はじめに
この記事はさくらインターネット Advent Calendar 2025 11日目の記事です。
さくらインターネットでセールスエンジニア(プリセールス)をやっている鶴田です。
昨年に続いての記事投稿です。
今回は本日(2025/12/11)正式版としてリリースされたモニタリングスイートの記事を書いてみます。
本記事中に記載される各サービス仕様は執筆時点の内容となりますのでご注意ください。
さくらのクラウド 新サービスリリースでお祭状態
さくらのクラウドはガバメントクラウドに条件付認定を受けており、2026年3月末の認定に向けて開発を進めています。
諸々の都合から今年度下期に新サービスリリースが急ピッチで実施されていて、新サービスリリースを知らせるクラウドニュースが鳴りやまない状況=お祭状態になってます。
以前はIaaS中心だったさくらのクラウドにもアプリケーション連携周りのマネージドサービスが増えていて、更に活用の幅が広がっているのを感じています。
数々の正式版リリースされたサービスの中から個人的に関心が高いのは、新たな監視マネージドサービスであるモニタリングスイート です。
今回はモニタリングスイートへのメトリクス/ログ送信環境の実装パターンの検討と、シンプルなメトリクス送信環境構築を実践してみようと思います。
本記事の内容はあくまで[やってみた]レベルのため、実際に利用される際はご利用のシステム環境に応じた構成で十分に事前検証することをオススメします。
さくらのクラウド モニタリングスイートとは
モニタリングスイートは、システム監視を行うためのプラットフォームです。
さくらのクラウド・その他のクラウド・オンプレ等の多様な環境を一元管理し、可視化することができます。
オブザーバビリティの実現にも対応可能な監視プラットフォームであり、監視対象から収集されたメトリクス/ログ/トレースデータをサービスが用意するストレージへ保存し、ダッシュボードで可視化、アラート通知までをマネージドサービスとして提供します。
ユーザは専用のストレージ/ダッシュボード/アラート基盤を構築せずに監視基盤構築できるため、運用負荷を大幅に軽減することができます。

さくらのクラウド内のサービスについては、ルーティング機能を利用して各ストレージへ直接連携できますが、クラウド内のサーバや他社クラウド/オンプレミスといった環境は、モニタリングスイートの仕様に合わせてメトリクス/ログを送信する必要があります。
- マネージド範囲は各種データの保存ストレージ/可視化ダッシュボード/アラート通知です。
- クラウド環境内のサーバのメトリクス/ログの自動取得はできないため、ユーザ側でストレージまで送信する環境の構築/実装が必要です。
モニタリングスイートへのメトリクス/ログ送信の対応プロトコルについて
モニタリングスイートは以下表のプロトコルに対応しています。
| 項目 | メトリクスストレージ | ログ・トレースストレージ |
|---|---|---|
| 送信プロトコル | Prometheus Remote Write 1.0 | OpenTelemetry Protocol (OTLP/HTTP) |
リソースを作成すると発行されるエンドポイント (例: "https://**********.metrics.monitoring.global.api.sacloud.jp/prometheus/api/v1/write" )に対して対応プロトコルでデータを送信していく事になります。
※詳しい仕様はマニュアルを参照してみてください。
モニタリングスイートへのメトリクス/ログ送信環境実装パターンの検討
