YAPC::Asia Tokyo 2015、ロゴのとおりに熱いイベントでした...今年で最後なのはほんとに惜しいです。最初にして最後の参加となった私は、「Google Cloud Platformの謎テクノロジーを掘り下げる」というタイトルでトークをさせていただきました。

しかし謎は謎のまま...
Twitter上の反応まとめを見ますと、「謎が謎のまま終わった」とのご指摘も多く、これはほんとに私の不徳の致すところです、申し訳ありません……。スライド上の「?」の部分、あまり掘り下げられませんでした。タイミング的に現時点で発表できなかった製品もいくつかあったり。今後もできるだけ謎の中身をシェアすべく努力したいと思います。この記事でも、いろいろとヒントとなることを書いたつもりです。
Datacenter as a Computer
このトークの要点をひとことで言えば、「Google Cloud Platform (GCP)のキモはDatacenter as a Computerの考えにある」です。


Datacenter as a Computerは、Googleのデータセンターやインフラ技術を統括するSVP、Urs Holzleが同名の書籍を書く際に用いたキーワードです。以下に説明するさまざまな技術も、おおざっぱには「データセンターを単なる多数のコンピューターを収容したビルディングではなく、全体で1台の大規模分散コンピューターのように設計し、全体最適を目指すための技術」と捉えることができます。
ぼくのかんがえたさいきょうの大規模分散並列計算機
この点は、私が4年半前にGoogleに入る前からApp EngineやBigtableに対して惚れ込んでいた「Googleクラウドらしさ」からまったく変わっていません。Googleクラウドって、分散システムの専門家・学者たち、ハードウェアの設計者らをたくさん招いて、「ぼくのかんがえたさいきょうの大規模分散並列計算機」をゼロから構築してしまった、しかもビジネスとしてもガンガン黒字で回ってる、ってところがクールです。
例えば、Googleでは、サーバー、ネットワーク等、データセンターを構成する大半のハードウェアを自社で開発しています。台数規模的に見て、Googleは世界トップクラスのサーバーベンダーだ、なんて表現する人もいます。私自身も今年初め、Googleのオレゴンと台湾のデータセンターの中を見て回る機会がありましたが、HPやDELL、CiscoやJuniperといったおなじみの製品はま〜ったく見当たりませんでした。

ちなみに、本社Mountain Viewの人材募集ページを探すと、LSI設計者を絶賛採用中なのが分かります。
Deep experience in one or more of the following areas: PCIe, RDMA, SR-IOV;
L1 10G/40G/100G MAC/PCS; L2-L3 packet switching/routing; Low-latency networking
design; Memory Controllers; SoCs. ... Familiarity with emulators such as
Palladium/Veloce
なにやろーとしてんだか分かりやすすぎな気がしますがw ここに書いてあるPalladiumって、ASIC設計用の大量のFPGAの塊みたいなデジタル回路エミュレータで、1台何億円かするらしいです。Googleよおまえはチップベンダーかw
そしてもちろん、インフラソフトウェアについてもほとんど自社開発。分散ファイルシステムであるGoogle File System (GFS)や、大規模分散バッチ処理フレームワークであるMapReduce、そして元祖NoSQLとも言える大規模分散データベースBigtableなど、Googleの各種サービス(初期はおもに検索サービス)のスケーラビリティを支えるためのソフトウェア技術。
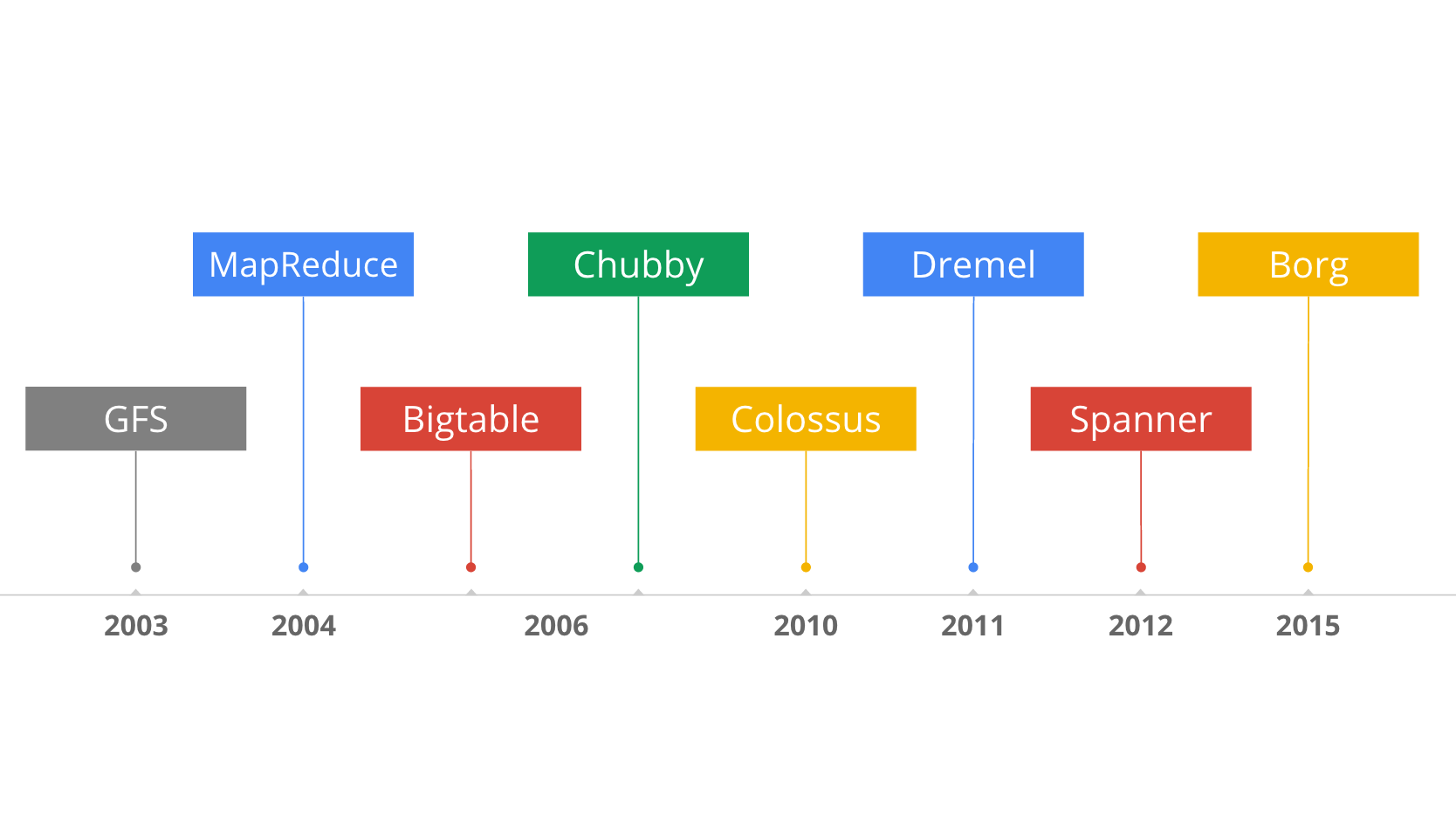
これらは、GoogleフェローであるJeff Deanをはじめ、レジュメを見てるとそのあまりの異次元さ(同じ会社社員とはとても思えません)にヘコんでしまうくらいのアカデミアのロックスター達が、シコシコと泥臭いproduction codingに尽力して、細かいバグもyak shavingもおろそしい大規模障害も乗り越えて生み出してきた基盤です。しかもその凄まじい成果の詳細はほとんど外に出ない。ノーベル経済学賞受賞者たちにデリバティブ取引を実装させていたヘッジファンドLTCMをほうふつとさせますね(←なんかよくないフラグ)。
ちなみにBigtableはいまでもGmail等を支えるばりばり現役ですが、GFSはColossusに、MapReduceはFlumeJavaやDremel等の次世代技術にそれぞれ主役の座を譲っています。
Googleクラウドをそのまま使えるのがGCP
そんなGoogleクラウドを、外のお客様にも使っていただこう! というサービスがGoogle Cloud Platform (GCP)です。
まだAWSには及びませんが、GCPも一通りのサービスが整ってきて、国内外のユーザー様が増えつつあります。

