はじめに
一年前にこんな記事を書きました。未だにちょくちょくいいねを頂いているので、自然言語処理の練習を兼ねて久しぶりに遊んでみた系の記事を投稿しようと思います。

やったこと
- 歌詞データのクローリング
- Mecabによる分かち書き
- tf-idfによるベクトル化
- ベクトル化した歌詞によるアーティストのクラスタリングとUMAPでの可視化
- (おまけ) fastTextでハチ=米津玄師を見分けられるのか?
分析にはJupyter Labを用いました。
歌詞データ
今回用いる歌詞データについて説明します。
クローリングで取得
先立って歌詞データのクローリングをしました。とある人気アーティスト順に歌詞を取得できるサイトより、45人のJ-popアーティストにつき、最大50曲分の歌詞を取得しCSVに保存しました。
実際にクローリングに用いたコードを公開するのもどうかと思うので、ここでは割愛します。。。BeautifuleSoupとrequestsを用い、正規表現に苦戦しながら50行程度でクローラーを作ることができました。
実際に取得できたデータ
実際に取得した歌詞をPandasで一部読み込んだものがこちらです。

個々のアーティストの名前を列挙するのは避けますが、錚々たるメンバーです!
前処理
自然言語処理のキモと言える前処理です。今回NLPは初めてなのですが、気合いを入れて頑張ってしました!
分かち書き
Mecabで形態素解析を行い、各品詞を原型に変形しながら分かち書きを行いました。
import MeCab
import unicodedata
def split_text(text, filter = ["動詞", "形容詞", "形容動詞", "名詞"]):
tagger = MeCab.Tagger('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
text=unicodedata.normalize('NFC', text)
tagger.parse("")
# 形態素解析の結果をリストで取得、単語ごとにリストの要素に入ってる
node = tagger.parseToNode(text)
result = []
#助詞や助動詞は拾わない
while node is not None:
#日本語の処理
if node.surface.isalnum():
if isalpha(node.surface):
pass
else:
# 品詞情報取得
# Node.featureのフォーマット:品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用形,活用型,原形,読み,発音
hinshi = node.feature.split(",")[0]
if hinshi in filter:
word = node.feature.split(",")[6]
if word not in stop_words and not isalpha(word):
result.append(word)
node = node.next
return " ".join(result)
Stop Words
今回日本語のstop wordsに加え、まず後のtf_idfでランクづけをした際、「ある」「いる」「ない」など全アーティストであからさまに多く、意味もなさそうな単語を主観でstop wordsに追加しました。
さらに、このstop wordsで分かち書きした後に全曲の歌詞で単語の出現回数ランキングを作成し、ランキング上位20件をさらにstop wordsに加えました。
(この辺りの経緯はトライアンドエラーの繰り返しで、かなりごっちゃになってしまっています。。。)
# Stop Words除外用
url = "http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt"
res = requests.get(url)
stop_words = res.text.split()
# 出現回数ランキング
words = {}
for row in df["words"]:
for word in row.split(" "):
words[word] = words.get(word, 0) + 1
# sort by count
d = [(v,k) for k,v in words.items()]
d.sort()
d.reverse()
for row in d[:20]:
print(row)
stop_words.append(row[1])
""" 参考 : ランキングの結果
(9014, '君')
(6231, '*')
(5349, 'の')
(4348, 'ん')
(4320, '僕')
(2706, '心')
(2276, '夢')
(2148, '見る')
(1966, 'くれる')
(1939, 'さ')
(1872, 'られる')
(1868, '愛')
(1812, '言う')
(1727, 'いく')
(1665, '行く')
(1664, '笑う')
(1652, '知る')
(1643, '生きる')
(1632, '胸')
(1596, '言葉')
"""
今回このstop wordsに関するDataFrame処理のフローが、
- 既存の日本語stop words + 主観のstop wordsでstop wordsリストを作成
-
df["words"]=df["lyrics"].map(lambda x: split_text(x))で各曲の歌詞を分かち書き - 分かち書きした結果をもとに単語の出現回数ランキングを作成
