こんにちは。こちらはAWS for Games Advent Calendar 2022 21日目の記事です。
はじめに
クライアントで開発中に出力されるログや様々な情報は一時的には使われますが、調査や分析などされる目的で出力されていないのでゲームサーバーなどで出力されるログに比べて活用されている機会はまだ少ないと思います。そのため、ログを出力していてもフォーマットが定まっていなことが多いと思います。もし活用するとなっても元のログを整形や加工を行なってデータベースに投入する必要があります。また、これらのログの管理はクライアントエンジニアが行なっていることが多く、分析や可視化をするまでのデータパイプラインなどの作成に慣れていない方が多いと思います。そこで今回は 開発中にクライアントなどで出力される整形されていないログを検索できるようにしたいと思います。
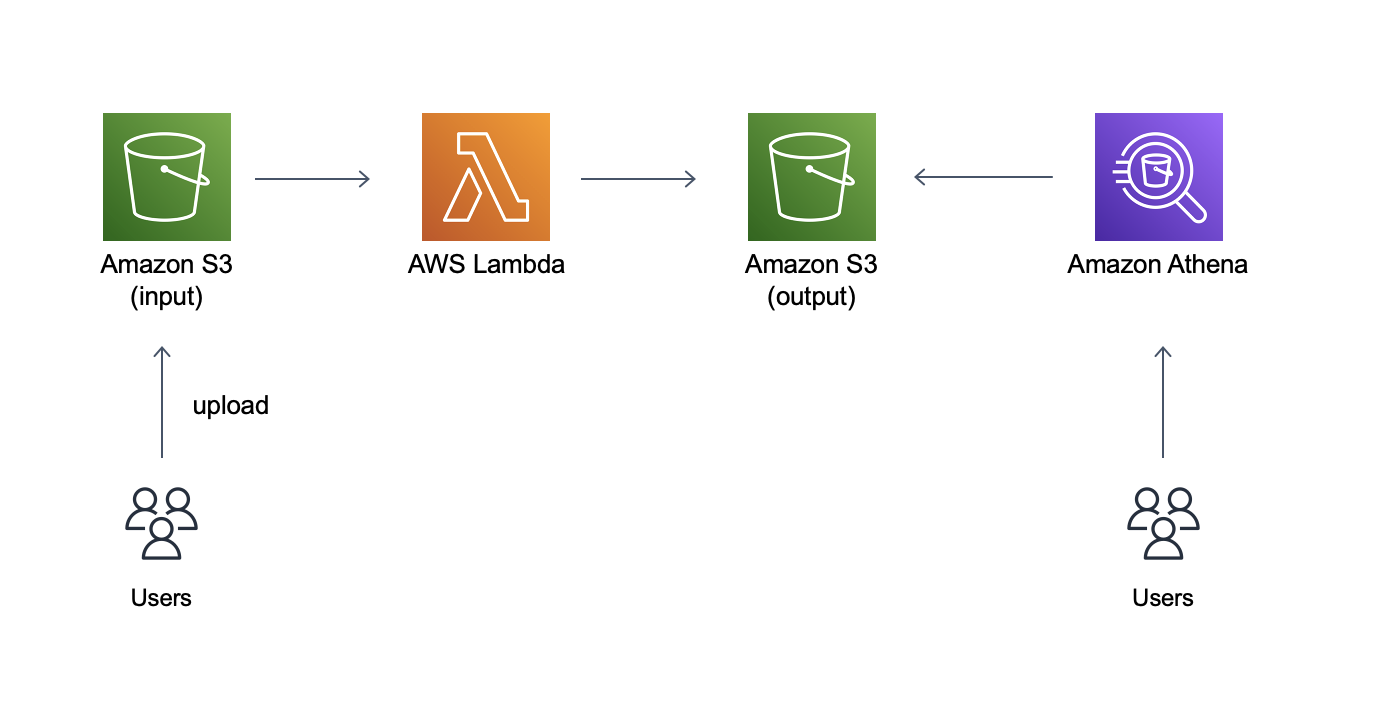
今回作るもの
入力用S3に投入されたデータをLambdaで加工、整形し、出力用S3に出力し、最終的にAthenaで検索できるところまでをやります。
各サービスの説明はこちら
https://aws.amazon.com/jp/s3/
https://aws.amazon.com/jp/lambda/
https://aws.amazon.com/jp/athena/
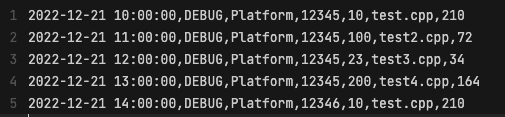
(サンプルログ)
[2022-12-21 10:00:00][DEBUG][Platform][12345]‘Error10:予期せぬエラーが起きました#test.cpp(210)
上記のようなフォーマットのログを使えるようにします。(このフォーマットは私が適当に作ったものです)
