本記事は New Relic Advent Calaendar 2021 の14日目のエントリーです。
Observabilityを実現する上で、複数台構成で動くサービスのホスト一台あたりのメトリクスやアラートはそんなに重要じゃなかったりしますよね。
そんなわけで、New Relicのテレメトリデータ量を最適化した話です。
(ちょっとした失敗談も含んでいます![]()
Infrastructure host
見直しポイント1:Metrics送信間隔
デフォルトの間隔が短いと感じた為、以下のように広げました。
| 設定値 | デフォルト値 | 変更後の値 |
|---|---|---|
| metrics_system_sample_rate | 5 | 180 |
| metrics_process_sample_rate | 20 | 180 |
| metrics_storage_sample_rate | 20 | 180 |
| metrics_network_sample_rate | 10 | -1(無効化) |
| (単位:秒) |
見直しポイント2:プラグイン設定のデフォルト設定を無効化
デフォルトではすべてのプラグインが有効化されている為、デフォルト設定をオフに変更し、必要なものがあったときに有効化していくような設定に変更しました。
disable_all_plugin: true
metrics_system_sample_rate: 180
metrics_process_sample_rate: 180
metrics_storage_sample_rate: 180
metrics_network_sample_rate: -1
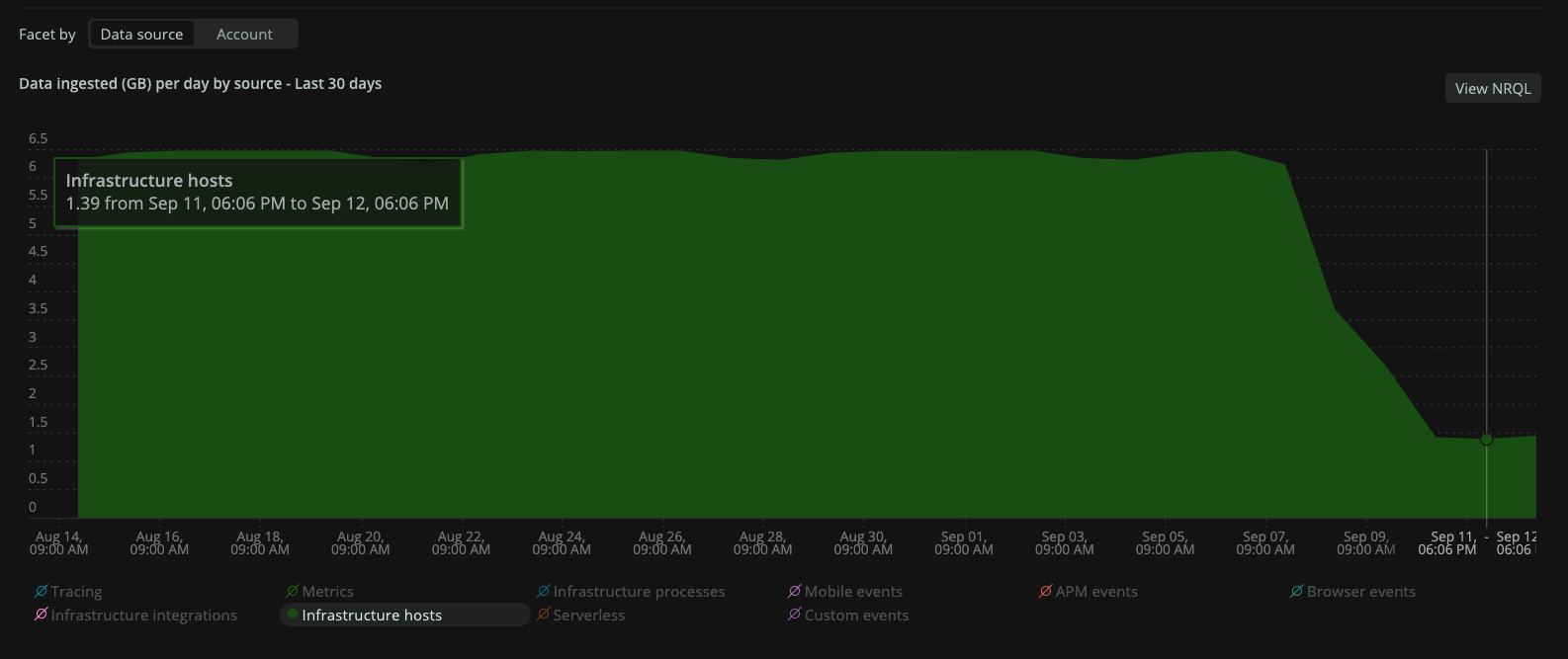
削減効果:75%減(当社比)
- 6.5GB/日 → 1.5GB/日
- 201.5GB/月 → 46.5GB/月
Infrastructure proccess
見直しポイント1:プロセス監視設定
プロセス監視が必要な場合、
enable_process_metrics
を true に設定します(デフォルト値は false )
これを有効にした場合は、必ず
include_matching_metrics の設定をして、監視対象プロセスを絞り込みましょう。
enable_process_metrics: true
include_matching_metrics:
process.name:
- regex "^java"
以下は、configで enable_process_metrics: true のみ設定し
対象プロセスの絞り込みをしなかった際の失敗例です ![]()
弊社の監視対象はEC2ホストよりFargateの比率がだいぶ高く、台数そんなに多くないのになんで??となって調べて気づきました。
enable_process_metrics: true のみで説明が終わるネット記事があるので要注意です。
昔の私たちと同様に気づいていない方がいるかも?
