IE を除く現代の多くのブラウザでは TextEncoder と TextDecoder の API が使えて、UTF-8 や Shift_JIS の格納された Uint8Array と、string の相互変換が可能です。
(エンコード)文字列を Uint8Array の任意オフセット位置に UTF-8 で書き込む
(デコード)Uint8Array の任意オフセット位置に書かれた UTF-8 文字列を読み込む(バイト数は既知)
という条件で文字列の入出力処理について、下記の3実装の速度を比較してみます。
(1)Node.js の Buffer の当該機能を使った場合
(2)Pure JS で適宜実装した場合
(3)TextEncoder/TextDecoder API を利用した場合
今回は「Uint8Array の入出力かつ任意オフセット」という条件がキモです。
この条件だけ検証している理由は、なぜなら私がそういう実装が欲しいからです。
なお2の Pure JS 実装は fastestsmallesttextencoderdecoder モジュールとか、
たくさん種類があるんだけど、手元のコードなので、最速ではないかも。
検証環境は Node v14.17.0 arm64 M1 Macbook Pro です。
[グラフ補足]
- SB は半角
Aが続く、シングルバイト文字の文字列です。 - MB は全角
Aが続く、マルチバイト文字の文字絵です。 - グラフの横軸は文字数。縦軸は ops/sec です。上ほど速い。
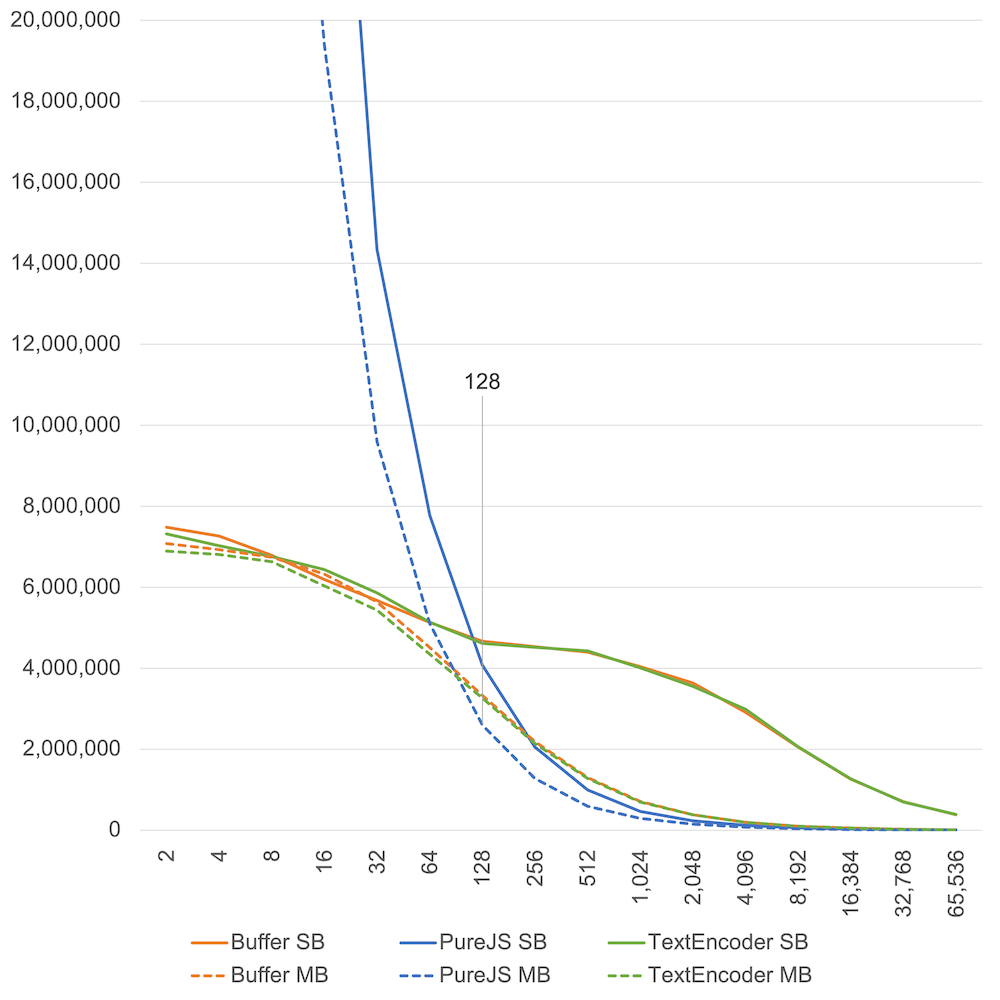
エンコード(UTF-8書き込み)
書き込み速度の結果はシンプルです。
- 100文字くらいまでの短い文字列なら、オブジェクト生成が少ない Pure JS 実装が圧倒的に速い。
- それを超えるような長い文字列なら、ネイティブな TextEncoder・Buffer が速い。
- TextEncoder#encode と Buffer#write に優位な差がない。
- シングルバイト文字・マルチバイト文字でも、傾向は大差ない。
ベンチマークのソースコードは text-encoder-bench-js に置きました。
Buffer 版はこんな実装。入力が Uint8Array なので、いったん ArrayBuffer 経由で Buffer オブジェクトを作り直してから write で書き込む手順。
