この記事は、シリーズ物です。
初回、 pandasチュートリアル1
前回、 pandasチュートリアル2
目標
前回は、データフレームの中身の確認方法を学びました。
今回は、欠損の扱いと集計、イテレーションについて学びましょう!
1、準備
前回同様paiza.IO (パイザ・アイオー)を開き、使用言語をしてPython3を選びましょう。
2、練習
i: 欠損の扱い
欠損状態の確認
DataFrameとして、チュートリアル1で作成した上場投信-トピックス("jp.stock.1305")、ソフトバンクグループ("jp.stock.9984")を使用しましょう。またあえて欠損を生むために、チュートリアル2で学んだ「指定条件からの行・列抽出」を使用します。
isnull
isnullメソッドを使用することで、欠損データの有無を、bool値(True, False)で確認することができます。
############################### チュートリアル1と同じ部分###############################
import pandas as pd
# DataFrameの作成
cp = {"jp.stock.1305":[1640.0, 1635.0, 1628.0, 1647.0, 1646.0],
"jp.stock.9984":[5152.5, 5099.0, 5027.0, 5201.0, 5165.0]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
############################### チュートリアル1と同じ部分###############################
# チュートリアル2で学んだ条件抽出
df_mod = df[df > 1635]
print(df_mod)
# isnull
print(df_mod.isnull())
 出力を確認してみましょう。df_modにてNaNであった、"jp.stock.1305"の2019-6-25, 2019-6-26のデータが、isnullメソッドによって、Trueとして返されていることが確認できますね。また、NaNでなかったデータは全てFalseで返されます。
出力を確認してみましょう。df_modにてNaNであった、"jp.stock.1305"の2019-6-25, 2019-6-26のデータが、isnullメソッドによって、Trueとして返されていることが確認できますね。また、NaNでなかったデータは全てFalseで返されます。
欠損の削除や置き換え
次に、欠損の削除と穴埋めについて学びましょう。
dropna, fillna
dropnaメソッドで、NaNを含む行の削除、fillnaメソッドで、NaNの他の値による補完ができます。
fillnaメソッドでは、補完の際に引用する値を、引数のmethodとして渡すことができます。
- method='ffill'で直前の値を使用(forward fill)
- method='bfill'で直後の値を使用(backward fill)
ここでは'ffill'を使用してみましょう。
############################### チュートリアル2と同じ部分###############################
import pandas as pd
# DataFrameの作成
cp = {"jp.stock.1305":[1640.0, 1635.0, 1628.0, 1647.0, 1646.0],
"jp.stock.9984":[5152.5, 5099.0, 5027.0, 5201.0, 5165.0]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
############################### チュートリアル2と同じ部分###############################
# チュートリアル2で学んだ条件抽出
df_mod = df[df > 1635]
print(df_mod)
# dropna, fillna
print(df_mod.dropna())
print(df_mod.fillna(method='ffill'))

まずdrponaメソッドによって、もともとNaNを含んでいた、2019-06-26, 2019-06-27の行を削除することができでいます。
またfillnaメソッドにより、もともとNaNであった部分を、その直前の2019-06-24の値である1640.0を使用し、補完することができていますね。
ii: 集計
diff, rolling
前行との差分が欲しい時は、diffメソッドを使用します。これによって、今回の株価データでは、行が日単位で入っているので、diffメソッドによって、前日との差分を算出することができます。(前日との差分を算出するため、初日はNaNとなります。)
複数日にまたがって値の集計を行いたいときは、rollingメソッドを使用します。ここでは、3日間の移動平均を求めてみましょう。
