本日は12/24です。何の日か、みなさんお分かりですよね?🎅
そう、みんな大好き有馬記念の日です。🐎
ボートレースファンからはグランプリの優勝戦の日だろ!という主張もありそうですが、今回は数年ぶりに競馬予想ネタを書きたいと思います。
私自身、過去に2回、競馬予想をテーマにした記事を掲載してきました。
レースは相対評価で予想したい
過去記事では、ロジスティック回帰やランダムフォレスト等を使用してましたが、実は違和感を少々感じていました。それは、データセット全体から絶対評価で、購入対象馬を予測しているからになります。
ちょっと分かりにくいかもしれませんが、例として、以下のデータセットの場合、レース番号に関係なく、賞金の高い馬が購入対象になりやすいという傾向があります。
| レース番号 | 馬番 | 馬名 | 獲得賞金 | 予測結果 |
|---|---|---|---|---|
| 1R | 1 | アアアアア | 100万 | 0(買わない) |
| 1R | 2 | イイイイイ | 200万 | 0(買わない) |
| 1R | 3 | ウウウウウ | 300万 | 0(買わない) |
| 2R | 1 | カカカカカ | 400万 | 0(買わない) |
| 2R | 2 | キキキキキ | 500万 | 0(買わない) |
| 2R | 3 | ククククク | 600万 | 1(買う) |
| 3R | 1 | サササササ | 700万 | 1(買う) |
| 3R | 2 | シシシシシ | 800万 | 1(買う) |
| 3R | 3 | ススススス | 900万 | 1(買う) |
ところが、競馬というものは、レースに出走する馬の中から、以下の例のように、勝ち馬を見つければいいわけで、相対評価での予測が適していると言えます。
| レース番号 | 馬番 | 馬名 | 獲得賞金 | 予測結果 |
|---|---|---|---|---|
| 1R | 1 | アアアアア | 100万 | 0(買わない) |
| 1R | 2 | イイイイイ | 200万 | 0(買わない) |
| 1R | 3 | ウウウウウ | 300万 | 1(買う) |
| 2R | 1 | カカカカカ | 400万 | 0(買わない) |
| 2R | 2 | キキキキキ | 500万 | 0(買わない) |
| 2R | 3 | ククククク | 600万 | 1(買う) |
| 3R | 1 | サササササ | 700万 | 0(買わない) |
| 3R | 2 | シシシシシ | 800万 | 0(買わない) |
| 3R | 3 | ススススス | 900万 | 1(買う) |
ランキング学習を使ってみる
そこで、ランキング学習というものに興味を持ちました。ランキング学習は、Googleの検索エンジンが、検索キーワードごとに表示順位を決めているように、相対的な順位を予測する場合に使用される学習方法です。
今回使用した機械学習アルゴリズムは、LightGBMです。LightGBMでは、勾配ブースティングという手法を使って、ランキング学習を簡単に導入することが可能です。