- stop wordsのリストにランキング上位20件を追加
- 再度
df["words"]=df["lyrics"].map(lambda x: split_text(x))
と無駄の多い感じになっています😓。愛にできることはまだあるかい。
アーティストごとにIDをマップし, 「アーティスト<=>曲中に出現する単語」の対応を表すDataFrameを作ります。
art_map = {}
for id, art in enumerate(df.artist.unique()):
art_map[art]=id
df['art_code'] = df['artist'].map(art_map)
words_df = df\
.groupby("art_code")["words"]\
.apply(lambda x: "%s" % ' '.join(x))\
.reset_index()
続いて、tf_idfで出現回数上位に来る単語に重み付けを行います。また、上位の単語を実際に抽出してアーティストがどのような単語を使っているのかみてみたいと思います。
このあたりの処理はこちら【特別連載】 さぁ、自然言語処理を始めよう!(第2回: 単純集計によるテキストマイニング)
を参考にさせていただきました。
from sklearn.feature_extraction.text import TfidfVectorizer
terms = vectorizer.get_feature_names()
vectorizer = TfidfVectorizer(stop_words="english")
tfidfs = vectorizer.fit_transform(words_df["words"])
def extract_feature_words(terms, tfidfs, i, n):
tfidf_array = tfidfs[i]
top_n_idx = tfidf_array.argsort()[-n:][::-1]
words = [terms[idx] for idx in top_n_idx]
return words
def get_key_from_value(d, val):
keys = [k for k, v in art_map.items() if v == val]
if keys:
return keys[0]
return None
top_n = 15 # 上位5件
highscore_words = [
extract_feature_words(terms, tfidfs.toarray(), i, top_n)
for i
in range(len(words_df.index))
]
highscore_words_str = [" ".join(l) for l in highscore_words]
words_df["highscore_words"] = highscore_words_str
words_df["artist"] = words_df["art_code"].map(lambda x: get_key_from_value(art_map,x))
結果はこちら

「パクチー」「おじさん」「パンパカパーン」。。。などなかなかクセのある単語が残っている一方、「僕」「キミ」「あたし」などの一、二人称を示す単語も多く残っていますね。
このあたりは結構アーティストの特徴として鍵になってくるんじゃないでしょうか。
クラスタリング&可視化
せっかくなのでアーティスト全体の傾向を測るため、クラスタリングを行い、UMAPを用いてクラスタを可視化してみようと思います。
クラスタリング
今回適当にクラスタ数を10と決め、K-meansによりクラスタリングを行います。
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.manifold import TSNE
import pandas as pd
from sklearn.cluster import KMeans
def kmeans_clustering(tags, vecs, n_clusters):
""" K平均法クラスタリングを行うメソッド """
km = KMeans(n_clusters=n_clusters,
init='k-means++',
n_init=20,
max_iter=1000,
tol=1e-04,
random_state=0)
clusters = km.fit_predict(vecs)
return pd.DataFrame(clusters, index=tags)
num_clusters = 10
num_seeds = 5
max_iterations = 1000
# calculate tf-idf of texts
tf_idf_vectorizer = TfidfVectorizer(analyzer="word", use_idf=True, smooth_idf=True, ngram_range=(2, 3))
tf_idf_matrix = tf_idf_vectorizer.fit_transform(words_df["words"])
# create k-means model with custom config
clustering_model = KMeans(
n_clusters=num_clusters,
max_iter=max_iterations,
precompute_distances="auto",
random_state=num_seeds,
n_jobs=-1,
)