国内でも、CyberAgentさん、Aimingさん、DeNAさん、Groovenautsさんをはじめ、名前は出せませんがあの国内最大手ソーシャルゲームベンダーさん、他社クラウドで何万コアも使ってそうな大規模なお客様たちのGCP導入事例が、昨年から急増しつつあり、これからじわじわと事例紹介が外に出てくると思います。そしてもちろん、Google BigQueryは昨年からぎゅーーんとユーザー数がうなぎのぼりに増えています。
なぜ、そうしたお客様は、実績も少なくコミュニティもまだまだ小さいGCPをわざわざ選んでいただいているか? と言うと、やっぱり答えは「Datacenter as a Computer」に行き着くと、個人的に思います。私が5年前にApp EngineやBigtable、BigQueryに抱いた「これは何か全然別物かも?」という感覚を、共有していただいているのかなと。
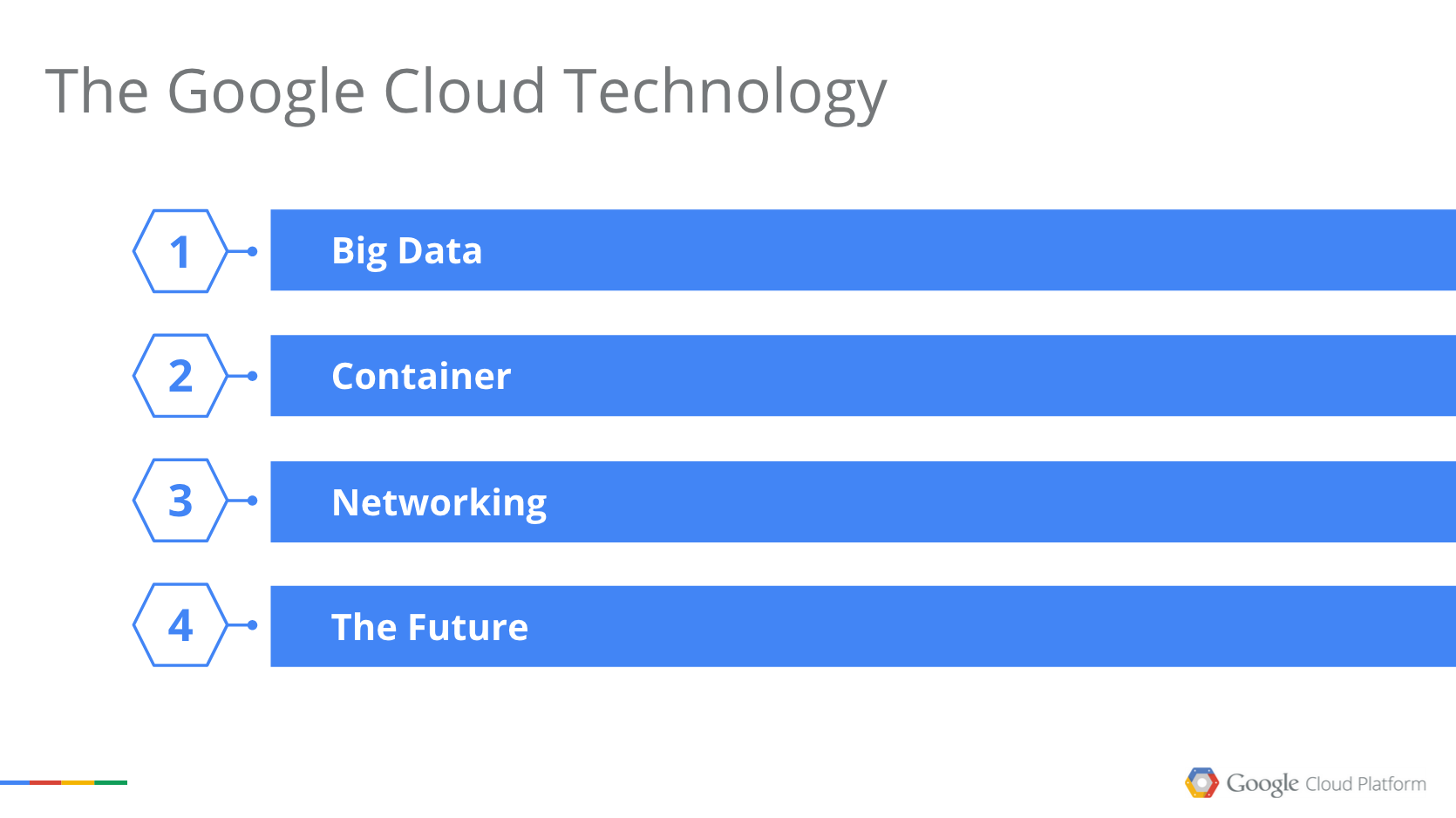
以下、その中身について、Big Data、Container、Network、そして今後の技術という4つの観点で掘り下げてみます。
Big Data
まずは、Big Dataから。

GCPのプロダクトマネージャ達がプレゼンするとき、よく「Google社内ではビッグデータのことを『データ』と呼んでます」ってフレーズを使います。Googleでは、社内のどの部門でも、取り扱うデータは基本ビッグです。
例えば:

YouTubeもAndroidも、現在のユーザー数は10億人。Google検索は月間1000億クエリをさばいていて、Gmailはアクティブユーザー数が9億人です。こんな調子で、Googleのどのサービスをとってみても、ログの量は簡単に数10TBを超えてしまいます。
私も4年半前にGoogleに入社した時は、国内で最大規模のAdWords APIユーザーをサポートしていました。そうしたお客様から突然トラブルコールが入ってきて、緊急にトラブルシューティングしなければならない時、ログの分析にMapReduceを使うと思いますか? マネージャやディレクターからの急ぎの問い合わせに対して、「今からMapReduceジョブを流しますから、半日待ってください!」って言えますか?
ムリです。Googleではそうした用途にはMapReduceは使いません。代わりに使うのは、Dremel、FlumeJava、MillWheelといった「ポストMapReduce世代」のビッグデータ処理基盤です。これらの次世代の基盤が、社内で「Googleスピード」と表現されるめまぐるしいペースでGoogleのさまざまなビジネスを遂行していく原動力となっています。

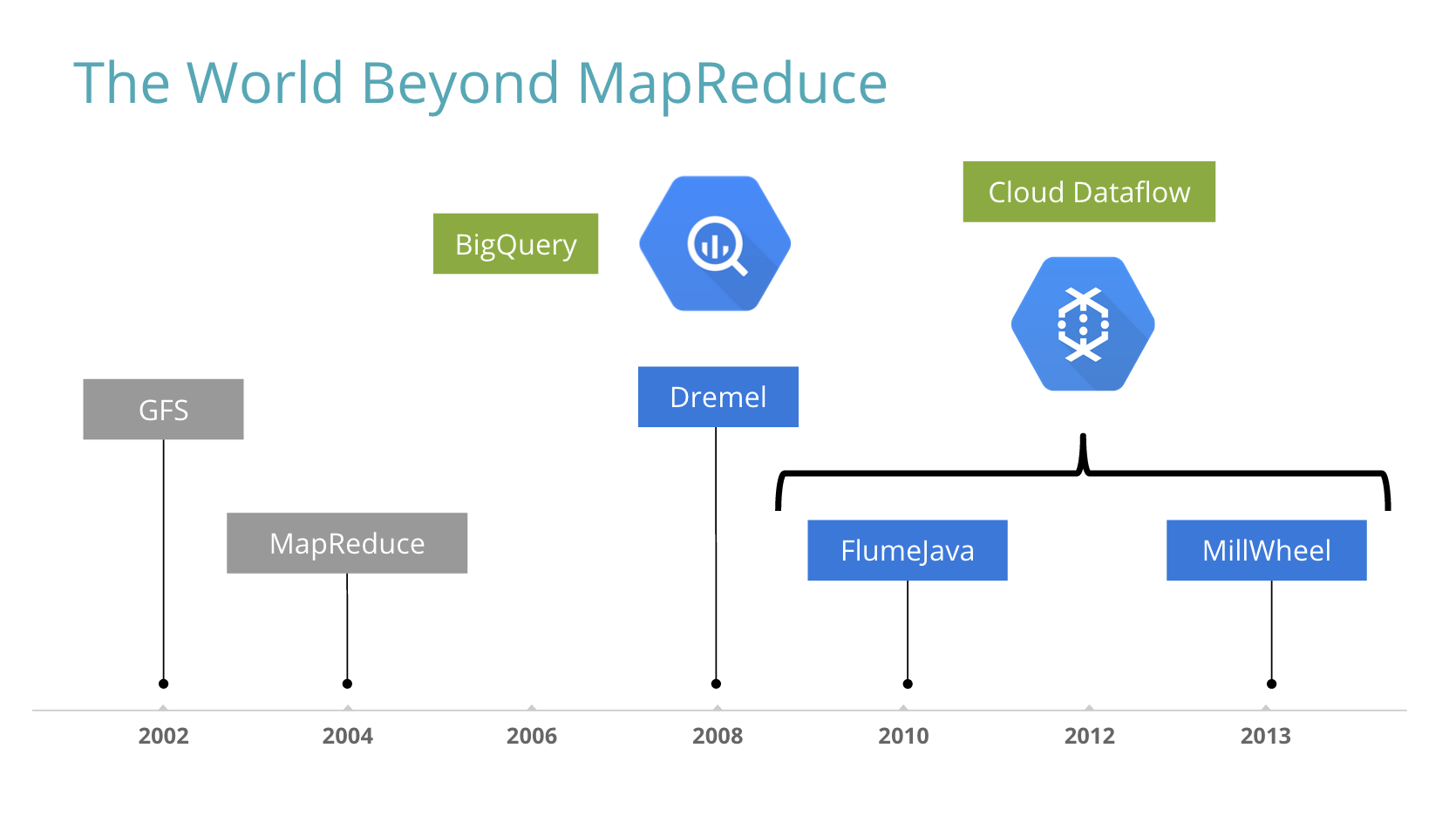
そしてGCPでは、DremelをBigQuery、FlumeJavaとMillWheelをCloud Dataflowとしてそれぞれ製品化しています。
Dremel/BigQueryがディスク1万台を使える理由
Dremelは社内では2006年からプロダクション利用されている、大規模分散クエリシステムです。BigQueryはそれにREST APIやストリームインサート機能を付けて公開してるもので、中身はDremelそのもの。その詳細は2010に公開されたペーパーで(ある程度まで)説明されています。

