この記事は、シリーズ物です。
前回のものがこちら: pandasチュートリアル1
目標
前回は、シリーズ、データフレームの2つのデータ構造を学びました。
今回は、前回作成したデータフレームを用いて、データの中身確認と、簡単な操作の練習をしましょう。
1、準備
前回同様paiza.IO (パイザ・アイオー)を開き、使用言語をしてPython3を選びましょう。
2、練習
i: index, columns, shape
Pandasにおけるデータ構造DataFrameにはデータをラベリングするindex名とcolumn名が存在します。
前回作成したDataFrameではこちらになります。

今回は、まずDataFrameから、このindex名とcolumns名を取得することを学びましょう。DataFrameとして、前回作成した上場投信-トピックス("jp.stock.1305")、ソフトバンクグループ("jp.stock.9984")の終値データを使用しましょう。
index名, columns名はそれぞれ、取得したいデータに対し、.index, .columnsを追加することで取得できます。取得したいデータの名前が、dfである場合は
- df.index
- df.columns
となります。
また、行数、列数をタプル(行数, 列数)の形で取得できるのが、shape属性です。
- df.shape
によって、対象とするデータの行数、列数を取得します。
############################### チュートリアル1と同じ部分###############################
import pandas as pd
# DataFrameの作成
cp = {"jp.stock.1305":[1640.0, 1635.0, 1628.0, 1647.0, 1646.0],
"jp.stock.9984":[5152.5, 5099.0, 5027.0, 5201.0, 5165.0]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
############################### チュートリアル1と同じ部分###############################
# indexの取得
index = df.index
print(index)
# columnsの取得
columns = df.columns
print(columns)
# shapeの取得
shape = df.shape
print(shape)
出力はどうなっているでしょうか。

index名として日付を、columns名として銘柄コードを無事に取得できています!
また、行数、列数を(5, 2)とタプル形式で取得できました!
ii: 抽出
単純な抽出
-
列の抽出
column名を指定して、特定の列を抽出できます。 -
行の抽出
: (コロン) で行番号を指定することで、特定の区間の行を抽出できます。行番は 0 行目から始まる点に注意しましょう。
############################### チュートリアル1と同じ部分###############################
import pandas as pd
