一定時間ごとにある程度の大きさのテキストファイルを読み込んで、その内容を反映させるプロジェクトのため、Unity(C#)で使える高速なファイルアクセスAPIを調べて AsyncReadManager に行きつきました。
偉大なる先駆者様 :
【Unity】ファイルを非同期で読み込んでアンマネージドメモリに展開できるAsyncReadManagerを試してみた
この先行研究ではメインスレッド上での動作確認とメモリ負荷の検証が主で、本文でさらっと
アンマネージドメモリにデータをキャッシュすると言いつつも、実装としてはJob等で並列化せずに愚直にメインスレッド上でパースを行っております。。(もう少し工夫すればJob化出来そうな気がしなくもなく。。要検証)
との表記に誘われて四苦八苦した結果、どうにか動くようになりましたので紹介させていただきます。
Unityプロジェクトなのに外部ファイル(しかもテキスト)をたくさん使うとか、非常にニッチな需要だとは思いますがそんな誰かの役にも立てばいいな……
Unityアドカレに1個未投稿の枠があったので、今更ながら滑り込ませていただきました。
成果物
C# JobSystem で文字列の類をいい感じに扱うツールセットは最終的に以下のようになりました。
最新版は Burst による最適化に対応しました。Burstの利用方法と性能評価についてはBurst編を参照してください。
GitHub
NativeStringCollections
動作環境
-
Unity 2019.4.24
- Collections 0.9.0-preview.6
-
Unity 2020.3.25
- Collections 0.17.0 or 1.1
使い方
雰囲気はこんな感じ。
using NativeStringCollections
public class TextData : ITextFileParser
{
NativeList<DataElement> Data;
public void Init()
{
/* クラス初期化。 new() 後に一度だけ呼ばれる */
/* ここだけはメインスレッドで実行されるのでマネージ型を使ってもいい */
}
public void Clear()
{
/* パース準備。 ParseLines(lines) が始まる前に一度呼ばれる */
}
public bool ParseLines(NativeStringList lines)
{
for(int i=0; i<lines.Length; i++)
{
var line = lines[i];
/* line を解析する。 次の行も読みたいなら true を返す */
}
}
public void PostProc()
{
/* 後処理。 ParseLines(lines) が終わったら一度呼ばれる */
}
public void UnLoad()
{
/* 一時的にデータを破棄したいときにここに処理を書く */
}
}
public class Hoge : MonoBehaviour
{
AsyncTextFileReader<TextData> reader;
void Start() { reader = new AsyncTextFileReader<TextData>(Allocator.Persistent); }
void OnClickLoadFile()
{
// どこかでファイル読み込みの指示を出す (必要なら Encoding も指定する)
reader.Encoding = Encoding.UTF8;
reader.LoadFile(path);
}
void Update()
{
// 進捗を表示できる (Read, Length ともに BlockSize単位のint)
var info = reader.GetState
float progress = (float)info.Read / info.Length;
// 終わってたら Complete()
if(reader.JobState == ReadJobState.WaitForCallingComplete)
{
reader.Complete();
// 読み込みにかかった時間も出せる [ms]
double delay = reader.GetState.Delay;
Debug.Log($" file loading completed. time = {delay.ToString("F2")} [ms].");
// データを取り出して何かする
var data = reader.Data;
}
}
void OnDestroy()
{
// データのDispose() は外で行う。 reader だけ先に Dispose() してもよい
var data = reader.Data;
reader.Dispose();
data.Dispose();
}
}
文字列の具体的な変換はこんな感じ
using NativeStringCollections;
public class TextData : ITextFileParser
{
public NativeList<DataElement> Data;
private NativeStringList mark_list;
private StringEntity check_mark;
// パース中に string を使いたい場合は
// Init() 内で NativeStringList や NativeList<char> に格納しておく
public void Init()
{
Data = new NativeList<DataElement>(Allocator.Persistent);
mark_list = new NativeStringList(Allocator.Persistent);
mark_list.Add("STRONG");
mark_list.Add("Normal")
// NativeStringList から StringEntity を取り出すのは値を全て格納してから
// あるいは全ての文字列を格納しきれるようあらかじめ大きな Capacity を設定しておく
// (StringEntity を取り出した後にバッファが再確保されると不正メモリ参照でクラッシュ)
check_mark = mark_list[0];
}
// 改行コードはあらかじめ解析されて NativeStringList に格納される
// List<string> のような感覚で使う
public bool ParseLines(NativeStringList lines)
{
bool continueRead = true;
for(int i=0; i<lines.Length; i++)
{
var line = lines[i];
continueRead = this.ParseLineImpl(line);
}
return true;
}
private bool ParseLineImpl(ReadOnlyStringEntity line)
{
// StringEntity.Split() の結果を受け取るリスト
var str_list = new NativeList<ReadOnlyStringEntity>(Allocator.Temp);
// カンマ区切りで "CharaName_STRONG,11,64,15.7,1.295e+3" みたいなデータだったなら
line.split(',', str_list);
// こんな風に
var name = str_list[0];
bool success = true;
success = success && str_list[1].TryParse(out long ID);
success = success && str_list[2].TryParse(out int HP);
success = success && str_list[3].TryParse(out float Attack);
success = success && str_list[4].TryParse(out double Speed);
// こんなことも
int mark_index = name.IndexOf(check_mark); // "STRONG" を検索
if(mark_index >= 0)
{
/* このキャラ特有の何か */
}
str_list.Dispose()
// 正しいフォーマットとして解析できたか
if(!success)
return false; // 解釈できなかったのでパース中止
Data.Add(new DataElement(ID, HP, Attack, Speed));
return true; // 解釈できたので次の行に進む
}
}
このような具合に。
実際には JobSystem の中で処理されますが、ユーザーが書く部分は通常のC#にだいぶ近い感じに設計できたと思います。
また、上記 class TextData は各プロジェクトにおいて適宜差し替えて使用することが前提ですが、常に JobSystem で実行されるとデバッグが面倒です。なのでメインスレッドでの実行を強制する下記のAPIもあります。
var reader = new AsyncTextFileReader<NewProjectData>(Allocator.Persistent);
reader.Encoding = Encoding.UTF8;
reader.Path = path;
// この場合 ParseLine(line) 内で Debug.Log() が使える。
// また、 var sb = new StringBuilder() や (obj).ToString() をしてもよい。
reader.LoadFileInMainThread();
if(reader.JobState == ReadJobState.WaitForCallingComplete) reader.Complete();
// データを取り出してデバッグする
var data = reader.Data;
reader.Dispose();
ちなみに、先駆者様の例と同等のサイズの 50万キャラクターのファイルについて、当方の環境では
| 処理内容 | 経過時間 |
|---|---|
| File.ReadAllLines()から解析 | 710~850ms |
| CharaDataParser.ParseLines(lines)で解析 | 450~460ms |
| CharaDataParser.ParseLines(lines)をBurst | 150~170ms |
となっており、 C# string と高速化の相性の悪さが如実に表れています。
これで File.ReadAllLines() を使わずに済むようになるでしょう。
中身のお話 (あるいは四苦八苦の記録)
▽AsyncReadManagerをNativeContainer風にラップしておく
AsyncReadManager.Read() はファイルデータのバッファ先や読み込みに関する制御情報(ReadCommandやReadHandle)の管理が必要で、APIをそのまま使うのは面倒なのでこれらをまとめて管理するAsyncByteReaderとしてラップします。
`AsyncByteReader` の実装(抜粋)
internal struct AsyncByteReaderInfo
{
public int bufferSize;
public int dataSize;
public Boolean allocated;
private Boolean _haveReadHandle;
private ReadHandle _readHandle;
public ReadHandle ReadHandle
{
get { return _readHandle; }
set
{
this.DisposeReadHandle();
_readHandle = value;
_haveReadHandle = true;
}
}
public void DisposeReadHandle()
{
if (_haveReadHandle)
{
_readHandle.Dispose();
_haveReadHandle = false;
}
}
public bool HaveReadHandle { get { return _haveReadHandle; } }
}
// ここで使用している PtrHandle<T> については後述
public unsafe struct AsyncByteReader : IDisposable
{
private NativeList<byte> _byteBuffer;
private PtrHandle<AsyncByteReaderInfo> _info;
private PtrHandle<ReadCommand> _readCmd;
public int BufferSize { get { return _info.Target->bufferSize; } }
public int Length { get { return _info.Target->dataSize; } }
/// <summary>
/// the constructor must be called by main thread only.