Dremel: Interactive Analysis of Web-Scale Datasets
私がGoogleに入社したときに驚いたことの一つは、このDremelが社内のさまざまな部門で、特にプログラマー以外の一般社員ユーザーによるアドホックなログ分析業務等で使われまくっていた点です。その頃の社外には、Apache DrillやCloudera Impala、Presto等のDremelライクなMPPクエリエンジンは存在していませんでした。Googleに入って衝撃を受けた謎テクノロジー、その1です。
(もちろん、Googleに入って驚いたのはいい事ばかりじゃなくて、例えば当時はまだAdWordsがMySQLクラスタで運用されててSpanner/F1へお引越し中だったのもびっくりしました。シャードをまたがるとJOINできない。Google普通だな)
Dremel/BigQueryのパフォーマンスについては、ご存知の方も多いと思います(ここにデモ動画があります)。

1000億行のWikipediaページビューログに対して、インデックスを使わないフルスキャンの正規表現マッチを実行して、レスポンスは30秒以下です。100億行だと7秒ほど。
この速度を実現できる理由はわりと単純で、Dremel/BigQueryでは個々のクエリにおいて5,000〜10,000台のディスクに並列アクセスしているからです。

過去には「ImparaやPrestoでも並列度を上げればそれくらい達成できる」という議論もありました。確かにそうかもしれません。が、ではなぜそうしたクラウドサービスが提供されていないのでしょうか?
それは、他のMPPクエリエンジンが「Datacenter as a Computer」の上で動いていないから、です。ImparaやPresto専用のデータセンターを作り、そこに数1000台のサーバーを並べて運用しても、経済的にペイしません。一方で、Googleのデータセンターの最大の特徴は、後述するコンテナ技術「Borg」をベースに、あらゆるGoogleサービスをデータセンター全体に薄く広くデプロイメントしている点です。
台湾のデータセンターを視察したとき、見渡す限り広がるサーバ群のどれひとつとってみても、特定のソフトウェアやサービスに特化したものはありませんでした。すべてのサーバ上でBorgが動作し、Google検索のフロントエンドでも、Mapsのバッチ処理でも、Dremelでも、どのようなサービスでもごく簡単なリソース割り当てでデプロイできる。そうした数万規模のサーバ群を、GoogleのSite Reliability Engineer (SRE)たちが24時間体制で運用しています。彼らSREは、いざとなったらDremelのソースを追って設計上の原因を特定し、緊急パッチを当てることさえできる、Googleエンジニアの中でもとびきり優秀な人たちです。
そうした運用基盤、ビジネスとして回せる基盤があるから、1クエリで5000台のディスクを使うような、本当の意味での大規模並列(massively parallel)クエリを実現できる。hakoberaさんがDremelの仕組みを「数の暴力」と表現されてましたが、個人的には、数の暴力が一定のcritical massを超えて経済的に回り始める現象こそ、クラウドの本質じゃないかな、と思います。
「?」の中身
Dremel/BigQueryのJOINおよびGROUP BYにおけるシャッフル性能は、単に台数が多いだけの理由ではなく、以下の図を書いたJordan Tigani(BigQueryチームのエンジニア)が雲のかたちで表した部分の能力に依るところが大きいです。
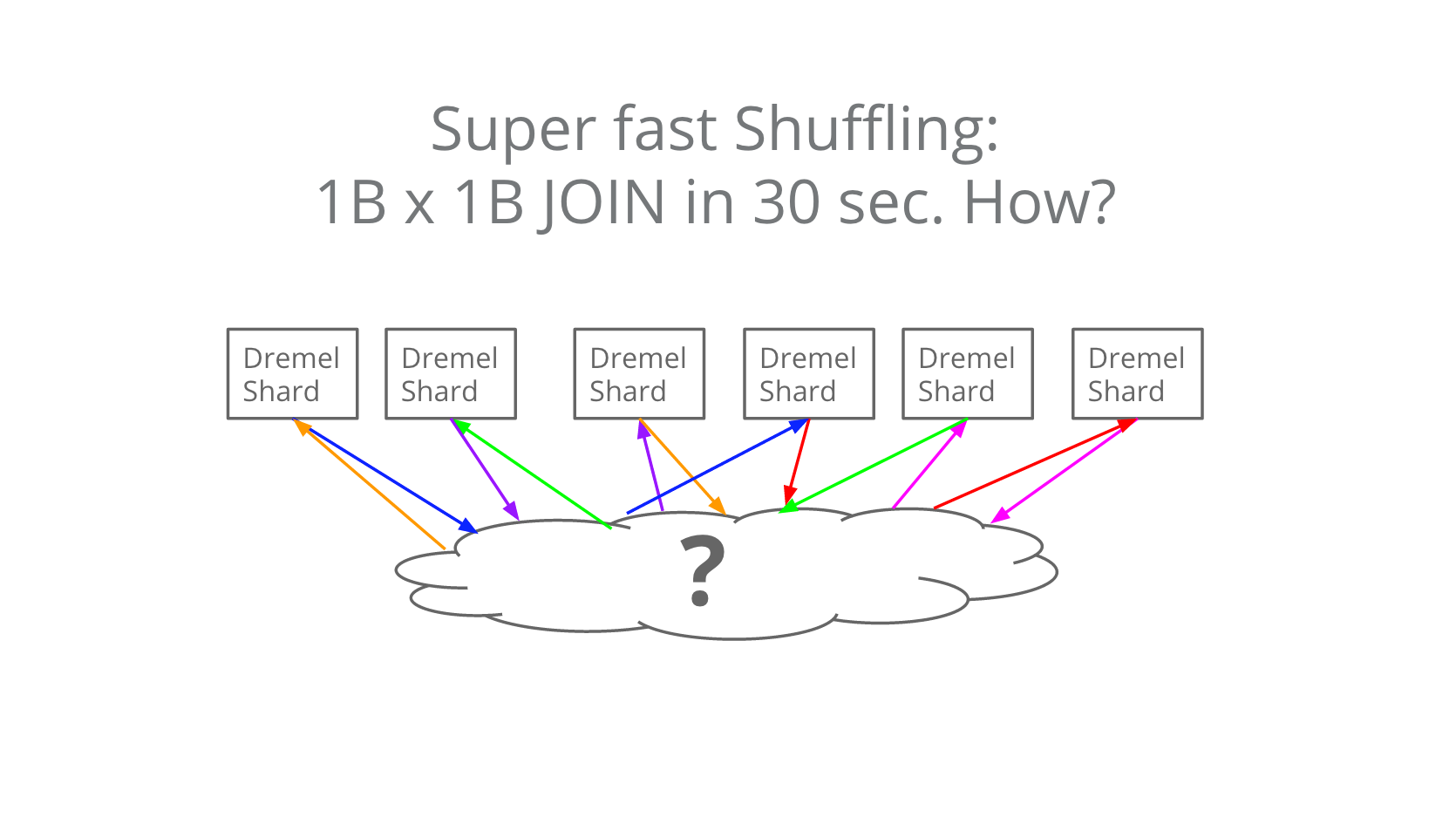
10億×10億のJOINが30秒で終わります。この「?」の中身は……残念ながらご想像にお任せするしかありませんが……ここまで速いともはやスパコンですね(小並感)。大量のデータを多数のノード間で低レイテンシかつ高速にやりとりできる。この部分の技術には、私が入社してDremel以来の2回めの衝撃を受けました。これもやはり、データセンターをまるごと1台のコンピューターとしてしまうような技術です。いずれこのあたりがペーパーとして公開されるといいな。
このクローズドソース野郎!
なんだか褒めてばっかりで我ながら気持ち悪くなってきたので、デメリットにも触れておきましょう。Dremel部分はブラックボックスなので、調子がよくないときは祈って待つしかありません。自分でソースを追って原因を特定したりできません。基本、クローズドソース野郎です。最近は時折ストリームインサート機能が調子よくないことがありました。Bigtableで受けてるのでデータが消えることはありませんが、インサートが遅延するとご迷惑おかけしまくりです。しかしBigQueryチーム一同、信頼性向上をP0としてがんばっております。
BigQuery UDF出ました!
会場で質問いただいた「User Defined Function (UDF)はいつ出ますか?」ですが、本日出ました。まさに蕎麦屋の出前のようですね。お試しあれ。
Cloud DataflowとFlumeJavaとMillWheel
については長くなるので別の機会に...
Container
つづいて、Googleのコンテナ技術について。

皆さん、Googleのあらゆるサービスが、仮想マシン(VM)を使わずに運用されてるって知ってましたか?
という質問をYAPC会場でしてみたところ、10人ほどの方が手を挙げられてました。たぶん150〜200人くらいの方がいたので、Googleがガチガチのコンテナベースという事実は、まだあまり広く知られていないようです。
Google検索も、Mapsも、Gmailも、YouTubeもなにもかも、すべてBorgと呼ばれる、Googleが相当昔から秘伝のタレのように伝承してきたコンテナ技術の上で動いています。Borgは週に20億個のコンテナを起動しています。

最近のDocker人気にともなうコンテナ技術の普及に押されて、Googleはやっと今年4月にBorgのペーパーを公開しました。「……う、ウチだって昔からコンテナ使ってるし!」という感じでしょうか。

