今回から開発編ということで、いままで開発で得た
EMR開発の実践的なところを紹介していきます!
開発編を1回で記事にしてしまうとボリュームが多すぎてしまうので、
基礎編、実装編 と分けることにしました。
早速ですが、 投稿スケジュールを以下に変更させていただきます;;
・11月上旬 ~EMR開発_基礎編~
・11月下旬 ~EMR開発_実装編~
・12月上旬 ~EMR開発_運用編~
・12月下旬 〜Redshiftについて
今回は、基礎編と題しましてEMR開発における
土台 の部分について書きたいと思います。
はじめに
先ずは、EMRを動かすために必要なものを一通り
・AWSアカウント
・アカウントに紐づくアクセスキー/シークレットキー
・処理対象のデータ
・Hadoopを動かすためのMapReduceコード(Hive/Pigの場合は不要)
・CLIツール(Webコンソールでも代用可能)
以上です、簡単に始められますw
もっと詳しく知りたい方は、以下にAWSの説明ページがありますので参照ください。
http://docs.aws.amazon.com/ja_jp/ElasticMapReduce/latest/DeveloperGuide/emr-what-is-emr.html
本連載では実践的なトピックに焦点を絞るため、
一般的な説明は省略させていただきます。
データフロー
早速、EMR運用の現状を紹介いたします。
先ずは、大規模データ処理の詳細図(データフロー)を参照ください。
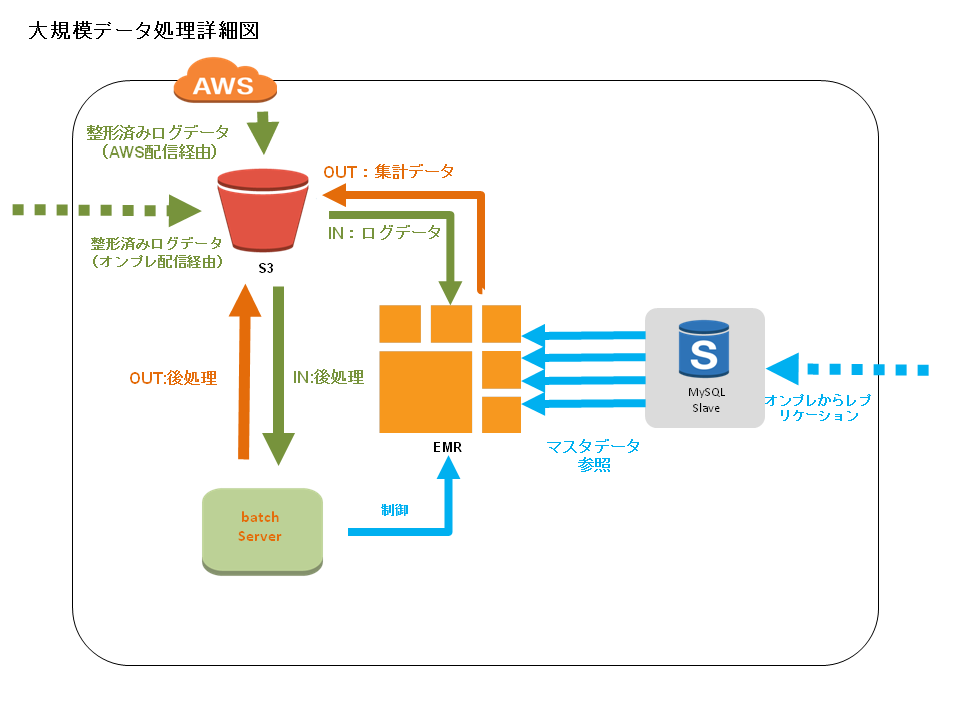
処理の流れ
0.前処理(EMRをスムーズに実行させるため、直前or日次でインプットファイルを整形する)
1.バッチサーバから引数を指定してEMR起動する
2.EMR処理(リソース足りない場合は増強する)
3.後処理(EMRアウトプットを出力要件に整形する)
処理詳細
EMR処理環境について
- バッチサーバ(EC2)
- Linux(CentOS)
- CLI(シェルスクリプトからのEMR制御)
オンプレ同様のごく一般的なLinuxサーバです。
EMRが特定リージョンのVPC上で動くので、そこからアクセスできる設定にする必要があります。
EMRの起動オプションについて
- subnet
VPC配下のsubnetIDを指定。
- region
ap-northeast-1 (東京リージョン)
- num-instances
基本2を指定してマスタ、スレーブ1台づつ起動。
足りない場合は後で、 spotインスタンス を追加します。
-
slave-instance-type
Hadoopスレーブインスタンスのタイプを設定します。
メインでMR処理を実行するサーバなので強めのインスタンスタイプを設定します。
ここでのパフォーマンスは、 「弱いインスタンス多数」<「強いインスタンス少数」
となるのでならべく強めのインスタンスを設定したほうが良いです。 -
master-instance-type
Hadoopマスタインスタンスのタイプを設定します。
それほどリソースを必要としません。 m1.medium で十分です。
- hadoop-version
Hadoopは日々進化しているので出来るだけ 最新版 を使いましょう。
...もちろん事前に動作確認を!