const encode = (data, offset, string) => {
const {buffer, byteOffset, byteLength} = data;
return Buffer.from(buffer, byteOffset, byteLength).write(string, offset);
};
TextEncoder 版はこんな実装。encodeInto を使うために subarray でオフセット位置の Uint8Array オブジェクトを切り出すオーバーヘッドがあるもの。
const encoder = new TextEncoder();
const encode = (data, offset, string) => encoder.encodeInto(string, data.subarray(offset));
Buffer はバージョンによって中の実装が変わるから、内部は一緒だったりするのかも。
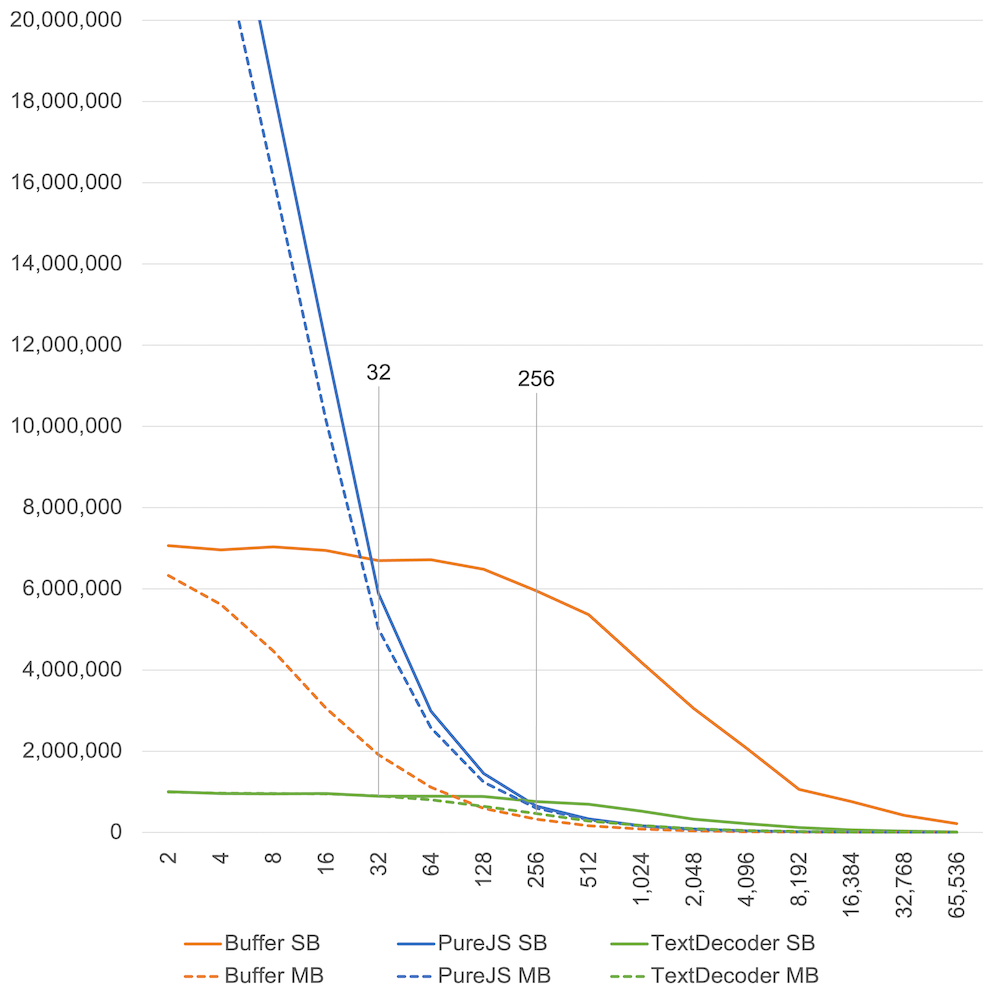
デコード(UTF-8読み込み)
読み込み速度も似たような話だが、なぜか Buffer が速い。
- 32文字くらいまでの短いシングルバイト文字の文字列なら、Pure JS が圧倒的に速い。
- それを超える長いシングルバイト文字の文字列なら、Buffer が数倍速い。
- 256文字くらいまでの短いマルチバイト文字の文字列なら、Pure JS が速い。
- それを超える長いマルチバイト文字の文字列なら、そこまで大きな差がない。
ベンチマークのソースコードは text-decoder-bench-js に置きました。
Buffer 版はこんな実装。入力が Uint8Array なので、いったん ArrayBuffer 経由で Buffer オブジェクトを作り直してから toString で取り出す手順。
const decode = (data, offset) => {
const {buffer, byteOffset, byteLength} = data;
return Buffer.from(buffer, byteOffset + offset, byteLength - offset).toString();
};