LightGBMには、2種類のAPIが存在します。
| API | 特徴 |
|---|---|
| Training API | trainメソッドで学習する |
| Scikit-learn API | sklearnのI/Fで使用でき、fitメソッドで学習する |
主には、学習処理のI/Fが異なるという違いのようで、私の場合はsklearnに馴染みがあるので、Scikit-learn API(LGBMRankerクラス)を使用しました。
データセットの作成
お決まりの学習と予測で使用するデータセットを作成します。実施内容の詳細は過去の記事を参照してください。
今回作成したデータセットはこちらです。
- 集計期間:2015年1月 〜 2023年12月
- 対象レース:中山競馬場の芝レース
| データ項目 | 用途 |
|---|---|
| race_index | index |
| 馬番号 | 説明変数 |
| 単勝オッズ | 説明変数 |
| 距離 | 説明変数 |
| 種牡馬入着率1 | 説明変数 |
| 種牡馬入着率2 | 説明変数 |
| 種牡馬入着率3 | 説明変数 |
| 騎手入着率1 | 説明変数 |
| 騎手入着率1 | 説明変数 |
| 騎手入着率3 | 説明変数 |
| ペース1 | 説明変数 |
| ペース2 | 説明変数 |
| ペース3 | 説明変数 |
| 先行力1 | 説明変数 |
| 先行力2 | 説明変数 |
| 先行力3 | 説明変数 |
| 獲得賞金1 | 説明変数 |
| 獲得賞金2 | 説明変数 |
| 獲得賞金3 | 説明変数 |
| 経過日数 | 説明変数 |
| 着順関連度 | 目的変数 |
以下、データ項目の説明をします。
index (race_index)
開催されるレースを特定した識別IDです。
indexにする必要は必ずしもないですが、学習や予測では、使用しない値のため、便宜上index化してます。
説明変数(馬番号 〜 レース経過日数)
こちらは、予想ファクターになりえるデータを設定していますが、ここが予測精度の肝になります。皆さんも、お好きな変数を採用してみてください。
目的変数(着順関連度)
こちらは、正解を学習させるためのデータになります。教師データとも言います。
今回は以下の通り、実際のレース結果の上位3頭までに、関連度を降順で設定しています。
| 着順 | 着順関連度 |
|---|---|
| 1 | 30 |
| 2 | 28 |
| 3 | 26 |
| 4 | 0 |
| 5 | 0 |
| ... | ... |
| 17 | 0 |
| 18 | 0 |
注意としては、LightGBMにおけるランキング学習のデフォルト設定では、目的変数(関連度)は整数値で30が上限になります。
実際のデータセットはこのようになります。
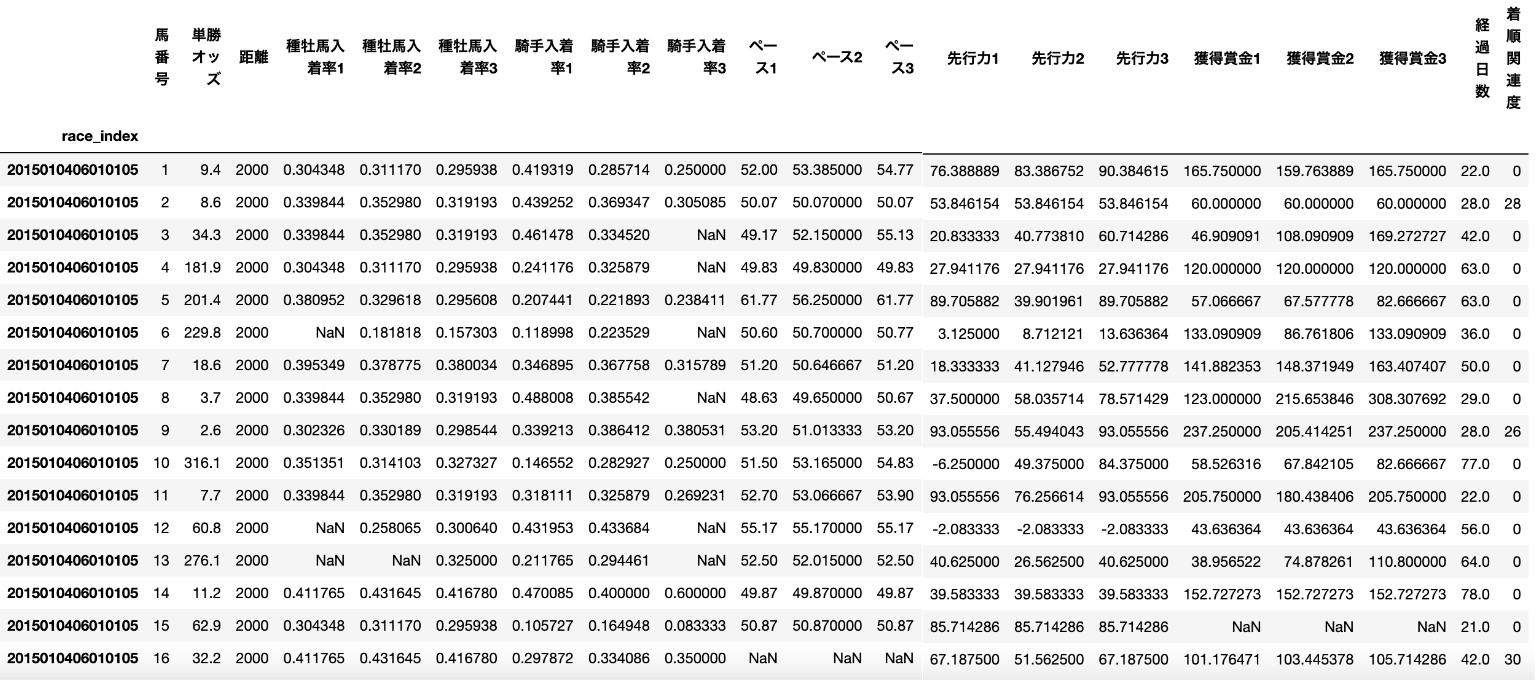
ランキング学習の実装サンプル
前段で作成したデータセットがdfという変数に格納されているとします。
import pandas as pd