rollingメソッドでは、引数center=Falseで、Windowの最後の日を基準に、最後の位置に算出されたデータが格納されます。(3日平均であれば、前々日、前日、当日の平均を、当日のセルに記入)
引数center=Trueとすると、Windowの中心位置に算出されたデータが格納されます。(3日平均であれば、前日、当日、翌日の平均を、当日のセルに記入)
移動平均線などを用いる際には、当日に至るまでの移動平均を算出したいので、center=Falseを用いて練習をしておきましょう!(前々日、前日、当日の平均を算出するため、初日と2日目はNaNとなります。)
############################### チュートリアル2と同じ部分###############################
import pandas as pd
# DataFrameの作成
cp = {"jp.stock.1305":[1640.0, 1635.0, 1628.0, 1647.0, 1646.0],
"jp.stock.9984":[5152.5, 5099.0, 5027.0, 5201.0, 5165.0]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
############################### チュートリアル2と同じ部分###############################
print(df)
print(df.diff())
print(df.rolling(window=3).mean())

diffメソッドにより前日との差分を、rollingメソッドにより3日間平均を算出することができました。
例として"jp.stock.1305"の2019-06-28の値をみてみましょう。diffメソッドでは、前日06-27の値である1647.0と当日の1646.0の差分である、-1.0が算出されています。rollingメソッドでは、2019-06-26~2019-06-28までの3日間の平均値が算出されていますね。
iii: イテレーション
さあ、最後に学ぶのがイテレーションです。
イテレーションとは、「反復、繰り返し」の意味で、pandasでは、itemsメソッドとiterrowメソッドが便利です。
itemsメソッドでは列ごとに、iterrowメソッドでは行ごとにデータを取得します。
items
############################### チュートリアル2と同じ部分###############################
import pandas as pd
# DataFrameの作成
cp = {"jp.stock.1305":[1640.0, 1635.0, 1628.0, 1647.0, 1646.0],
"jp.stock.9984":[5152.5, 5099.0, 5027.0, 5201.0, 5165.0]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
############################### チュートリアル2と同じ部分###############################
for (sym, val) in df.items():
print(sym)
print(val)

itemsメソッドでは、column名(銘柄名)と、そのcolumn内の値をシリーズで返します。ここでは、(sym, val)と2変数を与えることで、column名(銘柄名)をsymとして、column内のシリーズをvalとして、取得できるようにしています。
これによって、実際に株の売買を行うときに、「もしval内の値が〜であったら、symの銘柄を買う」といった操作が簡単に行えるようになるのです!
iterrow
############################### チュートリアル2と同じ部分###############################
import pandas as pd
# DataFrameの作成
cp = {"jp.stock.1305":[1640.0, 1635.0, 1628.0, 1647.0, 1646.0],
"jp.stock.9984":[5152.5, 5099.0, 5027.0, 5201.0, 5165.0]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
############################### チュートリアル2と同じ部分###############################
for (date, val) in df.iterrows():
print(sym)
print(val)
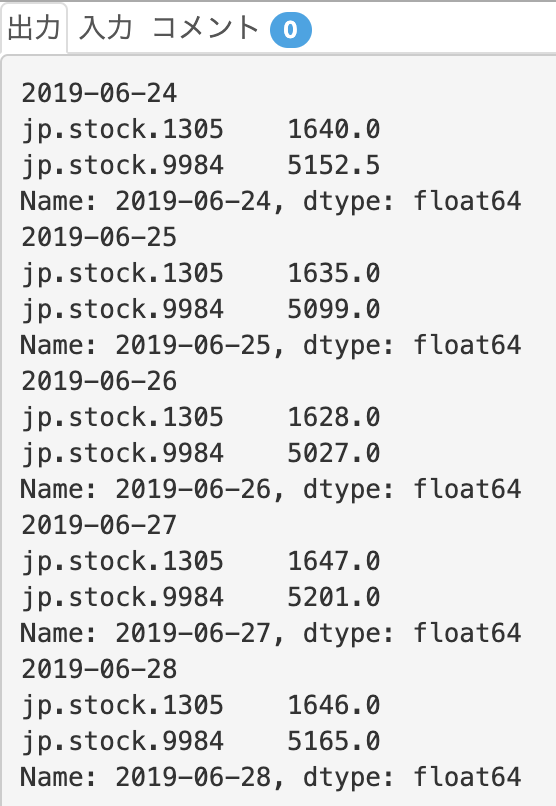
iterrowsメソッドでは、index名(日付)と、そのindex内の値をシリーズで返します。itemsメソッドと同様に、(date, val)の2変数を与えることで、日付と日付ごとの株価を取得できています。!
