この記事は Delphi Advent Calendar 2018 24日目の記事として執筆しています。
community.embarcadero.com が community.idera.com に統合されることをご存知でしょうか?
2018年11月26日に、Jim Mckeeth が community.embarcadero.com で次の記事を発表しました。
https://community.embarcadero.com/article/16644-announcing-the-new-embarcadero-developer-community
これにより、今後はエンバカデロのコミュニティサイトは community.idera.com で運用されます。しかしシステムによって提供される機能が変わると、戸惑うことがあります。
例えば、ブログ記事は公開日の新しい順に並んでいますが……
https://community.idera.com/developer-tools/b/blog
日本人スタッフブログの記事に付いているタグ「日本」にアクセスしてみると、必ずしも時系列順ではありません。どうも、タグでの抽出は「最近編集された順」に並ぶようです。
https://community.idera.com/tags/_E5652C67_
こういう微妙な不便さを解決するために、ウェブページのスクレイピングを Google Apps Script で行い、日本人スタッフによるブログ記事だけを公開日の新しい順で抽出できるような処理を書いてみることにしましょう。
※DelphiのアプリででRSSフィードを処理する話は、この記事の一番最後に書きましたので、Delphiの話だけ読みたい方はそちらをお読みください
Google Apps Script とは?
Google のサービスの中で、Gmail, Google Map, Google Drive (Document, Spreadsheet) は多くの方がご存知だと思いますが、Google Drive の中には JavaScript ベースのコードを Google Drive で作成、保存、実行できる機能があります。これが Google Apps Script です。
今回の処理のように、サーバ無しに何かの処理を行いたい場合の選択肢の一つであり、Google Drive 上の各文書を操作したり、Gmail を操作したりできるので、使い所を選べば大変便利です。