labels = clustering_model.fit_predict(tf_idf_matrix)
# print labels
X = tf_idf_matrix.todense()
words_df["cluster"]=labels
for i in range(0,words_df["cluster"].nunique()):
print(f"--Cluster : {i}--")
print(words_df[words_df.cluster==i].artist.unique())
結果はこんな感じに
| クラスタ | アーティスト |
|---|---|
| 0 | 中島みゆき, Aimer, JUJU |
| 1 | 嵐, 安室奈美恵, いきものがかり, TWICE, Superfly, サザンオールスターズ, 関ジャニ∞, ZARD, ゆず, スピッツ, Kis-My-Ft2, GLAY, ポルノグラフィティ, コブクロ |
| 2 | DREAMS COME TRUE, 西野カナ, E-girls |
| 3 | Mr.Children, あいみょん, BUMP OF CHICKEN |
| 4 | Perfume, back number, [ALEXANDROS] |
| 5 | X JAPAN |
| 6 | 乃木坂46, 欅坂46, AKB48 |
| 7 | 米津玄師, 椎名林檎, YUKI |
| 8 | 宇多田ヒカル, KinKi Kids, AAA, 星野源, GReeeeN, KAT-TUN, LiSA |
| 9 | B'z, SMAP, aiko, 倉木麻衣, NEWS |
パッとみて驚くのは、坂道アーティストの三組が過不足なく同じクラスタにいることです。もしかしたら姉妹ユニットということで同じ曲を歌っている場合も考えられますので、一応重複した曲がないか調べます。

ファンの方に怒られそうな雑な抽出条件ですが、曲の重複はなさそうです!
それぞれのクラスタに、独断と偏見で帰結を与えるとこんなところでしょうか...
| クラスタ | アーティスト | 特徴? |
|---|---|---|
| 0 | 中島みゆき, Aimer, JUJU | 女性アーティスト |
| 1 | 嵐, 安室奈美恵, いきものがかり, TWICE, Superfly, サザンオールスターズ, 関ジャニ∞, ZARD, ゆず, スピッツ, Kis-My-Ft2, GLAY, ポルノグラフィティ, コブクロ | 王道J-pop |
| 2 | DREAMS COME TRUE, 西野カナ, E-girls | 女性に共感される歌詞 |
| 3 | Mr.Children, あいみょん, BUMP OF CHICKEN | ロック系 |
| 4 | Perfume, back number, [ALEXANDROS] | わからん… |
| 5 | X JAPAN | 紅だぁぁ |
| 6 | 乃木坂46, 欅坂46, AKB48 | 坂道 |
| 7 | 米津玄師, 椎名林檎, YUKI | 独特の歌詞 |
| 8 | 宇多田ヒカル, KinKi Kids, AAA, 星野源, GReeeeN, KAT-TUN, LiSA | 王道J-pop2 |
| 9 | B'z, SMAP, aiko, 倉木麻衣, NEWS | わからん… |
よくわからないクラスタもありますが、だいたいこんなところでしょうか。ちなみにクラスタ数を絞るとクラスタ1, 8がだいたい同じ1つの大きなクラスタになります。
ふんわりと性別でクラスタが分かれているような気もするのは、先ほどの一人称が効いているのでしょうか? (米津玄師も椎名林檎も一人称はあたしが多いイメージ ※2021/11/24追記 : aikoの名曲「カブトムシ」も「あたし」ですね!)
可視化
今回t-SNEよりも綺麗に分かれると噂のUMAPとplotlyを用いて、クラスタの可視化を試みます。
UMAPはこちらを参考にさせて頂きました。論文の投稿日が僕の誕生日!
# UMAP
import umap
from scipy.sparse.csgraph import connected_components
Y = umap.UMAP(n_components=3, verbose=17).fit_transform(X)
# plotly
import plotly.plotly as py
import pandas as pd
scatter = dict(
mode = "markers+text",
name = "y",
type = "scatter3d",
x = Y[:,0], y = Y[:,1], z = Y[:,2],
text = words_df.artist.values,
marker = dict( size=5, color=labels, colorscale='Jet'),
)
layout = dict(
title = '3d point UMAP',
scene = dict(
xaxis = dict( zeroline=False ),
yaxis = dict( zeroline=False ),
zaxis = dict( zeroline=False ),
),
width=1000,
height=1000,
)
fig = dict( data=[scatter], layout=layout )
# Use py.iplot() for IPython notebook
py.iplot(fig, filename='Artist Clustering')
せっかくplotlyを使っているので、まずは3Dで可視化。こんな感じ!