/// </summary>
public AsyncByteReader(Allocator alloc)
{
_byteBuffer = new NativeList<byte>(Define.MinByteBufferSize, alloc);
_info = new PtrHandle<AsyncByteReaderInfo>(alloc);
_readCmd = new PtrHandle<ReadCommand>(alloc);
_info.Target->bufferSize = Define.MinByteBufferSize;
_info.Target->dataSize = 0;
_info.Target->allocated = true;
}
public void Dispose()
{
_byteBuffer.Dispose();
_info.Target->DisposeReadHandle();
_info.Dispose();
_readCmd.Dispose();
}
public JobHandle ReadFileAsync(string path)
{
this.CheckPreviousJob();
var fileInfo = new System.IO.FileInfo(path);
if (!fileInfo.Exists) throw new ArgumentException("the file '" + path + "'is not found.");
this.Reallocate(fileInfo.Length);
*_readCmd.Target = new ReadCommand
{
Offset = 0,
Size = fileInfo.Length,
Buffer = _byteBuffer.GetUnsafePtr(),
};
_info.Target->dataSize = (int)fileInfo.Length;
_info.Target->ReadHandle = AsyncReadManager.Read(path, _readCmd.Target, 1);
return _info.Target->ReadHandle.JobHandle;
}
private void CheckPreviousJob()
{
if (_info.Target->HaveReadHandle)
{
if (!_info.Target->ReadHandle.JobHandle.IsCompleted)
{
throw new InvalidOperationException("previous read job is still running. call Complete().");
}
else
{
_info.Target->DisposeReadHandle();
}
}
}
public void Complete()
{
_info.Target->ReadHandle.JobHandle.Complete();
}
public void* GetUnsafePtr() { return _byteBuffer.GetUnsafePtr(); }
public byte this[int index]
{
get { return _byteBuffer[index]; }
}
}
これを用いることで、以下のようにNativeContainerに近い感覚でAsyncReadManager.Read()を使えるようになります。
// reader を作成
var byte_reader = new AsyncByteReader(Allocator.Persistent);
// 読み込み開始
JobHandle job = byte_reader.ReadFileAsync(path);
// 読み込んだバッファにアクセス
job.Complete(); // byte_reader.Complete() でも可
void* ptr = byte_reader.GetUnsafePtr();
int length = byte_reader.Length;
// reader を破棄
byte_reader.Dispose();
▽string 使用禁止! しかし Encoding や Parse() 、 Split() は欲しい……
C# string と JobSystem の相克
C# における文字列解析、というと、よくある例としては Files.ReadAllLines() で string[] を受け取り、イテレータで行ごとに回してそこから望みのフォーマットに split() で切り出した後、数値に変換するなら Parse() メソッドを使用する、というパターンかと思います。
しかしこのデザインの根幹である string は参照型で、たとえ GCHandle などを使用し JobSystem に持ち込んでも string インスタンスの生成は当然できないので String.Split() が使えません。
そこで本実装では Unity 2019.1 より char 型の NativeContainer を作成できるようになった ことを利用して、文字列はまるっと NativeList<char> に保持して、これに string のように扱えるインターフェイスを被せることにしました。
まず文字列全体の管理として、 string (のようなもの)が集合した char についてのジャグ配列 に相当するコンテナにデータ本体を保持し、外側配列のインデックスアクセスで当該部分のスライスを取り出す、という形にします。 List<string> のように使えることを目標とします。
大本の管理 struct は何となくジェネリックにします。
ジェネリックなデータ本体部 `NativeJaggedArray` の実装(抜粋)
public struct NativeJaggedArray<T> : IDisposable, IEnumerable<NativeJaggedArraySlice<T>>
where T : unmanaged, IEquatable<T>
{
internal struct ElemIndex
{
public int Start { get; private set; }
public int Length { get; private set; }
public int End { get { return this.Start + this.Length; } }
public ElemIndex(int st, int len)
{
this.Start = st;
this.Length = len;
}
}
private NativeList<T> _buff;
private NativeList<ElemIndex> _elemIndexList;
#if ENABLE_UNITY_COLLECTIONS_CHECKS
private NativeArray<long> genTrace;
private PtrHandle<long> genSignature;
#endif
public unsafe NativeJaggedArray(Allocator alloc)
{
_buff = new NativeList<T>(alloc);
_elemIndexList = new NativeList<ElemIndex>(alloc);
_alloc = alloc;
#if ENABLE_UNITY_COLLECTIONS_CHECKS
genTrace = new NativeArray<long>(1, alloc);
genSignature = new PtrHandle<long>((long)_buff.GetUnsafePtr(), alloc); // sigunature = address value of ptr for char_arr.
#endif
}
public void Clear()
{
this._buff.Clear();
this._elemIndexList.Clear();
}
public int Length { get { return this._elemIndexList.Length; } }
public int Size { get { return this._buff.Length; } }
public unsafe NativeJaggedArraySlice<T> this[int index]
{
get
{
var elem_index = this._elemIndexList[index];
T* elem_ptr = (T*)this._buff.GetUnsafePtr() + elem_index.Start;
#if ENABLE_UNITY_COLLECTIONS_CHECKS
return new NativeJaggedArraySlice<T>(elem_ptr, elem_index.Length, this.GetGenPtr(), this.GetGen());
#else
return new NativeJaggedArraySlice<T>(elem_ptr, elem_index.Length);
#endif
}
}
public unsafe void Add(T* ptr, int Length)
{
int Start = this._buff.Length;
this._buff.AddRange((void*)ptr, Length);
this._elemIndexList.Add(new ElemIndex(Start, Length));
this.UpdateSignature();
}
/// <summary>
/// specialize for NativeJaggedArraySlice<T>
/// </summary>
/// <param name="slice"></param>
public unsafe void Add(NativeJaggedArraySlice<T> slice)
{
this.Add((T*)slice.GetUnsafePtr(), slice.Length);
}
public void RemoveAt(int index)
{
this.CheckElemIndex(index);
for (int i = index; i < this.Length - 1; i++)
{
this._elemIndexList[i] = this._elemIndexList[i + 1];
}
this._elemIndexList.RemoveAtSwapBack(this.Length - 1);
}
#if ENABLE_UNITY_COLLECTIONS_CHECKS
if (gap > 0) this.NextGen();
#endif
}
[Conditional("ENABLE_UNITY_COLLECTIONS_CHECKS")]
unsafe private void UpdateSignature()
{
#if ENABLE_UNITY_COLLECTIONS_CHECKS
long now_sig = GetGenSigneture();
if (now_sig != this.genSignature)
{
this.NextGen();
this.genSignature.Value = now_sig;
}
#endif
}
#if ENABLE_UNITY_COLLECTIONS_CHECKS
private void NextGen()
{
long now_gen = this.genTrace[0];
this.genTrace[0] = now_gen + 1;
}
private unsafe long GetGenSigneture() { return (long)this._buff.GetUnsafePtr(); }
private long GetGen() { return this.genTrace[0]; }
unsafe private long* GetGenPtr() { return (long*)this.genTrace.GetUnsafePtr(); }
#endif
}
ジェネリックなスライス部分 `NativeJaggedArraySlice` の実装(抜粋)
unsafe public interface IJaggedArraySliceBase<T> where T: unmanaged, IEquatable<T>
{
int Length { get; }
T this[int index] { get; }
bool Equals(NativeJaggedArraySlice<T> slice);
bool Equals(ReadOnlyNativeJaggedArraySlice<T> slice);
bool Equals(T* ptr, int Length);
void* GetUnsafePtr();
}
public interface ISlice<T>
{
T Slice(int begin = -1, int end = -1);
}
[StructLayout(LayoutKind.Sequential)]
public readonly unsafe struct NativeJaggedArraySlice<T> :
IJaggedArraySliceBase<T>,
IEnumerable<T>,