実装のために必要なことを整理する
ウェブページの情報をどうやって取得できるか?
HTMLページの取得自体は、UrlFetchApp が使えます。
そして今回のスクレイピングは次のURLを使うことにします。
本来は https://community.idera.com/developer-tools/b/blog をスクレイピングしたいのですが、ページの挙動を調べると、ブログ記事の一覧の現物は上記のURLから取得していました。従って上記URLを直接扱うほうがパフォーマンスがよくなります。
スクレイピングをどのように行えるか?
Google Apps Script でのスクレイピングでは、以下のような選択肢があります。
- XmlService
- 正規表現マッチ
今回は正規表現マッチでやってみることにします。
Google Spreadsheet にどのように書き込めばよいか?
Google Spreadsheet を Google Apps Script から操作する場合は SpreadsheetApp を使用すると、任意のシート、セルを操作できます。
日本人スタッフの記事だけを抽出するにはどうすればよいか?
https://community.idera.com/developer-tools/b/blog のページソースを見る限りでは、残念ながら日本人スタッフの記事だけを抽出する簡単な方法が、どうも見当たらないです。仕方がないので、著者名でフィルタリングしてみることにします。
実際に実装しよう
概ね、以下のようなことをすれば実装できそうです。
- スクレイピングするための正規表現マッチを作る
- Google Spreadsheet の「スクリプトエディタ」に community.idera.com をスクレイピングして Google Spreadsheet に保存する処理を書く
- Google Spreadsheet に保存されたデータから、日本人スタッフの記事だけを抽出して別のシートに保存する
1. スクレイピングするための正規表現マッチを作る
正規表現でパターンマッチするのは非常に一般的ですが、内容が複雑になると作るのが大変です。そこで今回は2つのサイトを使って楽に作ってみることにします。