Large-scale cluster management at Google with Borg
そのBorgですが、コンテナとは言いつつも、Dockerとは使われ方や規模感がかなり異なります。こさき先生が「我々が知ってるコンテナじゃなくて独自実装のクソクソコンテナ」とつぶやいてましたが、たしかに完全クローズドソースな独自実装すぎるコンテナですw。
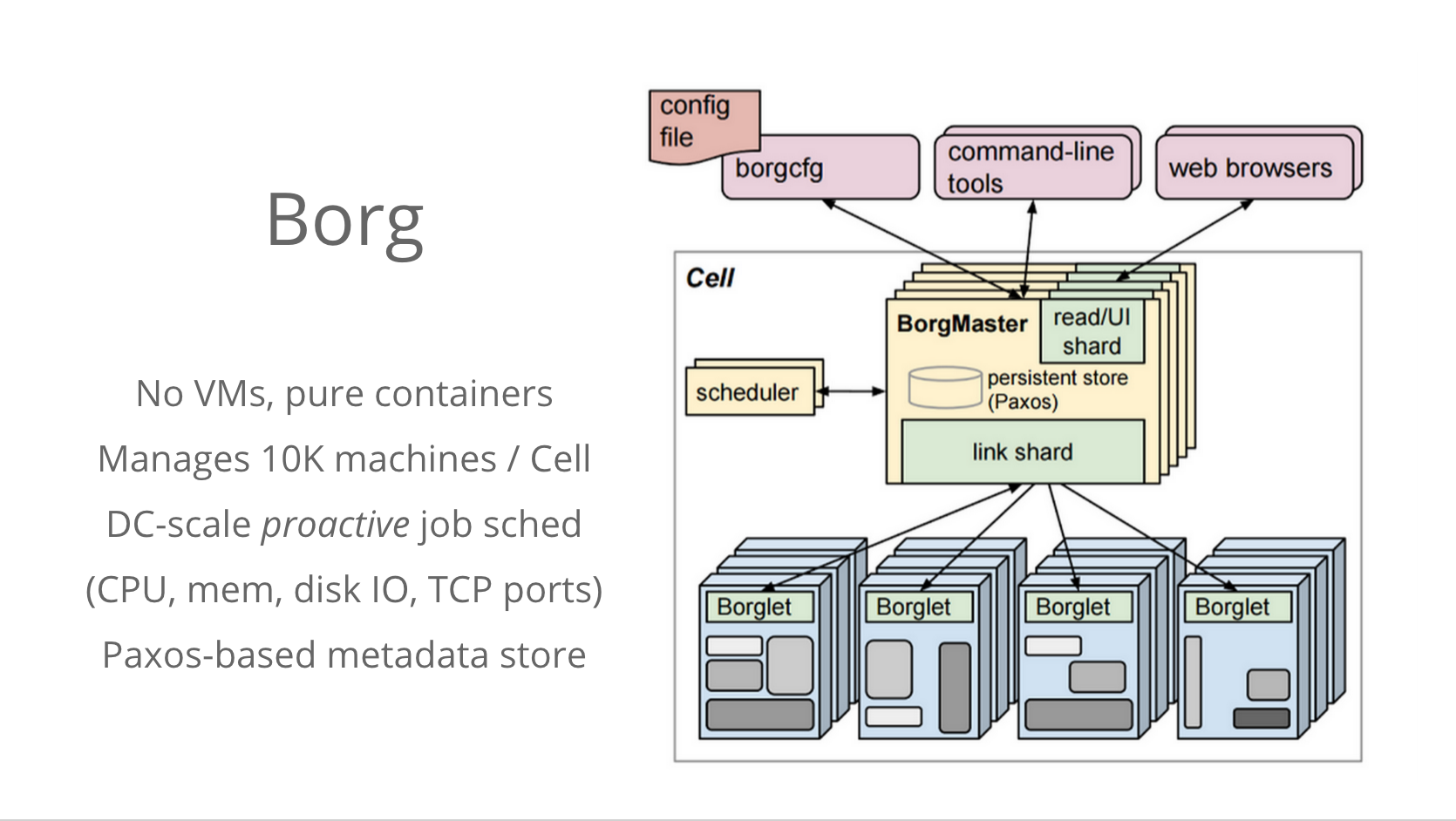
BorgはGoogle社内ユーザーによる利用のみを想定しており、マルチテナントやセキュリティ隔離は不要なため、ユーザー間を隔てるためにVMは必要としません。ベアメタルサーバーの上で直接Borgのコンテナ(Borgジョブと呼ばれる)を動かします。
また、Borgを司るBorgMasterと呼ばれるコントローラーは、1つでおよそ1万台のマシン(Borgセル)を管理します。その規模で、CPUやメモリ、ディスク、ネットワークといったリソースの配分を最適化するジョブスケジューリングを実施します。
以下のグラフは、昨年計測されたあるBorgセルのCPUおよびメモリ使用率グラフです。1つの縦線がマシン1台を表します。
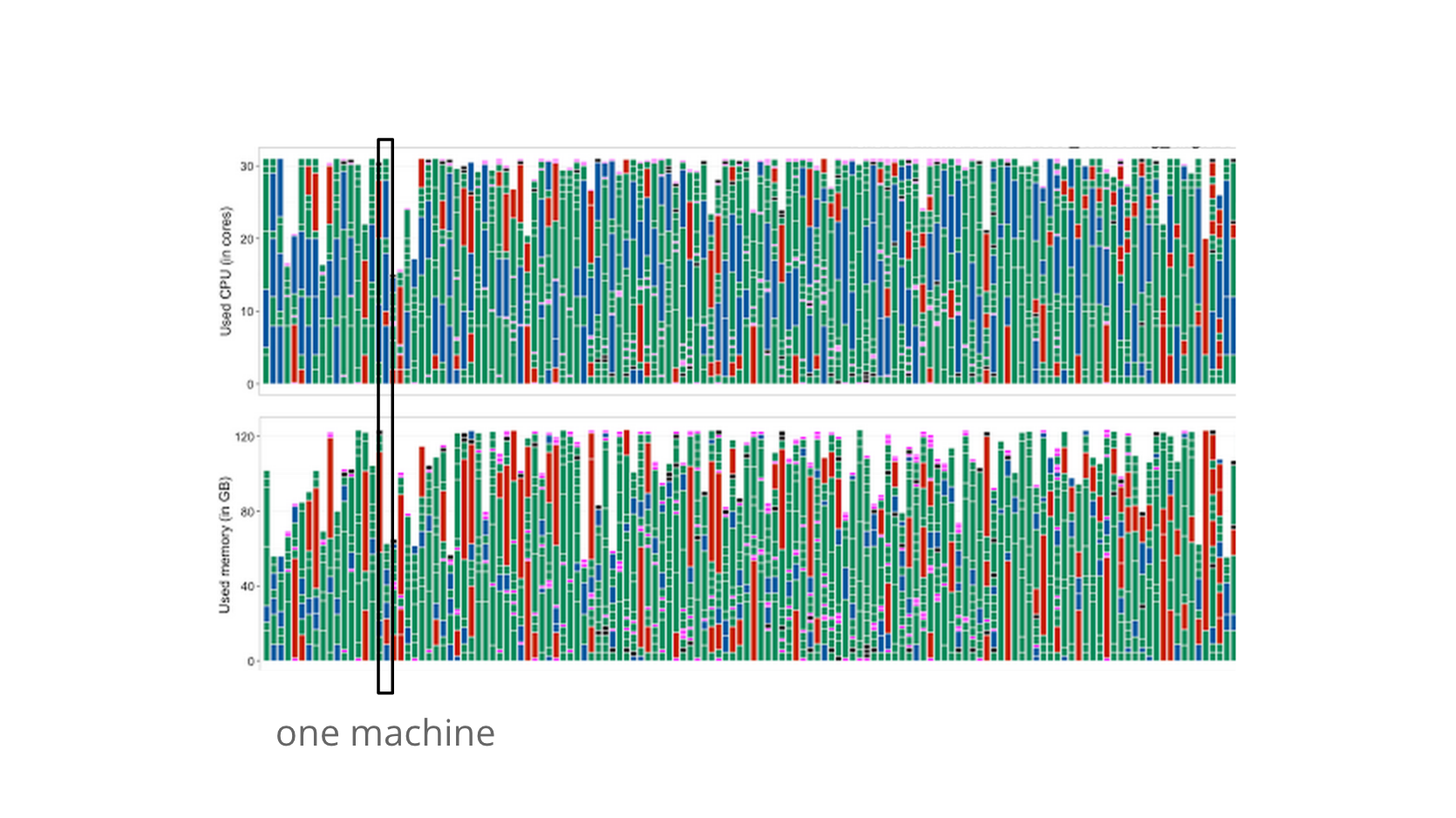
CPUのグラフを見れば、Borgセル全体のCPU利用率が相当に高いことが分かります。最近、データセンターのサーバーのうち1/3はゾンビサーバーという記事がありましたが、一般的なデータセンターの平均CPU利用率っておそろしく低いですよね。いざというときにリソースに空きが無いと誰かが怒られますから。
それと比較すれば、さまざまなサービスを多数のサーバーに薄く広くデプロイメントし、データセンター規模のジョブスケジューリングを行うことで得られるコストメリットは、明らかかと思います。さらにBorgは、その規模の大きさを生かして、時期や時間帯に基づくリソース消費の事前予測を行い、データセンター規模のオーバープロビジョニングやリソース配分最適化を行います。もはや電力会社です。
ということで、GoogleはVMを使っていない。そしてGoogleだけでなく、FacebookもプロダクションサービスにVMは使っていないそうです。世の中の「クラウドサービス」のかなりの割合がVMなしで運用されています。俺はいつから「クラウド=VM」と錯覚していた? と問いたくなります。確かに、マルチテナント環境においてはVMはセキュリティ隔離という役割を担いますが、単なる「アプリケーションの入れ物」として細かくVMを切って、個々のVMの起動をじーっと待ったりOSイメージを個別に保守したりするのは、あまり効率的な方法ではないようです。
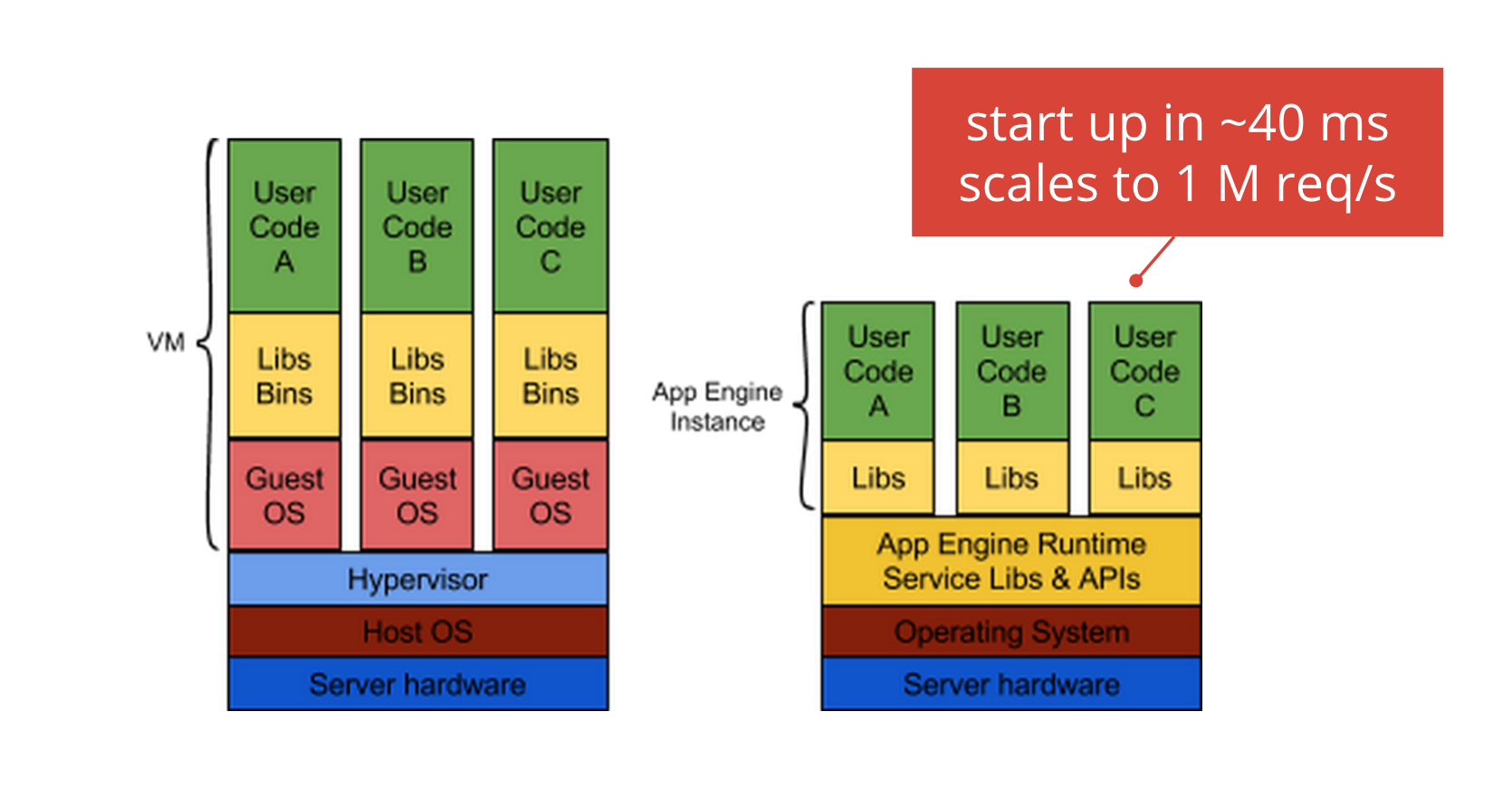
Google App Engine: みんなのBorg
そうしたBorgのコンテナ技術のメリットを、わりとそのままGCPユーザーに提供するサービスがGoogle App Engineです。App Engineのインスタンスは、Borgのコンテナそのものです。
App Engineの不運なところは、これまでGoogleがBorgやコンテナ技術についてまったく公開せず、VMに対するメリットがあまりきちんと説明されてこなかったことです。その一方で、例えば「App Engineのインスタンスはステートレス設計にすべし」などの制約事項が多く、なんだかこのPaaS使いにくいなー独自だなーHerokuの方が普通だなーというイメージが根強かった。