IEquatable<IEnumerable<T>>, IEquatable<T>,
ISlice<NativeJaggedArraySlice<T>>
where T: unmanaged, IEquatable<T>
{
[NativeDisableUnsafePtrRestriction]
internal readonly T* _ptr;
internal readonly int _len;
public int Length { get { return _len; } }
#if ENABLE_UNITY_COLLECTIONS_CHECKS
[NativeDisableUnsafePtrRestriction]
internal readonly long* _gen_ptr;
internal readonly long _gen_entity;
#endif
#if ENABLE_UNITY_COLLECTIONS_CHECKS
public NativeJaggedArraySlice(T* ptr, int Length, long* gen_ptr, long gen_entity)
{
_ptr = ptr;
_len = Length;
_gen_ptr = gen_ptr;
_gen_entity = gen_entity;
}
#else
public NativeJaggedArraySlice(T* ptr, int Length)
{
_ptr = ptr;
_len = Length;
}
#endif
public T this[int index]
{
get
{
this.CheckReallocate();
return *(_ptr + index);
}
set
{
this.CheckReallocate();
this.CheckElemIndex(index);
*(_ptr + index) = value;
}
}
public NativeJaggedArraySlice<T> Slice(int begin = -1, int end = -1)
{
if (begin < 0) begin = 0;
if (end < 0) end = _len;
this.CheckSliceRange(begin, end);
int new_len = end - begin;
#if ENABLE_UNITY_COLLECTIONS_CHECKS
this.CheckReallocate();
return new NativeJaggedArraySlice<T>(_ptr + begin, new_len, _gen_ptr, _gen_entity);
#else
return new NativeJaggedArraySlice<T>(_ptr + begin, new_len);
#endif
}
[Conditional("ENABLE_UNITY_COLLECTIONS_CHECKS")]
private void CheckReallocate()
{
#if ENABLE_UNITY_COLLECTIONS_CHECKS
if(_gen_ptr == null && _gen_entity == -1) return; // ignore case for NativeJaggedArraySliceGeneratorExt
if( *(_gen_ptr) != _gen_entity)
{
throw new InvalidOperationException("this slice is invalid reference.");
}
#endif
}
public void* GetUnsafePtr() { return _ptr; }
}
スライスは本当にポインタと長さしか持ちません (release build 時)。
Unity.Collections で NativeArray<T> から NativeSlice<T> は作れるのに対して NativeList<T> からは作れないのは、 List の伸縮に伴い内部バッファの再確保が行われた場合、メモリ上の位置が変わってそれまでに作ったポインタによる参照が無効になってしまうため、安全なスライスを作れないことが理由の一つとして考えられます。
今回の実装では、文字列の取り扱いとして最初にデータ全体の構築を行い、その後は要素の追加をせずにスライスの切り出しのみを行うことを基本方針としてちょっと危なめな設計にしました。
そうはいってもついやっちゃうこともあり得るので、要素の追加時に内部バッファの _buff.GetUnsafePtr() の値が変化したかどうかを確認し、それにより世代確認を行う関数 CheckReallocate() を実装してあります。
UnityEditor 上であればやらかしを検知できます。
これに文字列に特化したインターフェイスを被せてジャグ配列の NativeStringList とスライスの StringEntity とします。(今更だけど怒られそうな名前を付けてしまった……)
`NativeStringList` の実装(抜粋)
public struct NativeStringList : IDisposable, IEnumerable<StringEntity>
{
private NativeJaggedArray<char> _jarr;
public unsafe NativeStringList(Allocator alloc) { _jarr = new NativeJaggedArray<char>(alloc); }
public void Dispose() { _jarr.Dispose(); }
public unsafe StringEntity this[int index] { get; }
public StringEntity Last { get; }
// string のようなものへの特殊化
public void Add(IEnumerable<char> str)
{
_jarr.Add(str);
}
public unsafe void Add(char* ptr, int Length)
{
_jarr.Add(ptr, Length);
}
public unsafe void Add(StringEntity entity)
{
this.Add((char*)entity.GetUnsafePtr(), entity.Length);
}
public unsafe void Add(ReadOnlyStringEntity entity)
{
this.Add((char*)entity.GetUnsafePtr(), entity.Length);
}
public unsafe void Add(NativeList<char> str)
{
this.Add((char*)str.GetUnsafePtr(), str.Length);
}
public unsafe void Add(NativeArray<char> str)
{
this.Add((char*)str.GetUnsafePtr(), str.Length);
}
}
`StringEntity` の実装(抜粋)
public unsafe readonly struct StringEntity :
IParseExt,
IJaggedArraySliceBase<char>,
ISlice<StringEntity>,
IEquatable<string>, IEquatable<char[]>, IEquatable<IEnumerable<char>>, IEquatable<char>,
IEnumerable<char>
{
/* 中略 */
/* string のようなものへの特殊化 */
public bool Equals(char* ptr, int Length)
{
this.CheckReallocate();
if (_len != Length) return false;
// pointing same target
if (_ptr == ptr) return true;
for (int i = 0; i < _len; i++)
{
if (_ptr[i] != ptr[i]) return false;
}
return true;
}
public bool Equals(StringEntity entity)
{
this.CheckReallocate();
return entity.Equals(_ptr, _len);
}
public bool Equals(ReadOnlyStringEntity entity)
{
this.CheckReallocate();
return entity.Equals(_ptr, _len);
}
public bool Equals(NativeJaggedArraySlice<char> slice)
{
this.CheckReallocate();
return slice.Equals(_ptr, _len);
}
public bool Equals(ReadOnlyNativeJaggedArraySlice<char> slice)
{
this.CheckReallocate();
return slice.Equals(_ptr, _len);
}
public bool Equals(string str)
{
if (this.Length != str.Length) return false;
return this.SequenceEqual<char>(str);
}
public bool Equals(char[] c_arr)
{
if (this.Length != c_arr.Length) return false;
return this.SequenceEqual<char>(c_arr);
}
public bool Equals(char c)
{
return (this.Length == 1 && this[0] == c);
}
public bool Equals(IEnumerable<char> in_itr)
{
this.CheckReallocate();
return this.SequenceEqual<char>(in_itr);
}
public static bool operator ==(StringEntity lhs, StringEntity rhs) { return lhs.Equals(rhs); }
public static bool operator !=(StringEntity lhs, StringEntity rhs) { return !lhs.Equals(rhs); }
public static bool operator ==(StringEntity lhs, ReadOnlyStringEntity rhs) { return lhs.Equals(rhs); }
public static bool operator !=(StringEntity lhs, ReadOnlyStringEntity rhs) { return !lhs.Equals(rhs); }
public static bool operator ==(StringEntity lhs, IEnumerable<char> rhs) { return lhs.Equals(rhs); }
public static bool operator !=(StringEntity lhs, IEnumerable<char> rhs) { return !lhs.Equals(rhs); }
public override bool Equals(object obj)
{
return obj is StringEntity && ((IJaggedArraySliceBase<char>)obj).Equals(_ptr, _len);
}
public ReadOnlyStringEntity GetReadOnly()
{
return new ReadOnlyStringEntity(this);
}
public void* GetUnsafePtr() { return _ptr; }
}
これで string のようなもの同士で比較したり、スライスを切り出したりやりたい放題できるようになりました。
なお、 NativeJaggedArray<T> のほうを使えば任意の struct についてユーザー管理の共通バッファへの参照を JobSystem と GameObject の両方にばらまくことができてしまいます。ポインタ無法地帯へはあと一歩のぎりぎりのラインにいるので、ご利用は計画的に。
Encoder の自力実装は勘弁してほしい
- なので
GCHandleで JobSystem の中に持っていく
Encoder,Decoderをバグなく実装する自信はないですし、さらに日本語の文字コードは Unicode系列 (UTF-8, UTF-16, UTF-32)のほかに Shift-JISやらEUC-JP、 ISO-2022-JPなどどんなデータを読む羽目になるか分かったものではありません。(特に古いシステムの吐いたデータほど。)
幸い C# 標準にDecoder.GetChars(byte*, int, char* ,int)関数が用意されており、GCHandleで持ち込みさえすれば JobSystem で使えます。 - 日本ローカルの Encoding に注意!