普段このようなことをやったことがないのでわからないのですが、そこそこクラスタごとに分かれているような気がします。t-SNEも試したのですが、そちらよりは綺麗に分離できている気がします。
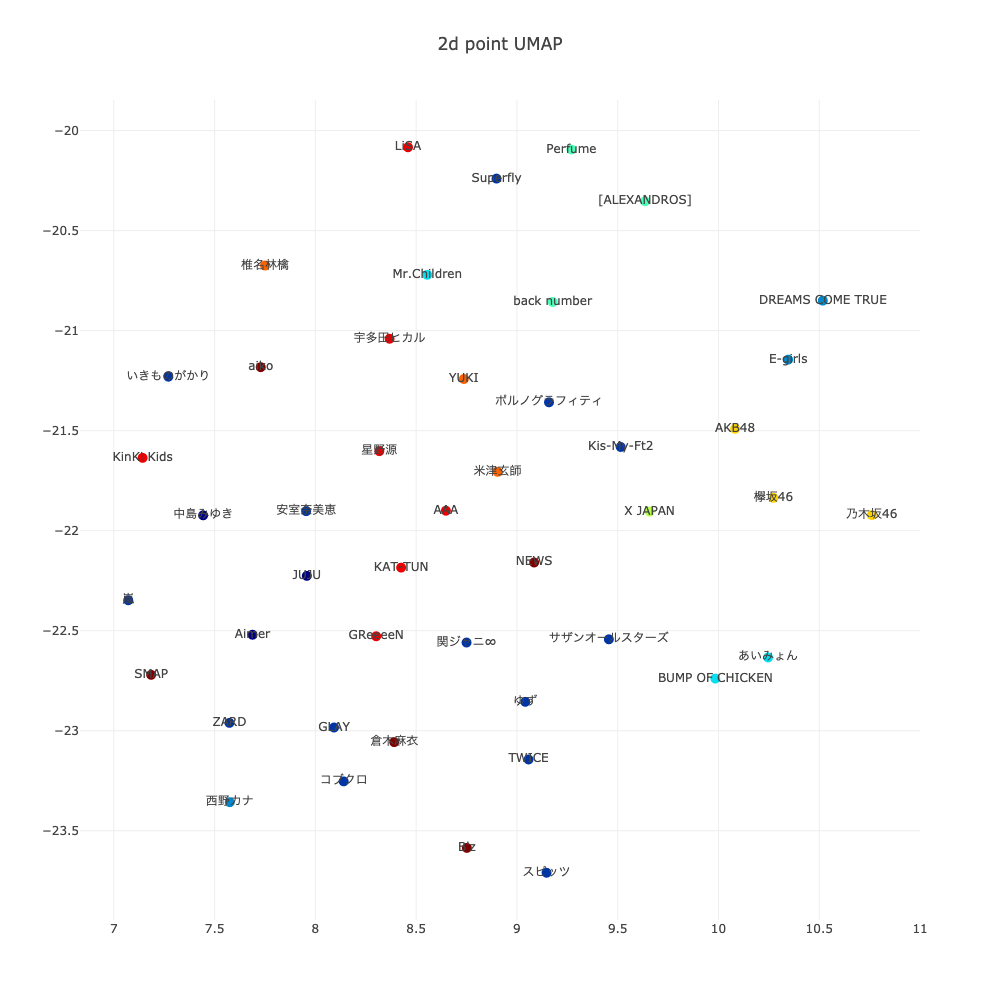
2Dではこんな感じになりました。
オマケ : 米津玄師 = ハチを見破れるか!?