開発中にテストプレイをしていて出力されたログという想定です。ゲーム側の出力としてログの出力時間、ビルド環境、プラットフォーム、ビルドのバージョンが出力され、その後実際のエラー内容が出力されている、というものです。
上記のようなログの場合、いつ、どのバージョンでどのようなエラーが多いのか、等がわかることでエラー対応の優先順位やコード担当者がいる場合はその方の負荷であったりなど、様々な情報を取得することができます。
今回このログで必要なものは 「日付」「環境」「プラットフォーム」「バージョン」「エラー番号」「コード名」「起きた行数」 とします。
エラー詳細文言は基本的にエラー番号の説明として使われていることが多いのでerror10が予期せぬエラーが起きたという紐付けさえできればわざわざ文字列として情報を持つ必要はありません。
この前提条件をもとに今回加工した後の内容は
2022-12-21 10:00:00,DEBUG,Platform,12345,10,test.cpp,210
というcsvに変換し、検索できるものを作ります。
構築する
※既にAWSアカウントはあるものとしてここから作業を始めます。
S3
入力用のS3と出力用のS3を作成します。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/create-bucket-overview.html
上記リンクに方法が記載されているので任意の名前でS3を2つ作りましょう。
入力側にはinput、出力側にはoutputと付けるとわかりやすいと思います。
(Athenaを使用する際にAthenaのログを格納するようのS3も必要になります。ここでもう一つAthenaログ用のS3も作っていておいた方が良いかと思います。)
Lambda