上で上げたエンコーディングのうち、Shift-JIS、EUC-JP、ISO-2022-JP の3つは UnityEditor上では普通に使えますがビルドすると必要なDLLが欠けるためプレイヤーがこけます。
上の記事で対応は可能ですが、レガシーの文字エンコードの対応が適当……
(いやゲームエンジンとしては不要なモノなのでまっとうな設計ではあるのですが)
TryParse(), Split(), Strip() は自力実装
文字列解析用データ構造として StringEntity を自作してしまったので、これらのユーティリティも当然自作します。
実装の単純化のため、C#ではParse() メソッドで一緒くたになっていた十進表記と16進数表記の解析を TryParse() と TryParseHex() に分離します。パーサーを作るにあたって、どちらの表記かわからない、なんてことはないでしょうし、そもそもHexフォーマットを使う状況というのは float や double の値を確実に読み書きしたい状況ぐらいでしょう。
Split() , Strip() については、さっそく StringEntity.Slice() の出番です。普通に線形探索して結果を切り出します。
2022/3/2 追記
高速化のため、TryParse() の数値パーサーに csFastFloatを、整数パーサーにPieter Witvoetさんの実装を移植しました。
また、オリジナルの csFastFloat は標準の TryParse() と異なり、数値として解析可能な文字列の後に解析できない文字が来ると解析できる部分だけを数値に解釈し true を返す仕様になっていますが、今回はC#標準側に合わせて parse に失敗するように変更しました。
Burst なしの条件では自力実装とあまり変わらない速度ですが、 Burst による最適化を行うと下記のように大幅に高速化しました。
| 自力実装(比較) | 高速版 | |
|---|---|---|
TryParse() float, double の高速化 |
0 [ms] | -80 [ms] |
TryParse() int, long の高速化 |
0 [ms] | -20 [ms] |
| total | 250 [ms] | 150 [ms] |
(計測条件:キャラクタ数50万、UTF-8、ファイルサイズ約37MB)
Base64 の変換もできると便利
前節で TryParseHex() を用意したものの、データの利用効率が劣悪(4bit -> 8bit と必要分で単純に倍、プリフィックスに 0x をつければ 2B 追加。ASCIIコード換算で float が 4B -> 10B = 250% になる)なので配列や構造体の生バイト列などの大きなものには正直向いていません。
というわけで由緒正しき Base64 のコンバータを用意しましょう。
C# Reference Source の実装を参考に、テーブル変換なので中身は単純です。
Base64コンバータの実装(抜粋)
/// <summary>
/// The Encoder for MIME Base64 (RFC 2045).
/// </summary>
public struct NativeBase64Encoder : IDisposable
{
private Base64EncodeMap _map;
private PtrHandle<Base64Info> _info;
/// <summary>
/// convert bytes into chars in Base64 format.
/// </summary>
/// <param name="buff">output</param>
/// <param name="byte_ptr">source ptr</param>
/// <param name="byte_len">source length</param>
/// <param name="splitData">additional bytes will be input or not. (false: call Terminate() internally.</param>
public unsafe void GetChars(NativeList<char> buff, byte* byte_ptr, int byte_len, bool splitData = false)
{
if (byte_len < 0) throw new ArgumentOutOfRangeException("invalid bytes length.");
uint store = _info.Target->store;
int bytePos = _info.Target->bytePos;
int charcount = 0;
for(uint i=0; i<byte_len; i++)
{
if (_info.Target->insertLF)
{
if (charcount == Base64Const.LineBreakPos)
{
buff.Add('\r');
buff.Add('\n');
charcount = 0;
}
}
store = (store << 8) | byte_ptr[i];
bytePos++;
// encoding 3 bytes -> 4 chars
if(bytePos == 3)
{
buff.Add(_map[(store & 0xfc0000) >> 18]);
buff.Add(_map[(store & 0x03f000) >> 12]);
buff.Add(_map[(store & 0x000fc0) >> 6]);
buff.Add(_map[(store & 0x00003f)]);
charcount += 4;
store = 0;
bytePos = 0;
}
}
_info.Target->store = store;
_info.Target->bytePos = bytePos;
if (!splitData) this.Terminate(buff);
}
/// <summary>
/// apply termination treatment.
/// </summary>
/// <param name="buff">output</param>
public unsafe void Terminate(NativeList<char> buff)
{
uint tmp = _info.Target->store;
switch (_info.Target->bytePos)
{
case 0:
// do nothing
break;
case 1:
// two character padding needed
buff.Add(_map[(tmp & 0xfc) >> 2]);
buff.Add(_map[(tmp & 0x03) << 4]);
buff.Add(_map[64]); // pad
buff.Add(_map[64]); // pad
break;
case 2:
// one character padding needed
buff.Add(_map[(tmp & 0xfc00) >> 10]);
buff.Add(_map[(tmp & 0x03f0) >> 4]);
buff.Add(_map[(tmp & 0x000f) << 2]);
buff.Add(_map[64]); // pad
break;
}
_info.Target->store = 0;
_info.Target->bytePos = 0;
}
public void Dispose()
{
_map.Dispose();
_info.Dispose();
}
}
/// <summary>
/// The Decoder for MIME Base64 (RFC 2045).
/// </summary>
public struct NativeBase64Decoder : IDisposable
{
private Base64DecodeMap _map;
private PtrHandle<Base64Info> _info;
/// <summary>
/// convert Base64 format chars into bytes.
/// </summary>
/// <param name="buff">output</param>
/// <param name="char_ptr">source ptr</param>
/// <param name="char_len">source length</param>
/// <returns>convert successfull or not</returns>
public unsafe bool GetBytes(NativeList<byte> buff, char* char_ptr, int char_len)
{
if (char_len < 0)
{
#if UNITY_EDITOR
throw new ArgumentOutOfRangeException("invalid chars length.");
#else
return false;
#endif
}
uint store = _info.Target->store;
int bytePos = _info.Target->bytePos;
for(int i=0; i<char_len; i++)
{
char c = char_ptr[i];
if (this.IsWhiteSpace(c)) continue;
if(c == '=')
{
switch (bytePos)
{
case 0:
case 1:
#if UNITY_EDITOR
throw new ArgumentException("invalid padding detected.");
#else
return false;
#endif
case 2:
// pick 1 byte from "**==" code
buff.Add((byte)((store & 0x0ff0) >> 4));
bytePos = 0;
break;
case 3:
// pick 2 byte from "***=" code
buff.Add((byte)((store & 0x03fc00) >> 10));
buff.Add((byte)((store & 0x0003fc) >> 2));
bytePos = 0;
break;
}
return true;
}
else
{
uint b = _map[c];
if (b != 255)
{
store = (store << 6) | (b & 0x3f);
bytePos++;
}
}
if(bytePos == 4)
{
buff.Add((byte)((store & 0xff0000) >> 16));
buff.Add((byte)((store & 0x00ff00) >> 8));
buff.Add((byte)((store & 0x0000ff)));
store = 0;
bytePos = 0;
}
}
_info.Target->store = store;
_info.Target->bytePos = bytePos;
return true;
}
private bool IsWhiteSpace(char c)
{
return (c == ' ' || c == '\t' || c == '\n' || c == '\r');
}
}
internal struct Base64EncodeMap : IDisposable
{
private NativeArray<byte> _map;
public Base64EncodeMap(Allocator alloc)
{
_map = new NativeArray<byte>(65, alloc);
int i = 0;
for(byte j=65; j<=90; j++) // 'A' ~ 'Z'
{
_map[i] = j;
i++;
}
for(byte j=97; j<=122; j++) // 'a' ~ 'z'
{
_map[i] = j;
i++;
}
for(byte j=48; j<=57; j++) // '0' ~ '9'
{
_map[i] = j;
i++;
}
_map[i] = 43; i++; // '+'
_map[i] = 47; i++; // '/'
_map[i] = 61; // '='
}
public char this[uint index]
{
get
{
if (index > 65) throw new ArgumentOutOfRangeException("input byte must be in range [0x00, 0x40].");
return (char)_map[(int)index];
}
}
}
internal struct Base64DecodeMap : IDisposable
{
private NativeArray<byte> _map;
public Base64DecodeMap(Allocator alloc)
{
_map = new NativeArray<byte>(80, alloc);
int i = 0;