最初に使うのは https://regexr.com/ 。実際に正規表現マッチを適用したいテキストに対して、それがどのように適用されるかを確認しながら作業できる、大変便利なサイトです。
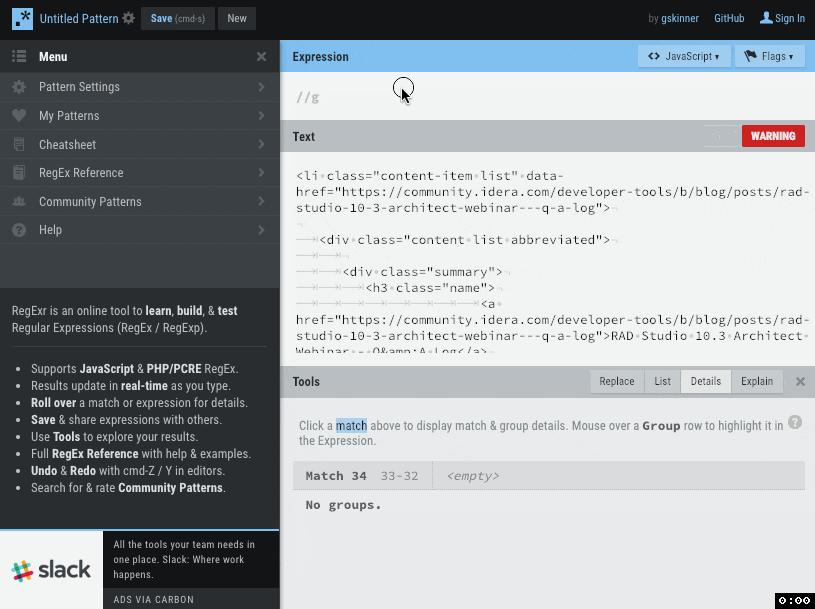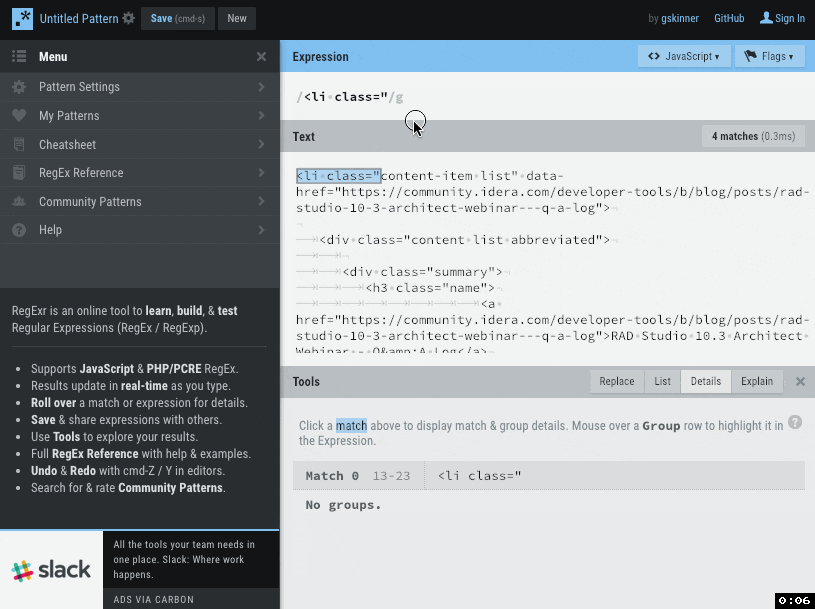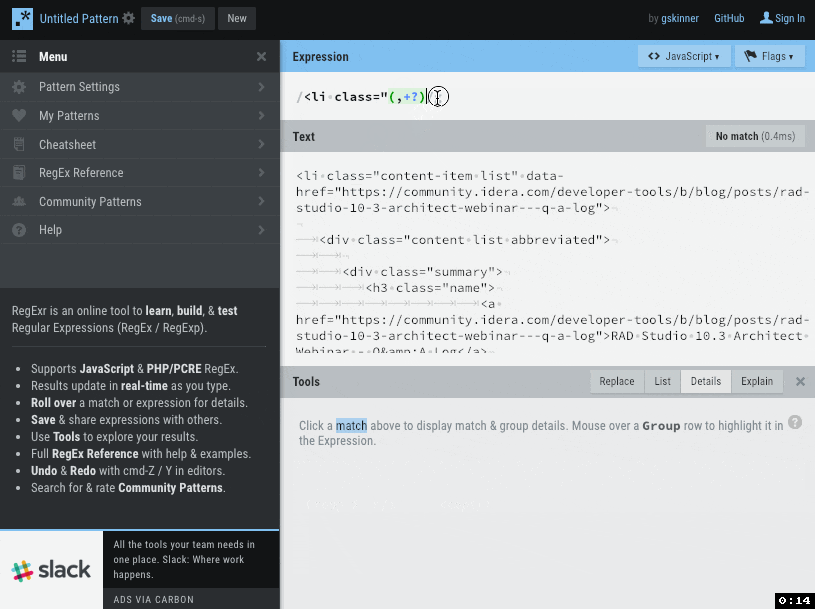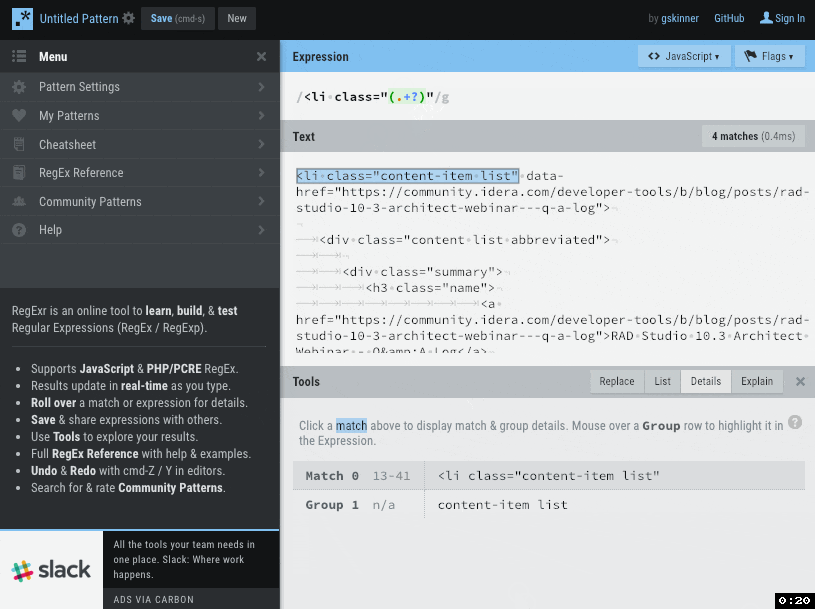
このサイトで記事のページソースを貼り付けて正規表現を書いてみましたが、記事URL、記事タイトル、執筆者、サマリ、記事公開日の情報にマッチする正規表現が書けました。
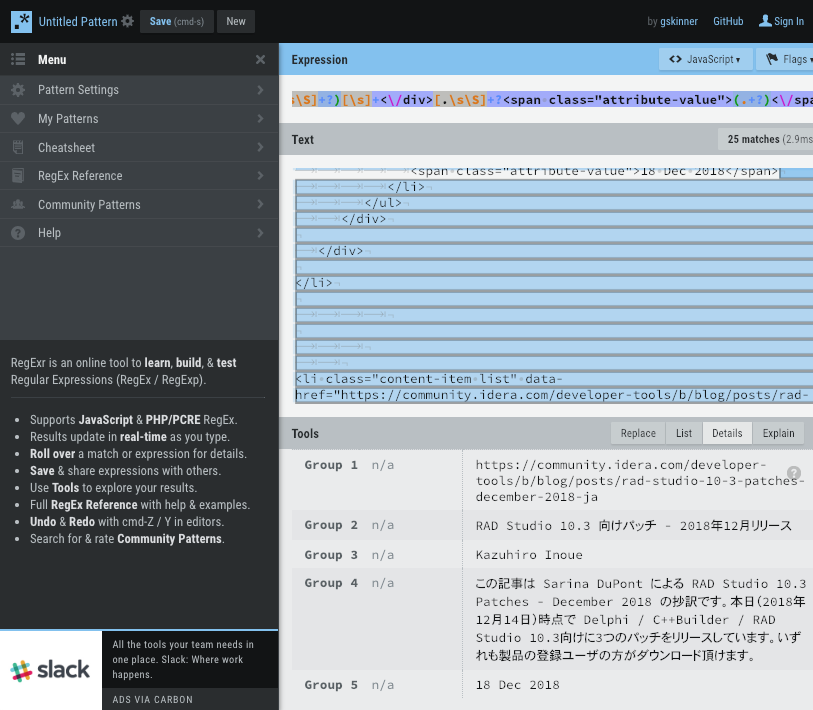
/[\s\S]+?<li class="content-item list" data-href=".+?">[.\s\S]+?<a href="(.+?)">(.+?)<\/a>[.\s\S]+?<span class="user-name">[.\s\S]+?<a href=".+?" class="internal-link view-user-profile">[\s\S]+?[\s]+([.\s\S]+?)[\s]+<\/a>[.\s\S]+?<div class="post-summary">[\s\S]+?[\s]+([\w\s\S]+?)[\s]+<\/div>[.\s\S]+?<span class="attribute-value">(.+?)<\/span>/g
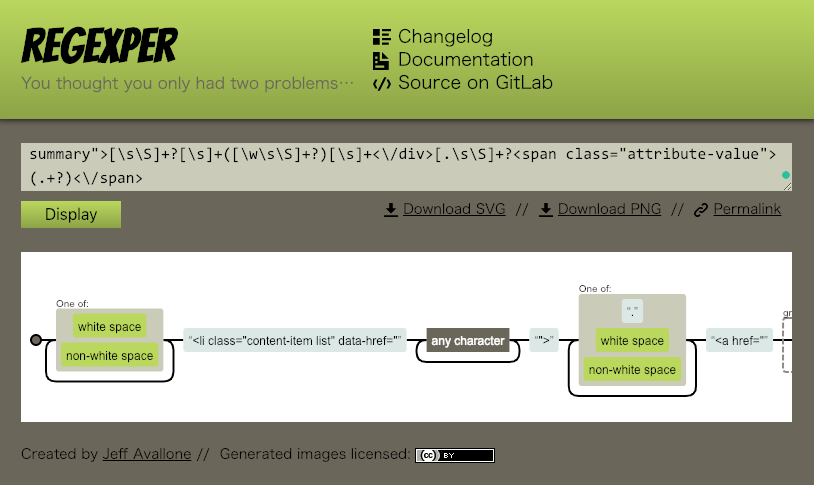
しかし正規表現が書けたのは良いのですが、正規表現にありがちな問題は、不慣れな方にとってパターンマッチの内容をイメージしづらく、また慣れている方でも自分以外が書いた複雑すぎる正規表現を読み解いたりメンテナンスしたりするのは案外手間がかかることです。こういう場合に正規表現を可視化してくれるサイトを使えば、読み解くのが非常に楽になります。というわけで、もう一つのサイト https://regexper.com/ を紹介します。今回作ったものは次のように可視化されました。
2. Google Spreadsheet の「スクリプトエディタ」に community.idera.com をスクレイピングして Google Spreadsheet に保存するようにコードを書く
