あまり有名ではありませんが変わった性質のニューラルネットワークとして Reservoir Computing があります。
Recurrent Neural Network のひとつですが、中間層の重みを固定してしまって、出力層の部分だけ学習するというアルゴリズムです。
Recurrent Neural Network とは
まずは Recurrent Neural Network (RNN) について簡単に触れておきましょう。
時系列学習
時系列データを扱う方法は多種多様ですが、ニューラルネットワークにおいてはRNNを使います。
時系列情報をネットワーク内で表現するために途中にループがある構造のネットワークを指し、少し前だと Elaman Network とか Jordan Network とかが有名でした。
最近はディープラーニングの文脈で度々登場する Long-Short Term Memory (LSTM) や、その改良版であるGRUが有名ですね!
LSTMでは忘却ゲートやその他多数の度重なる工夫によって素晴らしい性能を発揮していますが、RNNは基本的に学習が難しいネットワークです。
RNN の面倒くささ
RNNの最適化が困難な理由は多数ありますが (たとえばこれとか)、ひとつには「そもそもBackpropagationするのが面倒くさい」という部分が大きいのです。
通常RNNの学習をする場合、BPTT(Backpropagation through time)を使いますが、過去に遡る形で多層のネットワークでの誤差伝播をしなければなりません(他にも Real Time Recurrent Learning とかがあります)。
その他のイケてないところ
通常の利用範囲ではなんの問題もないのですが、BPTTは時系列を展開して過去に遡りながら重みを更新していくという方法をとります。普段は「ニューラルネットワークは人間の脳を模したアルゴリズムで…」とか言ってるくせに、タイムマシンみたいなことしてるんですよこいつは。許せませんね。
「脳っぽさ」を考えたときに限って言えば、重みの伝播をネットワークを時間方向に展開して更新したり、厳密な微分の計算が必要だったりするのはあまりうれしくありません。
このあたり、もうちょっとなんとかならないでしょうか?
Reservoir Computing (RC) はそのようなときに便利です。
いや便利ではないかもしれませんが、考え方が面白いので紹介します。
先に断っておくと、あとで紹介するRC系アルゴリズムが「生理学的に妥当性がある!」と言うわけではありません…。
Reservoir Computing
RC は単一のアルゴリズムを指す用語ではありません。 Deep Learning と同じで、ある種のアルゴリズム全般を指す言葉です。まずはRCの概観をつかみましょう。
通常のRNNのよくないところを一言で言えば、すべての重みを(BPTTなどで)最適化しないといけないことです。
RCではこの点を諦めて、重みの大部分を乱数で初期化したあとは固定してしまいます。つまり学習データが入ってきても重みを変更しません。
RC系のアルゴリズムは、入力層、Reservoir(隠れ層)、出力層の3層構造を持ちます。
3層とはいっても、Reservoirは下図のとおりランダムに結線されているのが特徴です1。
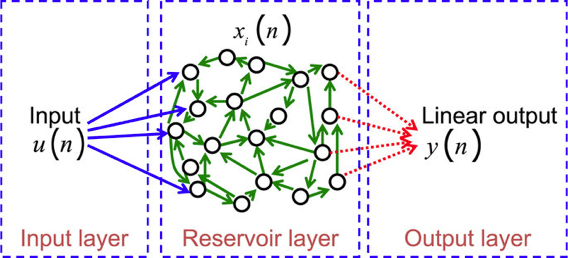
入力層とReservoir間、Reservoir内の結合重みは乱数で初期化したあとは変更せず、Reservoirと出力層の間の重みだけを学習します(ここはなんでもいいのですが、 オンライン線形分類器とかを使うのが良いでしょう)。
考え方としては、入ってきた信号は Reservoir 内をぐるぐると駆け巡っていくので、それによって時系列情報を記録できている…という感じです。
こんなもんでうまく学習できるのか?と思うかもしれませんが、一応は Universal function approximation です。
RC系のアルゴリズム
結局はほぼおなじアルゴリズムなのですが、有名所を紹介します。
Liquid State Machine
LSM2 は、脳の機能解明が出発点で、他のニューラルネットワークとはちょっと毛色が違います。
一応著者曰く「脳は事前に決められた回路ではなく生まれたときはランダムだが、それでもちゃんとうまく学習できるし、本質的に連続した時系列データを自然な形で扱えているので、LSMもその点優れている」みたいな感じだそうです。
動機としては「脳っぽいもの」を念頭に置いているらしく、連続時間かつニューロンはスパイクを出すというモデルになっています。
Echo State Network