_map[i] = 62; i++; // 0x2b, '+'
for(int j=0; j<3; j++)
{
_map[i] = 255; i++; // invalid code
}
_map[i] = 63; i++; // 0x2f, '/'
for(byte j=52; j<=61; j++)
{
_map[i] = j; i++; // '0' ~ '9'
}
for(byte j=0; j<7; j++)
{
_map[i] = 255; i++; // invalid code
}
for(byte j=0; j<=25; j++)
{
_map[i] = j; i++; // 'A' ~ 'Z'
}
for(byte j=0; j<6; j++)
{
_map[i] = 255; i++; // invalid code
}
for (byte j = 26; j <= 51; j++)
{
_map[i] = j; i++; // 'a' ~ 'z'
}
}
public byte this[uint index]
{
get
{
if (index < 0x2b) return 255;
if (index > 0x7a) return 255;
return _map[(int)(index - 0x2b)];
}
}
}
元のリファレンスでは全ビットパターン分(16*16=256)テーブルが作ってありましたが、有効な値は64種類、いくつか途中にある無効な値を考慮しても端から端まで長さ80あれば足りるので、今回の実装ではせっかくなので小さくしてみました。
▽どうせならユーザー定義データも class にしてしまえばいい
Encoding を持ち込むと決めた段階で、byte列 -> char列の変換処理に Burst を使えないことが確定しました。
ジョブ丸ごとの struct 化とかもう気にしなくていいので、ユーザー定義のデータコンテナも class ということにして、これも GCHandle でJobSystemへ持って行きます。
ただしこの設計により、誤って struct のデータコンテナを渡したところ当然ながら GCHandle の取得でコケたので、最終的に class のみを受け取る形にしました。
▽ポインタがすべてを解決する
高速化
実は実装初期のパース速度は Chara 50万体のデータに ~ 1300 ms 程度とだいぶ遅かったのですが、プロファイラを確認したところ主要な処理負荷がインデクサ this[index] や Length フィールドから値を取り出すところだったので、ライブラリ内の処理実装部分では最初に void* と Length を取り出してポインタで直接処理するようにしました。その高速化の経過は下記の通り。
| 処置した関数 | 速度 |
|---|---|
| StringSplitter.Split() | ~1000 ms |
| 上記に加え、 TextDecoder.ParseLineImpl() | 700 ~ 800 ms |
| 上記に加え、 StringParserExt.TryParse() | 600 ~ 700 ms |
| そのほかBoxingの除去など | 500 ~ 550 ms |
見やすいプロファイラは素晴らしい。
共有変数の管理
また、欲しい関数の追加や処理のバッファとして内部的に使う、などにより NativeContiner に似たものを多数作成しましたが、状態管理用の変数ごとにポインタを作るのは手間がかかる上に事故の危険もコピーコストも増大する挙句、データがメモリ上に分散して性能に悪影響を及ぼします。
よって、ジェネリックなポインタ管理ヘルパー PtrHandle<T> を作りましょう。
ポインタ管理ヘルパー `PtrHandle` の実装
public unsafe struct PtrHandle<T> : IDisposable where T : unmanaged
{
[NativeDisableUnsafePtrRestriction]
private T* _ptr;
private readonly Allocator _alloc;
private Boolean _isCreated;
#if ENABLE_UNITY_COLLECTIONS_CHECKS
[NativeSetClassTypeToNullOnSchedule]
private DisposeSentinel _disposeSentinel;
private AtomicSafetyHandle _safety;
#endif
public PtrHandle(Allocator alloc)
{
if (alloc <= Allocator.None)
throw new ArgumentException("Allocator must be Temp, TempJob or Persistent", nameof(alloc));
_alloc = alloc;
_ptr = (T*)UnsafeUtility.Malloc(UnsafeUtility.SizeOf<T>(), UnsafeUtility.AlignOf<T>(), _alloc);
_isCreated = true;
#if ENABLE_UNITY_COLLECTIONS_CHECKS
DisposeSentinel.Create(out _safety, out _disposeSentinel, 0, _alloc);
#endif
}
public PtrHandle(T value, Allocator alloc)
{
if (alloc <= Allocator.None)
throw new ArgumentException("Allocator must be Temp, TempJob or Persistent", nameof(alloc));
_alloc = alloc;
_ptr = (T*)UnsafeUtility.Malloc(UnsafeUtility.SizeOf<T>(), UnsafeUtility.AlignOf<T>(), _alloc);
_isCreated = true;
*_ptr = value;
#if ENABLE_UNITY_COLLECTIONS_CHECKS
DisposeSentinel.Create(out _safety, out _disposeSentinel, 0, _alloc);
#endif
}
public Boolean IsCreated { get { return (_isCreated); } }
public void Dispose()
{
if (IsCreated)
{
#if ENABLE_UNITY_COLLECTIONS_CHECKS
DisposeSentinel.Dispose(ref _safety, ref _disposeSentinel);
#endif
this.CheckAllocator();
UnsafeUtility.Free((void*)_ptr, _alloc);
_ptr = null;
_isCreated = false;
}
else
{
throw new InvalidOperationException("Dispose() was called twise, or not initialized target.");
}
}
public T* Target
{
get
{
if (!_isCreated) throw new InvalidOperationException("target is not allocated.");
return _ptr;
}
}
public T Value
{
set { *_ptr = value; }
get { return *_ptr; }
}
public static implicit operator T(PtrHandle<T> value) { return *value._ptr; }
private void CheckAllocator()
{
if (!UnsafeUtility.IsValidAllocator(_alloc))
throw new InvalidOperationException("The buffer can not be Disposed because it was not allocated with a valid allocator.");
}
}
この PtrHandle<T> を使用して、NativeContiner に似た struct の状態変数は以下のように一括管理ができるようになります。
struct MyInfo
{
public int Size;
public bool Flag;
public MyStateEnum State;
}
struct MyProcessor<T> : IDisposable
where T: unmanaged
{
private NativeList<T> _buffer;
private PtrHandle<MyInfo> _info;
public MyProcessor(Allocator alloc)
{
_buffer = new NativeList<T>(alloc);
_info = new PtrHandle<T>(alloc);
}
public void Dispose()
{
_buffer.Dispose();
_info.Dispose();
}
public unsafe void Execute()
{
if(_info.Target->State == MyStateEnum.Default)
{
/* 何か処理 */
}
}
}
PtrHandle<T> は GameObject 側と JobSystem 側での変数の共有を想定しており、(ライブラリの外部に渡す場合には内容を別の出力専用 readonly struct に値をコピーしてから返すなどの安全対策をしておけば) Job の管理にも有用です。
デモでファイル読み込みの進捗状況を取得して表示させていますが、内部的には PtrHandle<T> を利用しています。
struct へのポインタを安全に保持したいだけなら大きさ1のNativeArrayを作ることも考えられますが、Unity標準のNativeContainerはJobSystemの安全装置によってJobSystemで使用中はメインスレッドからのアクセスが禁止されてしまうため、Job実行中の共有情報の参照には使えません。
よって、NativeContainerの安全装置のうち意図的にアクセッサの安全装置だけを殺したものとして PtrHandle<T> をつくり、これを各種管理情報の保持、参照に使います。
ライブラリに閉じ込めるなどしてポインタが暴れださないようにできれば、ポインタはすべてを解決する。
▽in readonly struct で速くな……らない!
実はしれっとスライスの実装を readonly struct で定義していたので、さらなるコピー削減のため StringEntity を引数に渡している部分に in をつけてみます。その結果……100 ms 程遅くなりました。
そもそも最初に頑張ってスライスを軽量化した結果、パディングの具合にもよりますがリリースビルドでは 8 byte ~ 16 byte のフットプリントしかありません。小さい struct では in readonly struct を渡して低速化する報告もあり、常々言われることではありますがやはり最適化に計測と確認は必須です。
▽文字列デコードのブロック処理
C# における char は最小データサイズが 2 byte になる UTF-16 が採用されています。ここで、例えば UTF-8 でエンコードされた、ほぼASCIIコードのテキストファイル(=ファイル上ではほぼ全て 1 byte)を一気にデコードすると、メモリ上にファイルサイズの倍の大きさの char配列が出現します。元のファイルサイズがMBクラスの大きさならあっという間にCPUのキャッシュからはみ出して処理速度が悲しいことになります。
というわけで、キャッシュ内でパース処理をするためにブロック単位で char に変換し、改行コードを解析して line を示すスライスに切り出し、ブロック内の切り出しが終わったら出来上がった line を ITextFilePaser.ParseLine(line) に流し込みます。
この line の切り出しの表現に、先頭部分のカタマリの挿入、削除に対応するラッパーを被せた NativeHeadRemovableList<T> を使用します。
`NativeHeadRemovableList` の実装(抜粋)
internal struct NativeHeadRemovableList<T> : IDisposable where T : unmanaged
{
private NativeList<T> _list;
private PtrHandle<int> _start;
public unsafe NativeHeadRemovableList(Allocator alloc) {}
public unsafe T this[int index]
{
get { return _list[_start + index]; }
set { _list[_start + index] = value; }
