はじめに
本記事はFringe81 アドベントカレンダー2017の5日目の投稿です。
現在稼働中のAWS(EMR)上のHadoopバッチを低コスト化する試みとして、GCPのDataflow&BigQueryへ移植した簡易版のプロトタイプ実装について書きました。
(参考までに、EMR上のhadoopバッチについてはコチラに昔私が書いた記事があります...今となっては時代遅れなのであくまで参考までに(^^;))
Cloud Dataflowへ期待したこと
GCP上の主要リソースをつなぐデータ処理を運用コスト最小(NoAdm)で実現できるソリューションであること。
データ処理はリアルタイムに近づけようとしたり、データ量が増えると、
リソースパラメータ調整、クラスタ再起動、再実行等で運用コスト増大するため、
このような複雑さをトータルで効率化できることを期待しました。
下記のようにGoogleデータ基盤10年来の集大成とのことで過剰な期待してます(^^;)
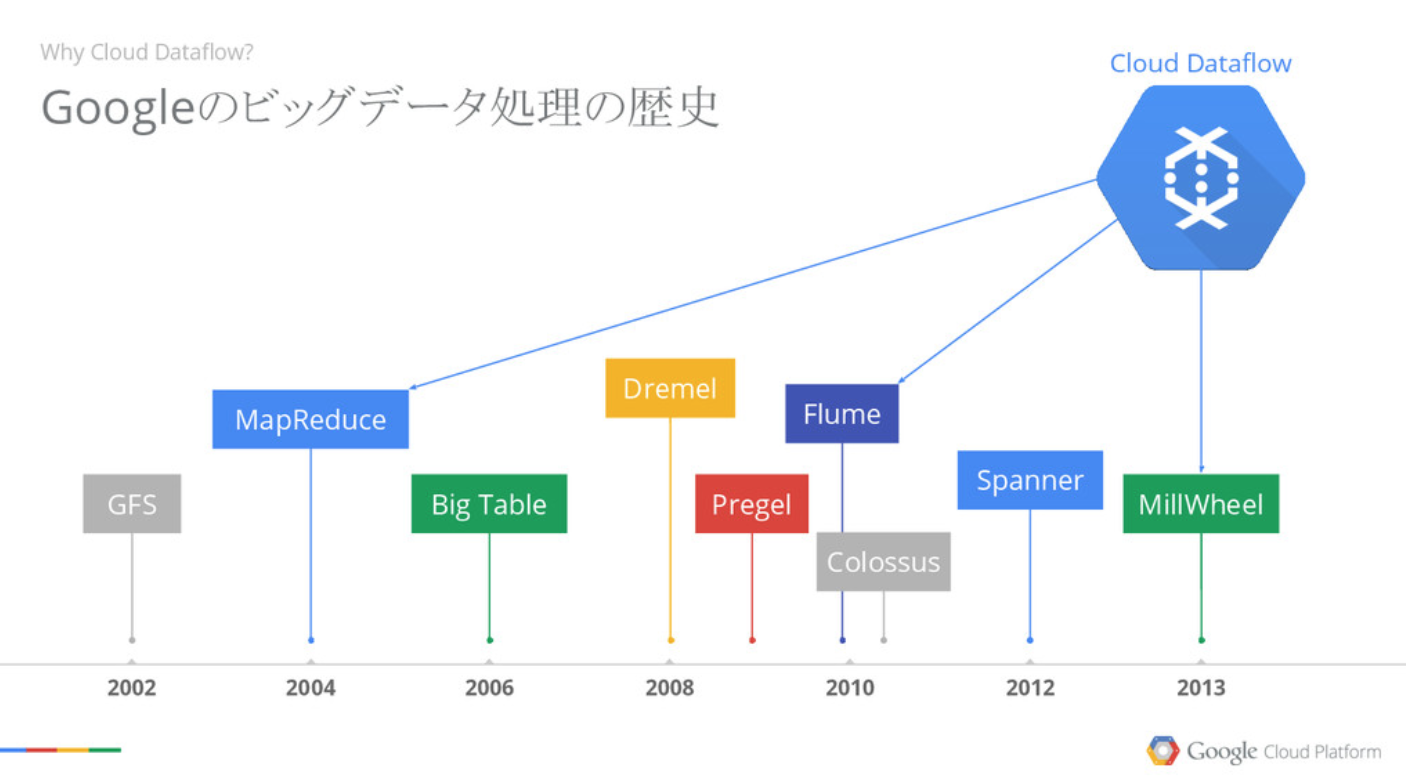
(GoogleCloudNext'17資料より)
一般的にdataflowがどういう処理に適するかのイメージはこのページが参考になります。
