初めに、前回から大規模データ処理について連載させていただきましたが、
思ったより多くの方にストックいただき、この分野の関心の高さを改めて実感しております。
われわれも、この分野の事業に力を入れており、
積極的に取り組んで行く所存でございます!
それでは 大規模データについて第2回 ~EMR(Hadoop)について、なぜEMRなのか~
EMR(Hadoop)について
ご存じない方は、EMRって何?ということになると思うので
軽く説明させていただきます。
EMRとは、Amazon Web Service社(AWS)が提供している
__クラウドでのHadoopの実行環境__です。
正式名称は「Amazon Elastic MapReduce」になります。
処理対象データをAWSのS3(クラウドストレージ)に配置し、
必要なコンピューティングリソースをを指定して実行すると、
必要な時に必要なだけ、文字通り「Elastic」にHadoopを実行できるというサービスです。
詳細はAWSの説明ページにて、
http://aws.amazon.com/jp/elasticmapreduce/
EMR運用状況について
2010年から先ず自社サーバでHadoop運用を開始し、
2012年からEMRに移行し始めました。
現在では、主要な大規模データ処理は全てEMR上で動いている状況です。
前回は「digitalice」のデータ処理フローを紹介しましたが、
「TagKnight」のデータ処理(もう少しシンプルなフロー)も
EMRで実行しています。
ここまでで、Hadoopがよくわからない?
EMRがピント来ない?
という方は、、、
先ず、以下のリンク先から理解を深めていただきたく思います。
初めてEMR開発に係わっていただくエンジニアにぜひ見て
いただきたいページになります。HadoopやEMRについて
分かり易くまとめられています。
HadoopやEMRに関する入門ページはネット上にたくさんあります。
入門的な説明や一般的な説明はそれらのページに任せ、
本連載では、いままで培ったデータ処理開発で得られた現場開発者に
役立つ情報をお伝えしたく思います!
(できる限り...)
EMR連載について
さて、本題に戻りまして、EMRの連載について詳細をお伝えします。
全3回しました。
なぜEMRなのか?
と、その前に「なぜHadoopを使い始めたのか」というところから
お話させていただければと思います。
なぜHadoopなのか?
ぶっちゃけ、Hadoop以前は集計処理をMySQL上で実行していました...
ご存じの方も多いとおもいますが、MySQLのマスタサーバは
スケールアウト(処理を分散化)出来ません。
(ごにょごにょすればできますが...大変なのでここでは出来ないとしますw)
なので、処理が間に合わなくなってくるとサーバをスケールアップ