モニタリングスイートでは、メトリクス/ログを送信するためのエージェント(CloudwatchでいうCloudwatch Logsエージェント)は提供していないため、各プロトコルに対応したOSSツール等を選定して実装する必要があります。
大きく分けて、監視対象のサーバから直接メトリクス/ログを送信する か、 Prometheusサーバ等の収集サーバで集約後に送信する の2パターンが考えられます。
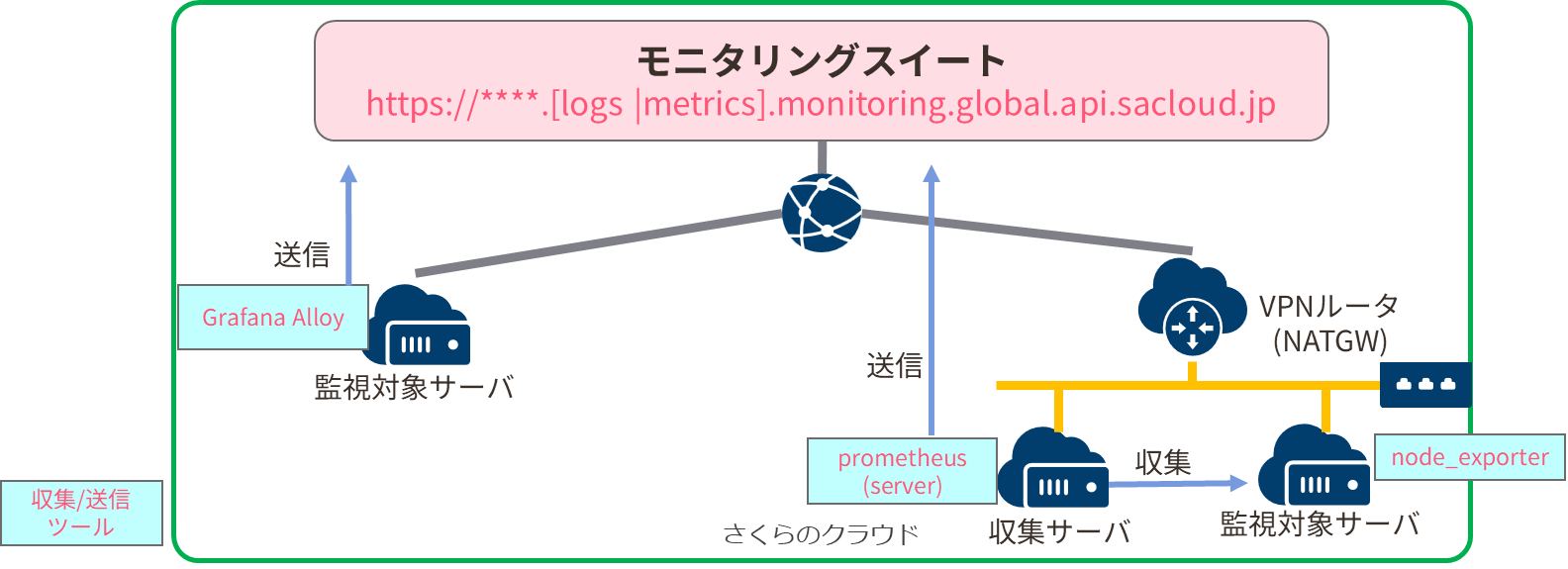
監視対象サーバが数台の場合は、わざわざ収集サーバを立てるのも手間なのでnode_exporter/otel_collectorといったメトリクス/ログ収集ツールを入れつつ、送信プロトコルに対応可能なツール(ミドルウェア)を使って送信する構成がシンプルです。
この後紹介する Grafana Alloy だと、Prometheus/OTLPどちらでのデータ収集/送信に対応できるのでオススメです。
真面目にnode_exporterだけを使ってもremote_writeでの送信ができず、prometheus本体を入れると重いため悩んでいたら"proetheus互換ツールならAlloyが良い"と見かけたので試したらめっちゃ楽でした。 ※パッケージマネージャでインストールできるのが特に助かる
一方、監視対象が数十台など大規模な場合や既にPrometheusサーバのある環境については、収集サーバで一旦集約後にまとめて送信する方が効率的です。
なお、↑の画像ではインターネット側のエンドポイントに向けて送信しているイメージになっていますが、最近リリースされたスイッチの機能拡張であるサービスエンドポイントゲートウェイ(SEG)を利用するとプライベートNW内からインターネット側を経由せず、直接モニタリングスイートへデータ送信できます。 ※AWSでいうVPCエンドポイント的なやつです。
サービスエンドポイントゲートウェイにおけるモニタリングスイート対応のお知らせ
LinuxサーバからGrafana Alloyを使ってメトリクス取得/モニタリングスイートへ送信してみる
それではクラウド上のLinuxサーバ(今回はAlmaLinux 9.5)から、取得したメトリクスをモニタリングスイートへ送信する構成を実践してみます。
モニタリングスートのストレージ作成/アクセスキー取得
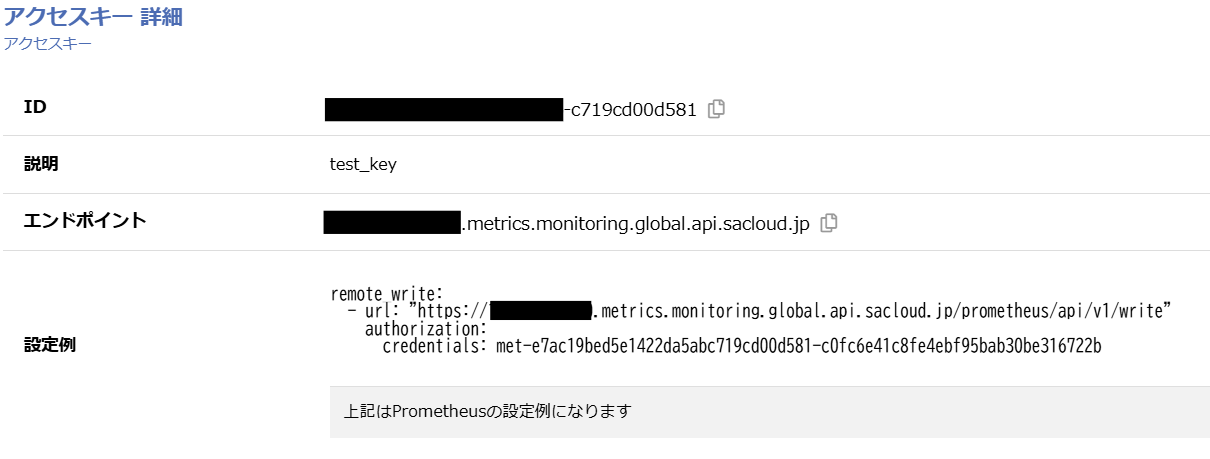
事前にモニタリングスイートのメトリクスストレージを作成してアクセスキーを取得しておきましょう。
ストレージの作成
アクセスキーを取得すると、Prometheus remotewrite形式で以下のような設定用文字列を取得できます。
Grafana Alloyのインストール
Grafana Alloyのインストール/設定はこちらを参照します。
必要パッケージのインストール/update
# dnf install gpg wget -y
# echo -e '[grafana]\nname=grafana\nbaseurl=https://rpm.grafana.com\nrepo_gpgcheck=1\nenabled=1\ngpgcheck=1\ngpgkey=https://rpm.grafana.com/gpg.key\nsslverify=1\nsslcacert=/etc/pki/tls/certs/ca-bundle.crt' | sudo tee /etc/yum.repos.d/grafana.repo
[grafana]