せっかくなので集めたデータを、文章分類を行えるライブラリfastTextに食べさせてみました。
また、学習したモデルでハチ (米津玄師のボカロP時代の名義) の歌詞のアーティストを予測し、ちゃんと米津玄師と予測できるか実験してみます。
訓練データ : 米津玄師、テストデータ : ハチって感じですね。
fastTextの学習データはこんな感じで作ります。
__label__0, [分かち書き]
__label__1, [分かち書き]
...
__label__n, [分かち書き]
データフレームを使ってサクッと作りました。
with open("train.txt", "a") as f:
for index, row in df.iterrows():
line = f"__label__{art_map[row['artist']]}, {row['words']}\n"
f.write(line)
今回データ数 (単語数) が少ないのでなんとも言えず、そもそもfastTextを使ったことがないのでカンでlossが1.0程度に下がるまで学習させます。
./fasttext supervised -epoch 100 -input ../lycrawler/train.txt -output model
10秒足らずで学習が終わります。めっちゃ早いですね。
それでは予測させてみます。先ほどの分かち書きのメソッドに歌詞をなげて、モデルに予測させます。
import fastText as ft
def get_artist_from_label(label):
label = label.replace("__label__","").replace(",","")
return [k for k, v in art_map.items() if v == int(label)][0]
model = ft.load_model("../fastText/model.bin")
# パンダヒーロー
panda = """
銘々に狂った 絵画の市
黄色いダーツ板に 注射の針と...
"""
panda_split = split_text(panda)
res = model.predict(uma_split, k=5)
for label, score in zip(res[0], res[1]):
print(f"{get_artist_from_label(label)} ({round(score, 3)})")
結果は。。。

おお!!
続いて、ハチさんの曲で、ニコニコ動画において100万再生超え (ミリオン達成) の曲を食べさせてみます。出典
ただし、「ドーナツホール」と「砂の惑星」は学習データに入っている (米津玄師名義でリリースしている) ので外します。
結果だけ貼るとこんな感じです。
| タイトル | 1位 | 2位 | 3位 |
|---|---|---|---|
| 結ンデ開イテ羅刹ト骸 | 米津玄師 (0.154) | 関ジャニ∞ (0.113) | BUMP OF CHICKEN (0.113) |
| マトリョシカ | TWICE (0.103) | LiSA (0.084) | 関ジャニ∞ (0.081) |
| clock lock works | 米津玄師 (0.746) | BUMP OF CHICKEN (0.073) | ポルノグラフィティ (0.032) |
| パンダヒーロー | 米津玄師 (0.223) | スピッツ (0.213) | [ALEXANDROS] (0.121) |
| Mrs.Pumpkinの滑稽な夢 | 米津玄師 (0.779) | YUKI (0.195) | [ALEXANDROS] (0.01) |
| リンネ | BUMP OF CHICKEN (0.332) | 米津玄師 (0.261) | back number (0.179) |
| ワンダーランドと羊の歌 | 米津玄師 (0.784) | 星野源 (0.042) | [ALEXANDROS] (0.031) |
| WORLD'S END UMBRELLA | Aimer (0.519) | 宇多田ヒカル (0.132) | コブクロ (0.119) |
...データ数が少ない割に、なかなかの正解率ではないでしょうか??
ちなみに米津玄師さん自身もスピッツやBUMP OF CHICKENから影響を受けたと自身でおっしゃっております。
オマケで、クローリングした時点では載っていなかった新曲「馬と鹿」についても予測しました。

想像以上にすごい!!
まとめ
- 自然言語処理の基礎がわかった気がしました。もしかしたら最新鋭のもっといい手法があるかもしれませんが。。。
- UMAPすごい!!
- もっとデータを集めるべきだなぁと反省。もうちょっと集めてリベンジしたいです。
今回のノートブックはこちらです。
https://gist.github.com/kazuya-n/df443c705d774a36b30e45b3a1793df1