# DataFrameの作成
cp = {"jp.stock.1305":[1640.0, 1635.0, 1628.0, 1647.0, 1646.0],
"jp.stock.9984":[5152.5, 5099.0, 5027.0, 5201.0, 5165.0]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
############################### チュートリアル1と同じ部分###############################
print(df["jp.stock.1305"])
print(df[1:3])
print(df["jp.stock.1305"])で、"jp.stock.1305"の列を取得します。
print(df[1:3])で、1行目〜2行目の行を取得します。(注:pythonのスライス(:を用いて、シーケンスの一部分を切り取ってコピーを返してくれる仕組み)では、終点(ここで言う[1:3]の3)は、結果に含まれません)
出力をみてみましょう。
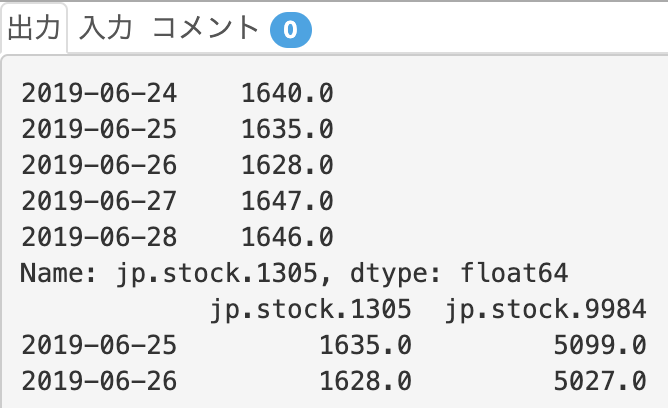
前半では、"jp.stock.1305"の列を抽出しています。
後半では、データ全体の1行目〜2行目("2019-06-25", "2019-06-26")を取得できていますね。
詳細な抽出
loc: ラベルに基づいて(つまりindex名、column名)特定の行・列抽出できます。
例 - df.loc[["2019-06-24"], ["jp.stock.1305"]]
iloc: 行や列の位置に基づいて行・列を取得することができます。
例 - df.iloc[[0], [0]
ix: 両方で指定可能です。
例 - df.ix[[0], ["jp.stock.1305"]]
############################### チュートリアル1と同じ部分###############################
import pandas as pd
# DataFrameの作成
cp = {"jp.stock.1305":[1640.0, 1635.0, 1628.0, 1647.0, 1646.0],
"jp.stock.9984":[5152.5, 5099.0, 5027.0, 5201.0, 5165.0]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
############################### チュートリアル1と同じ部分###############################
print(df.loc[["2019-06-24"], ["jp.stock.1305"]])
print(df.iloc[[0], [0]])
print(df.ix[[0], [0]])
print(df.ix[[0], ["jp.stock.1305"]])
print(df.ix[["2019-06-24"], ["jp.stock.1305"]])
# 複数のインデックスを指定する場合は以下のようにすれば良い
print(df.ix[:, [0]]) # 全て
print(df.ix[1:5, [0]]) # 範囲指定
print(df.ix[1:5]) # indexのみの指定