次にデータを変換するLambdaを作成します。AWSコンソールから 「Lambda」 と検索してLambdaサービスを表示します。
(画像の黒塗りが気になるかもしれませんがご容赦ください…)
「関数の作成」のボタンを押すと関数の作成ページに移動します。
関数名はわかりやすい名前を自由につけてください。 ランタイムに関しては自分の扱いやすい言語を選択してください。今回は Python3.9 を選択しております。また、今回は 「一から作成」 を選択します。
すると名前をつけた関数の作成のページに移動します。
ここで「関数の概要」内にある 「トリガーを追加」 ボタンを押します。このトリガーというものがLambdaを起動させるための条件となります。今回は入力用S3内にファイルが置かれたらこのLambdaが起動するようにします。
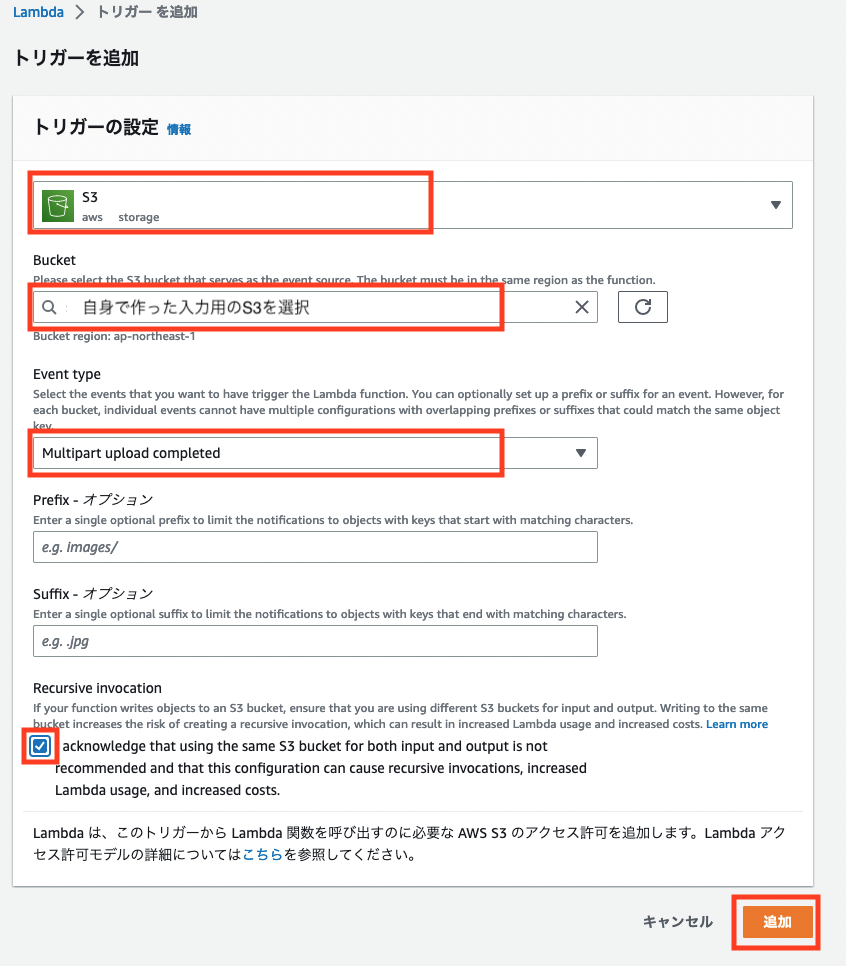
トリガーの設定で 「S3」 を選択します。Bucketに入力用のS3を指定してください。Event typeには新規ファイルが作成された時のみ起動してほしいので 「PUT」 と 「Multipart upload completed」 を設定します。ここでPUTだけにしてしまうと容量の大きなファイルがS3に置かれた際にMultipart uploadが動作し、Lambdaが起動しなくなってしまいます。Multipart uploadの説明はこちら
一度に一つのトリガーしか設定ができないのでどちらかを設定した後にもう一つのトリガーを追加してください。私はこれを設定していなかったので実際にこのパイプラインを作った時にLambdaが起動する時と起動しない時があって調査するのに苦労しました。
あとはオプションなので基本何もなしで最後に「入力のS3と出力のS3を一緒にすると危険ですよ(要約)」という注意書きのチェック欄にチェックを入れるとトリガーの設定は完了です。(今回はS3を分けているので問題ないです)