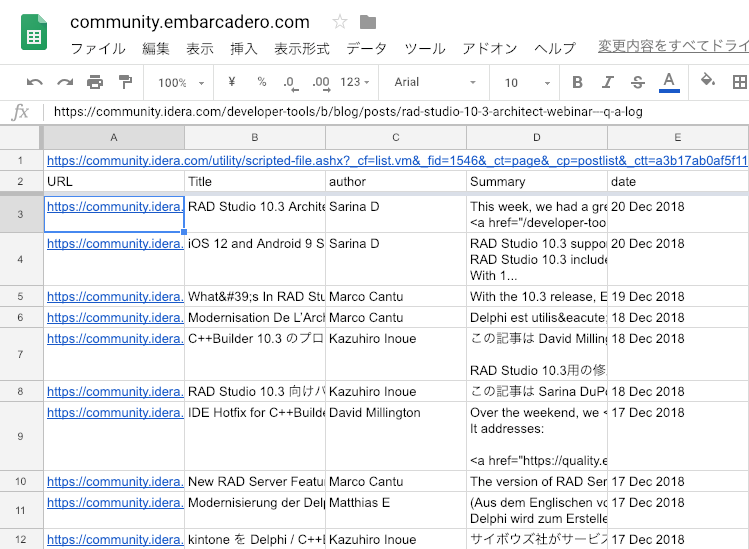
実装に必要となりそうなトピックは既に書いていますので、あとは実装するだけです。次のようなデータを取得することがゴールです。
Google Drive より Google Spreadsheetを新規に作成し、タブ名を "community.idera.com" としておきます。
タブ名はシート間参照で使うので、先に設定するのが良いでしょう。
セルA1に、記事取得用のURLを書き、2行目に見出しをつけておく
次の状態にします。
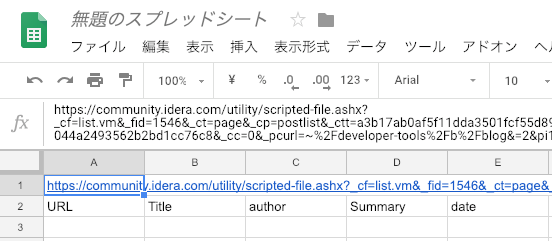
記事のURLはこれを使います。URLパラメータ pi1546= がページング処理のようなので、記載するURLからはページ番号を抜いておきます。Google Apps Script側でページ番号を動的に付け替えるように実装しましょう。
https://community.idera.com/utility/scripted-file.ashx?_cf=list.vm&_fid=1546&_ct=page&_cp=postlist&_ctt=a3b17ab0af5f11dda3501fcf55d89593&_ctc=53078f2bda4045c7bb98db6a7ed4176d&_ctn=b5f5591ee9044a2493562b2bd1cc76c8&_cc=0&_pcurl=~%2Fdeveloper-tools%2Fb%2Fblog&=2&pi1546=
ツールメニューより「スクリプトエディタ」を選ぶ
選ぶと Google Apps Script の編集画面に切り替わります。
コードを実装する
実装する、といいつつ、下記のコードのコピペでOKです。コードのコメントを読めば基本的な実装内容は理解できると思います。
function ScrapeBlogCommunityIderaCom () {
// このスクリプトに紐づいているスプレッドシートに含まれる"community.idera.com"シートを操作する
var sheetData = SpreadsheetApp.getActive().getSheetByName("community.idera.com");