- bootstrap-action
マスタ、スレーブサーバの負荷状態を見るために ganglia が有用です。
bootstrap-actionに以下を指定するだけで利用できます。
新しくローンチした処理の効率はこれで見るようにしています。
s3://elasticmapreduce/bootstrap-actions/install-ganglia
EMRのclusterタイプについて
- カスタムJar
選択肢として、Hive、ストリーム、HBase…等が用意されてますが、
MapReduceの自由度から、我々がEMRで動かしているモジュールは
全て カスタムJar になっています。
オンプレHadoopの一部では開発の容易さをとってHiveを使っています。
一般的には、以前AWSのセミナーで聞いたところでは、
__EMR利用の70%__程度はHiveという話でした。
実行制御ツールについて
-
WebConsole
AWS管理画面から遷移するwebページです。
基本的に重く、使い勝手はそれほどよくないです。(悪口では無いです。)
先日の改修で良くなったようですが...
JobFlowのチェック(一覧で見る)には便利です。 -
CLI
Linuxサーバ(バッチ)からEMRの制御に使います。詳細はコチラから
EMRマニュアルではRuby版のインストール手順がありますが、上記のPython版の方が軽いです。
設計について
設計について、ポイント毎にまとめます。
大量データを処理する
- データは圧縮する!
s3費用、処理速度(EMR)にも影響が出ます。
必ず圧縮しましょう!!
- inputデータはあらかじめ データを切り分けておく
読み込みデータ量削減のために集計単位のkeyごとにログをあらかじめ
分割しておくとコストを圧縮出来ます。
不必要なデータを取り込んだまま処理してしまうと無駄なmapタスクが起動してしまいます。
- 小容量のinputファイルは、 S3distCp でまとめる。
inputファイル1つに対して、最低でも1つ以上のMapタスクが立ち上がるので、
inputが小容量ファイル多数となる処理は避けるべきです。
S3DistCp についてはこちら。
- EMR参照専用DBを作る。
DB接続が必要な処理では、 __EMR参照専用DB__を用意した方がよいです。
分散処理なのでEMRから同時多発的に参照が発生します。
安定的なシステム運用のために
-
オペレーションコストを低く抑える
大量データを扱うからこそ平常時はもちろん、リカバリ時も手間がかからないようにすることが大切です。
不具合が起きたときのリカバリも必要最低限のオペレーションで出来るようにしておくのが理想です。 -
前処理、後処理について
必要ですが、EMRで処理できない(難しい)もののみ処理するべきです。
分散処理ではないので、ここを作り込んでも本末転倒です。
inputデータの分割、統合、outputデータのexcel化、outputデータ文字コード変換...
開発時に参照する情報
-
Hadoopについて
当たり前ですが、Hadoop情報の総本山です。 -
まとめ系
-
AWSマニュアル
基本的に英語版を見ることを推奨します。
日本語版は、仕組みを把握する等の基本的で不変な情報は問題ないですが、
新しいツールやbugfix情報は古いので注意が必要です。
大規模データについてのリンク
「大規模データについていろいろやってみます!(第1回)」
「大規模データについて第2回~EMR(Hadoop)について、なぜEMRなのか〜」
「大規模データについて第3回~EMR開発_基礎編〜」
「大規模データについて第4回~EMR開発_実践編〜」
「大規模データについて第5回~EMR開発_運用編〜」
「大規模データについて第6回~Redshift編〜」