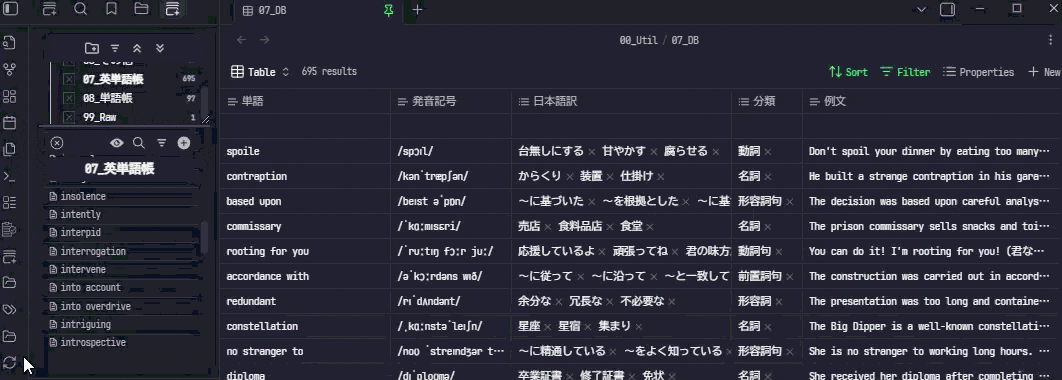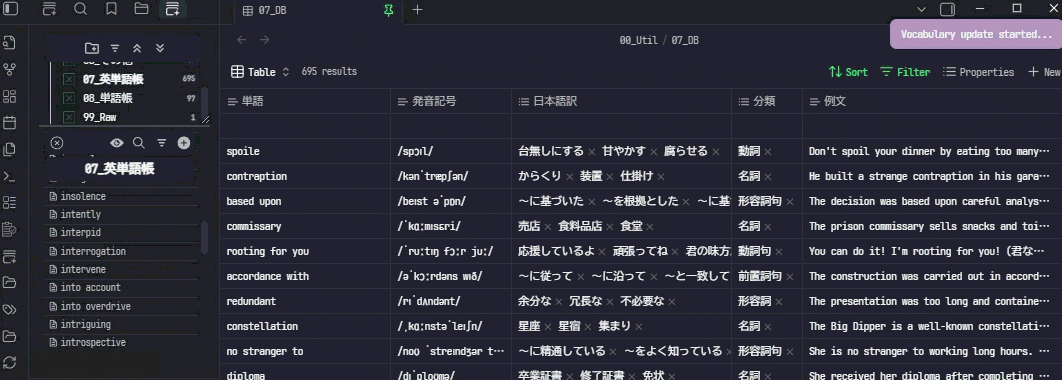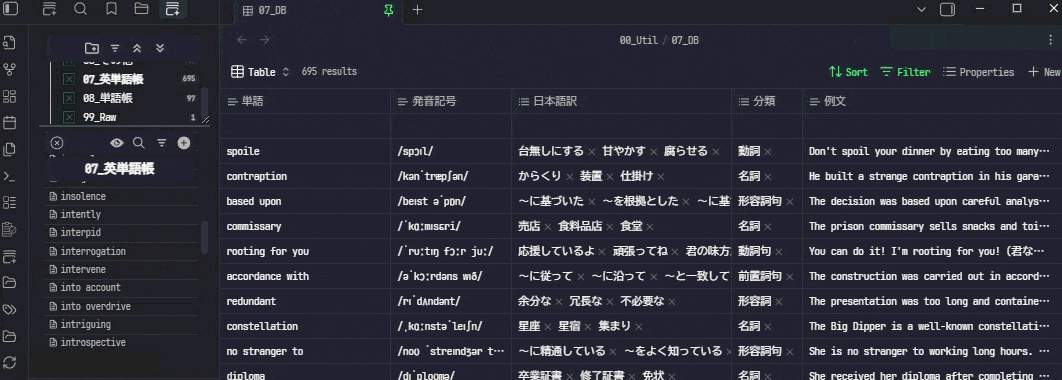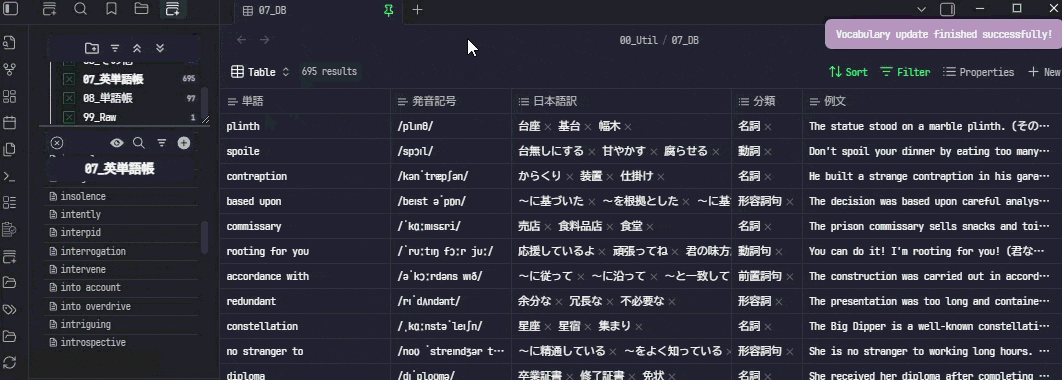
3. Obsidianの左側にあるリボンメニューからアイコンをクリックします
4. 10秒ぐらい待つと処理が終わり、単語の内容が記入されます。
1.2.の処理を繰り返し、ある程度未記入の単語を貯めておいて、一括で処理させることもできます。
また、単語が被っている場合は2.のところでエラーになります。
これは当たり前のことで、同じディレクトリ内に同じ名前のファイルを作成できないというだけです。
これによって以前起票したものを再度起票していることに気付き、復習の機会が生まれます。
良い点と改善点
良い点
- 効率化
- 煩わしい手動での検索・入力作業が不要
- シンプルな操作
- 一度設定すれば、Obsidian上での操作はワンクリックで完了
改善点
- 初期設定の複雑さ
- Node.js, Python, APIキーなど、非エンジニアにとっては導入のハードルが高い
- リファクタ
- するべき箇所たくさん、でも動いてるからヨシ!
まとめ
この記事では、自作したObsidianプラグインの紹介をすることで、
- Obsidianのプラグイン作成
- 生成AIを趣味に活かした事例
- ObsidianのBases機能
についてお話ししました。
英単語帳については、英語の勉強として単語帳を読み返したり、例文を音読したりして地道に単語の定着を目指しています。
また、このデータをさらに活用することも検討しています。
現状考えているのは、例文の日本語訳文読み上げ -> 数秒待つ -> 英語例文読み上げ、といった音声ファイルを作成することです。
日本語訳文を聞き脳内で英作文を作成、英語例文を聞くといった、英作文トレーニングができるかなと思っています。
また、このデータをもとに自分だけの英単語アプリ(Android)も作ってみたいなとも思っています。
専門用語の単語帳については、単語帳を眺めて「俺の単語帳、充実してきてるな!」 とニマニマします。それだけです。
これが実生活で活きることはないですね。
以上、趣味のお話でした。
この記事が、Obsidianの活用を進めていきたい方や、生成AIを自分の趣味に活用したい方にとって、何かしらのヒントになれば幸いです。