name=grafana
baseurl=https://rpm.grafana.com
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://rpm.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
# dnf update ★真面目にupdateすると結構時間かかります
Alloy のインストール
# dnf install alloy -y
Last metadata expiration check: 0:03:02 ago on Thu 11 Dec 2025 04:42:51 PM UTC.
Dependencies resolved.
=======================================================================================================
Package Architecture Version Repository Size
=======================================================================================================
Installing:
alloy x86_64 1.12.0-1 grafana 112 M
Transaction Summary
=======================================================================================================
Install 1 Package
(中略)
Installed:
alloy-1.12.0-1.x86_64
Complete!
Alloyのサービス起動/有効化/自動起動
# systemctl start alloy
# systemctl status alloy
● alloy.service - Vendor-agnostic OpenTelemetry Collector distribution with programmable pipelines
Loaded: loaded (/usr/lib/systemd/system/alloy.service; disabled; preset: disabled)
Active: active (running) since Thu 2025-12-11 16:47:41 UTC; 21s ago
Docs: https://grafana.com/docs/alloy
Main PID: 55847 (alloy)
Tasks: 7 (limit: 24602)
Memory: 31.8M (peak: 32.2M)
CPU: 156ms
CGroup: /system.slice/alloy.service
└─55847 /usr/bin/alloy run --storage.path=/var/lib/alloy/data /etc/alloy/config.alloy
# systemctl enable alloy.service
Created symlink /etc/systemd/system/multi-user.target.wants/alloy.service → /usr/lib/systemd/system/alloy.service.