(高性能化して置き換え)するしかありません。
しかし、スケールアップやチューニングしても現実はスズメの涙程度の効果...
そのような運用状況のなか、MySQLでのデータ処理に限界を感じる出来ごとがありました。
digitaliceの前身であるiogousのクリエイティブ最適化処理の拡張機能を開発した時です。
配信結果を集計して、ユーザの属性毎にクリエイティブ最適化を施して配信するという要件でした。
この時のMySQL(RDBMS)での大規模データ処理について深堀させていただくと、
図のようになり、あらゆるところに落とし穴(地獄)が出てくる状況でしたw
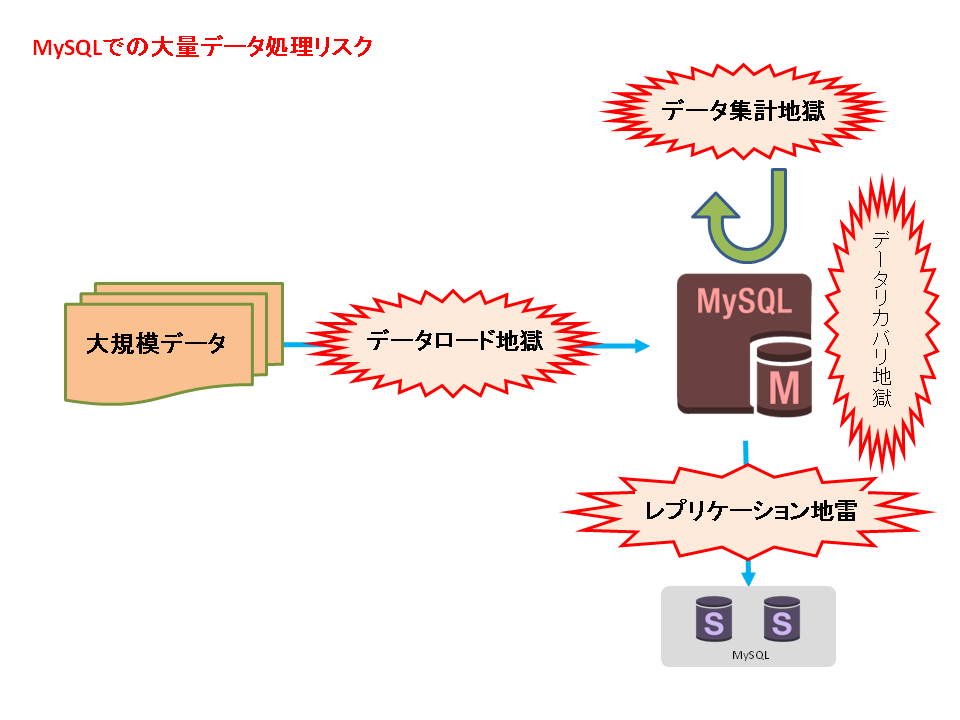
(図1MySQLでの大量データ処理リスク)
まず、集計するためには先ずデータをロードする必要があります。
~第1章データロード地獄~
データ量が1,000万件を超えてくるとここから気を使わないといけませんw
MySQLマスタサーバへアップ出来るデータ量はせいぜい数百万件/回です。
(チューニング済みの3桁万円サーバにて)
億レベルになると、数十ファイルに分けて数時間かかって
アップロードする必要があります...
ここで負荷をかけすぎるとMySQL死亡により「第1.5章データリカバリ地獄」へ
乗り切れても、「第2章データ集計地獄」が待ってますw
~第1.5章 データリカバリ地獄~
よっぽどのことがない限りここまでは至りませんがw
サービス停止~マスタサーバの切り替え
~バックアップデータからのリカバリと激しく手間が掛ります。
~第2章 データ集計地獄~
やっとのことでロード終わったと思ったらここからが本番w
インデックスの貼り忘れがないか最終確認したらSQLコマンドを発行します。
あとは、MySQLの力を信じて待つのみwww
最悪の事態を避けるためリソースモニタで監視しつつ...
また、「レプリケーション地雷」にも要注意です。
(レプリケーションとは参照負荷分散のためマスタサーバのデータを
スレーブサーバにコピーする仕組みで、広告配信サービスのような参照負荷が
高いサービスには必須の仕組みです)
処置をせずに大規模データが貧弱なスレーブサーバに流れてしまうと、
スレーブサーバが死んでしまったり、レプリケーション遅延等の問題を起こします。
流れてしまった時点で気付いたら、スレーブサーバのレプリケーション無視tableリストに
入れればスレーブ問題は回避できるかに思われます...
が、実は根本的にマスタサーバからデータが流れない設定にしておかないと、
ネットワークにデータ転送負荷がかかってしまって更に面倒な問題が起きる可能性が...
そうなると、スキーマ別切り、マスタサーバ再起動...が必要で...
となると大量データ処理のための高性能MySQLサーバが必要で...
そのためにデータの切り分けをして...
