今回の目標
今回はSparkStreamingにSparkSQL, DataFrameを組み合わせて実践的な集計を実装します。
SparkSQL、DataFrameについて
SparkSQLとDataFrameはSparkで構造データを扱うモジュールで分散処理クエリエンジンとして動作する。
Hiveデータを取り込んで操作することも出来る。

※参照元 http://spark.apache.org/sql/
準備
SparkStreaming開発の環境設定は前回の投稿を参照してください。
http://qiita.com/kaz3284/items/72dc7483872c412b6ba7
コードを書く
- 本体:sbtプロジェクトのsrc > main > scalaに作る。
ss1.scala
package org.apache.spark.streaming
import org.apache.spark.sql.SQLContext
import org.apache.spark.{Logging, SparkConf}
import org.apache.spark.storage.StorageLevel
/**
* `$ nc -lk 9999`で入力データを設定する。
*/
object NetworkWordCountSQL extends Logging {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("NetworkWordCountSQL")
val ssc = new StreamingContext(sparkConf, Seconds(10))
// Create a socket stream on target ip:port and count the
val windowData = ssc.socketTextStream("localhost", 9999, StorageLevel.MEMORY_AND_DISK_SER)
windowData.foreachRDD{jsonRdd =>
if (jsonRdd.count() > 0) {
val sqlContext = SQLContext.getOrCreate(jsonRdd.sparkContext)
val rowDf = sqlContext.read.json(jsonRdd)
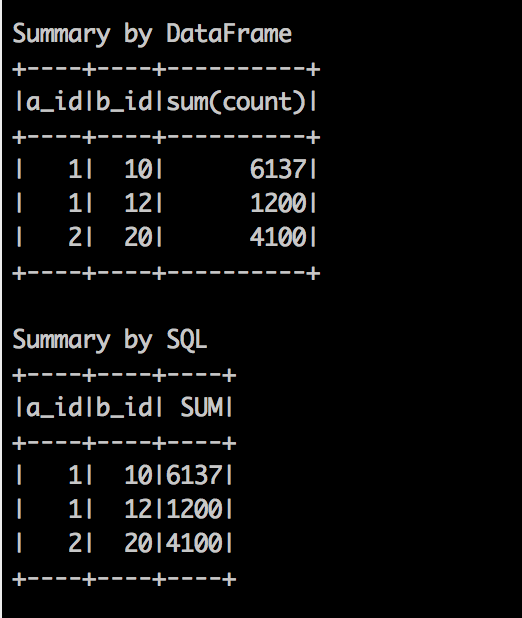
println("Summary by DataFrame")
rowDf.groupBy("a_id","b_id").sum("count").show()
println("Summary by SQL")
rowDf.registerTempTable("json_data")
val sumAdf = sqlContext.sql("SELECT a_id, b_id, sum(count) AS SUM FROM json_data GROUP BY a_id, b_id")
sumAdf.show()
}
}
ssc.start()
ssc.awaitTermination()
}
}
- 今回コードのgithubは以下
https://github.com/kaz3284/4qiita/blob/master/sparkstreaming/ss2/src/main/scala/ss2.scala
buildする
cd /Users/kaz3284/github/4qiita/sparkstreaming/ss1 #sbtプロジェクトのホーム
sbt assembly
実行する
-
準備
pre-build版をDLして実行環境を作る。※手もとでspark-submitを動かせるようにするため。- 下記リンク先で「1.5.2」「Pre-built for Hadoop 2.6 and later」を選択してDL、解凍して${SPARK_HOME}とする。
http://spark.apache.org/downloads.html
- 下記リンク先で「1.5.2」「Pre-built for Hadoop 2.6 and later」を選択してDL、解凍して${SPARK_HOME}とする。
-
sparkstreaming起動
Macで実行する場合の例
export SPARK_HOME=/Users/kaz3284/develop/spark/spark-1.5.2-bin-hadoop2.6
export SS_SRC=/Users/kaz3284/github/4qiita/sparkstreaming/ss1
${SPARK_HOME}/bin/spark-submit ${SS_SRC}/target/scala-2.11/ss1-assembly-1.0.jar
- ncでメッセージ送る
nc -lk 9999
{"a_id":1,"b_id":10,"c_id":100,"count":1000}
{"a_id":1,"b_id":10,"c_id":100,"count":1001}
{"a_id":1,"b_id":10,"c_id":101,"count":1011}
{"a_id":1,"b_id":10,"c_id":101,"count":1012}
{"a_id":1,"b_id":10,"c_id":101,"count":1013}
{"a_id":1,"b_id":10,"c_id":110,"count":1100}
{"a_id":1,"b_id":12,"c_id":120,"count":1200}
{"a_id":2,"b_id":20,"c_id":200,"count":2000}
{"a_id":2,"b_id":20,"c_id":210,"count":2100}
- 下記のような標準出力が出れば今回のプログラム完成!!
- 補足:開発時に余計なメッセージを消す場合は以下を実施する。
cp ${SPARK_HOME}/conf/log4j.properties.template ${SPARK_HOME}/conf/log4j.properties
vi ${SPARK_HOME}/conf/log4j.properties
- 以下のように標準出力の部分をINFO=> WARNへ
log4j.properties
# Set everything to be logged to the console
log4j.rootCategory=WARN, console
最後に
今回はStreamingとDataFrame, SQL構造的なデータを取り込んでの集計を実装しました。
DataFrameで取り込んでしまえば集計の基本である「GroupBy」のような処理を簡単にかけることが実感できます。
次はより実践的な分散環境での開発&実装を紹介します。
今回の開発の参考までに
spark git
spark docs