しかし、今のままだとLambda側からS3へのアクセス権がないのでファイルが置かれても検知できないのでLambdaに割り当てられているロールにS3のアクセス権を追加します。
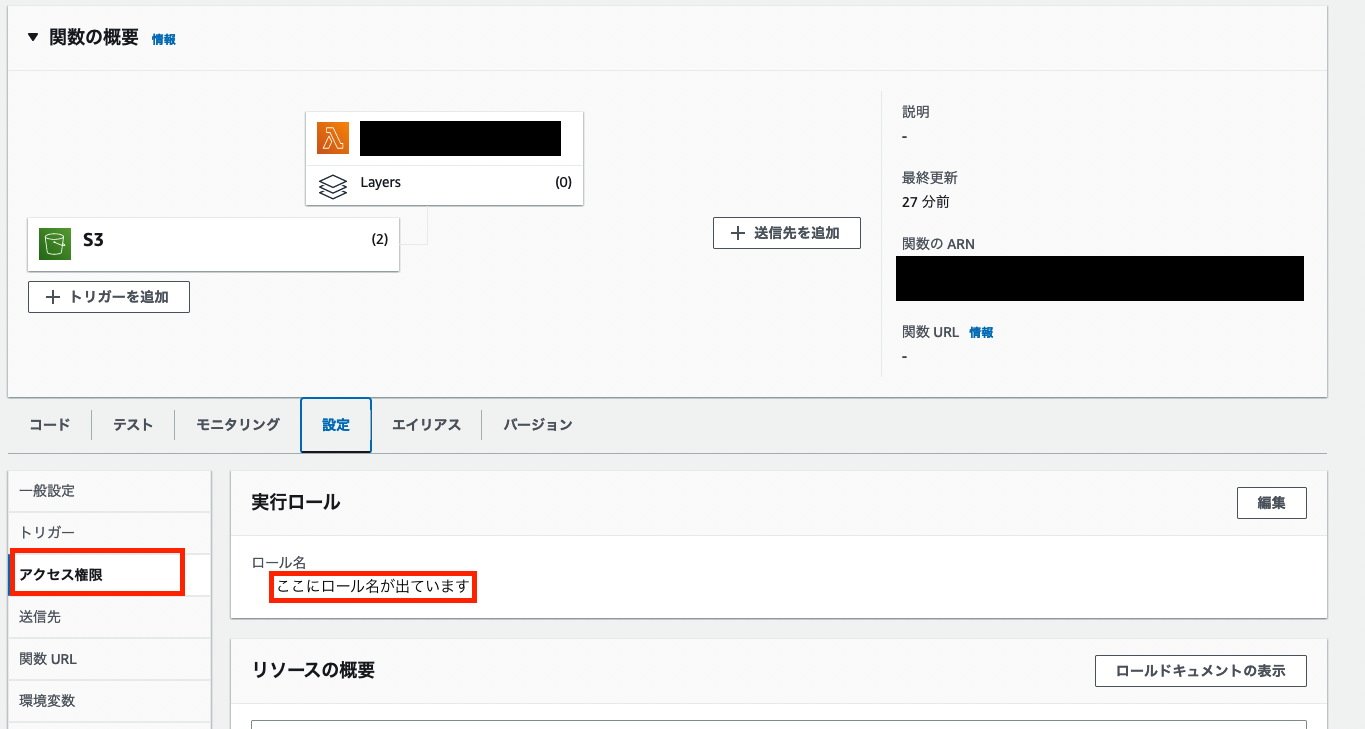
設定の中の 「アクセス権限」 をクリックすると実行ロールが出てくるのでその中に表示されている 「ロール名」 をクリックし、Lambdaに設定されているロールにS3の権限を追加します。
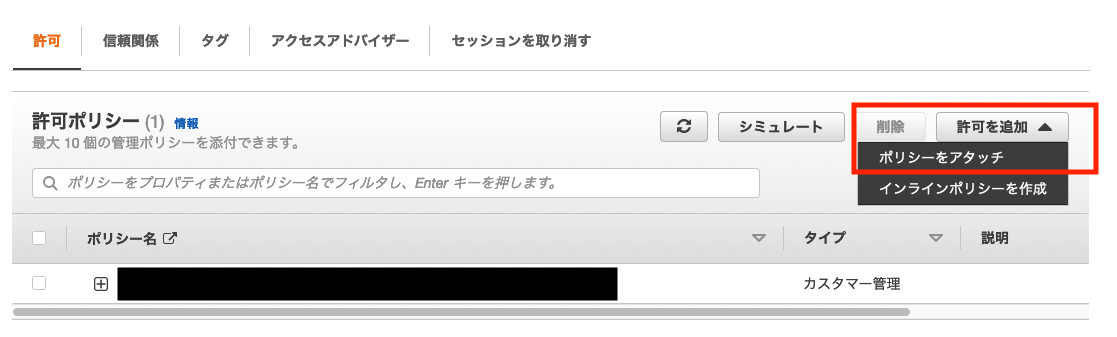
許可ポリシー内の 「許可を追加」 ボタンをクリックし、 「ポリシーをアタッチ」 をクリックします。検索窓でS3と入力し検索するといくつかS3のポリシーが出てきます。
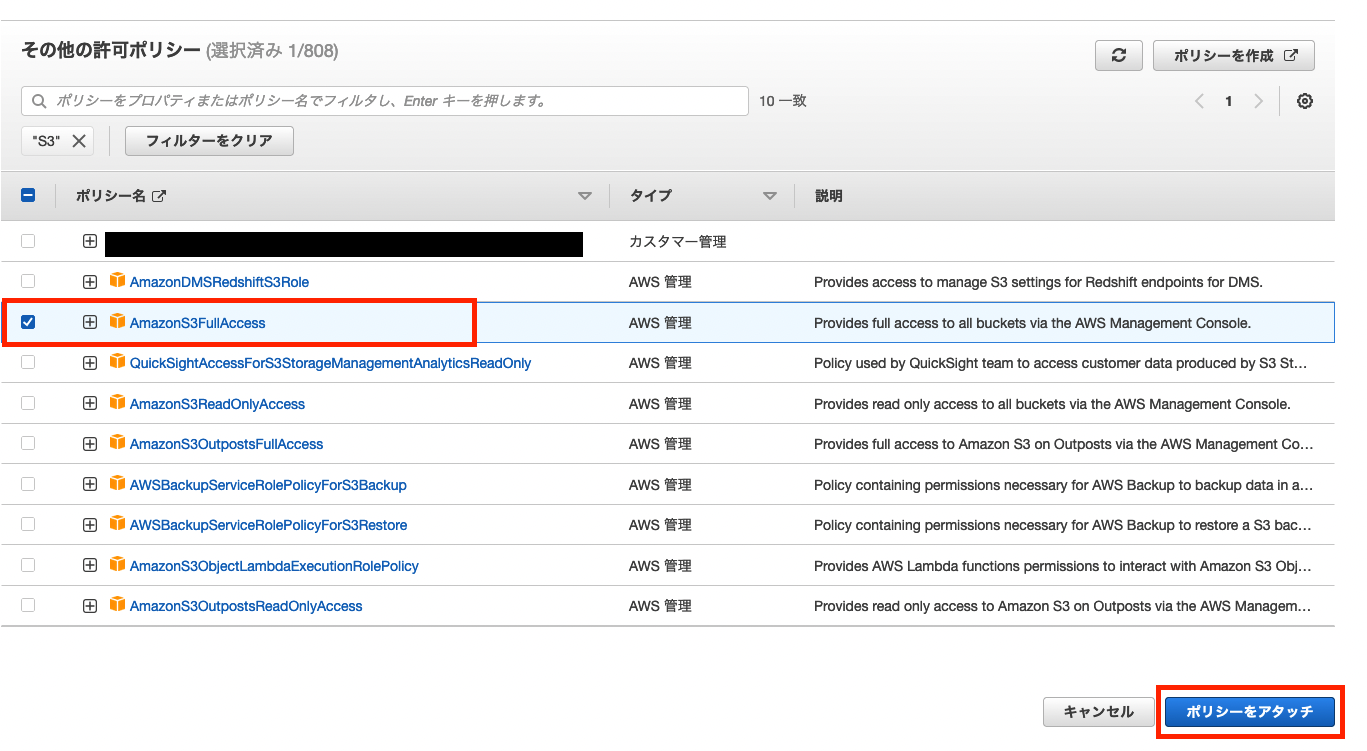
今回は読み込み、と書き込みなどのS3に関する権限が必要なので 「AmazonS3FullAccess」 のチェックボックスにチェックをつけ 「ポリシーにアタッチ」 をクリックしポリシーの追加を行います。
これで設定は完了です。
次にlambdaのコードを書きましょう。Lambdaページに戻り「コード」の中の「lambda_function.py」のコード内に以下のコードをコピペしてOUTPUT_BUCKETを自身で作成した出力用S3の名前に変更してください。
import json
import urllib.parse
import boto3
import re
OUTPUT_BUCKET = 'output_s3_bucket_name'
s3 = boto3.resource('s3')
# 加工プログラム
def convert_data(input):