}
public unsafe int Length { get { return _list.Length - _start; } }
/* 中略 */
public unsafe void RemoveHead(int count = 1)
{
if (count < 1 || Length < count) throw new ArgumentOutOfRangeException("invalid length of remove target.");
_start.Value = _start + count;
}
public unsafe void InsertHead(T* ptr, int length)
{
if (length <= 0) throw new ArgumentOutOfRangeException("invalid size");
// when enough space exists in head
if (length <= _start)
{
_start.Value = _start - length;
UnsafeUtility.MemCpy(this.GetUnsafePtr(), ptr, UnsafeUtility.SizeOf<T>() * length);
return;
}
// slide internal data
int new_length = length + this.Length;
int len_move = this.Length;
_list.ResizeUninitialized(new_length);
T* dest = (T*)_list.GetUnsafePtr() + length;
T* source = (T*)_list.GetUnsafePtr() + _start;
UnsafeUtility.MemMove(dest, source, UnsafeUtility.SizeOf<T>() * len_move);
// insert data
_start.Value = 0;
UnsafeUtility.MemCpy((void*)_list.GetUnsafePtr(), (void*)ptr, UnsafeUtility.SizeOf<T>() * length);
}
}
改行を見つけたら当該部分のコピー後に NativeHeadRemovableList<T>.RemoveHead(int) で1行分ごそっと消しますが、内部的には _start に長さ分足しているだけです。
また、ブロック処理の都合上末尾に未処理のデータ片が残り、これを次回の処理開始時に配列の先頭に移動させねばなりません。そのために NativeHeadRemovableList<T>.InsertHead(T*, int) を実装した……のですが、処理手順を考えると char配列の受け取り前に残ったデータを UnsafeUtility.MemMove() で先頭に移動して、 Decoder.GetChars(byte*, int, char* ,int) に渡すポインタをその続きにすれば一番効率的だったことにこれを書いてる今気づきました。
現状で性能にほぼ影響がないので放置していますが、これから似たようなことをやる人はご注意ください。
いまどきこんな低レベルなところを弄る人がどのくらいいるかわかりませんが……
具体的なブロックサイズについては、当方の検証では 2kB ~ 4kB 程度が一番よさげでしたので、2kB を規定値として採用しました。
▽注文も非同期な感じで受け付けてほしい
さて、これでそこそこの速度でテキストファイルをパースできるようになったわけですが、せっかく非同期なので追加の要求です。複数の GameObject から好き勝手に Load, UnLoad の要求が出される状況に対応しましょう。
複数ファイルへの複数のユーザーからの問い合わせに対応するバージョンとして
AsyncTextFileLoader<T> を作ります。
`AsyncTextFileLoader` の実装(抜粋)
public class AsyncTextFileLoader<T> : IDisposable
where T : class, ITextFileParser, new()
{
private List<string> _pathList;
private Encoding _encoding;
private Allocator _alloc;
private Dictionary<int, ParseJob<T>> _parserPool;
private int _gen;
private int _blockSize;
private int _maxJobCount;
private NativeList<RunningJobInfo> _runningJob;
private List<PtrHandle<ReadStateImpl>> _state;
private List<T> _data;
private struct RunningJobInfo
{
public int FileIndex { get; }
public int ParserID { get; }
public RunningJobInfo(int file_index, int parser_index)
{
FileIndex = file_index;
ParserID = parser_index;
}
}
private enum FileAction
{
Store = 1,
UnLoad = -1,
}
private struct Request
{
public int fileIndex { get; }
public FileAction action { get; }
public Request(int index, FileAction action)
{
fileIndex = index;
this.action = action;
}
}
private NativeQueue<int> _parserAvail;
private NativeList<Request> _requestList;
private NativeList<int> _updateLoadTgtTmp;
private NativeList<int> _updateUnLoadTgtTmp;
private UnLoadJob<T> _unLoadJob;
/* 中略 */
public int MaxJobCount
{
get { return _maxJobCount; }
set { if(value > 0) _maxJobCount = value; }
}
public int LoadWaitingQueue { get { return _loadWaitingQueueNum; } }
public bool FlushLoadJobs { get; set; }
// 管理対象のファイルが追加されたら担当のデータクラス T を生成
public unsafe void AddFile(string str)
{
_pathList.Add(str);
_data.Add(new T());
_data[_data.Count - 1].Init();
var s_tmp = new PtrHandle<ReadStateImpl>(_alloc);
s_tmp.Target->Clear();
_state.Add(s_tmp);
}
// データとJobの状態について index でアクセス
public unsafe T this[int fileIndex]
{
get
{
if (!_state[fileIndex].Target->IsStandby)
throw new InvalidOperationException($"the job running now for fileIndex = {fileIndex}.");
return _data[fileIndex];
}
}
public unsafe ReadState GetState(int index)
{
return _state[index].Target->GetState();
}
// Load, UnLoad ともに外部からの注文はいったんリストにためて Update() で処理
public void LoadFile(int index)
{
_loadWaitingQueueNum++;
_requestList.Add(new Request(index, FileAction.Store));
}
public void UnLoadFile(int index)
{
_requestList.Add(new Request(index, FileAction.UnLoad));
}
public void Update()
{
this.UpdateImpl(this.FlushLoadJobs);
this.FlushLoadJobs = false;
}
// リストにためた注文を一気に処理する
private unsafe void UpdateImpl(bool flush_all_jobs = false)
{
// check job completed or not
for (int i= _runningJob.Length-1; i>=0; i--)
{
var job_info = _runningJob[i];
var read_state = _state[job_info.FileIndex];
if (read_state.Target->JobState == ReadJobState.WaitForCallingComplete)
{
_parserPool[job_info.ParserID].Complete();
read_state.Target->JobState = ReadJobState.Completed;
this.ReleaseParser(job_info.ParserID);
_runningJob.RemoveAt(i);
}
}
if(_unLoadJob.JobState == ReadJobState.WaitForCallingComplete)
{
_unLoadJob.Complete();
_unLoadJob.Clear();
}
// no requests. or all available parser were running. retry in next Update().
if (_requestList.Length == 0 || (_maxJobCount - _runningJob.Length <= 0 && !flush_all_jobs))
{
return;
}
//--- extract action
_updateLoadTgtTmp.Clear();
_updateUnLoadTgtTmp.Clear();
for (int i=0; i<_requestList.Length; i++)
{
var act = _requestList[i];
if (act.action == FileAction.Store)
{
var tgt_state = _state[act.fileIndex];
if (tgt_state.Target->RefCount == 0)
{
_updateLoadTgtTmp.Add(act.fileIndex);
}
tgt_state.Target->RefCount++;
}
else
{
_updateUnLoadTgtTmp.Add(act.fileIndex);
}
}
_requestList.Clear();
//--- preprocess unload action
for (int i=0; i< _updateUnLoadTgtTmp.Length; i++)
{
int id = _updateUnLoadTgtTmp[i];
var tgt_state = _state[id];
tgt_state.Target->RefCount--;
if (tgt_state.Target->RefCount == 0)
{
int found_index = _updateLoadTgtTmp.IndexOf(id);
if (found_index >= 0)
{
// remove from loading order (file loading is not performed)
_updateLoadTgtTmp.RemoveAtSwapBack(found_index);
}
else
{
// remove from loaded data
if (_unLoadJob.JobState == ReadJobState.Completed && tgt_state.Target->IsStandby)
{
//--- unload in job (workaround for LargeAllocation.Free() cost in T.UnLoad().)
_unLoadJob.AddUnLoadTarget(id, _data[id], _state[id].Target);
}
else
{
// now loading. unload request will try in next update.