TextEncoder 版はこんな実装。subarray でオフセット位置の Uint8Array オブジェクトを切り出すオーバーヘッドがあるもの。
const decoder = new TextDecoder();
const decode = (data, offset) => decoder.decode(data.subarray(offset));
Pure JS が配列を作って String.fromCharCode.apply を使う実装なので、
単純な文字列結合を使った場合は、結果が違うかもしれない。
TextDecoder よりも Buffer が速い理由を予想してみると、
Buffer は TextDecoder とは別の独自実装を持っていて、
内部文字列表現が OneByteString だけで済むときは特別に高速になってるのかな。
ただし、マルチバイト文字が入り TwoByteString に切り替わるとバイト数のぶん遅くなる。
(グラフの右軸は文字数なので、全角 A は UTF-8 で3倍のバイト数になる)
シングルバイト文字100文字くらいまで Buffer の速度がサチってるので、
たぶんオブジェクト生成のオーバーヘッドで頭打ちになるラインがこの辺なのか。
デコード処理の実装時の戦略としては、
エンコード時と同じように100バイトくらいを閾値にして、
Pure JS 実装 or Buffer/TextEncoder 実装を切り替えてもいいかも。
より細かく分類すると、Buffer が使える Node.js 環境では、
シングルバイト文字前提なら入力長 32 バイトくらい、
マルチバイト文字前提なら入力長 256 バイトくらいが、
Pure JS 実装 or Buffer 実装を切り替える閾値になるか。
Buffer が使えないブラウザ環境なら、入力長 256 バイトくらいが
Pure JS 実装 or TextDecode 実装を切り替える閾値になるか。
検証結果まとめ
- 短い文字列なら、オブジェクト生成オーバーヘッドの少ない Pure JS 実装が最速。
- 長い文字列なら、ネイティブの Buffer / TextEncoder / TextDecoder を使うべし。
- どうせバージョンによって挙動が変わるから、一概には言えないが、シンプルに考えると、100文字や100バイトくらいを切り替え閾値にしても良いかも。