output_list = []
for line in input.splitlines():
error_text = re.search(r'\'.*\'', line).group()
error_no = re.search(r'\d+:', error_text).group()
error_no = re.sub(r':','',error_no)
error_src = re.search(r'#.*\(', error_text).group()
error_src = re.sub(r'#','',error_src)
error_src = re.sub(r'\(','',error_src)
error_line = re.search(r'\(\d+\)', error_text).group()
error_line = re.sub(r'\(','',error_line)
error_line = re.sub(r'\)','',error_line)
line_buf = line.replace(error_text, '')
line_buf = re.sub('\[','',line_buf)
line_buf = re.sub('\]',',',line_buf)
output_buf = line_buf + error_no + ',' + error_src + ',' + error_line + '\n'
output_list.append(output_buf)
output = ''.join(s for s in output_list)
return output
# ここから下がLambdaが動かす関数
def lambda_handler(event, context):
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
input_obj = s3.Object(input_bucket,input_key)
response = input_obj.get()
body = response['Body'].read().decode('utf-8')
output_body=convert_data(body)
output_obj = s3.Object(OUTPUT_BUCKET,input_key)
response = output_obj.put(
Body = output_body.encode('utf-8'),
ContentEncoding='utf-8',
ContentType='text/plane'
)
return
行っていることは入力用S3に置かれたファイルを読み込み、加工して出力用S3に送るという内容です。
簡単に「convert_data」の中身を説明します。ファイル内の文字列を1行づつ取り出し、正規表現で必要なものを取得し、文字列変換を行い最後に1行の文字列に変換し、配列に格納していきます。その配列を最後に一つの文字列にしています。どの文字列が不要なのか等わかりやすくするために取り出しては不要な文字列を消してという処理を一つづつ書いています。
違う加工がしたい、フォーマットを変更したい、といった時にはこの関数の中身を変えてください。
lambdaは起動すると lambda_handler の関数が呼び出されます。event内の情報からバケットネームやキーネームを取得して入力用S3に置かれたデータを取得してきます。そのデータをconvert_data関数を使用して加工し、output_body内にデータを入れます。その後putで出力側のS3に同じ名前のファイルを出力します。