ESN3 のほうは特に脳がどうとかは触れておらず、いわゆる普通のニューラルネットワークに結構近いモデルです。
時間も離散的ですし、出力も実数で出てきます(活性化関数として tanh を使っています)。
こちらのほうがわかりやすいかと思います。
まあ先程も書きましたが LSM と ESN はほぼ同じアルゴリズム4で、大きな違いといえばLSMはスパイクを扱い、ESNは普通に実数を出力するニューロンを扱う点くらいでしょうか。
ESNは私も利用したことがありますが、パラメータにもそんなに敏感ではなく適当にやってもまあまあそれなりの結果が得られるという点では便利でした。
FORCE
FORCE(First Order Reduced and Controlled Error) Learning は、ESNを拡張したアルゴリズムです(FORCEの特別な場合がESN)。
こちらは運動生成を再現しようといったところが出発点のようです。そういう意味ではLSMに近いかもしれません。
たとえば運動パターンを覚えさせておいて、あとできっかけだけを与えたらそのパターンが再生されたり、あるパターンから自然に別のパターンに変化させる(たとえば歩行から走行に移行するとき、動物はいったん立ち止まらなくても自然に移行できる)といったことを狙っているようです。
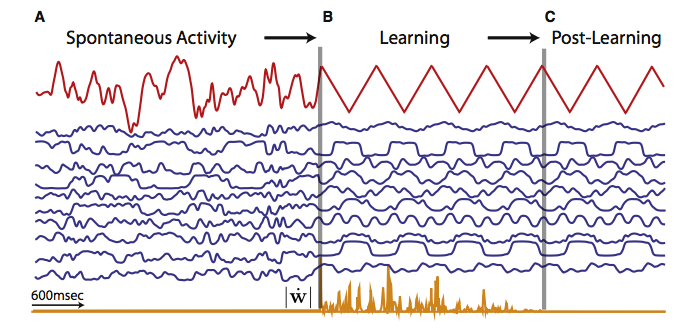
上記の画像は Sussillo らの資料5を引用したものですが、一番上の赤い線に注目してください。最初は乱雑な動きをしています(図中A)が、望ましい出力を覚えさせると(図中B)、教師信号をなくしても自発的に同じ出力を繰り返すようにしたりできます(図中C)。
SussilloによるとESNより性能が良いそうなので、今後はFORCEのほうが有名になるかもしれません。
おわりに
RC がうまくいく理由としては、高次元空間へのランダム射影がうまくいっていることや、カーネル法との関係がありますが、ネットワークの大部分がランダムでも時系列データを扱うことができるという点はいくつかのメリットがあります。
たとえば、不安定な素子を使ってもある種の学習ができるのであれば、システムのハードウェア実装が容易になるかもしれませんし、省電力化も狙えるでしょう(実際に、特に LSM においてはハードウェア実装がよく語られます)。
また、Reservoirは固定でもかまわないので、Readout部分だけ別で用意すればネットワークの大部分は別のタスクと使いまわせることも意味します。このような点は通常重視されませんが、ハードウェアリソースが制限されている場合などには有効です。
RNNで良い性能を出したい場合、やはり最近であればLSTMベースの手法をとるのが良い選択ですが、これらは非常に高コストです。RCのような「ゆるい」感じのアルゴリズムもたまに役に立ちますので、ご参考になれば幸いです。
-
François Duport, Anteo Smerieri, Akram Akrout, Marc Haelterman and Serge Massar (2016). Fully analogue photonic reservoir computer. Scientific Reports 6, Article number: 22381. ↩
-
Maass, Wolfgang, Natschläger, Thomas. Markram and Henry. Real-time computing without stable states: a new framework for neural computation based on perturbations, Neural Comput, 14 (11): 2531–60 ↩
-
Herbert Jaeger and Harald Haas. Harnessing Nonlinearity: Predicting Chaotic Systems and Saving Energy in Wireless Communication. Science 2 April 2004: Vol. 304. no. 5667, pp. 78 – 80. ↩
-
Jaeger H, Maass W, and Principe J (Eds.) (2007). Echo State Networks and Liquid State Machines, Volume 20 of Neural Netw. ↩
-
Sussillo, D., Abbott, L.F. (2009): Generating Coherent Patterns of Activity from Chaotic Neural Networks. Neuron 63(4), 544-557. ↩