// アクセスするURLはシートのA1に書いてあるものを使う
var baseURL = sheetData.getRange(1, 1).getValue();
// 3行目からデータを書く
var i = 3;
// 記事一覧表示の最新10ページ分をスクレイピングする
for (page = 1 ; page <= 10 ; page++) {
var URL = baseURL + page;
Logger.log(URL)
var response = UrlFetchApp.fetch(URL);
var html = response.getContentText('UTF-8');
Logger.log(html);
// 正規表現マッチにより、ページソースから記事情報を取得してスプレッドシートに書く
var BlogTitle = /[\s\S]+?<li class="content-item list" data-href=".+?">[.\s\S]+?<a href="(.+?)">(.+?)<\/a>[.\s\S]+?<span class="user-name">[.\s\S]+?<a href=".+?" class="internal-link view-user-profile">[\s\S]+?[\s]+([.\s\S]+?)[\s]+<\/a>[.\s\S]+?<div class="post-summary">[\s\S]+?[\s]+([\w\s\S]+?)[\s]+<\/div>[.\s\S]+?<span class="attribute-value">(.+?)<\/span>/g
while ((matchTitle = BlogTitle.exec(html)) != null ) {
sheetData.getRange(i,1).setValue(matchTitle[1]); // url
sheetData.getRange(i,2).setValue(matchTitle[2]); // title
sheetData.getRange(i,3).setValue(matchTitle[3]); // author
sheetData.getRange(i,4).setValue(matchTitle[4]); // summary