でも、コンテナ技術の普及のおかげで、App Engineのメリットは説明しやすくなりました。また、Blue-Green DeploymentやImmutable Infrastructureの考えが浸透したので、フロントエンドを極力ステートレスかつポータブルに設計する意義も理解されやすい。そうした制約事項は、結局のところ、Google社内の設計プラクティスや運用形態を反映したものです。だからApp Engineのアプリは、特別な設計をせずとも、データセンターがまるごと落ちた時でも他のデータセンターに瞬時にフェイルオーバーできる。
そうしたApp Engineの尖った部分を積極的に取り入れてきたSnapchatやApplibot等のユーザーは、例えばインスタンスの起動時間が40ms(Goの場合)といったアホみたいなスケーラビリティの高さ、ポータビリティの高さのメリットを享受しつつ、インフラエンジニアのコストを極力抑えたサービス運用を行ってきました。Snapchatは先日、App Engineで1M req/sを達成しました。IngressもApp EngineとBigtableで動いてますが、あまり広く知られていないですね。
このクローズドソース野郎!
デメリットにも触れておきましょう。App Engineは基本、クローズドソース野郎です。Datastoreにたんまりデータを溜め込んだりしたら確実にベンダーロックインされます。たまにデプロイが引っかかったりするけど、諦めて待つしかありませんね……。それに、httpd部分はGoogle Front EndというGoogleの全サービス共用のhttpdを使っており、スケーラビリティ&セキュリティ最強といったメリットはあるものの、現時点はWebSocketやNode.js等に対応してません。リアルタイム系が弱い。Java/Python/Go/PHPは対応してるけど、RubyやPerlその他の言語は使えません。そういう用途にはIaaSであるGoogle Compute EngineかManaged VMをお使いください。
k8sとGKE - オープンソース野郎と呼ばれたい...!
GCPだってオープンソースコミュニティにまざりたい……! そこでGoogleでは、Borgの運用で得た知見を、DockerベースのオープンソースのオーケストレーションツールKubernetes (k8s)の開発に投入しています。
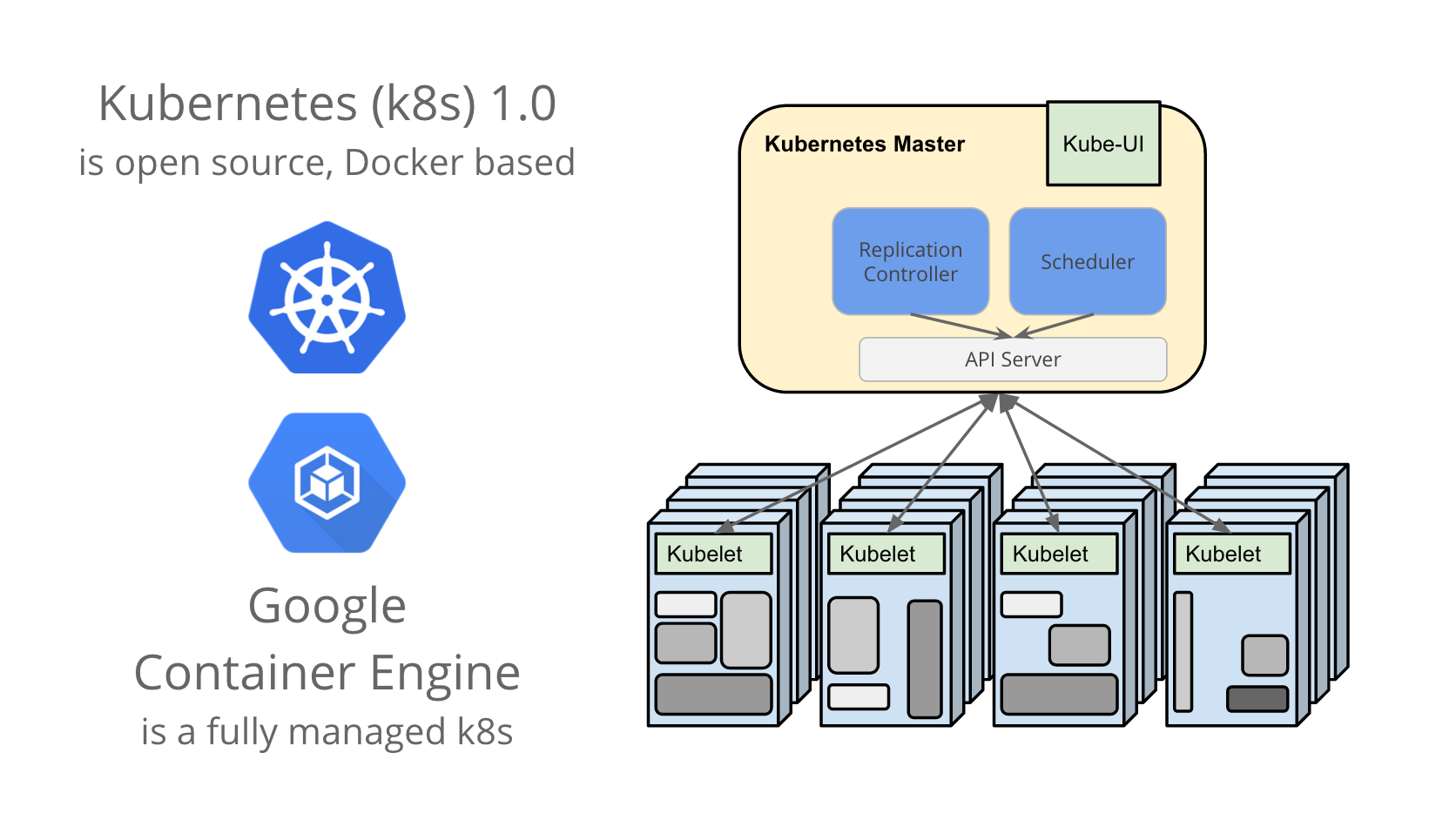
そのk8sのフルマネージド版がGoogle Container Engine (GKE)。App Engine時代からGCP時代へと大きく変わった点は、このk8sとGKEのように、できるだけオープンソース技術とGoogleのクラウド技術を統合し、外部のデベロッパーにとってベストな製品(=クローズドソース野郎と言われにくい製品)の提供にフォーカスしている点です。k8s/GKEの完成度は発展途上ではありますが、今後のGCPの各種サービスはGCEとk8sを基盤に構築されていく予定です。
Nearline: いまやディスクI/Oが高い
それともうひとつ、Borgのメリットを生かしたGCP製品が、Google Cloud Storage Nearlineです。Nearlineは、他社クラウドのバックアップサービスと同程度のコストながらも、読み出しまでに数時間も待つことなく2〜3秒でアクセスできるストレージサービスです。