Alloyのconfigファイル編集
/etc/alloy/config.alloy に、デフォルトのコンフィグファイルが生成されているので眺めてみます。
既にnode_exporter互換のprometheus.exporter.unix の設定が入っています。
forward_toの所に、よしなにprometheus.remote_write的な設定を追加して参照せよ、と書いてあります。
// Sample config for Alloy.
//
// For a full configuration reference, see https://grafana.com/docs/alloy
logging {
level = "warn"
}
prometheus.exporter.unix "default" {
include_exporter_metrics = true
disable_collectors = ["mdadm"]
}
prometheus.scrape "default" {
targets = array.concat(
prometheus.exporter.unix.default.targets,
[{
// Self-collect metrics
job = "alloy",
__address__ = "127.0.0.1:12345",
}],
)
forward_to = [
// TODO: components to forward metrics to (like prometheus.remote_write or
// prometheus.relabel).
]
}
ファイルを編集していきます。
- prometheus.remote_write "sakura_ms" ブロックを末尾に追加
- remote_writeの設定はモニタリングスイート/メトリクスストレージで作成したアクセスキーで生成されたurl,認証キー(credentials)を設定する
- credentialsはBearer Token型(Bearer)を指定して記述する
- prometheus.scrape "default" ブロックのforward_toで、prometheus.remote_write "sakura_ms" ブロックを参照する
- 行末に ","が必要なので忘れないよう注意
# vi /etc/alloy/config.alloy
// Sample config for Alloy.
//
// For a full configuration reference, see https://grafana.com/docs/alloy
logging {
level = "warn"
}
prometheus.exporter.unix "default" {
include_exporter_metrics = true
disable_collectors = ["mdadm"]
}
prometheus.scrape "default" {
targets = array.concat(
prometheus.exporter.unix.default.targets,
[{
// Self-collect metrics
job = "alloy",
__address__ = "127.0.0.1:12345",
}],
)
forward_to = [
prometheus.remote_write.sakura_ms.receiver, ★←行末のカンマ(,)を忘れずに,,
]
}