となかなかハードな運用です^^;
Hadoop特徴
上の問題を解決するものとして導入したのがオンプレ(自社サーバ)Hadoopです。
先ず、 Hadoopの特徴をまとめ ます(MySQL(RDBMS)と比較)。
長所
- 分散処理できる(スケールアウト)
対象データ量が増えたら、サーバ(ノード)数を増やすことで解決できます。
処理速度もスケールします。
- データ量に関係なく一貫した処理ができる
大量データ処理を前提に設計されているため、
大規模データの処理でもMySQLのような特別対応が必要いです。
どんな大量データでも同じモジュールで処理できます。
分散処理で生じるノードの不具合を自動でリカバリしてくれる仕組みもあります。
- キーに対するsort済み処理ができる。
大量データを分散処理するための基本機能であるMapReduceを
直接操作すると、RDBMSでは難しいキー毎の粒度が細かい処理を実現できます。
具体的には、キーをユーザid、時刻としてMR処理すると、
ユーザ毎に時系列に並んだ行動履歴を出力できます。
RDBMSで大量データに対して、このような処理を実行するのは現実的でないです。
短所
- 小規模データ処理は遅い。
起動~処理が動き始めるまで数分かかります。
また、ノード数が多くなるほど起動時間がかかります。
- JobFlow(Hadoop一連の処理システム)が基本的にシングルプロセス
1JobFlowで同時に複数並列処理を実行すると、処理待ち行列に入ります。
優先順位を付けて割り込み処理させることは出来ますが、
割り込みされた方が待たされるので、実質1プロセス処理と同様...
⇒月初などに処理が集中すると渋滞が発生します。
- リアルタイム処理に向かない。
小規模データ処理が遅いに通じますが、
Hadoop処理を車で例えるなら大型トラックです。
一度に大量の荷物を遠くまで運べる(大量データを分散処理する)が、
近所に買い物に行く(小規模データを集計する)のに大型トラックは不便です。
- MapReduceフレームワークに沿ったプログラムを書く必要がある。
SQLのように誰もが気軽に使える構文でデータを取り出せるわけではありません。
⇒HiveというSQLライクにデータ抽出できる仕組みはあります。
(われわれも部分的に使ってますが)、MRの利点も消してしまいます...分散処理に適したプログラムを書く必要がある。敷居が高いわけではないですが、
慣れは必要だと思われます。
- debugが難しい
開発PCで大量データを用意し、複数ノードでの分散処理のチェックまで
するのは難しいです。開発の最終確認は本番データを使って整合性チェック
するというプロセスになります。MRの要はキーに対する処理なので、複数ノードで実行したら結果がおかしくなる
というbugもしばしば起きます。また、少々のエラーは突き抜けてしまうので、
ポイント毎に整合性チェックロジックを入れと安心です。
⇒ここら辺の細かいところは後程の開発連載にて...
Hadoopを導入し、大規模データ処理はHadoopにと、
長所を生かした処理をさせて大規模データ処理地獄から抜けだせました。
しかし、短所で示した通り、決してMySQL(RDBMS)と置き換わるツールではないです。
あくまで大規模データを処理するツールとして使っています。
しかし、オンプレ(自社サーバ)Hadoop運用にも間もなく限界が来ることになります...