# Dataframeにデータを格納(したとする)
df = pd.DataFrame()
データセットを説明変数と目的変数に分割
# 説明変数をdataXに格納
dataX = df.drop(['着順関連度'], axis=1)
# 目的変数をdataYに格納
dataY = df['着順関連度']
説明変数と目的変数を学習用と評価用に分割
まず、indexを時系列順に並べて、学習用と評価用に分割します。
# indexをユニークなリストに変換し、時系列順にソート
sorted_index_list = dataX.sort_index().index.unique()
# 8:2の割合で、学習用と評価用に分割
learn_count = round(len(sorted_index_list) * 0.8)
learn_index_list = sorted_index_list[:learn_count]
test_index_list = sorted_index_list[learn_count:]
※ 今回、サンプルに使用しているrace_indexは、以下の形式になっているため、時系列順にソートすることが可能です。ご自身の利用するデータに読み替えて、適切なソート処理を実施してください。
参考) race_indexのデータフォーマット
| 添字(レンジ) | データ長 | 項目説明 |
|---|---|---|
| 0〜3 | 4byte | 年 |
| 4〜5 | 2byte | 月 |
| 6〜7 | 2byte | 日 |
| 8〜9 | 2byte | 競馬場コード |
| 10〜11 | 2byte | 開催回次 |
| 12〜13 | 2byte | 開催日次 |
| 14〜15 | 2byte | レース番号 |
indexをさらに訓練用と検証用に分割します。
# 8:2の割合で、訓練用と検証用に分割
train_count = round(len(learn_index_list) * 0.8)
train_index_list = learn_index_list[:train_count]
valid_index_list = learn_index_list[train_count:]
indexリストを元に説明変数と目的変数の双方を分割します。
X_train = dataX.loc[train_index_list]
X_valid = dataX.loc[valid_index_list]
X_test = dataX.loc[test_index_list]
y_train = dataY.loc[train_index_list]
y_valid = dataY.loc[valid_index_list]
y_test = dataY.loc[test_index_list]
少々ややこしいですが、結果的に以下のようにデータ分割すればOKです。(分割割合に決まりはありません)
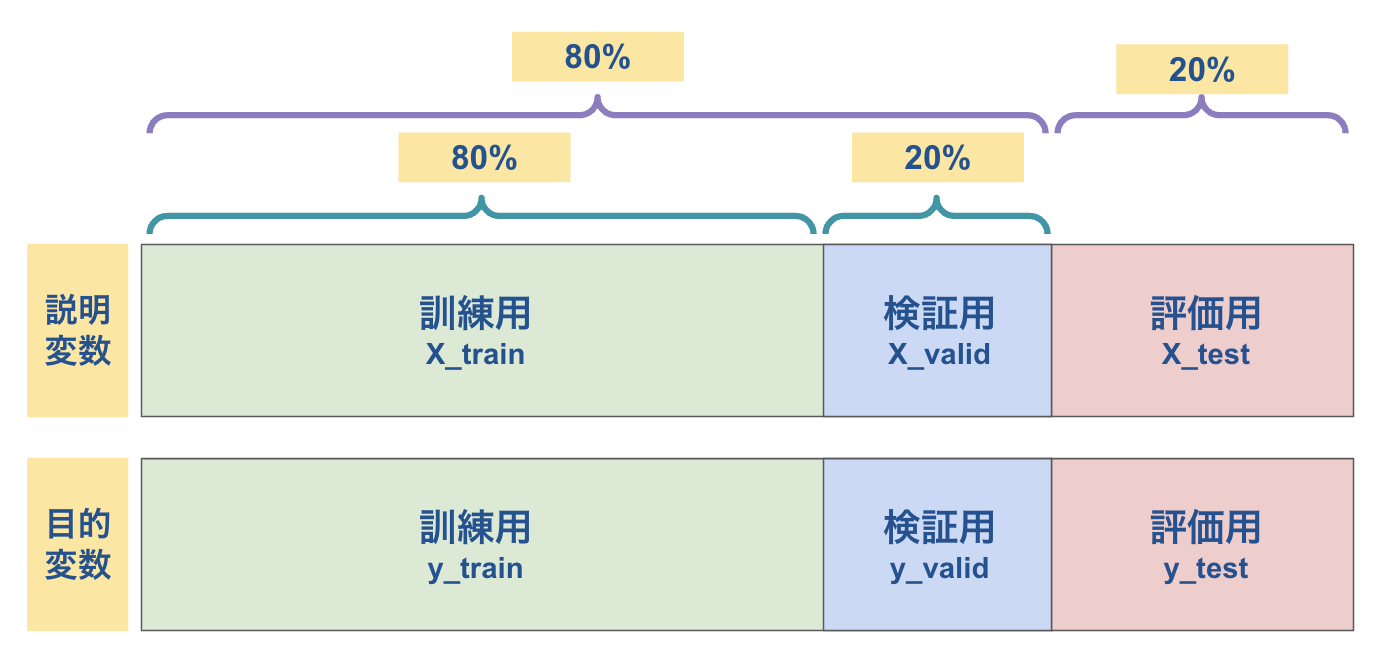