tgt_state.Target->RefCount++; // reset ref count
this.UnLoadFile(id);
}
}
}
if (tgt_state.Target->RefCount < 0)
{
throw new InvalidOperationException($"invalid UnLoading for index = {id}.");
}
}
_updateUnLoadTgtTmp.Clear();
// schedule jobs
//--- unload job
_unLoadJob.UnLoadAsync();
//--- supply parsers for load job
int n_add_parser = Math.Max(_updateLoadTgtTmp.Length - _parserAvail.Count, 0);
if (!flush_all_jobs)
{
n_add_parser = Math.Min(this.MaxJobCount - _parserPool.Count, n_add_parser);
}
for (int i = 0; i < n_add_parser; i++) this.GenerateParser();
//--- run jobs
int n_job = Math.Min(_parserAvail.Count, _updateLoadTgtTmp.Length);
for(int i=0; i<n_job; i++)
{
int file_index = _updateLoadTgtTmp[i];
int p_id = _parserAvail.Dequeue();
var p_tmp = _parserPool[p_id];
var p_state = _state[file_index];
p_tmp.BlockSize = _blockSize;
p_tmp.ReadFileAsync(_pathList[file_index], _encoding, _data[file_index], p_state);
_runningJob.Add(new RunningJobInfo(file_index, p_id));
}
//--- write back excessive queue
_loadWaitingQueueNum = 0;
for (int i=n_job; i<_updateLoadTgtTmp.Length; i++)
{
int id = _updateLoadTgtTmp[i];
_state[id].Target->RefCount--; // reset ref count
this.LoadFile(id);
_loadWaitingQueueNum++;
}
_updateLoadTgtTmp.Clear();
}
}
大まかな流れとしては、
- (
Update()が呼ばれるまで) 任意の Load, UnLoad を受け付けてすべてリストにためる - たまった注文を Load と UnLoad に分ける
- まず Load だけを取り出し、各ファイルの参照カウントをインクリメントし、
ここで参照カウントが0→1になったなら LoadJob の予約表に書きこむ - 次に UnLoad だけを取り出し、各ファイルの参照カウントをデクリメントし、
ここで参照カウントが1→0になったなら、
2. LoadJob の予約表に該当ファイルの予約があれば、それを消す (その結果何もしない)
2. 予約がなければ UnLoadJob の対象リストに入れる - UnLoadJob を
schedule()する。 - LoadJob を
schedule()する。
Load だけでなく UnLoad も Job にしてしまっていますが、これについては次節で説明します。
ここにさらに同時に動作する LoadJob の最大数 MaxJobCount に合わせて、同時に保持するパーサーの数とジョブの割り当てを管理しています。
パーサーは一度動かすとファイル丸ごとをバッファすること、またそもそもファイルのロードは多数を同時に走らせることは稀という前提で、メモリ消費の削減の観点からこのような設計にしました。しかし、後述の課題により MaxJobCount はせいぜい 1 ~ 2 ぐらいまでしかまともに動かないことが判明しました。
実際の運用では、 LoadJob 待機中の注文数を取得するプロパティ AsyncTextFileLoader<T>.LoadWaitingQueue を参照して注文する GameObject 側がタイミングを調節する形になるでしょう。
▽大きなデータのUnLoad
大きなファイルの読み込みもそうですが、メモリ領域の破棄にもそれなりにコストがかかります。
大容量のデータをいくつも一気に UnLoad したりすると LargeAllocation.Free() に ms 単位で持っていかれかねません。せっかくパース処理そのものはワーカースレッドに追い出したのに、これでメインスレッドが遅くなったら片手落ちです。
幸い NativeContainer のアロケータはワーカースレッドでも動くので、多数のファイルを管理する AsyncTextFileLoader<T> では UnLoad() もワーカースレッドにやらせてメインスレッドを身軽にします。
ここで、 JobHandle.Schedule() の呼び出しコストを削減するため、 UnLoad() 対象のデータ (の GCHandle )のリストを1つの Job に渡して一気に UnLoad させます。
UnLoad 用の Job は以下のようになります。
`UnLoadJob` の実装(抜粋)
internal unsafe struct UnLoadJobTarget<Tdata>
where Tdata : class, ITextFileParser
{
internal GCHandle<Tdata> data;
internal ReadStateImpl* state_ptr; // UnLoad 対象の State. 書き換えだけ行うので生ポインタを渡す
internal int file_index;
public UnLoadJobTarget(int file_index, Tdata data, ReadStateImpl* state_ptr)
{
this.data = new GCHandle<Tdata>();
this.data.Create(data);
this.state_ptr = state_ptr;
this.file_index = file_index;
}
public unsafe void UnLoad()
{
this.state_ptr->JobState = ReadJobState.UnLoaded;
this.data.Target.UnLoad();
}
}
internal struct UnLoadJobInfo
{
internal ReadJobState job_state;
internal JobHandle job_handle;
internal Boolean alloc_handle;
}
internal struct UnLoadJob<Tdata> : IJob, IDisposable
where Tdata : class, ITextFileParser
{
internal NativeList<UnLoadJobTarget<Tdata>> _target;
internal PtrHandle<UnLoadJobInfo> _info; // UnLoadJob の管理情報
public unsafe UnLoadJob(Allocator alloc)
{
_target = new NativeList<UnLoadJobTarget<Tdata>>(alloc);
_info = new PtrHandle<UnLoadJobInfo>(alloc);
_info.Target->job_state = ReadJobState.Completed;
}
public unsafe void Dispose()
{
this.DisposeHandle();
_target.Dispose();
_info.Dispose();
}
private unsafe void DisposeHandle()
{
if (_info.Target->alloc_handle)
{
for (int i = 0; i < _target.Length; i++) _target[i].data.Dispose();
