はじめに
AzureOpenAI studioにてデプロイ可能なEmbedding(埋め込み)を使用したデータ検索について調べてみたのでまとめました。
※RAGについて詳しいことが気になる方はほかの方の記事を読んだほうがいいかもしれません。機械学習未経験の方へ向けた記事となっております。
今回はEmbeddingモデルをデプロイしてベクトル同士を比較するところまで行います。
Embeddingとは
エンベディング(embedding)とは、単語やテキストなどのデータを、AIが扱いやすいように、数値ベクトルデータに変換する技術のことです。これによって、単語やテキストなどのデータ同士が意味的に近いかどうか、AIが判別できるようになります。
「引用元」
数値に変換してあげることで自然言語の意味もデータとして扱えるようになります。
ベクトルとは
数学におけるベクトルは空間上における力や速度を矢印の向きと長さを用いて表現しています。
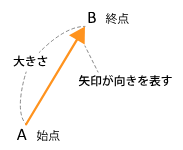
【参照】ベクトルとは何か?
機械学習の分野においてはデータの特徴をとらえて、処理するための基本的な要素として使用されています。
ベクトル化を活用したデータ比較
今回ベクトル化したデータの比較にはコサイン類似度という尺度を使います。
コサイン類似度とは
コサイン類似度とは
AとBのベクトルがどれだけ類似しているかを表した値で
ベクトルの向きと大きさがどれだけ近しいかを0~1で表現します。
下の画像では口コミ1と2は入力文書に比べ近しい関係にあるといえます。
矢印の長さの差とAとBを比較した際の内角の大きさが小さければ小さいほど類似しています。

【参照】【python】コサイン類似度は高校数学の知識で理解できます!|自然言語処理
Embeddingを使ってみよう
使用言語
今回はPythonを使用してコーディングを行っていきます。
モデルのデプロイ
今回はEastUSリージョンにてtext-embedding-ada-002をデプロイしそちらを使用しました。
モデルのデプロイ方法は以下の記事を参考にしてください。
使用するライブラリ
使用するライブラリは以下の通りです。
・openai
・numpy
・pandas
・csv
今回は入力値Aと入力値Bのベクトルをコサイン類似度にて比較し出力するプログラムを記述していきます!
from openai import AzureOpenAI
import pandas as pd
import numpy as np
import csv
client = AzureOpenAI(
api_key="YOUR API KEY", #APIキーを入力
api_version="2023-12-01-preview",
azure_endpoint="YOUR END POINT" #エンドポイントを入力
)
def main():
text_A = translateVector(input("Aを入力してください。"))
text_B = translateVector(input("Bを入力してください。"))
similarity = cos_sim(text_A,text_B) #コサイン類似度を取得
print("AとBのコサイン類似度は" + str(similarity) + "です")
def translateVector(input):
inputs = input
resp = client.embeddings.create(
input=inputs,
model="YOUR MODEL NAME" #作成したモデル名を入力してください。
)
resp = resp #展開代入
return resp.data[0].embedding #ベクトル化した値を返す
def cos_sim(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2)) #コサイン類似度計算
main()
検証
完成したコードを動かしてみると....
AとBが完全に一致している場合は最大値の1が出力されました!

次は全く違う者同士を比較してみましょう。

全く違う場合は80%を切ってくるということがわかります。
次は少し違う者同士を比較してみましょう。
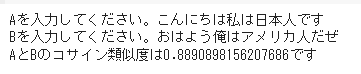
国籍の部分が違う場合は90%を切ってきました。
しかし文章の構成がほぼ同じのため90%弱と高い結果がでました。
挨拶+一人称+国籍+助動詞
両方とも日本人の場合はどうなるでしょうか

90%を超えてきましたね。
使っている言葉は違っていても意味がほぼ同じということがうまく判断できています。
このような類似度とそのほかのアルゴリズムを用いることで最適なドキュメントを選びだす検索機能が作れるわけです!
まとめ
今回text-embedding-ada-002を使用しましたが、全く異なるテキストを渡しても70%超えと平均して高い類似率を示すことがわかりました。
その点を踏まえると用途に応じてそのほかのモデル(text-embedding-3)を選ぶなど柔軟な対応が必要ですね...
この分野についてはまだまだ知識が浅いため、積極的に学習する時間を設けていこうと思います。
part2ではたくさんあるデータの中から最適なデータを見つけ出すコードを紹介します!