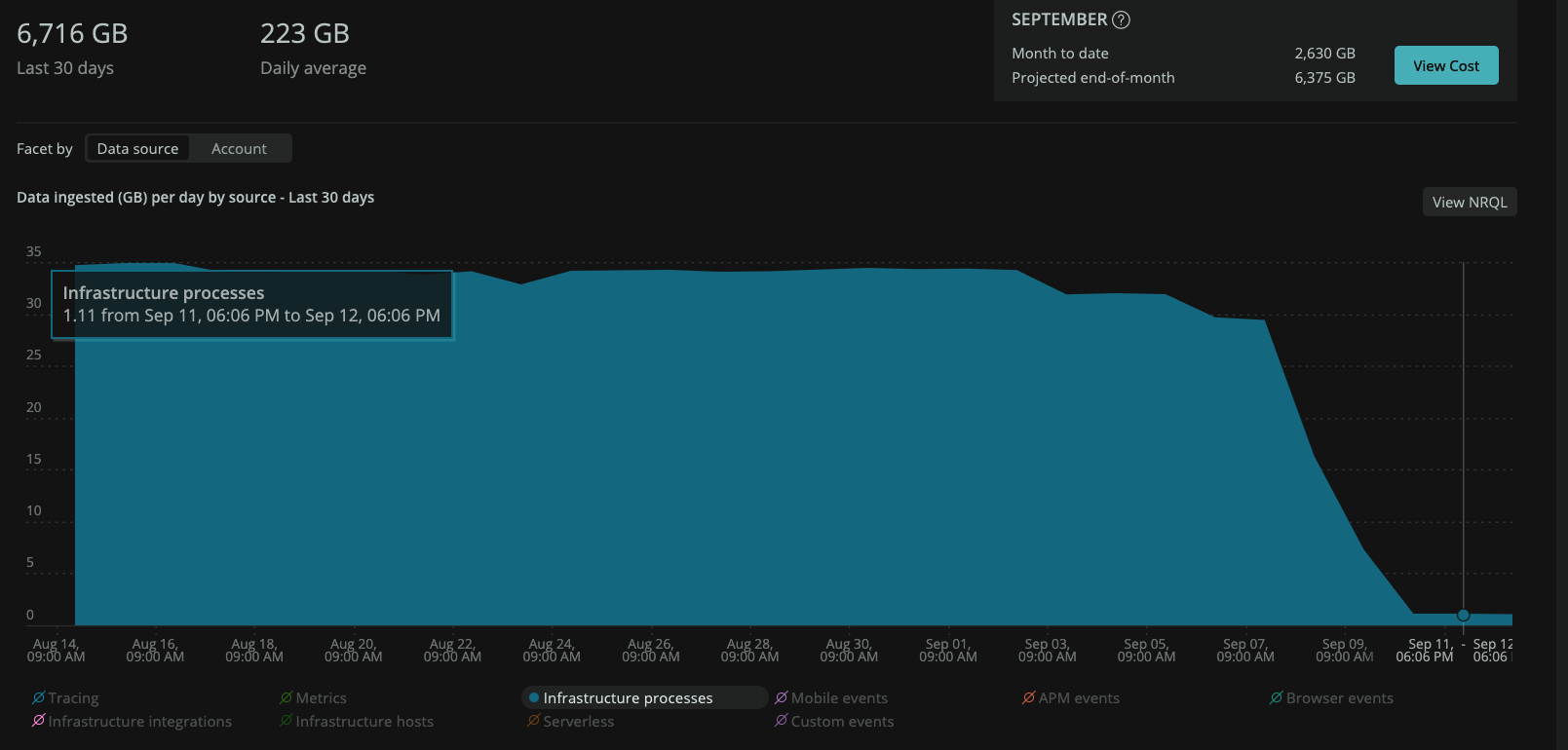
削減効果:当社比97%
- 35GB/日→1.2GB/日
- 1085GB/月→37.2GB/月
ちゃんと対象プロセスの絞り込みをすることで、当社比97%の削減に成功しました!(良い子は真似しないでね
Tracing
見直しポイント1:Distributed Tracingの必要可否を考える
マイクロサービスアーキテクチャを採用したシステムではトラブルシューティングをする上で非常に強力な機能かと思いますが、シンプルな作りのアプリケーションの場合、有効化してもあまり見る機会がなかったり、きちんと設定されていないとあまり有用な情報が出力されず、使いこなせていないケースも存在するかと思います(そしてデータ量も結構大きめです)。