実のところNearlineは、Google Cloud Storage (GCS)とまったく同じディスクを使って提供されています。では、なぜ価格をGCSの半分にできるのでしょうか? それは、いまやディスクはスペースよりもI/Oが高いからです。
ご存知のとおり、磁気ディスクのスピンドルあたりの容量はテラバイトクラスに拡大しましたが、シークタイムやアクセスタイムはほとんど伸びていません。あいかわらず数10msの時間がかかります。そのため、Borgによるデータセンター規模のリソース配分を行う上では、ディスクサイズよりもディスクI/Oの方が貴重な資源となっています。
台湾データセンターの中を見ていちばん印象的だった光景は、何万台というサーバーすべてにおいて、ディスクアクセスを示すLEDがつねに途切れなくチカチカしていた点です。そんなデータセンター、見たことありますか? 普通は、一部のサーバーだけ不連続にチカチカする感じですよね。つまりGoogleのデータセンターでは、Borgによるリソース配分最適化によってディスクI/Oの負荷を数万台にまんべんなく分散できています。
だからこそ、I/Oがほとんど発生しないとあらかじめ分かっているNearlineに対しては、同じディスクなのにぐんと低い価格を提示できます。バックアップ用の特別なストレージデバイスを用意する必要はありません。
Networking
次に、Googleのネットワーク技術。