出力結果は以下の通りです。
index, column名やそれぞれの番号に従って、データを抽出することができました。
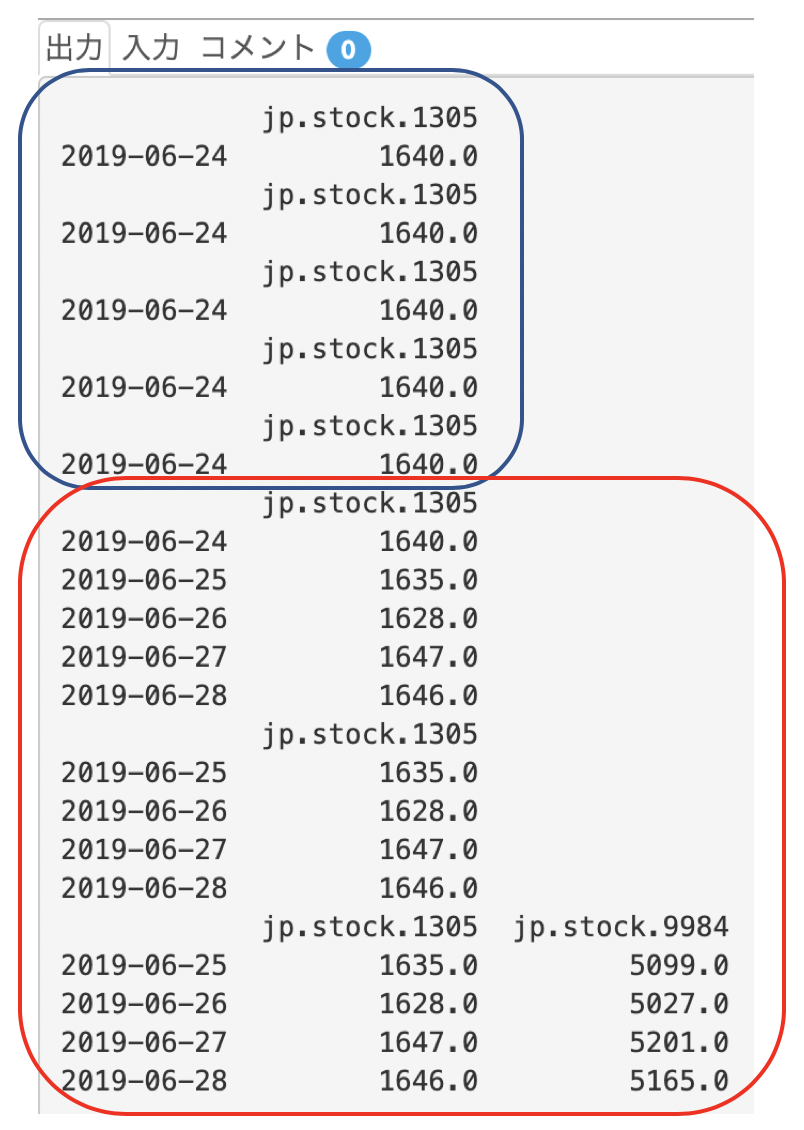
前半の青枠内は、loc, iloc, ixを用い、同じデータを5通りで抽出した結果です。
後半の赤枠内では、
- 全ての行を含む、0列目のデータ
- 1〜4行目までを含む、0列目のデータ
- 1〜4行目まで、全列のデータ
の結果となっています。
指定条件からの行・列の抽出
真偽値(True, False)を返す式を指定することで、特定の条件式に基づく行・列の取得ができます。
############################### チュートリアル1と同じ部分###############################
import pandas as pd
# DataFrameの作成
cp = {"jp.stock.1305":[1640.0, 1635.0, 1628.0, 1647.0, 1646.0],
"jp.stock.9984":[5152.5, 5099.0, 5027.0, 5201.0, 5165.0]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
############################### チュートリアル1と同じ部分###############################
print(df > 1640)
print(df[df > 1640])
print(df["jp.stock.9984"] > 5100)
print(df[df["jp.stock.9984"] > 5100])
print(df[(df > 1640) & (df < 5200)])
出力を見ることで、どう操作できているのか、確認しましょう。
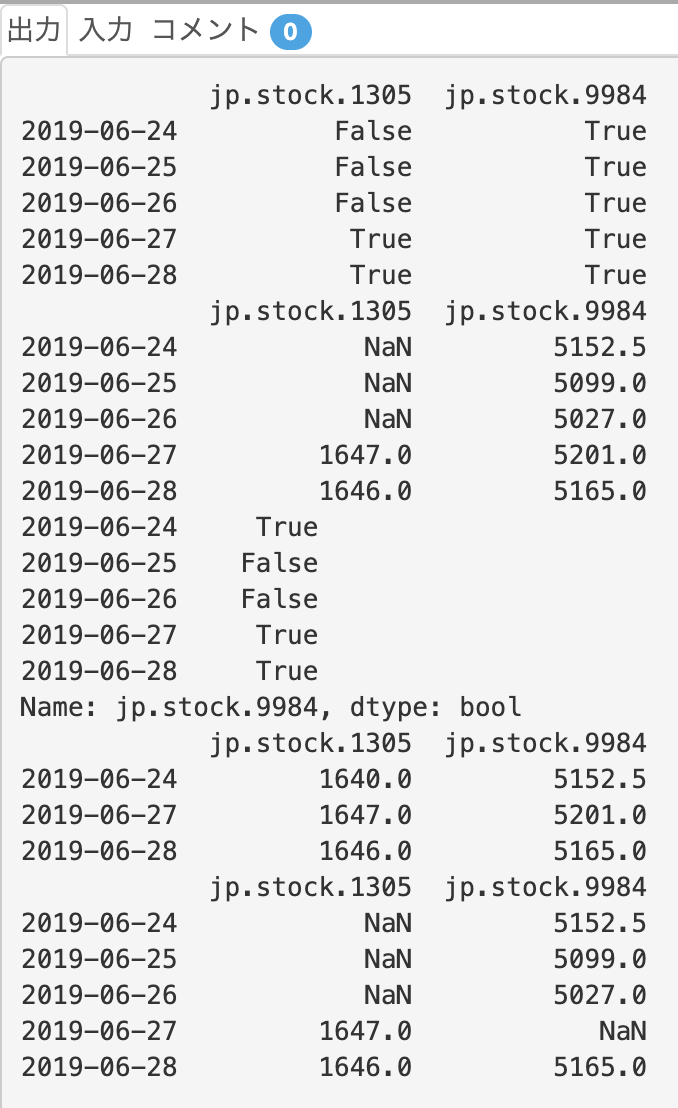
**print(df > 1640)**では、value(ここでは株価)が1640より大きいかを判定し、True, Falseをprintしています。
**print(df[df > 1640])**では、df > 1640でTrueだったもののみのvalueを採用し、Falseだったものに関しては、NaNをprintしています。
**print(df["jp.stock.9984"] > 5100)**では、"jp.stock.9984"列内で、valueが5100より大きいかを判定し、True, Falseをprintしています。
**print(df[df["jp.stock.9984"] > 5100])**では、print(df["jp.stock.9984"] > 5100)でTrueだった行のみを採用し、printしています。
**print(print(df[(df > 1640) & (df < 5200)]))では、&を用いることでvalueが1640より大きく、5200より小さなもののみをフィルターしています。&ではなく|**を用いることでorを表現できます。
3、Quiz
前回のクイズを元に、日産自動車("jp.stock.7201")、ファストリテーディング("jp.stock.9983")の株価表のデータの中身をみてみましょう!