https://cloud.google.com/solutions/processing-logs-at-scale-using-dataflow?hl=ja
何をやるのか
ユーザ行動の計測機能によりBigQueryへ時系列の行動履歴が入っていることを前提として、
BigQuery上のデータをSQLでユーザid、行動idをkeyとしてソートし、
抽出条件に合致したユーザと取り出すというバッチ処理の実装です。
具体的には
bigquery(user_history)にあるユーザ毎の行動履歴データから、
mysql上のマスタデータ(segment)に設定された条件(どの行動を何回やったユーザを抽出するか)に合致するユーザを抽出します。
構成を簡単に図で表すと以下のような流れで実現します。
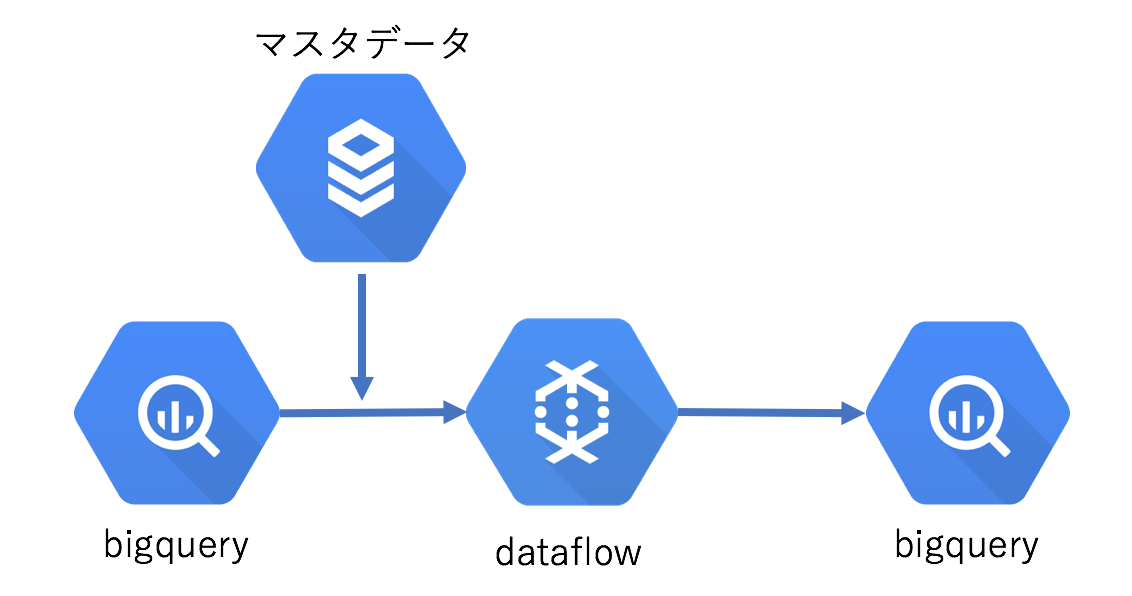
使うもの
scio(0.3.0)
scioはApache Beam と Google Cloud Dataflowに対応するScala APIです。
spotifyが自社のデータ処理基盤を刷新するために開発されたもので、現在でも大規模処理で使われホットに開発されてます。
詳しくはsciowiki を参照ください.