Googleは、ネットワーク基盤をゼロから構築しています。ファイバーの敷設から、ネットワークスイッチの開発まで、フルスクラッチです。でもこれは「Datacenter as a Computerをつくる」という観点からはとても理にかなっていて、先ほどのDremel/BigQueryの「?」部分で触れた「データセンターをまるごと1台のコンピューターとしてしまう」ために欠かせない要素となっているように思います。

Google最新のネットワーク基盤はJupiterと呼ばれ、その詳細が今年6月に一般公開されました。

Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network
Jupiterは、特殊なバックプレーンを備えたベンダー製の高価なハイエンドスイッチを用いる代わりに、比較的小規模な自社製スイッチでClosトポロジーと呼ばれる五月雨式の多段構成を組むことで、全体として広い帯域を確保する設計になっています。10Gbps接続のサーバーを10万台収容可能で、合計1Pbpsを提供。まだSoftware Defined Network (SDN)としての性質を備え、ソフトウェアやアプリケーション側と連携してすばやく仮想LANを設定する機能を備えます。
台湾のデータセンターでは、ついにRJ45を見つけることはできませんでした(すみっこに何本かあったかも)。基本、ファイバーしかありません。
Jupiterのメリットを体感できる分かりやすい例が、Google Compute Engine (GCE)のネットワーク機能です。
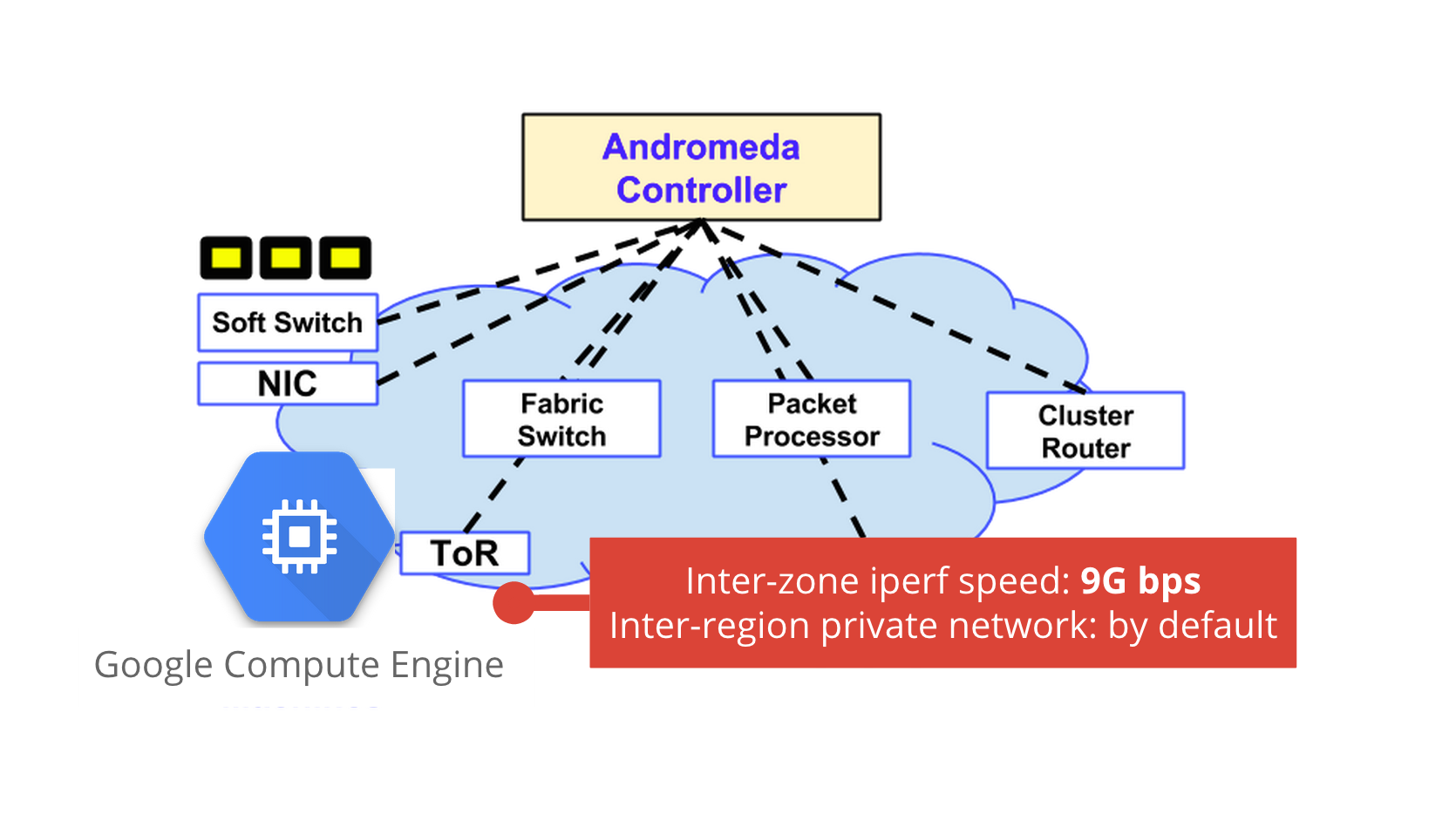
Enter the Andromeda zone - Google Cloud Platform’s latest networking stack
ゾーン間のiperfで9Gbps
例えば、異なる2つのゾーンにGCEのインスタンスを作成し、iperfコマンドで帯域を計測すると、9Gbpsくらい出ます。これ、速いですよね。まだあまり使われてないからでしょうか?
また、GCPではプロジェクトを作成するとその下に任意のリージョン(US、EU、Asia)のGCEインスタンスを作成できるのですが、なんにも指定せずとも、リージョンをまたいだデフォルトのプライベートネットワークが勝手にできてしまいます。VPC設定等を行う必要はいりません。これは、Jupiterに備わるSDNのメリットです。
google.comが温めてるロードバランサー
GCEのロードバランサー(GCE LB)も、Googleクラウドらしさをフルに生かしたネットワークサービスです。GCE LBは、基本「あっため」が不要です。いきなり1M req/sをさばける能力を備えています(下図の右側のグラフ)。なぜなら、google.comやGmail等、世界中のGoogleサービスのユーザーがつねに温めてくれているからです。
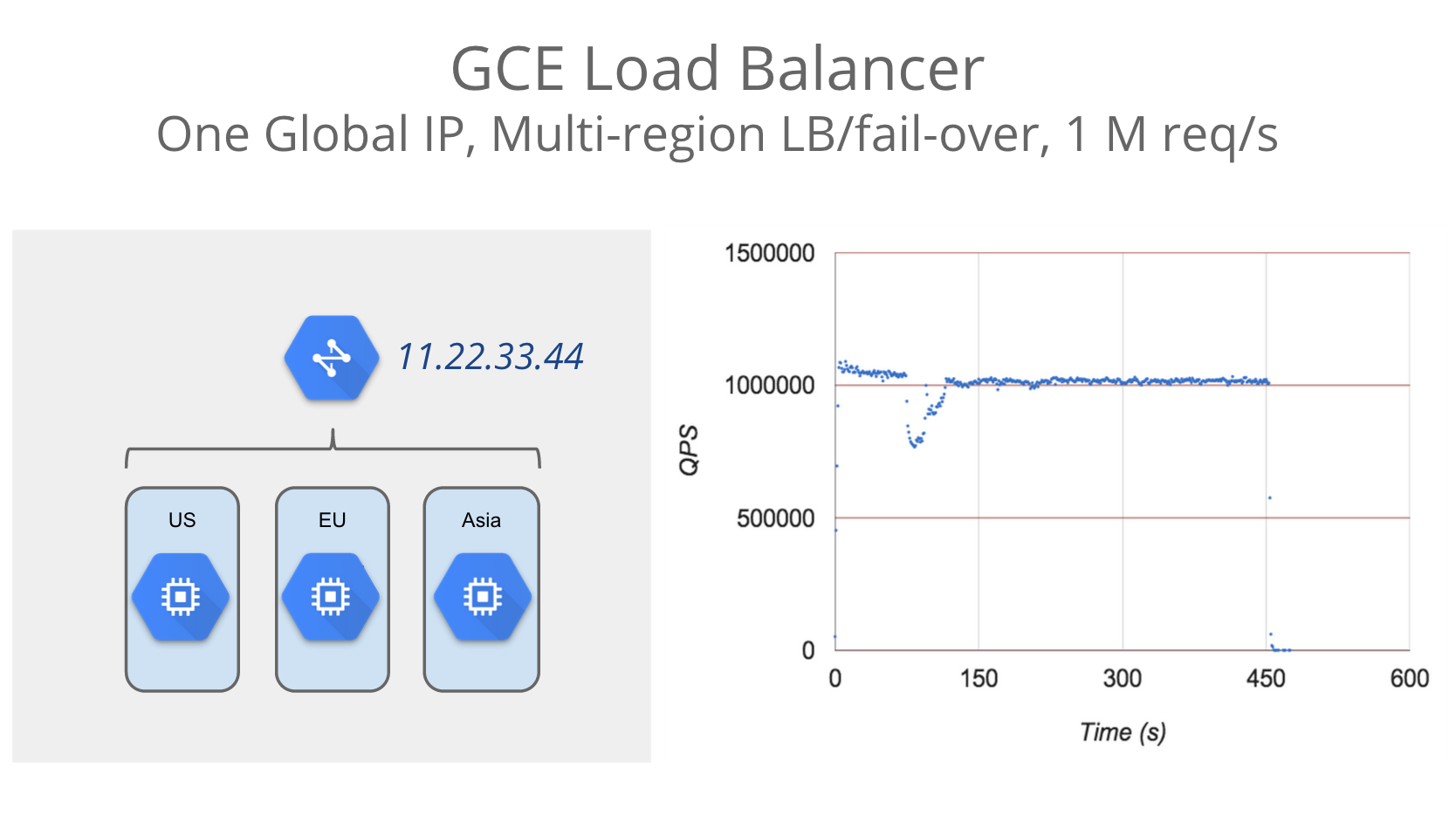
Unveiling scalable HTTP load balancing across cloud regions
ですからもし、GCE LBがダウンしている時は、google.comもおそらく落ちてますね。
一年ほど前にMountain View本社をうろうろしていたら、GCE LBのTech Leadとたまたま会ったので「1M req/sって性能、すごいね〜」と伝えたところ、「いや、あれは負荷クライアントがそれしか用意できなかっただけで、うちのLBは性能上限がないから」と言われました。アッ、ハイ。
TCP anycast
もうひとつ、これ頭おかしいと思ったGCE LBの機能、それは「グローバルIPひとつでリージョン間負荷分散+フェイルオーバーする」という点。これもGCP専用の機能ではなく、GoogleのPublic DNS「8.8.8.8」等でも以前から利用されている、Googleクラウド全体で備える機能です。
8.8.8.8って、どこか1台のサーバーやロードバランサーで受けてると思いますか? もちろん、そんなことはないです。
面白いことに、8.8.8.8は日本から見ると台湾データセンターに見えて、米国内ではUSデータセンター、ヨーロッパではEUデータセンターにパケットがルーティングされます。つまり、BGPの経路情報がリージョンによって異なるのです。いわゆるAnycastというやつです。しかし、TCPでAnycastを運用しようとすると問題となるのは、経路情報が変化したときにTCPコネクションが切れてしまうこと。でもなぜかGoogleのネットワークでは、この問題が起きません。不思議ですね。
GCE LBでは、この仕組みを使って、DNSラウンドロビンが不要な単一グローバルIPによるリージョン間フェイルオーバーと負荷分散を実現しています。実際の動作については、試していただいている方の記事が参考になります。GCEインスタンスを落とすと数秒で別リージョンのインスタンスに切り替わります。
こなれてない点
ネットワークについても、ダメな点を指摘しておきましょう。YAPC会場でもご指摘をいただきましたが、GCE LBは出てきたばかりの製品なので、まだこなれてない部分もあります。
GCE LBの内部では、たくさんのノードで負荷分散を負荷分散してます。それら多数のノードが、GCE上で動作するnginx等と間でHTTP Keep-Aliveのコネクションを個別に張る仕組みです。そのため、リクエストを重ねるうちに数百、数千のコネクションが生じ、同時接続数の耐性の低いWebサーバーにおいて問題となります。
以前その問題を中の人に伝えたところ、「別に数千とか張りっぱなしで平気でしょ」って返答が……。そりゃGoogleではそういうの平気でしょうけど。というわけで、これが問題となる場合は、現時点ではHTTPのKeep-Aliveをオフにするか短い時間に設定する必要があります。
The Future(力尽きた)
最後の「The Future」ですが、