sheetData.getRange(i,5).setValue(matchTitle[5]); // date
i++;
}
}
}
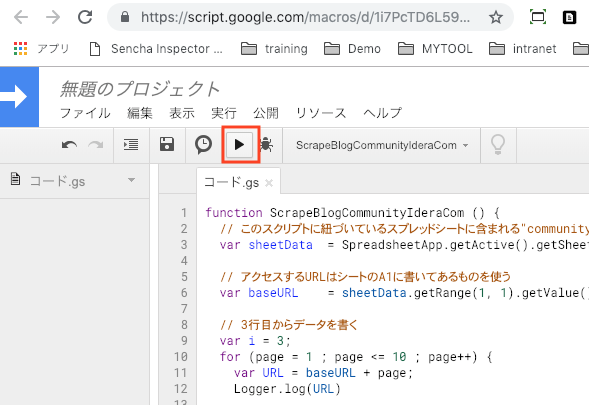
実行する
実行ボタンを押してみましょう。初回実行時は権限確認が必要なので、内容を確認して許可します
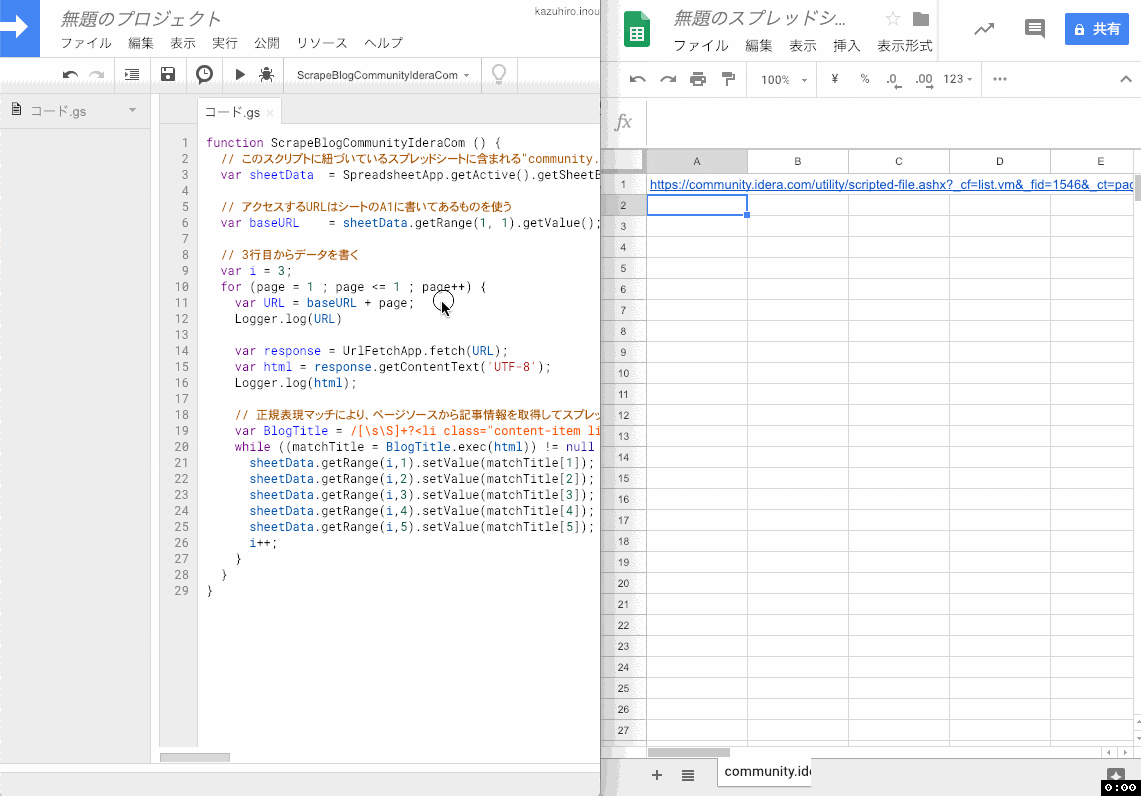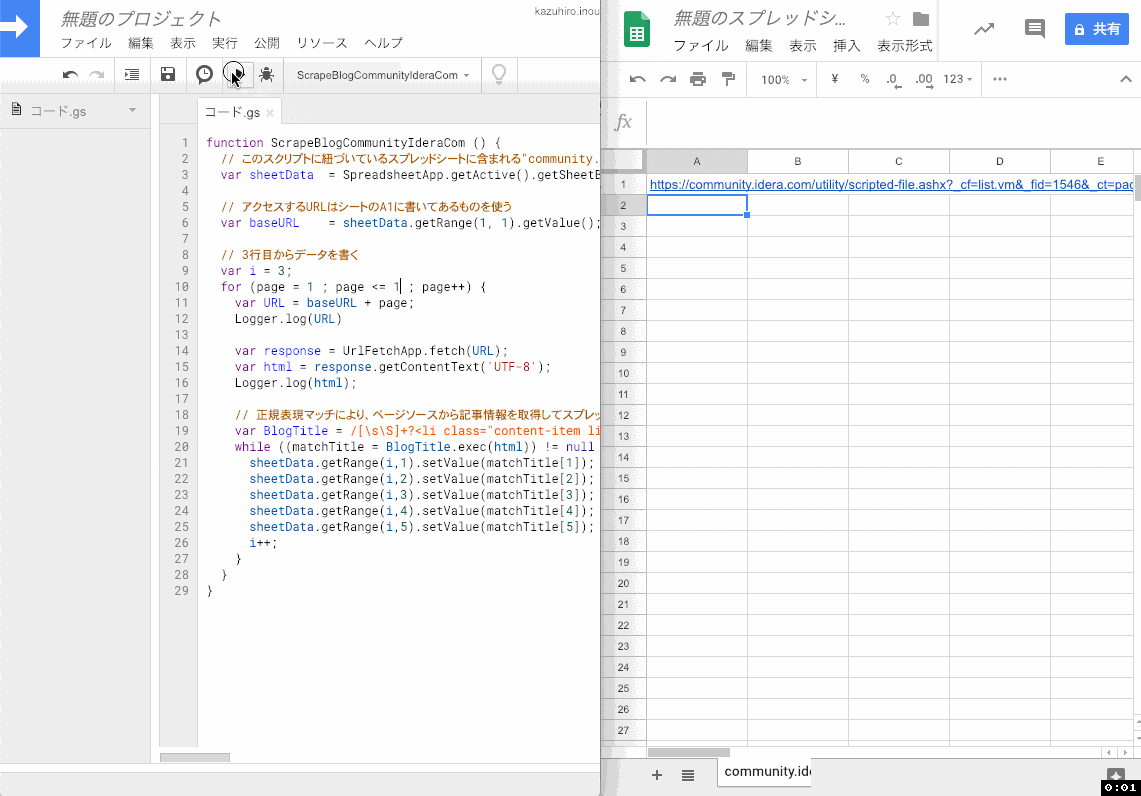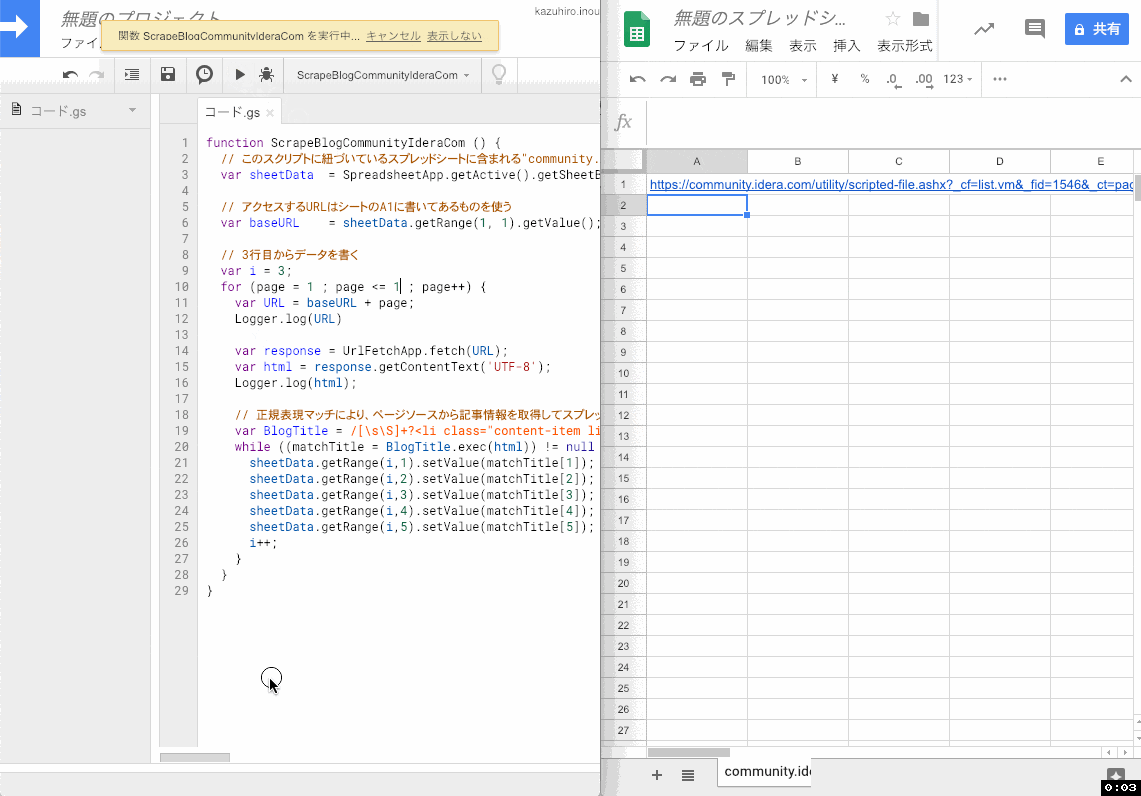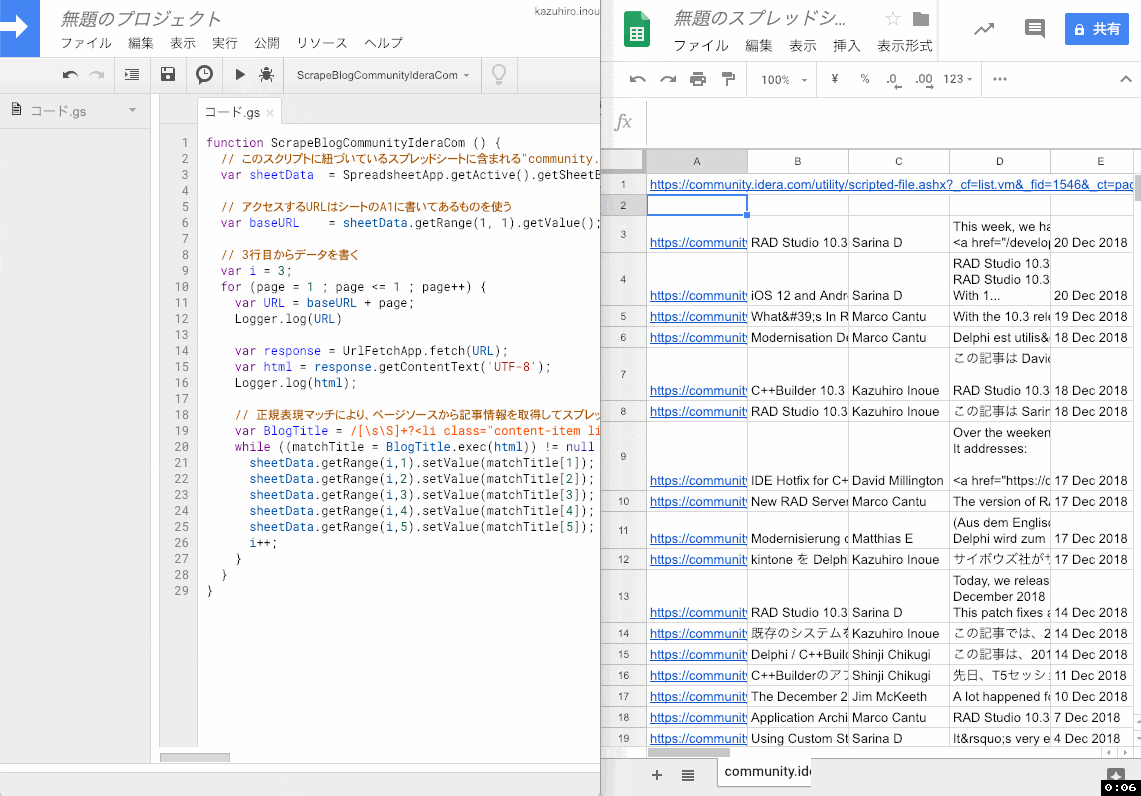
実行完了すると Google Spreadsheet 側にブログ記事の一覧が記入されます。
3. Google Spreadsheet に保存されたデータから、日本人スタッフの記事だけを抽出して別のシートに保存する
取得できたデータをもとにして、日本人スタッフの記事だけを抽出したシートを作ってみます。
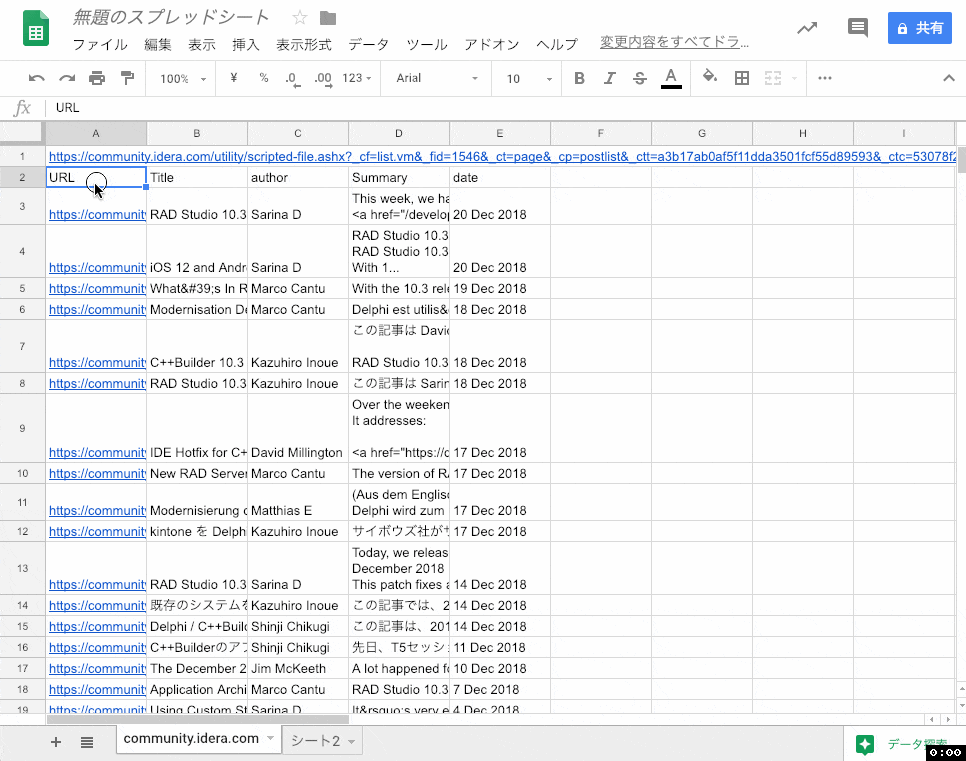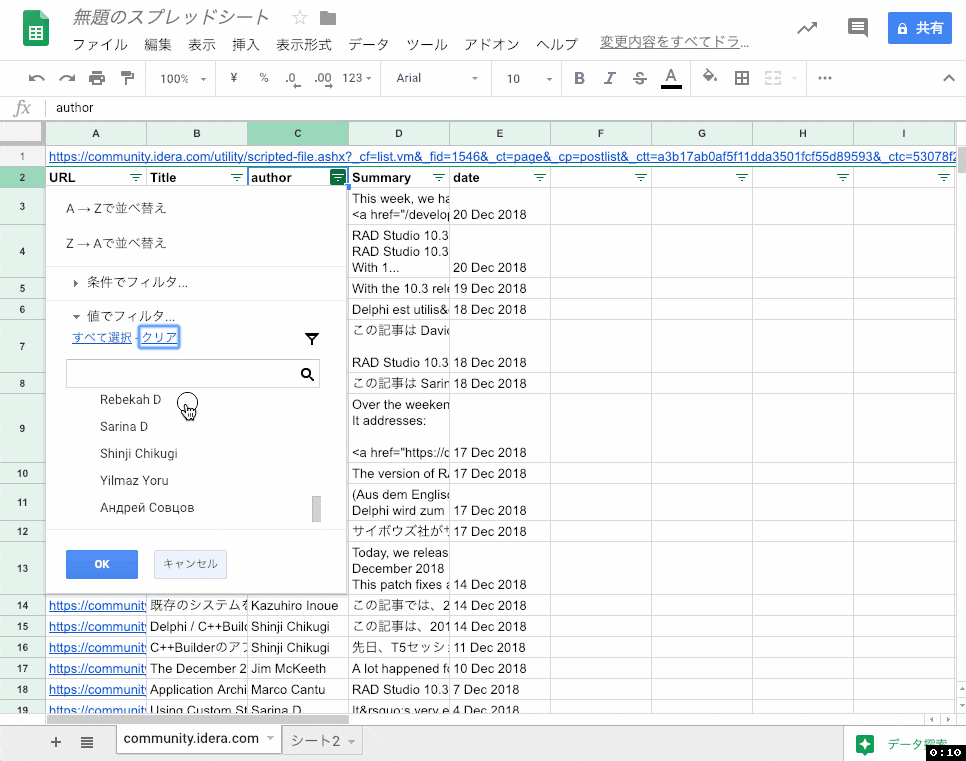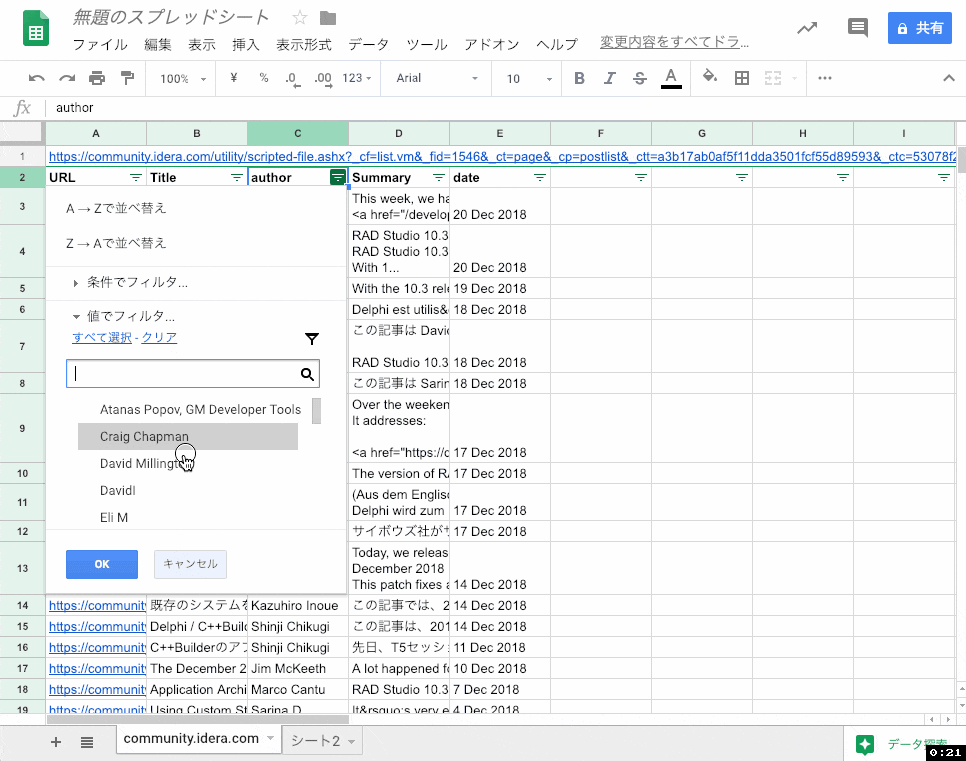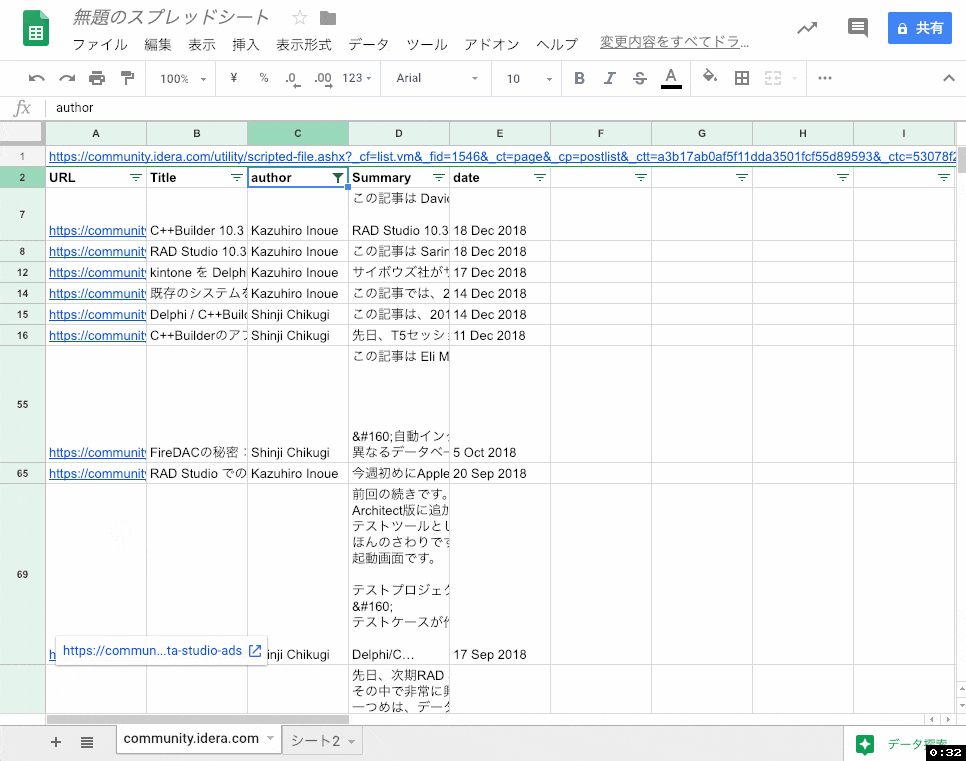
シート2を新規に作成し、そのセルA1に次のように入力してみてください。
=query(community.idera.com!A2:E, "where C = 'Kazuhiro Inoue'",1)
入力すると、私の記事だけがシート2に抽出できているはずです。

where の条件に、他の著者を or C = 'Shinji Chikugi' のように追記すれば、その他の著者の記事も抽出できるようになります。
別の方法としては、別シートに抽出するかわりにフィルタを作成する、という方法もあります。
その他の落ち穂拾い
community.idera.com でエンバカデロのブログ記事をRSSフィードで取得したいんですけど?
ブログ記事のRSSフィードは、次のURLで取得できるようです。
RSSフィードが取れるなら、わざわざスクレイピングとかしなくても、Google Spreadsheet の IMPORTFEED 関数で良いのでは?