なぜEMRを使い始めたか
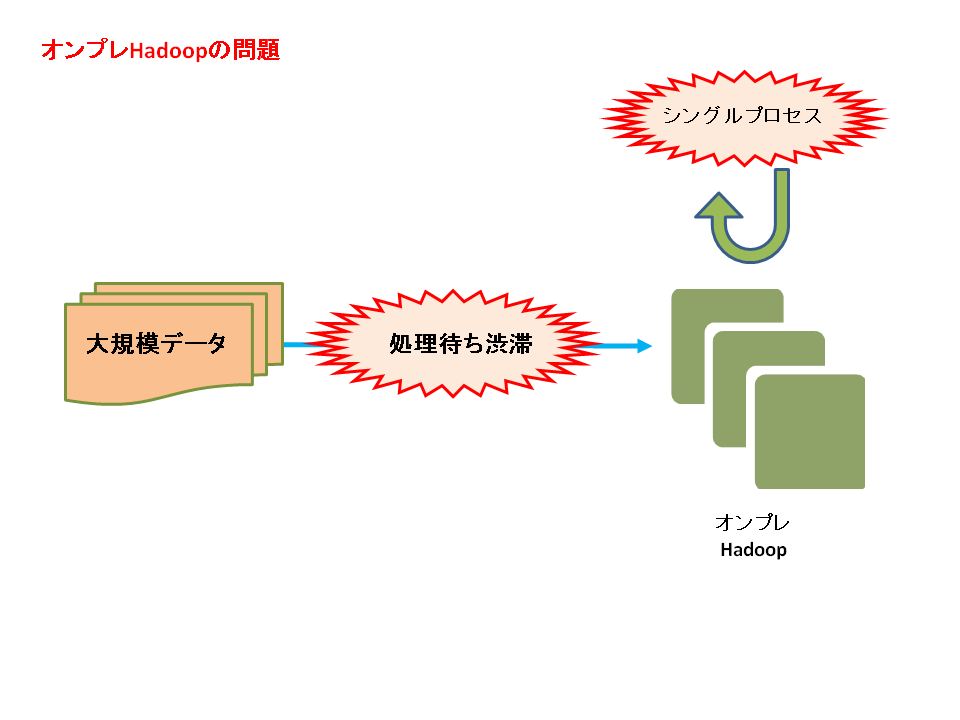
(図2 オンプレHadoopの問題)
大規模データ処理のために先ず、オンプレ(自社サーバ)Hadoopを導入しました。
当初は期待通りのパフォーマンスを発揮していました...
ですが、大規模データ処理が解禁されて様々なバッチ処理が動いてくると、
リソース問題が出てきました。
Hadoop短所でも上げましたが、JobFlow(Hadoop一連の処理システム)は
基本的にシングルプロセスです。同時複数処理ではないため、
日次や月次でバッチ処理が集中してしまうと「処理待ち渋滞」が起きます。
最悪期には月次バッチ処理が完了するまでに半月かかったこともありました(土日も稼働で)...
こうなると、詰まるんだったらピークに合わせてインフラ拡張すればいいだろう
という話になりますが、そこに合わせるとインフラコストが激増してしまいます。
日次や月次という10%程度の処理時間のために90%の時間を待機してるような、
もったいないHadoop専用サーバ(処理時にリソースを使いきるため、他処理との
共存が難しいを、場合によってはラック単位)を常時稼働させておかなければなりません。
ベンチャーにとっては致命的なコストです。
そんな時、 渡りに船 で登場したのが EMR でした。
EMRに移行して幸せになりました~
現在、最悪期の数倍に上るデータを処理していますが、月次処理に
かかる時間は2営業日程です。
コストも20万円/月程度。
EMRがなかったらどうなっていたことやら...
EMRの特徴
※オンプレ(自社サーバ運用)との比較
長所
- 必要な時に必要なだけ使える。
自由です。
JobFlowを同時並列に何本でも走らせることができ、処理待ち渋滞とは無縁になます。
JobFlow毎の処理時間のコントロールも容易にできます。
足りないとなったら実行中でもノード増やして増強できます。
- インフラリソース管理の必要がない。
やはり何といっても楽です。ハードディスク故障の度に
iDCへ行かなければならない苦行から解放されます。
OSやミドルも適時アップデートされるのでソフトウェア開発に集中出来ます。
- 他AWSサービスとの接続が容易。
便利です。必須なのはinput、outputデータ置き場のS3との接続。
使い方はマニュアルに従って、パスを指定するくらいの手軽さ。
他にもRDS、DynamoDBへの接続、RedShiftのinputへの出力も対応するようです。
短所
- 処理量に応じた利用料がかかる。
クラウドサービスを利用するので当たり前ですが、
オンプレと違って使った量の費用になるので最初はちゃんと計算しないといけません。
⇒実際使ってみると心配するほど高額にはならいです。
- オンプレと接続(DirectConnect)の必要がある。
マスタデータがオンプレにあるサービスでは
DirectConnectのような方法でオンプレとAWSを接続する必要があります。
まとめると、、、
EMR良いです!
