はじめに
こんにちは、京セラコミュニケーションシステム 川村(@kccs_takahiro-kawamura)です。
投稿が約1年空いてしまいました。今回はこの1年間溜め続けたドコモシェアバイクのデータを用いてBigQueryMLで予測モデルを作成してみたいと思います。
これまでの記事はこちらです。
本記事は2023年12月ごろに作成しております。よって、引用している文章などはこの時点での最新となります。ご了承ください。
本記事の対象者
- BigQueryMLを気になっている方
- BigQueryMLで予測モデルを作成したい方
データの前処理
まずはBigQueryMLを実行するために溜め続けたデータをTRAIN、PREDICTに分けます。
溜め続けたデータを100個グループにランダムに分け、このグループを指定することでTRAIN、PREDICTとして利用するデータを選択できるようにします。
この処理は以下のクエリで行います。
WITH t AS (
SELECT *,
ROW_NUMBER() OVER() AS row_number
FROM `[PROJECT_ID].docomo_cycle_tokyo.station_status`
)
SELECT *, MOD(ABS(FARM_FINGERPRINT(CAST(row_number AS STRING))), 100) AS group_number
FROM t
元々のデータに行番号を追加した一時テーブルを作成します。
行番号に対してハッシュを計算し、その計算結果に対して分けたいグループ数で割ったあまりを求めています。
これによりランダムにデータをグループ分けすることができました。
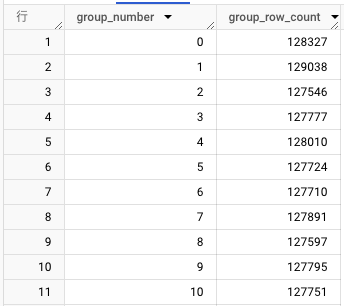
グループ分けした結果を載せておきます。概ね均等にグループ分けすることができました。
BigQueryMLとは
BigQueryMLとは、BigQuery上で機械学習モデルを作成および実行できる機能です。
モデルの作成と実行は、GoogleSQLクエリと呼ばれるANSI準拠のSQLで行うことができ、Pythonなどのプログラミング言語と機械学習フレームワークを習得していない人でも行えます。
また、データを機械学習タスク用のPCなどに移動させる必要がないため、開発スピードを向上させることができます。
BigQueryMLはいくつかのモデルをサポートしています。詳細は公式ドキュメントをご参照ください。
本記事の目的である予測に使えるモデルは、線形回帰モデル、時系列モデル、ブーストツリーモデル、ディープニューラルネットワーク(DNN)モデルがあります。
今回は線形回帰モデル、ブーストツリーモデル、DNNモデルを試したいと思います。
予測モデルの作成
予測モデルの作成は以下のSQLで行います。
今回は約9割のデータを使って学習させます。
CREATE MODEL `[PROJECT_ID].docomo_cycle_tokyo.station_status_linear_model`
OPTIONS(
model_type='linear_reg',
input_label_cols=['num_bikes_available'],
enable_global_explain=TRUE
) AS
SELECT
station_id,
num_bikes_available,
last_reported
FROM `[PROJECT_ID].docomo_cycle_tokyo.station_status_grouping`
WHERE group_number > 10
予測モデルがstation_status_linear_modelという名前で作成されました。
このSQLでは線形回帰モデルを使用して予測モデルを作成しています。