過去記事で実施した機械学習の場合、学習用と評価用の二種類のデータのみを使用していましたが、今回は検証用のデータが加わっています。これは、今回採用しているLightGBM(勾配ブースティング)によるものです。勾配ブースティングでは、イテレーションしながら、モデルの精度を高める仕組みがあり、そのために検証用のデータが必要になります。
ランキング学習で必要なクエリーデータを作成
# クエリーデータ(レース単位のデータ数のリスト)を作成
train_query = X_train.groupby('race_index').size().values.tolist()
valid_query = X_valid.groupby('race_index').size().values.tolist()
これが、相対評価を実現する肝になるデータです。レース単位のデータ数、つまりはレースの出走馬数のリストを作る必要があります。以下のケースでは、クエリーデータは [2, 3, 4]となります。
| レース番号 | 馬番 |
|---|---|
| 1R | 1 |
| 1R | 2 |
| 2R | 1 |
| 2R | 2 |
| 2R | 3 |
| 3R | 1 |
| 3R | 2 |
| 3R | 3 |
| 3R | 4 |
モデルの学習
ここまでの準備をしてから、ようやくモデルの学習を実行します。
import lightgbm as lgb
model = lgb.LGBMRanker(
random_state=100, # 乱数シード
n_estimators=500, # 決定木の個数(default:100)
learning_rate=0.01, # 学習率(default:0.1)
num_leaves=40, # 決定木にある分岐の個数(default:31)
max_depth=-1, # 決定木の深さの最大値(default:-1)
min_child_samples=150, # 一つの葉に含まれる最小データ数(default:20)
)
model.fit(X_train, y_train,
group=train_query, # 訓練用クエリーデータ
eval_set=[(X_valid, y_valid)], # 学習時に用いる検証用データ
eval_group=[valid_query], # 検証用クエリーデータ
early_stopping_rounds=100, # 性能が向上しないときに学習を打ち切るイテレーションの閾値
eval_metric='ndcg', # 学習時の評価手法
eval_at=[1, 2, 3] # 学習時の評価対象順位
)
LGBMRankerクラスに指定した各種オプション値は、環境に応じて適宜チューニングを実施してください。
fitメソッドのパラメータの説明は、コメントに買いた通りですが、eval_atに関しては、上位3位までが、競馬では的中対象になるため、[1, 2, 3]のリストを指定しています。
学習モデルを使用して、結果を予測
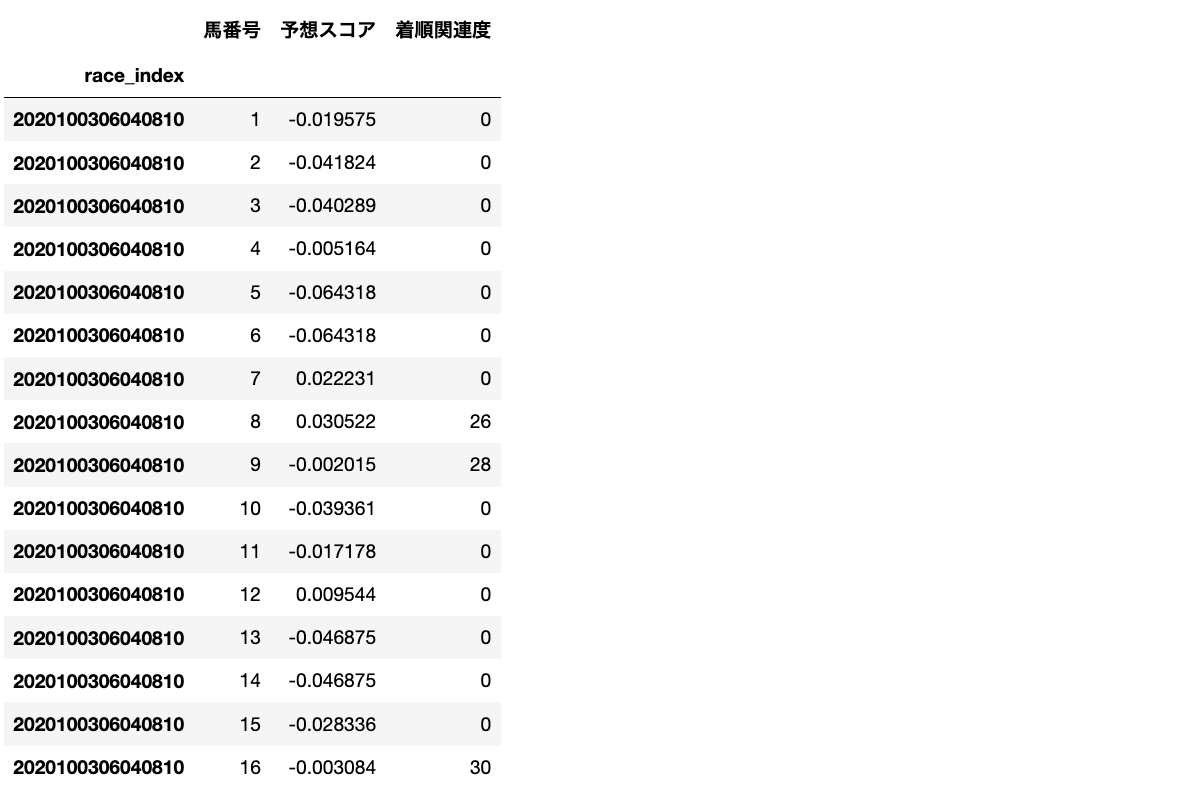