準備
GCPアカウントとdataflowを動かすための設定が必要です。
下記公式ページに詳細の手順があるのでご参照ください。
https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-maven
コード
本記事のソースコードは以下へ置きました。適宜参照ください
要所ピックアップ
副入力
データを取り出し、型に合わせて変換してサクッと完了。
// DB(mysql)からマスタ情報取得
val segmentsSi = sc.parallelize(FindSegments()).asIterableSideInput
抽出処理
- bigqueryの「user_history」テーブルからデータ取り出し
- action_historyをセグメンテーション処理できる形へ
- 処理結果をbigqueryの「segmentation_result」へ保存
def apply(unitId: Int, input: String, output: String, sc: ScioContext, segmentsSi: SideInput[Iterable[Segment]]): Unit = {
// bigqueryに入っている履歴データを処理に適したデータへ
val userHistories = sc.bigQueryTable(input)
.map {row =>
val userId = row.getString("user_id")
val actionHistory = row.getString("action_history").split('|').map(a => Action(a.toLong)).toList
UserHistory(unitId, userId, actionHistory)
}
// マスタデータを副入力で取り込み,処理結果をbigqueryへ保存
userHistories.withSideInputs(segmentsSi)
.flatMap { (userHistory, si) =>
val segments = si(segmentsSi)
val actionIdCountMap = userHistory.actionHistory.groupBy(_.actionId).mapValues(_.size)
findFilledSegmentIds(userHistory.userId, actionIdCountMap, segments)
.map(r => SegmentationResult(r.unitId, r.userId, r.filledSegmentId))
}.toSCollection
.saveAsTypedBigQuery(output, Write.WriteDisposition.WRITE_TRUNCATE, Write.CreateDisposition.CREATE_IF_NEEDED)
}
実行
Dataflowで実行
GCP上に環境構築の上、下記のコマンドで実行します。※zoneは「asia-east1-a」
(--runner=DirectRunnerとするとお手軽なローカルが可能です。)
sbt "runMain main.SegmentationMain --project=[プロジェクトid] --runner=DataflowRunner --zone=asia-east1-a --network=[ネットワーク名] --subnetwork=regions/asia-east1/subnetworks/[サブネットワーク名] --tempLocation=[gcs上の一時処理パス] --jdbcUri=[jdbcのuri] --dbUser=[dbユーザ名] --unitId=1 --input=[bigqueryのinputデータtable] --output=[bigqueryのoutputデータtable]"
実行すると
- フロー

- bigqury出力結果

inputデータ
- bigquery(user_history: ユーザ毎の行動履歴データ[|区切り])
user_id,action_history(行動履歴データ[|区切り])
aaaa,111|112|112|113|113|113|114|114|114|114|115|115|115|115|115
bbbb,111|112|112|113|113|113|114|114|114|114|215|215|215|215|215
cccc,111|112|112|113|113|113|214|214|214|214|215|215|215|215|215
dddd,111|112|112|213|213|213|214|214|214|214|215|215|215|215|215
eeee,211|212|212|213|213|213|214|214|214|214|215|215|215|215|215
outputデータ
- bigquery(segment毎に条件を満たしたユーザidを書き出し)
unit_id, segment_id,user_id
まとめ
実装してみて
期待通り、Hadoopバッチに比べてかなり見通しのよいシンプルな実装でバッチ処理が書けました。
sparkと比べても入力先を切り替えるだけで、バッチ->ストリーム処理へ切りかえられたり、
RDDに縛られるみたいな制約なくシンプル実装できます。
また、dataflow上でサクッと他のGCPサービスとつなげた処理が実現できるのは素晴らしいです!
動かしてみて
まだまだプロトタイプ動かしたみた程度ですが、運用コスト削減に大きく役立つと確信しています。
知見溜まってきたら改めて追加の情報公開して行きたいと思っております〜
開発時に参考にした情報
- scio wiki
https://github.com/spotify/scio/wiki - stackoverflow
- [Google Cloud Platform] Cloud Dataflowでフルマネージドなデータ処理を試してみた
https://adtech.cyberagent.io/techblog/archives/1424 - dataflowはどういうものなのか