3、Quiz
さあ、今回もチュートリアル1のデータを使用して、学んだことをチェックしてみましょう。
(あえて欠損値を生むために操作を加えています。)
import pandas as pd
cp = {"jp.stock.7201":[767, 764, 761, 778, 772],
"jp.stock.9983":[66530, 66090, 65400, 65390, 65130]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
df_mod = df[df > 765]
1、上のコードをそのままpaiza.IOへcopy & pasteしてください。
2、以下の項目の確認を、今回のチュートリアルを参考に行ってみてください。
i. df_modの欠損値の有無確認
ii. df_modの欠損値の穴埋め(ffill)
iii. 穴埋めしたものについて、前行との差分を算出
iv. 穴埋めしたものについて、3日間の移動平均
v. 穴埋めしたものについて、イテレーションを用い、銘柄と、その銘柄の株価シリーズを取得
出力結果がこちら! どうだったでしょうか!続いての記事がこちら
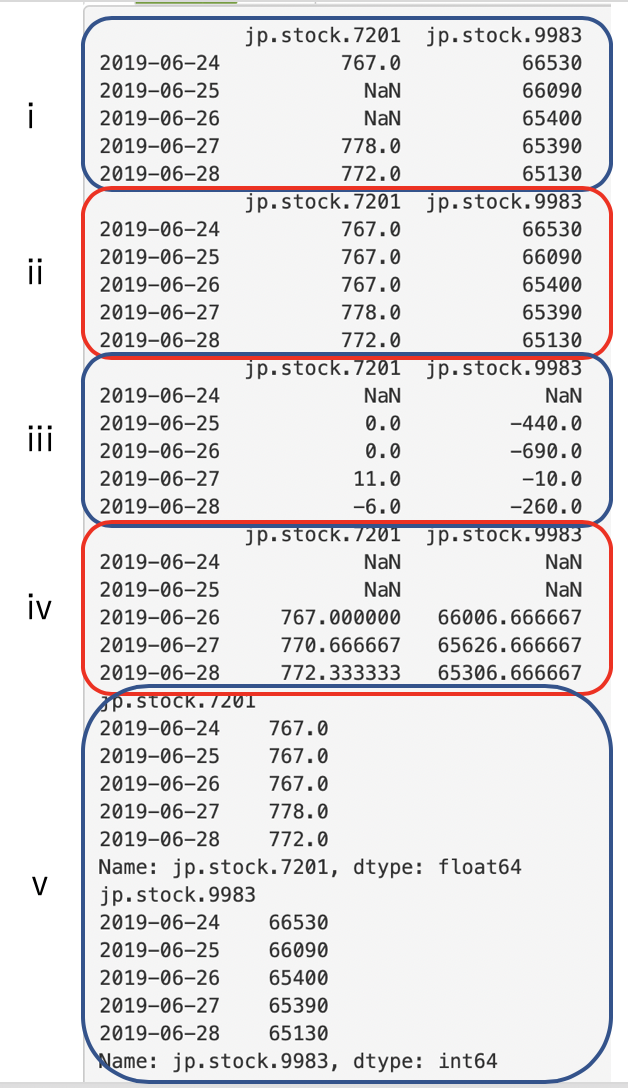
解答
import pandas as pd
cp = {"jp.stock.7201":[767, 764, 761, 778, 772],
"jp.stock.9983":[66530, 66090, 65400, 65390, 65130]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
df_mod = df[df > 765]
print(df_mod)
print(df_mod.fillna(method='ffill'))
print(df_mod.fillna(method='ffill').diff())
print(df_mod.fillna(method='ffill').rolling(window=3,center=False).mean())
for (sym, val) in df_mod.fillna(method='ffill').items():
print(sym)
print(val)