y_pred = model.predict(X_test, num_iteration=model.best_iteration_)
# 予測結果や関連度をDataFrameに連結
df_pred = pd.DataFrame({
'馬番号': X_test['馬番号'],
'予想スコア': y_pred,
'着順関連度': y_test,
})
predictメソッドの引数ですが、num_iteration=model.best_iteration_がポイントで、これを指定することで、検証時に最も精度が高かったイテレーション時の設定が採用されます。
予測結果(df_pred)のサンプルは以下の通りです。
モデルの評価
# クエリーごとにNDCGを計算し、その平均値を算出
ndcg_score = df_pred.groupby('race_index').apply(lambda d: ndcg_score([d['着順関連度']], [d['予想スコア']], k=3)).mean()
print(ndcg_score)
(出力結果)
0.5323389103782475
# 特徴量重要度の抽出
df_importances = pd.DataFrame({'columns':X_train.columns, 'importances':model.feature_importances_})
df_importances.sort_values('importances', ascending=False, inplace=True)
print(df_importances)
(出力結果)
columns importances
単勝オッズ 34
獲得賞金3 15
馬番号 12
種牡馬入着率3 12
種牡馬入着率1 9
獲得賞金1 9
先行力1 8
騎手入着率2 8
ペース1 7
騎手入着率3 5
ペース2 5
ペース3 5
騎手入着率1 5
先行力2 5
種牡馬入着率2 5
先行力3 4
獲得賞金2 4
経過日数 4
距離 0
ここでは、2つの評価指標を紹介します。
NDCG (Normalized Documented Cumulative Gain)
NDCGは、ランキング学習モデルの評価指標の一つで、生成したランキングが真の並び順にどれだけ適合しているかを評価します。今回はランキング3位までの評価を実施しています。0から1の範囲でスケーリングされ、1に近いほど良いランキングとなります。
特徴量重要度 (feature importance)
特徴量重要度は、各特徴量(説明変数)がモデルの予測に対してどれだけ影響を与えるかを示す指標で、説明変数の取捨選択に役立ちます。
モデルの保存と復元
最後に、構築した学習モデルを必要な場面でいつでも利用できるように保存します。
import pickle
filename = 'model.pickle'
pickle.dump(model, open(filename, 'wb'))
復元方法はこちらです。
import pickle
filename = 'model.pickle'