これで加工準備は完了です。
実際動作を確認してみましょう。このようなフォーマットのデータを

このように変換するようにします。
入力用のS3にファイルを置くと
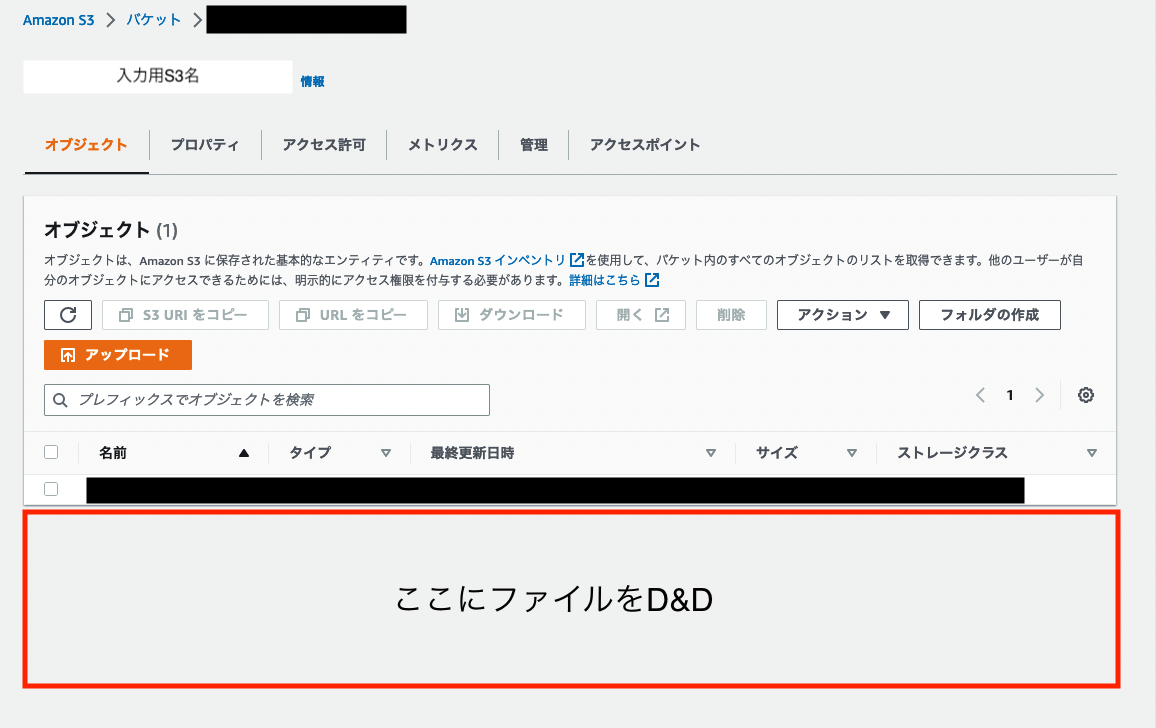
出力用のS3にファイルが出来上がっています。
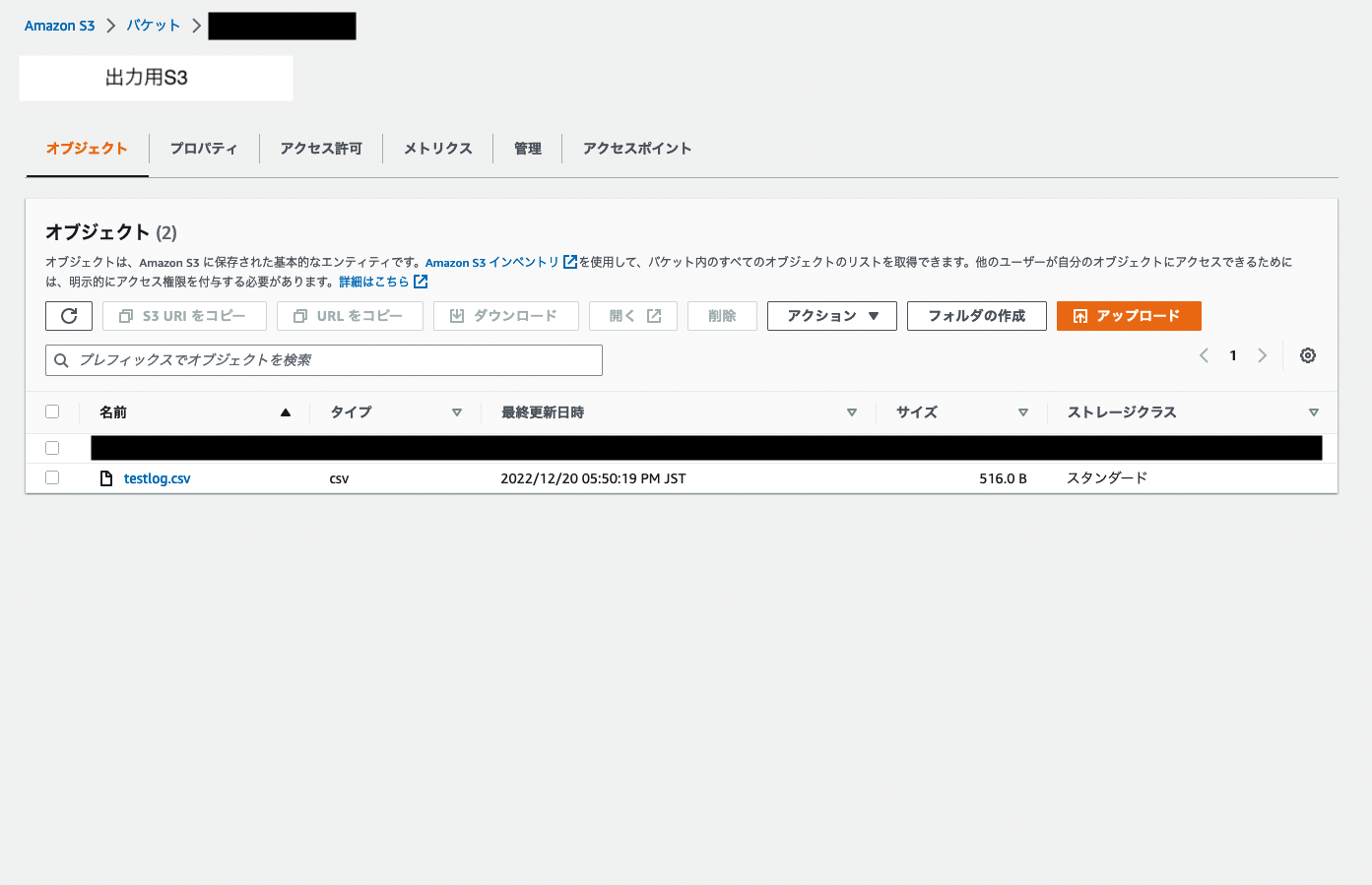
中身を確認してみると
想定通りの形になっています。(上と同じ画像ですが…)
これで完了です。
※Lambdaは多重起動する可能性があります。今回は同じ名前にすることで多重起動してもデータが増えないようにしています。各自多重起動などの対応が必要な場合は対応をお願いします。
Athena
最後にAtenaで検索できるようにします。AWSコンソールから 「Athena」 と検索してAthenaサービスを表示します。初めての方はAthenaのログが出力されるS3を設定しないといけないので設定からAthenaのログを入れるS3を選択してください。(まだ作成などしていない場合は別途作成して設定してください)
ログの出力S3が設定できたら次はAthenaでテーブルを作成します。
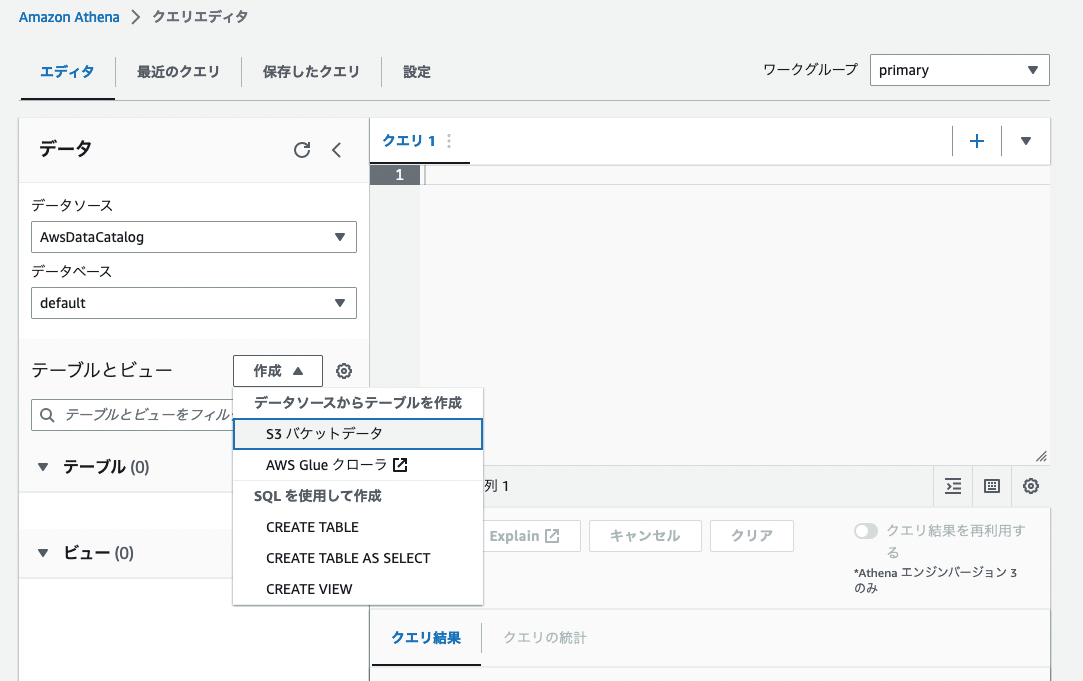
クエリエディタ内のテーブルとビューの隣にある 「作成」 ボタンを押し 「S3バケットデータ」 を選択します。
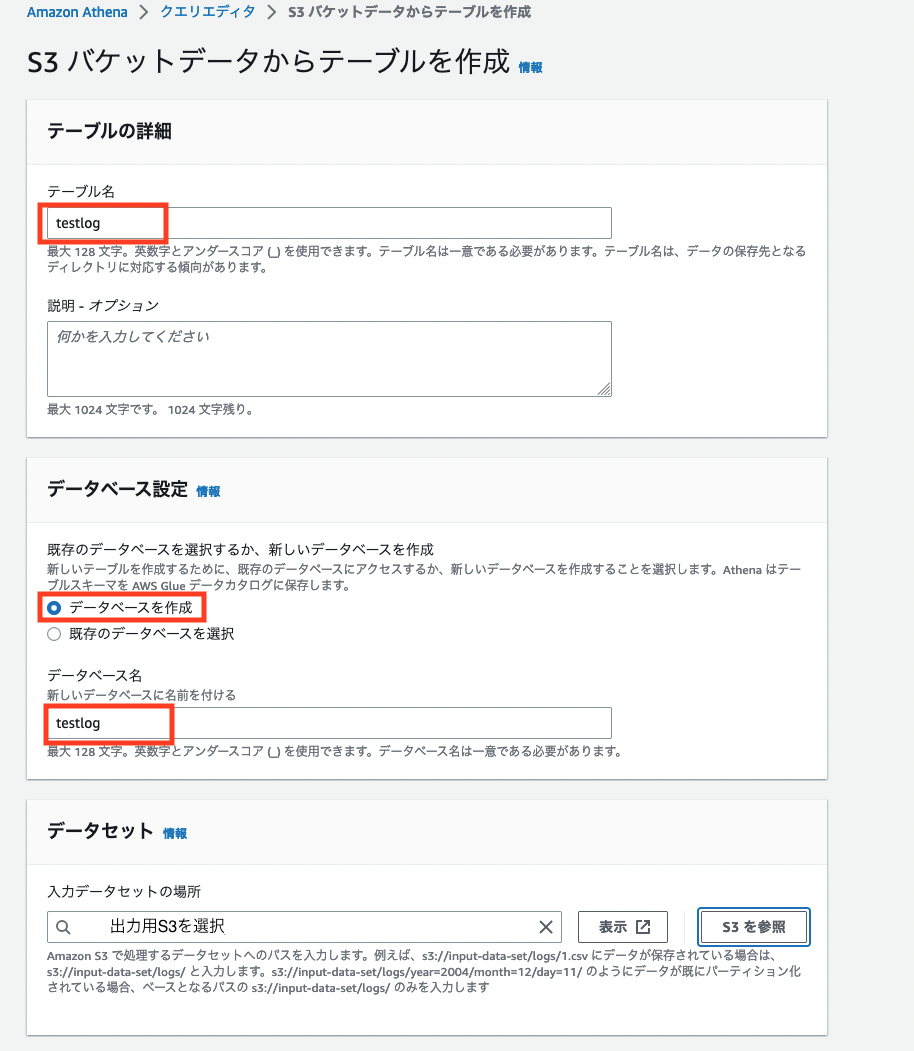
任意のテーブル名 を記載します。次にデータベース設定で 「データベースを作成する」 にチェックを入れて 任意のデータベース名 を記載します。データセットで 「S3を参照」 をクリックし 出力用のS3 を選択します。