model_typeに使用するモデルを指定することで任意のモデルを使用できます。
ブーストツリーモデルの場合は、BOOSTED_TREE_REGRESSOR
DNNモデルの場合は、DNN_REGRESSOR
input_label_colsには予測したいカラムを指定します。今回は利用できる自転車数を予測したいためnum_bikes_availableを指定しています。
enable_global_explainを有効することで、どの特徴量に影響があるのかをモデル作成後に確認できます。
その他のオプションについては公式ドキュメントをご参照ください。
学習データには、input_label_colsに指定したカラムを含める必要があります。
また、input_label_colsに含まれていないカラムは、モデルを実行して予測を行うときも指定する必要がありますのでご注意ください。
作成したモデルで予測してみよう
作成したモデルを実行して予測を行ってみます。
予測した値の精度が気になるため、溜めていたデータのlast_reportedを指定して予測を行い、予測結果と実績を並べて見たいと思います。
SELECT results.*, ss.num_bikes_available FROM ML.PREDICT(MODEL
`ds-poc-220705.docomo_cycle_tokyo.station_status_linear_model`,
(SELECT station_id, last_reported FROM `ds-poc-220705.docomo_cycle_tokyo.station_status_grouping` WHERE group_number <= 10)) AS results
INNER JOIN `ds-poc-220705.docomo_cycle_tokyo.station_status_grouping` AS ss
ON ss.station_id = results.station_id AND ss.last_reported = results.last_reported
WHERE ss.group_number <= 10
学習に使用していないデータで予測してみました。
ML.PREDICT(MODEL [モデル名], [入力データ])の形でモデルを実行できます。
今回はすでにテーブルに溜めてあるデータを使用していますが、アプリケーションから実行する場合は入力データの部分に値を渡せば実行できます。
線形回帰モデル、ブーストツリーモデル、DNNモデルのそれぞれの予測結果は以下のとおりです。
-
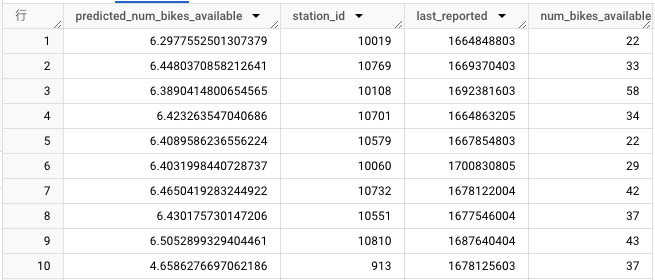
線形回帰モデル
-
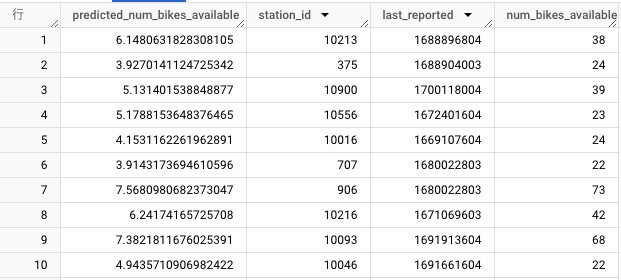
ブーストツリーモデル
-
DNNモデル
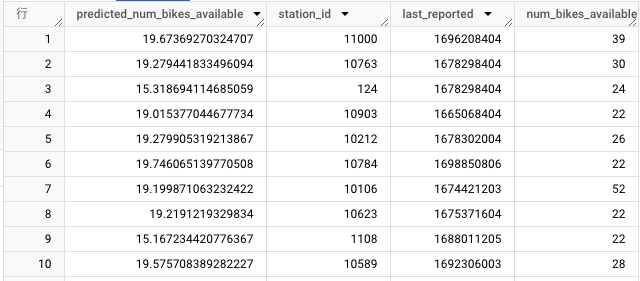
predicted_[input_label_colsに指定したカラム名]で予測結果が出力されます。
あまり精度がよくないですね😅。精度改善の記事はまた今度。
まとめ
- BigQueryMLは、事前学習されたモデルを使用してBigQuery上でSQLのみで独自モデルを作成できます。
- BigQueryMLで予測に使用できるモデルは、線形回帰モデル、時系列モデル、ブーストツリーモデル、ディープニューラルネットワーク(DNN)モデルがあります。
次回の記事もお楽しみに!
おしらせ
弊社X(旧:Twitter)では、Qiita投稿に関する情報や各種セミナー情報をお届けしております。情報収集や学びの場を求める皆さん!ぜひフォローしていただき、最新情報を手に入れてください😄