model = pickle.load(open(filename, 'rb'))
# 任意のレースを予測
y_pred = model.predict(予測対象レースの説明変数データ, num_iteration=model.best_iteration_)
有馬記念を予想してみる
まずは、構築した学習モデルを使って、過去2年分の有馬記念の予測結果がどうだったかを確認してみます。
2021年の予測結果
| 馬番 | 馬名 | 予想ランキング | 予想スコア(偏差値) | 人気 | 着順 |
|---|---|---|---|---|---|
| 10 | エフフォーリア | 1 | 71.627722 | 1 | 1 |
| 7 | クロノジェネシス | 2 | 61.886559 | 2 | 3 |
| 16 | タイトルホルダー | 3 | 61.202936 | 4 | 5 |
| 9 | ステラヴェローチェ | 4 | 59.686364 | 3 | 4 |
| 5 | ディープボンド | 5 | 54.278614 | 5 | 2 |
| 13 | アカイイト | 6 | 54.129245 | 6 | 7 |
2022年の予測結果
| 馬番 | 馬名 | 予想ランキング | 予想スコア(偏差値) | 人気 | 着順 |
|---|---|---|---|---|---|
| 5 | ジェラルディーナ | 1 | 61.409362 | 3 | 3 |
| 9 | イクイノックス | 2 | 60.565856 | 1 | 1 |
| 7 | エフフォーリア | 3 | 60.107762 | 5 | 5 |
| 13 | タイトルホルダー | 4 | 59.959483 | 2 | 9 |
| 10 | ジャスティンパレス | 5 | 59.893023 | 7 | 7 |
| 6 | ヴェラアズール | 6 | 58.089242 | 4 | 10 |
若干、人気順に引っ張られている感はありますが、大きく外してはいないという結果と言えます。
2023年(今年)の予測結果
それでは、今年の予測結果はこちらです。(12/24 1:00時点のオッズを使用)
| 馬番 | 馬名 | 予想ランキング | 予想スコア(偏差値) | 人気 |
|---|---|---|---|---|
| 5 | ドウデュース | 1 | 61.948174 | 2 |
| 1 | ソールオリエンス | 2 | 60.335332 | 6 |
| 10 | ジャスティンパレス | 3 | 59.382490 | 1 |
| 15 | スルーセブンシーズ | 4 | 59.226146 | 3 |
| 16 | スターズオンアース | 5 | 59.114727 | 7 |
| 4 | タイトルホルダー | 6 | 58.635826 | 4 |
記事投稿の都合上、かなり早い段階の単勝オッズを使用した予想となっています。
今年は、本命馬不在で、予想スコアも僅差となっているのが分かります。
これを参考にして、本日の有馬記念の買い目を考えたいと思います。それでは、良いクリスマスを。🎄