ええ、そうです。この記事書きながら改めて確認していたら、RSSフィードが取れることに気づいたので、スクレイピングは不要ですとも orz
適当なシートのセルに次のように書けば……
=IMPORTFEED("https://community.idera.com/developer-tools/b/blog/rss",,1)
次のような結果が得られます。
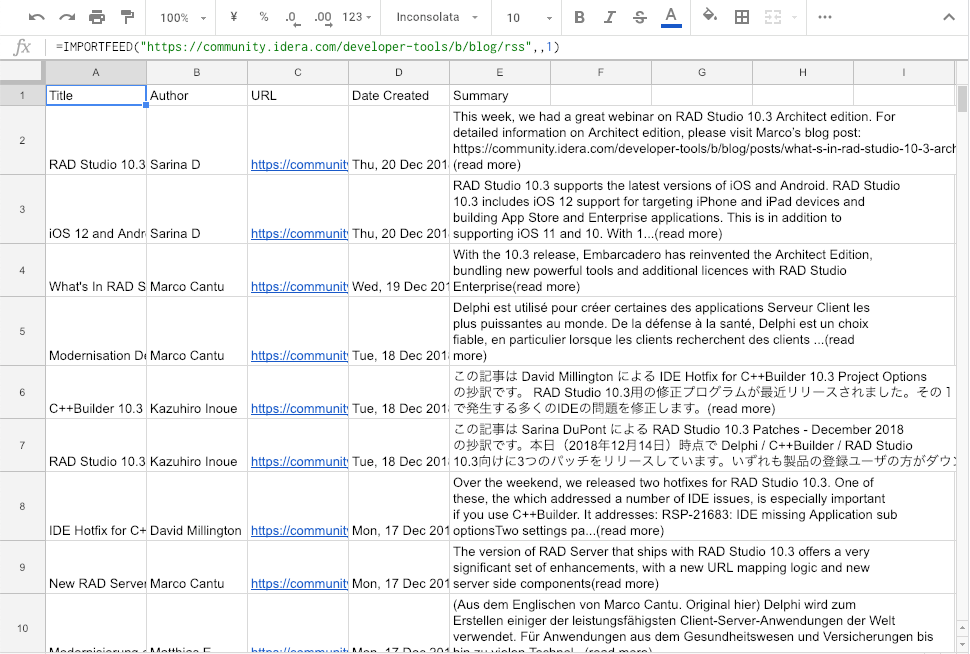
ではこれで十分かというと、このRSSフィードは直近の15件分しか取得できないようです。もっと多くの件数を取得したいならば、今回作成したようなスクレイピングのほうがよさそうです。
Delphi の話がないんですけど……
そうですよねえ。自分もそう思いました。じゃあ、上記のRSSフィードをDelphiで書いたアプリで扱ってみることにしましょう。具体的には、下記の機能を持つアプリを作ります。
- RSSフィードを取得し、日本人スタッフの記事だけを抽出する
- 抽出したフィードをグリッドで一覧表示する
- 一覧表示の特定の行を選択したら、ブラウザで該当記事を表示する
まずは Enterprise Connectors の RSS Data Source コネクタを用意します。
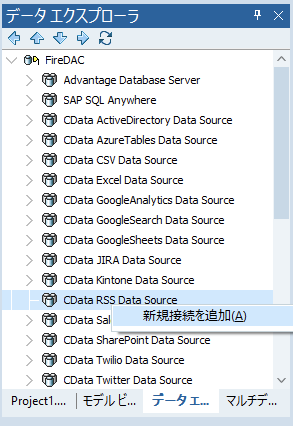
名前は community.idera.com にしておきます。
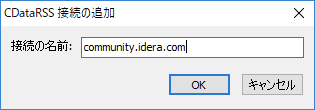
とりあえず、URIにRSSフィードのURLを指定します。
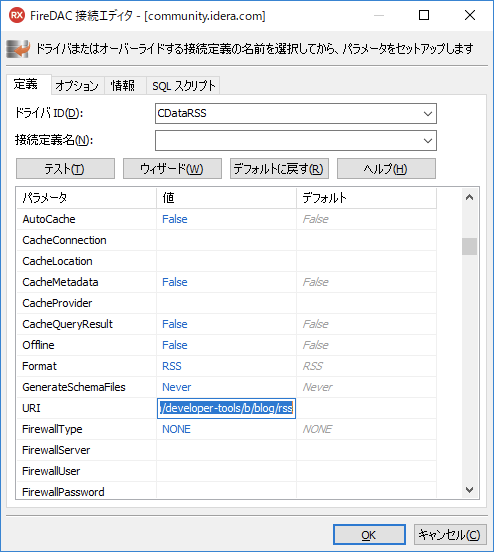
RSS Data Sourceは参照しかできないデータソースなので、テーブルではなくビューで操作します。
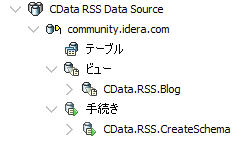
Enterprise ConnectorsはWindows 32-bitおよひ64-bit向けビルドに使えますので、今回はVCLアプリケーションで作ってみます。
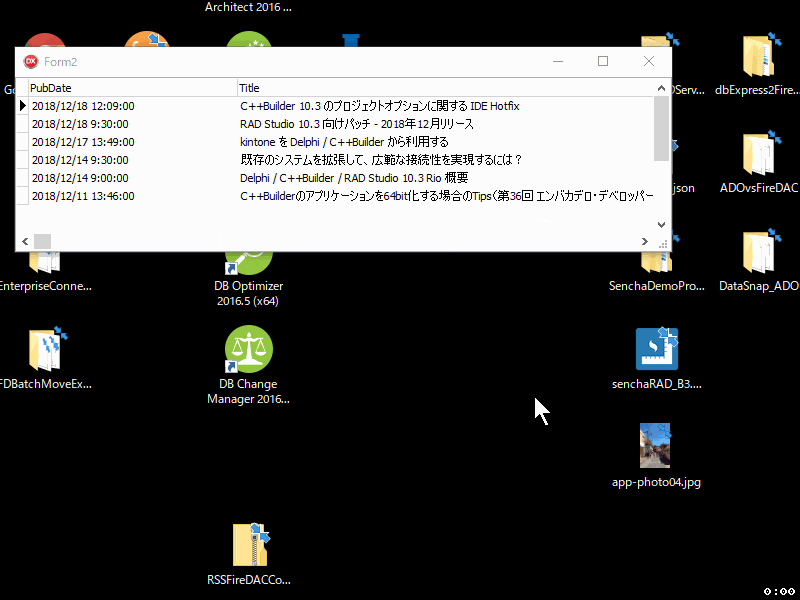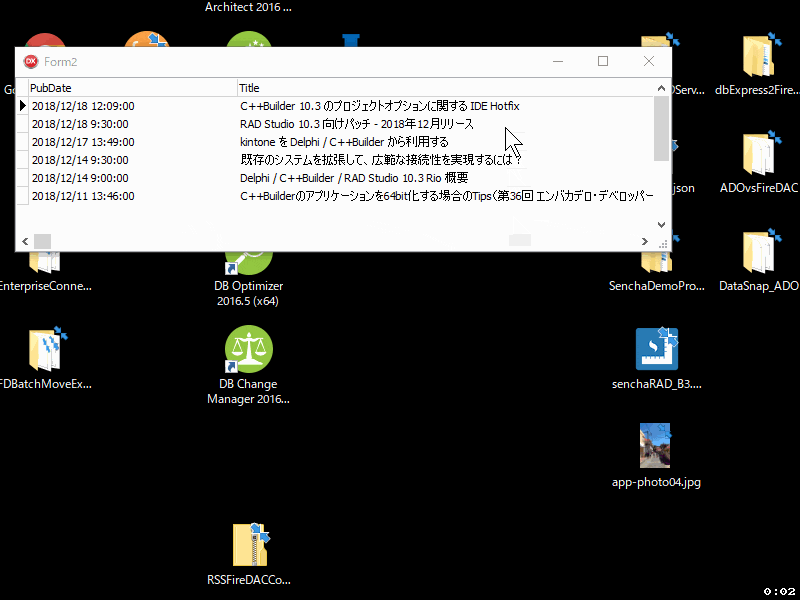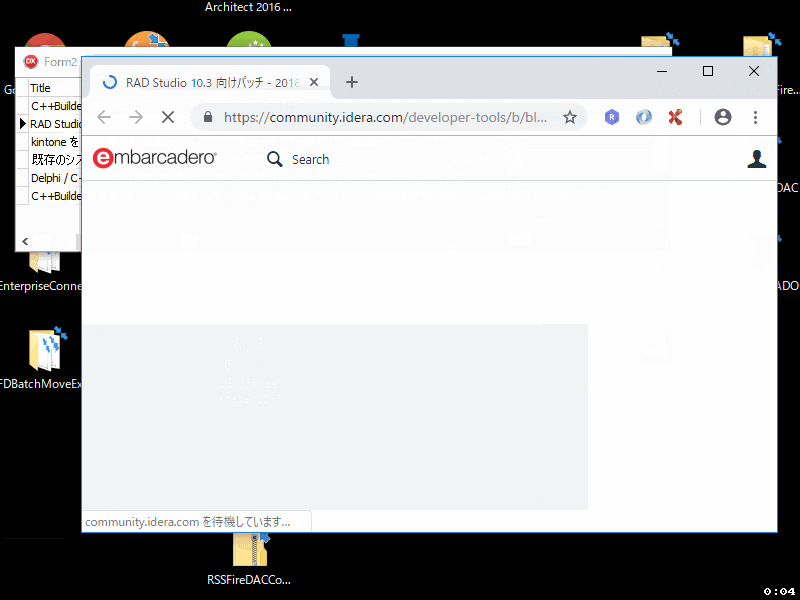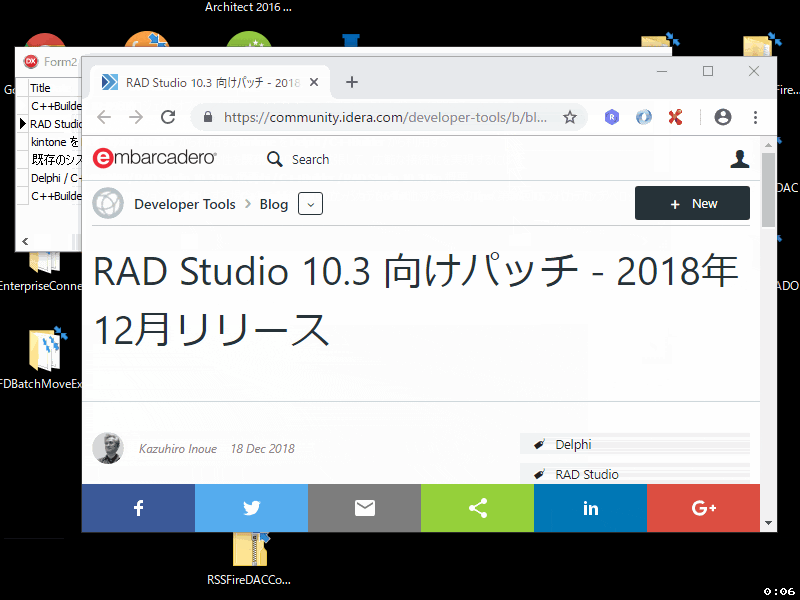