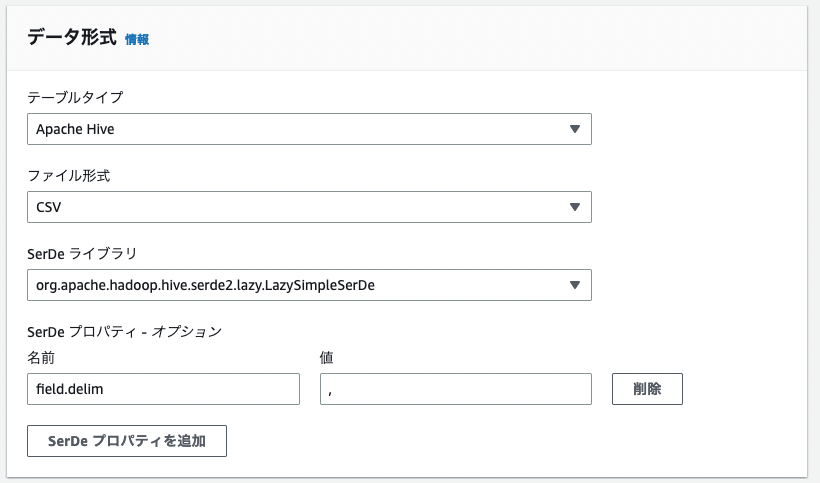
データ形式を 「CSV」 を選択します。その後、列の詳細で任意の列を追加していきます。
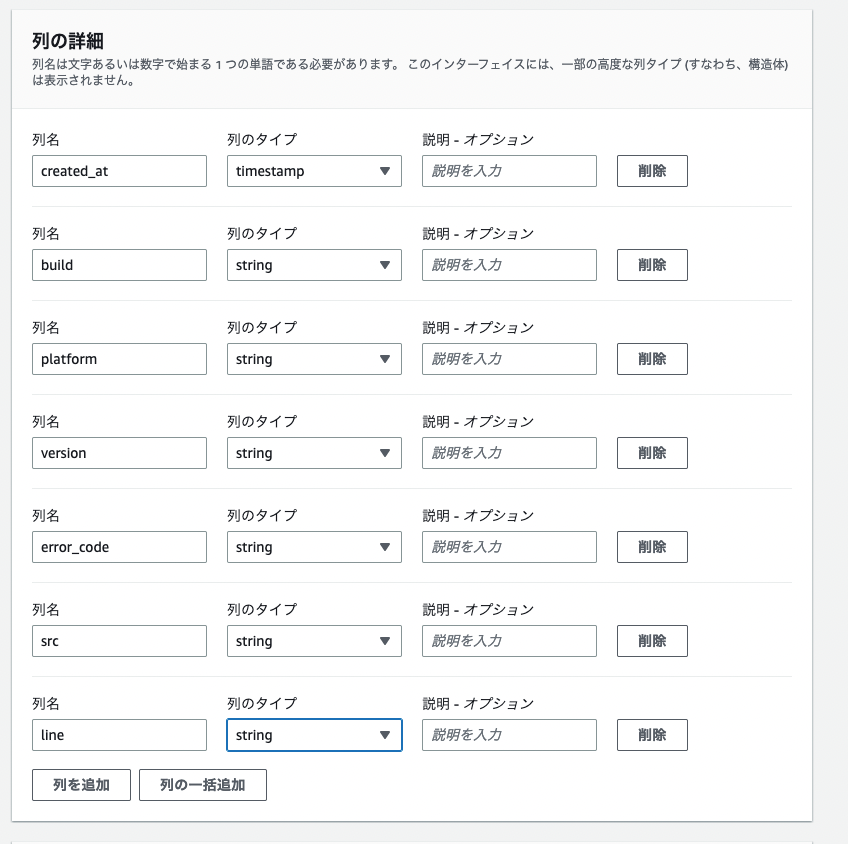
上記の画像のように設定します。
これで一番下にある 「テーブルを作成」 をクリックするとテーブルが出来上がります。
試しにクエリを実行してみましょう。エラー番号10番のエラーがどれくらい出ているかを確認するクエリです。
SELECT * FROM testlog WHERE error_code='10'
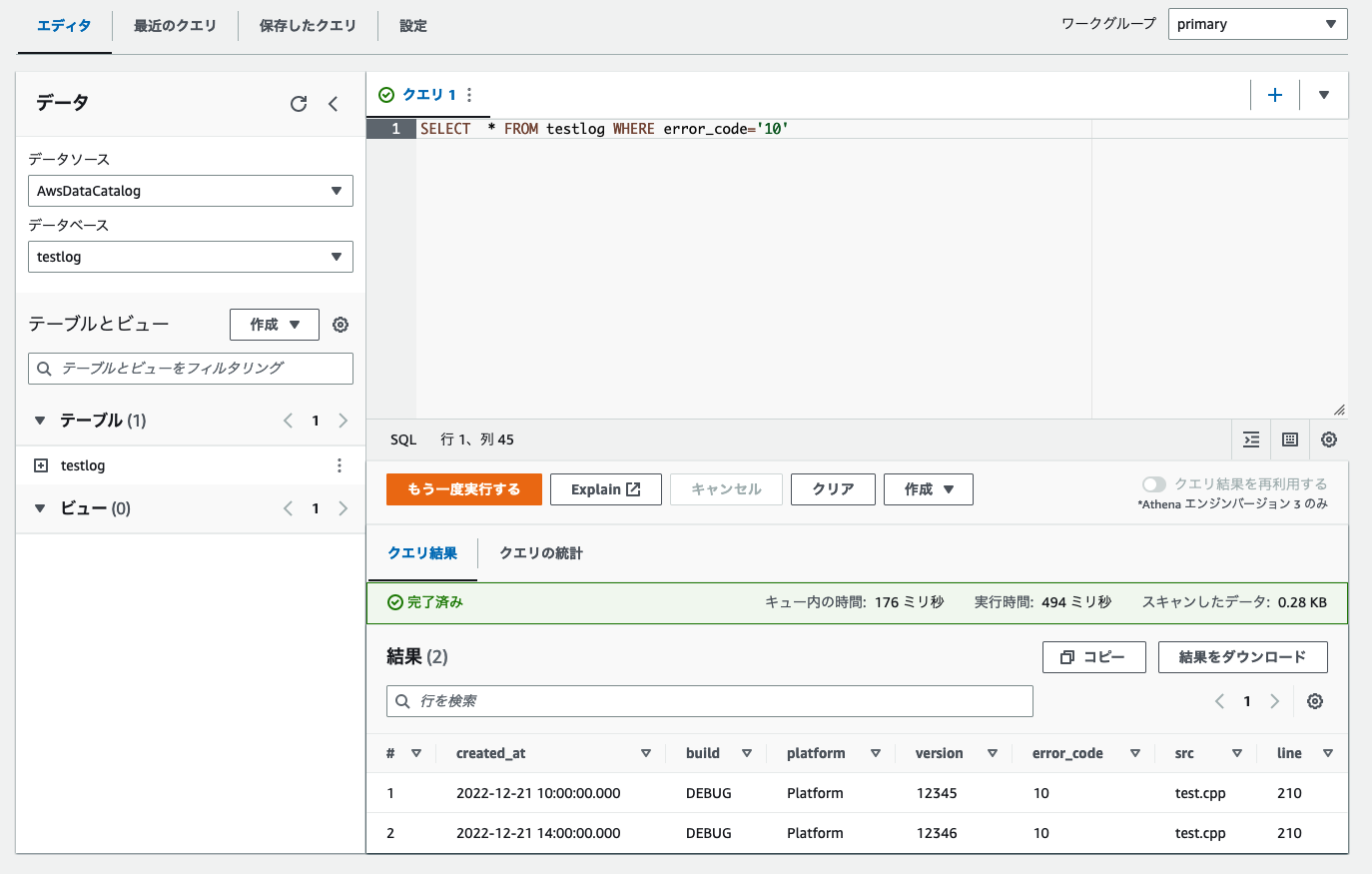
結果の部分に2件データが返ってきているのでうまく検索ができています。
これで入力用のS3にファイルが出力されたらAthenaで確認できるようになりました。
最後に
今回は簡単にデータを変換、検索できるところまでを作りました。このログデータが開発の役に立つかどうか、などを試す場合はこのような簡単な構成で十分だと思います。試してみて「このデータは使える。みんなに公開したい。」となった場合、データを自動的にS3にあげる仕組みや構成を見直す、DWHを使う、可視化するなど、どんどん拡張していっていただければと思います。
拡張していく際でも今回使用した入力用S3→Lambda→出力用S3の方法はシンプルで基本的な内容ですが、様々な場所で使うことができます。ちょっとした変換であればLambdaで十分行えますし、とても簡単でわかりやすいです。
ぜひ今まで使ってこなかったデータなどもどんどん活用していき開発効率を上げていきましょう。この記事が少しでもそのお手伝いになれば幸いです。
(免責) 本記事の内容はあくまでも個人の意見であり、所属する企業や団体は関係ございません。