prometheus.remote_write "sakura_ms" {
endpoint {
url = "https://xxxxxxxx.metrics.monitoring.global.api.sacloud.jp/prometheus/api/v1/write"
authorization {
type = "Bearer"
credentials = "met-e7ac19bed5e1422da5abc719cd00d581-c0fc6e41c8fe4ebf95bab30be316722b"
}
}
}
設定できたら、Alloyをリロードします。
statusを確認してエラーが起きてない事を確認します。
# systemctl reload alloy
# sudo systemctl status alloy
● alloy.service - Vendor-agnostic OpenTelemetry Collector distribution with programmable pipelines
Loaded: loaded (/usr/lib/systemd/system/alloy.service; enabled; preset: disabled)
Active: active (running) since Thu 2025-12-11 16:47:41 UTC; 37min ago
Docs: https://grafana.com/docs/alloy
Process: 56094 ExecReload=/usr/bin/env kill -HUP $MAINPID (code=exited, status=0/SUCCESS)
Main PID: 55847 (alloy)
Tasks: 8 (limit: 24602)
Memory: 44.7M (peak: 45.2M)
CPU: 3.293s
CGroup: /system.slice/alloy.service
└─55847 /usr/bin/alloy run --storage.path=/var/lib/alloy/data /etc/alloy/config.alloy
## エラーが表示される例 ※行末にカンマを記載する必要があった
\"/etc/alloy/config.alloy\": /etc/alloy/config.alloy:24:47: missing ',' in expression list"
モニタリングスイート側でメトリクスを確認する
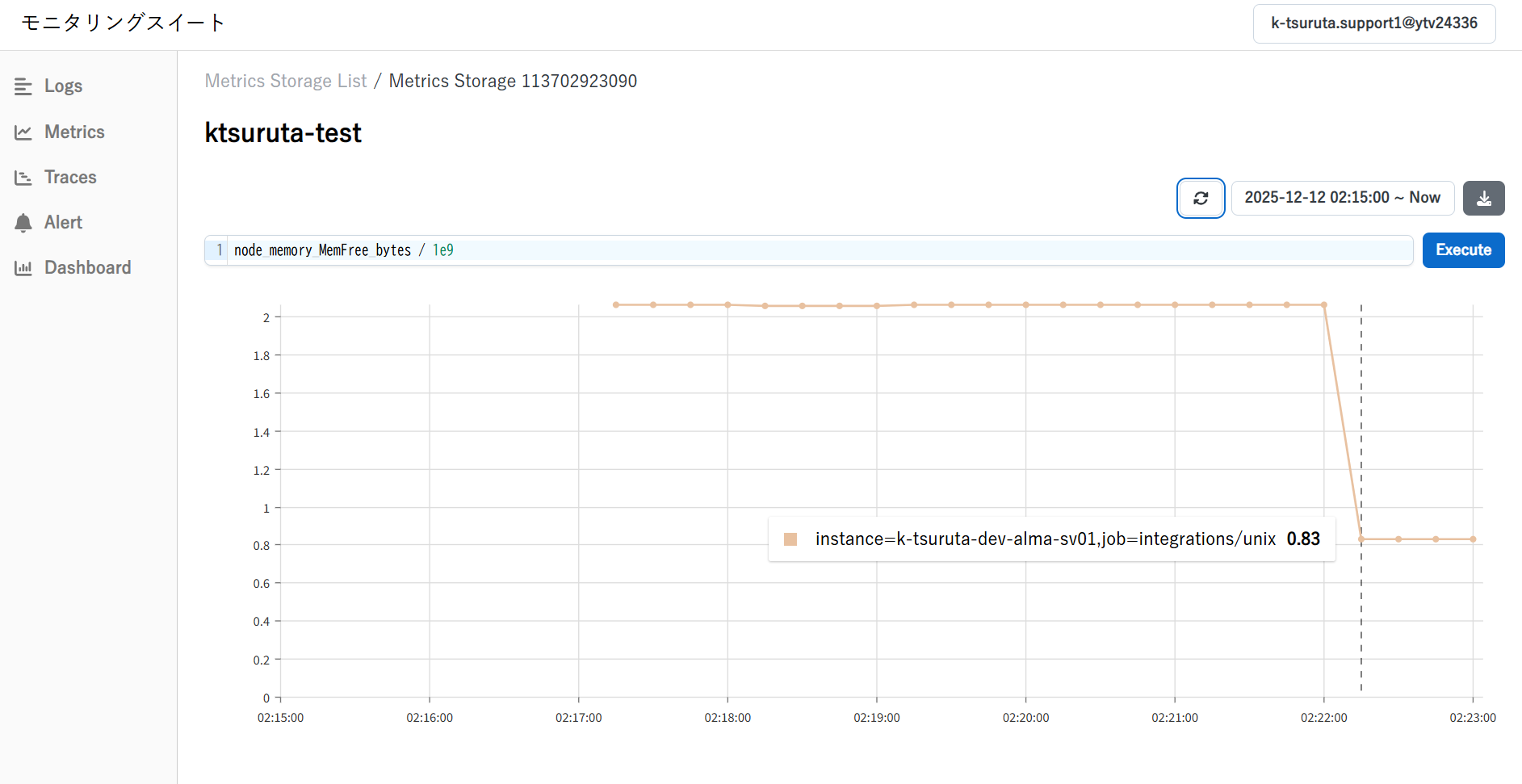
さくらのクラウドコントロールパネルから、メトリクスストレージを閲覧してみます。
通常のコンパネとは別に、モニタリングスイートの独自コンパネに遷移します。
試しにPromQL形式で空きメモリ容量をクエリしてみると、サーバから取得したメトリクスからデータを表示できました。
node_memory_MemFree_bytes / 1e9 # GB単位で空きメモリを表示させる
後は監視閾値を検討したうえでアラート作成、シンプル通知へ連携してメール通知を組んだり、Eventbus連携でオートスケールを実行させる等、モニタリングスイートの監視データを起点に運用自動化が実現できそうですね!
最後に
今回はモニタリングスイートへのメトリクス/ログ送信環境の実装パターン検討と、シンプルなメトリクス送信環境の構築例を実践してみました。
Prometheus/OTLPで既に監視環境を構築している方は、さくらのクラウドに限らず活用できるため是非お試しください!