突然落ちたり、突然の仕様変更で動かなくなったりと、癖はありしますがw
致命的なものではありません(バッチ処理なので)。
オンプレHadoopを使っていてバッチ処理(日次や月次)の処理渋滞問題で
お悩みの方は確実に改善できると思います。
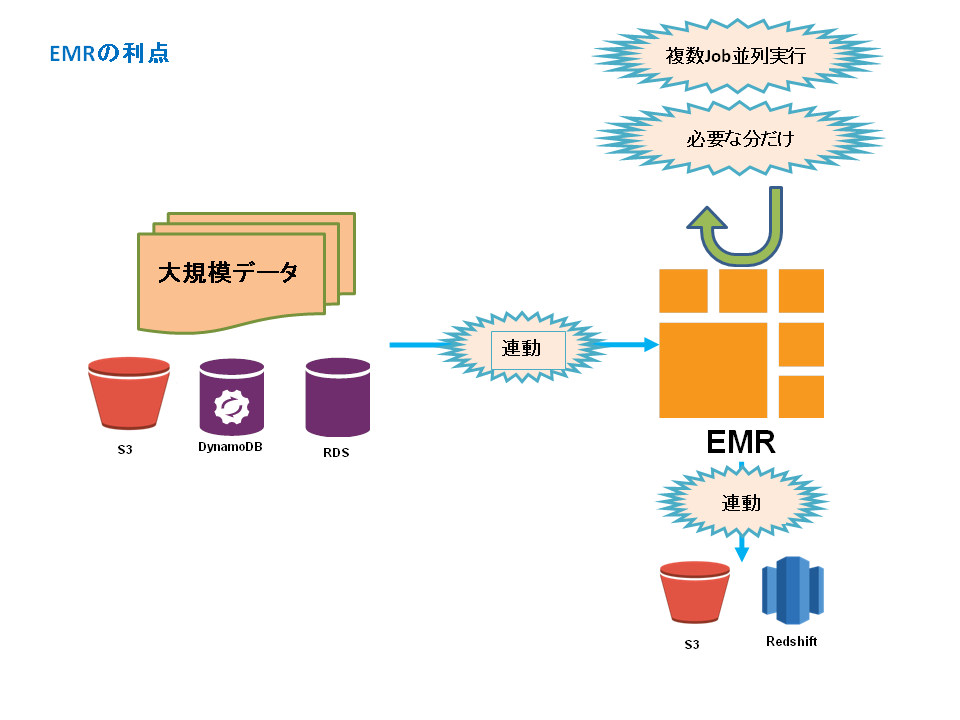
(図3 EMRの利点)
最後に
今回はEMR連載初回ということで、
大量データ処理でHadoop導入に至ったいきさつ~EMRを使い始めた理由
までを紹介しました。
次回以降では、具体的にEMR開発~運用までの勘所を紹介できればと考えております。
EMR運用実績はソコソコのありますので、質問等のフィードバック頂けると
お答えできるかと思います(できる限り...)
次回以降もよろしくお願いいたします!!
参照
- 「Hadoopで、かんたん分散処理」
- 「Amazon Elastic MapReduceの使い方─Hadoopより手軽にはじめる大規模計算」
- 「Amazon Elastic MapReduce」
大規模データについてのリンク
「大規模データについていろいろやってみます!(第1回)」
「大規模データについて第2回~EMR(Hadoop)について、なぜEMRなのか〜」
「大規模データについて第3回~EMR開発_基礎編〜」
「大規模データについて第4回~EMR開発_実践編〜」
「大規模データについて第5回~EMR開発_運用編〜」
「大規模データについて第6回~Redshift編〜」