YAPCトークでは、Jeff Deanが中心となって開発が進められているディープラーニングについて簡単に紹介しました。

が、ここまで書いて私も力尽きてきたので、
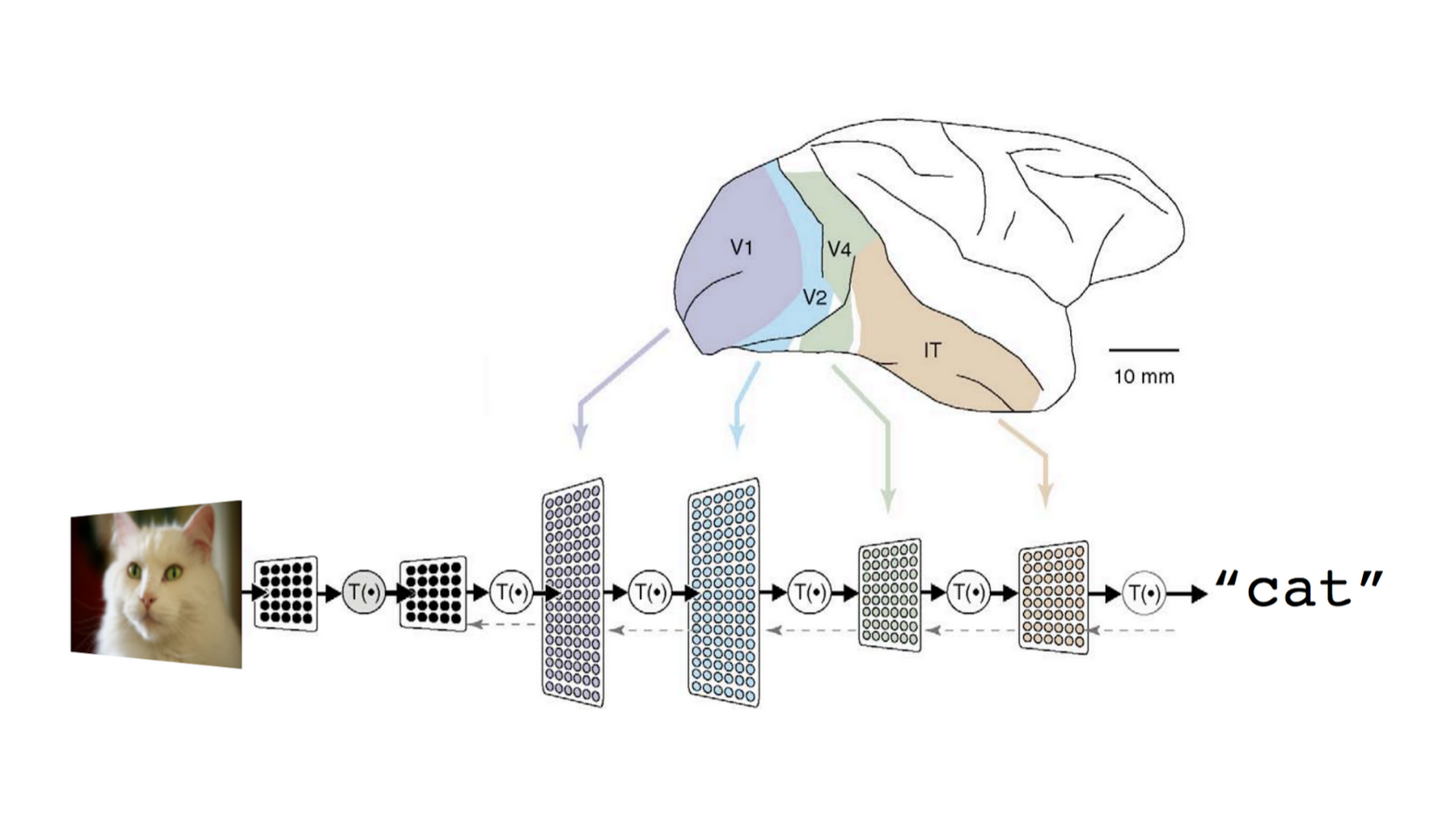
スライドをご覧いただければなんとなく内容もつかめるかと。
ひとつ言えることは、ディープラーニングはGoogleフォト等のサービスですでにプロダクション投入されており、研究段階の技術ではないということ。
とりわけGoogleでは、ディープラーニングの学習をスケールアウトさせるところに強みを持っています。専門家の皆さんのお話を聞くと、この部分って難しいようです。例えばGPUを使ってニューラルネット演算のアクセラレーションを行う場合、GPUノード間の大量のデータ受け渡しでネットワークのレイテンシが発生し、がくんと遅くなる。ここをどうするか、ですね。以下の図のように、モデルをいい感じに依存性少ない部分で切り分けてパーティショニングしたり。
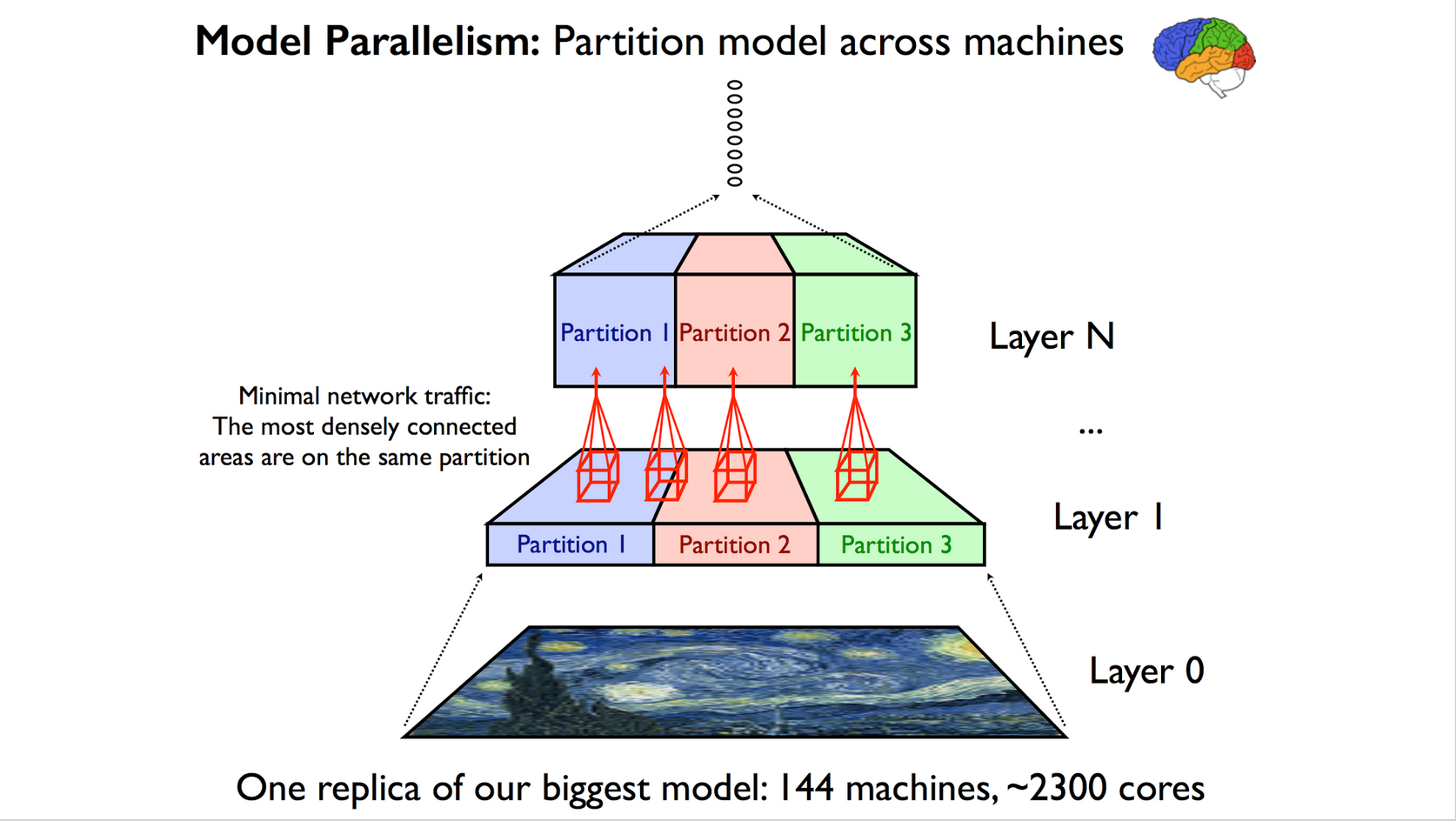
あとは、やはり多数のノード間で大量のデータを低レイテンシでやりとりする仕組みがカギとなります。さっきも同じフレーズが出てきたような。
そして、そうしたGoogleの強力なディープラーニング基盤を外部のデベロッパーに提供する動きが始まりつつあります。

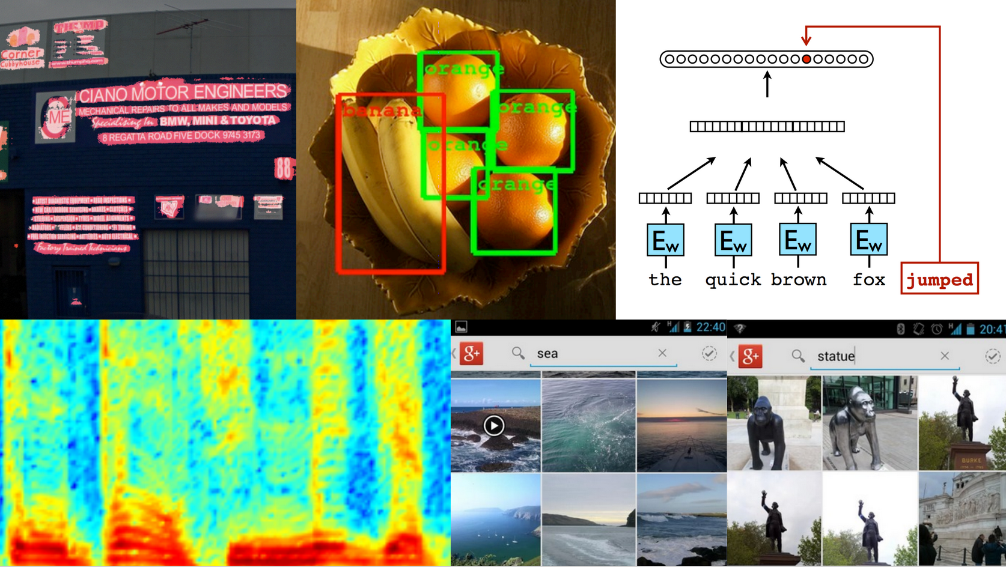
その第一弾が、AndroidのGoogle Play servicesで先日リリースされたVision APIです。顔検知機能を提供し、顔のランドマーク(目や鼻、口の位置など)、感情(怒ってる/笑ってる/悲しんでる)、顔の向きなどを任意の画像から検出します。
この調子で、今後もGoogleのディープラーニング技術をデベロッパーが簡単に利用できるようになればいいな〜と期待しています。
まとめ
以上、このトークでは、Googleクラウドを特徴付ける4つの技術、Big Data、Container、Networking、そしてディープラーニングについて見てきました。
ここまでの説明で、Googleクラウドとそのデータセンターは「単なるサーバの集合体」ではないことがお分かりいただけたかと思います。やっぱりGoogleのエラい人達は、Datacenter as a Computerの考えをさらに一歩進めたいのかな、という印象を私は持っていますし、最近投入されている新技術はその傾向をさらに強めています。そうしたGoogleクラウドの特性を知れば、マルチクラウド構成におけるGCPの「使いどころ」も見えてくるかと思います。GCP、楽しんで使ってくださいね。

Disclaimer この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。