そんな時は、一旦Distributed Tracingを無効化して本当に必要になった際に再度導入を検討されてみてはいかがでしょうか?
有効化・無効化の手順はAPM,Browser,Mobile等で様々なので割愛します。
Mobileでは現在デフォルトで有効になっているようです。
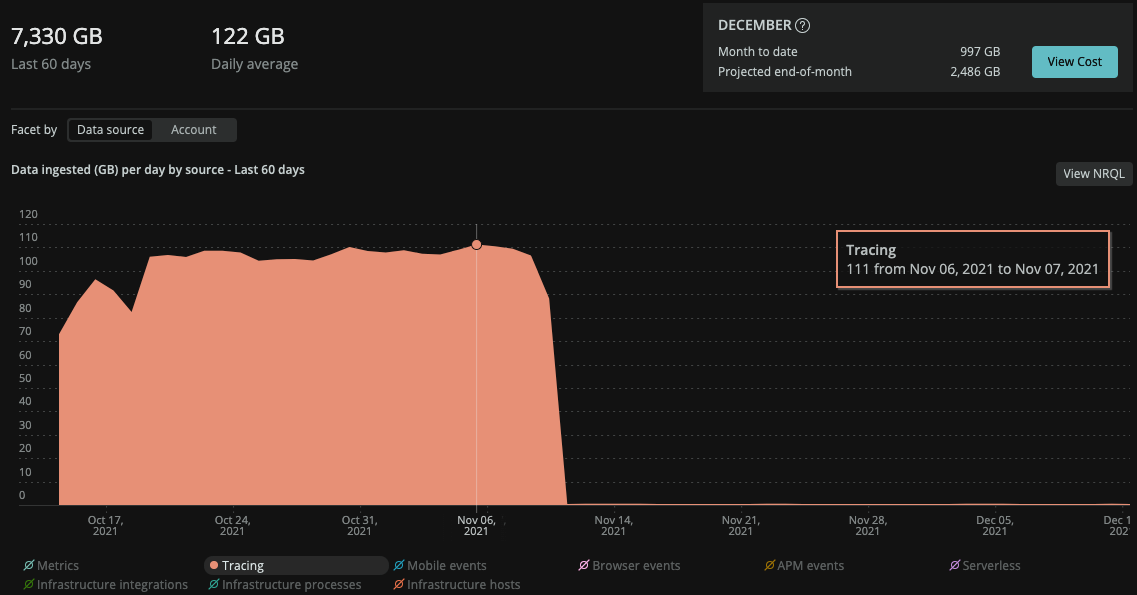
削減効果:当社比100%
- 122GB/日→0GB/日
- 7330GB/月→0GB/月
まとめ
いかがでしたでしょうか?
ちょうど契約更新タイミングが近かったこともありテレメトリデータ量の見直しについてまとめてみました。
ちょっとした小ネタでしたが、少しでも参考になれば幸いです。