# 前回クイズの解答より
import pandas as pd
cp = {"jp.stock.7201":[767, 764, 761, 778, 772],
"jp.stock.9983":[66530, 66090, 65400, 65390, 65130]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
print(df)
1、上のコードをそのままpaiza.IOへcopy & pasteしてください。
2、以下の項目の確認を、今回のチュートリアルを参考に行ってみてください。
- index名
- column名
- 行数、列数
- 2019-6-25 ~ 2019-6-27のデータ(行)だけを抜粋
- "jp.stock.7201"の株価が、770円以上の日付のみのデータを抽出。(つまり、等符号を使用して、"2019-06-27", "2019-06-28"のみのデータを抽出。)
出力は以下の通りです。さあ次回でpandasチュートリアルは最後です!ページはこちら!
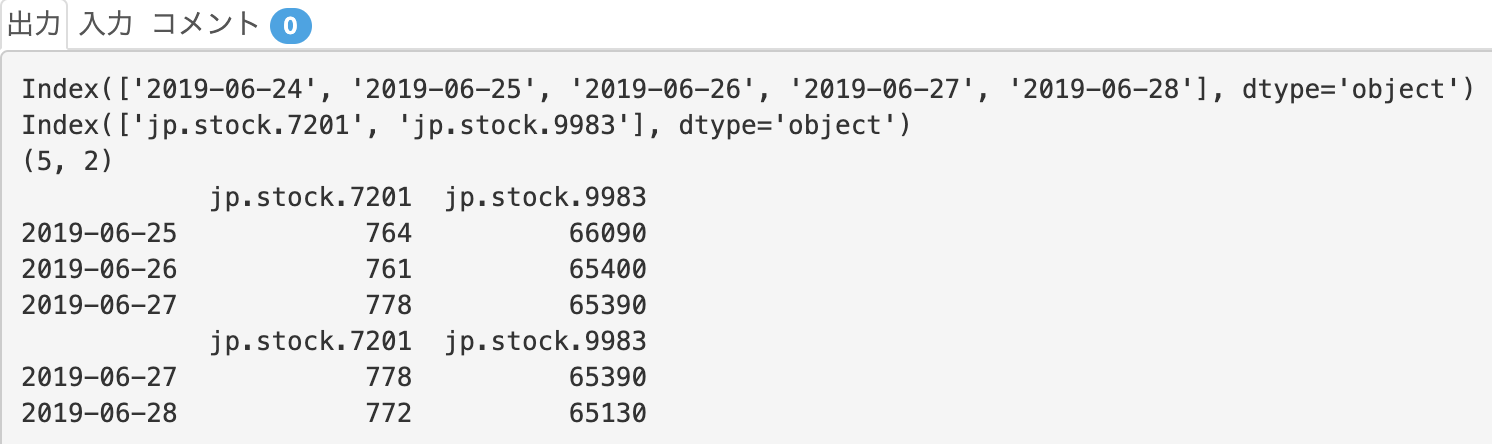
解答
import pandas as pd
cp = {"jp.stock.7201":[767, 764, 761, 778, 772],
"jp.stock.9983":[66530, 66090, 65400, 65390, 65130]}
cp_index = ["2019-06-24", "2019-06-25", "2019-06-26", "2019-06-27", "2019-06-28"]
df = pd.DataFrame(cp, index=cp_index)
print(df.index)
print(df.columns)
print(df.shape)
print(df[1:4])
print(df[df["jp.stock.7201"] >= 770])