RSS Data Sourceのビューをフォームにはりつけて、DBGridで表示させてみましょう。

- データエクスプローラからビューをポトペタしました
- ビューのフィールドエディタで使うフィールドを選びました
- TDataSourceをポトペタして、ビューを参照するように DataSet を設定しました
- DBGridを置き、TDataSourceを利用するように設定しました
- ビューをActiveにしたら、データの取得、表示ができることが設計時画面で確認できました
次に、日本人スタッフが投稿した記事だけを抽出するようにしてみましょう。例えば、クエリエディタを開いて where を次のように書いてみると、私の記事だけが抽出できます。
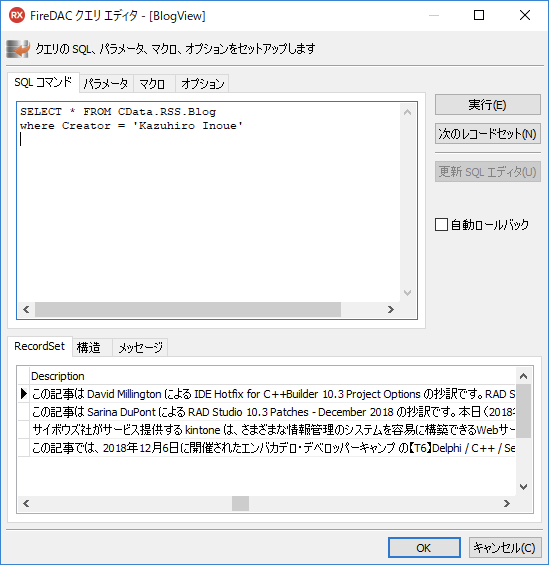
あるいは、次のように書いて、他の著者の分も抽出してみましょう。RSSフィードのような情報を SQL の文法で操作できるので、とても楽ですね。
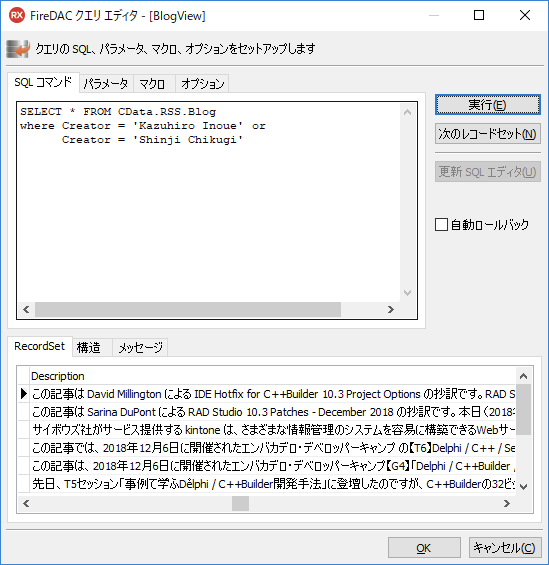
これだけでも十分かもしれませんが、せっかくなので特定の行をダブルクリックしたらブラウザで記事を開くようにしてみましょう。これはShellExecuteで実現できます。ShellExecuteはUsesにShellAPIを追加して使います。
OnDblClickのイベントにコードを実装します。
使用するブラウザはOSでデフォルト設定しているものを使います。次のコードのように、フィールド 'Link' の URL を ShellExecute で 'open' するように実装します。実質的な実装は1行だけです。
procedure TForm2.DBGrid1DblClick(Sender: TObject);
begin
ShellExecute(
0,
'open',
PChar(DataSource1.DataSet.FieldByName('Link').AsString),
nil,
nil,
SW_SHOW
);
end;
これで、community.idera.com に投稿された日本人スタッフの記事だけをリスト表示し、それをブラウザで開けるアプリができあがりました。