_info.Target->alloc_handle = false;
}
}
public void Clear()
{
this.DisposeHandle();
_target.Clear();
}
public unsafe void AddUnLoadTarget(int file_index, Tdata data, ReadStateImpl* state_ptr)
{
_target.Add( new UnLoadJobTarget<Tdata>(file_index, data, state_ptr) );
_info.Target->alloc_handle = true;
}
public unsafe JobHandle UnLoadAsync()
{
if(_target.Length > 0)
{
_info.Target->job_state = ReadJobState.UnLoadJob;
_info.Target->job_handle = this.Schedule();
return _info.Target->job_handle;
}
else
{
// no action
return new JobHandle();
}
}
public unsafe ReadJobState JobState { get { return _info.Target->job_state; } }
public unsafe void Execute()
{
for (int i = 0; i < _target.Length; i++) _target[i].UnLoad();
_info.Target->job_state = ReadJobState.WaitForCallingComplete;
}
public unsafe void Complete()
{
_info.Target->job_handle.Complete();
_info.Target->job_state = ReadJobState.Completed;
}
}
このジョブを1つインスタンス化しておいて、 UnLoad の注文が来たら UnLoadJob<T>.AddUnLoadTarget(int, T, PtrHandle<ReadStateImpl>) で対象の data を渡し、 UnLoadJob<T>.UnLoadAsync() で後始末させます。
課題
◎Burst でもっと速くならない?(対応済)
(2021/4/25)現行版でBurstに対応しました。
いつになるかは不明ですが、公式の案内では char には対応する予定らしいので、その暁にはもっと早くなるはず。
Burst does not support the following types:
- char (this will be supported in a future release)
- string as this is a managed type
ライブラリ内部ではASCII範囲の値しか検索、比較していないので、 char をすべて unit16 あたりにキャストして、関数ポインタ経由でBurstさせればもっと早くなる可能性は大いにあります。
しかし、公式が対応すると明言していますし、上記の手法で Burst による高速化が特に期待されるホットスポットは TryParse() や Split() 関数なので、Burst が char に対応したならユーザーデータクラスの ParseLine(line) をまるごと適用したほうがはるかに効果的でしょう。
◎複数のファイルを同時に読ませると途端に遅くなる(解決済)
(2021/4/25) Split() 関数内の Boxing を除去した現行版では解消しました。
デモシーン
/Assets/NativeStringCollections/Demo/Scenes/Demo_AsyncMultiFileManagement.unity で、
AsyncTextFileLoader<T> を使用して n個 のファイルを同時に読み込む指示を出すと、同時に始まった個々のジョブの処理時間が n倍 になり、結局速くなくなるどころか遅延時間の分だけ1個ずつ読ませていたほうがまし、という症状が出ています。
ストレージ <-> メモリ間、あるいは CPU <-> メモリ間の転送速度に引っかかったかとも思いましたが、プロファイラで確認したところメモリ転送負荷になりそうな `AsyncReadManager.Read()` や `NativeList.Add()` の処理時間をはじめ、 ~~ジョブの処理時間全体がプロファイラ上では 1ジョブの状態とほぼ同じ時間でした。しかし`AsyncTextFileReader内部のSystem.Diagnotics.Stopwatch` による処理時間の計測結果、および実時間では一気に動作が遅くなります。~~
小さなファイルで試すとプロファイラの経過時間と実時間が一致しました。1秒を超えるような長時間のジョブはプロファイラ内の経過時間がバグります。
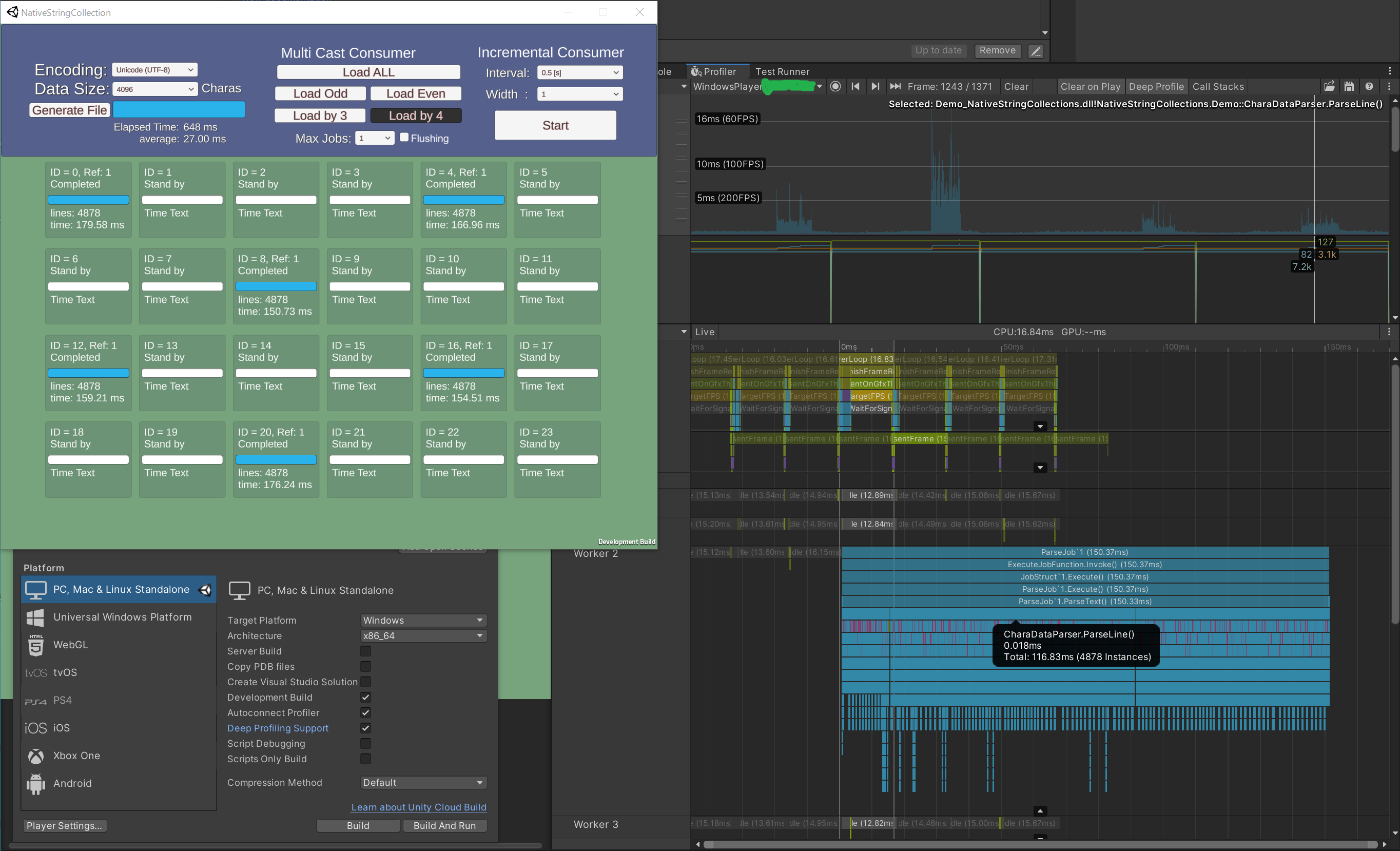
flushingの有無による変化を下記に示します。(Deep Profile)
-
flushing なし (MaxJobCount = 1)
-
flushing
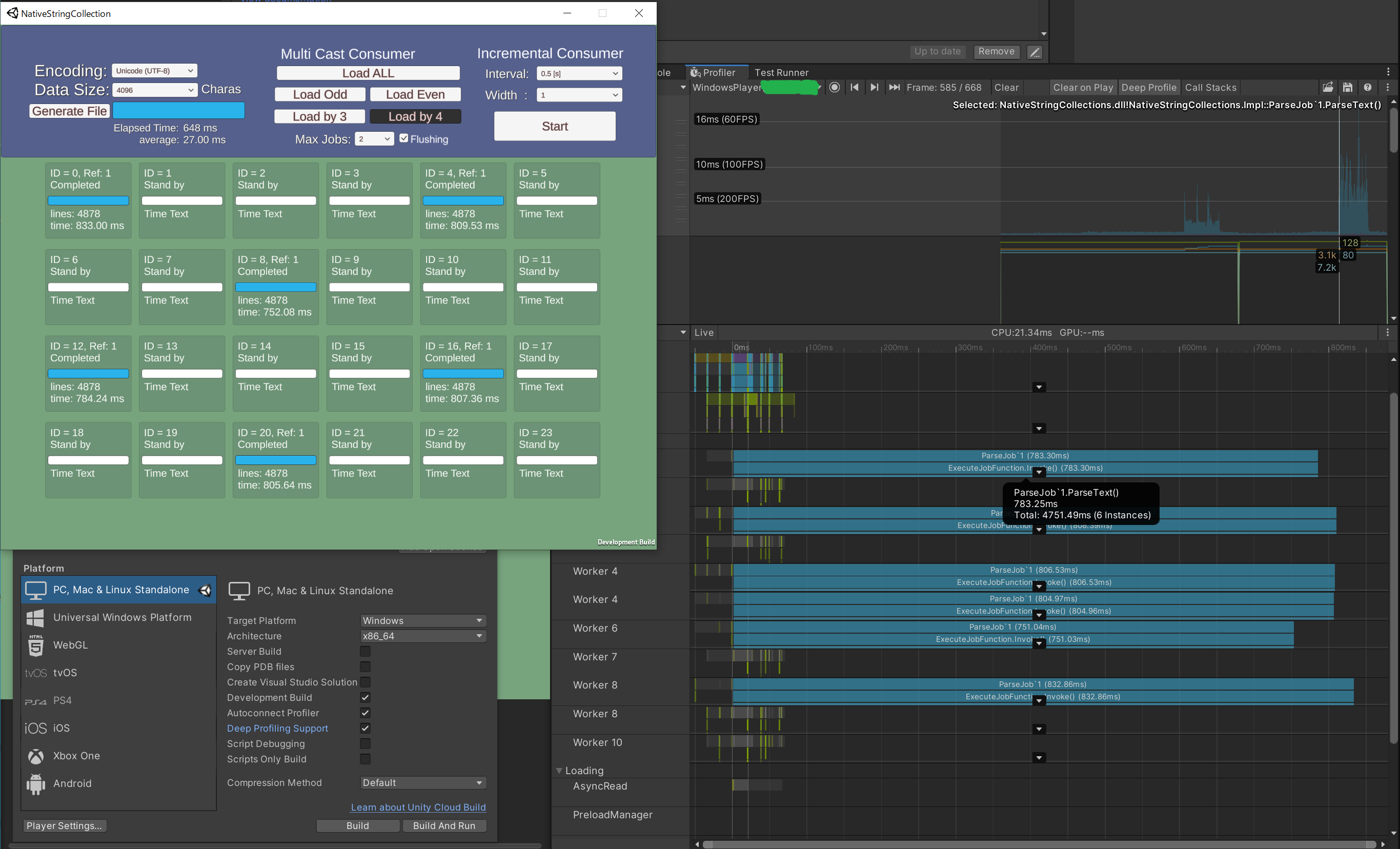
LoadJob を flush している場合の、ParseJob 内の各関数の経過時間は下記の通りです。
(数値は 6 Job の総和)
- 0.211 ms File.Read() (間に隙間はあるものの合計 1.0 ms 以下)
-
4751.49 ms ParseText()
- 704.39 ms ParseLinesFromBuffer()
-
3684.18 ms CharaDataParser.ParseLine()
- 165.25 ms ReadOnlyStringEntity.op_Equality()
- 348.70 ms ReadOnlyStringEntity.Slice()
- 904.67 ms StringSplitterExt.Split()
- 1071.26 ms StringParserExt.TryParse()
- 329.31 ms NativeBase64Decoder.GetBytes()
- 552.84 ms NativeStringList.Add()
- 155.91 ms NativeStringList.get_Last
- (156.24 ms others)
- 35.30 ms PostReadProc()
一方で job を1つずつ実行した場合の経過時間の一例は下記のとおりです。
- 0.035 ms File.Read()
-
150.33 ms ParseText()
- 22.24 ms ParseLinesFromBuffer()
-
116.83 ms CharaDataParser.ParseLine()
- 5.11 ms ReadOnlyStringEntity.op_Equality()
- 10.82 ms ReadOnlyStringEntity.Slice()
- 29.93 ms StringSplitterExt.Split()
- 34.11 ms StringParserExt.TryParse()
- 8.65 ms NativeBase64Decoder.GetBytes()
- 17.01 ms NativeStringList.Add()
- 4.66 ms NativeStringList.get_Last
- (6.54 ms others)
- 0.013 ms PostReadProc()
そして各関数の ParseText() 内の相対実行時間を比較すると下表のようになります。
| 関数名 | t[ms]_1Job | ratio_1Job | t[ms]_6Job | ratio_6Job | slower/Job |
|---|---|---|---|---|---|
| File.Read() | 0.035 | - | 0.211 | - | 1.00x |
| ParseText() | 150.33 | 100.0% | 4751.49 | 100.0% | 5.27x |
| ParseLinesFromBuffer() | 22.24 | 14.8% | 704.39 | 14.8% | 5.29x |
| CharaDataParser.ParseLine() | 116.83 | 78% | 3684.18 | 77.5% | 5.26x |
| ReadOnlyStringEntity.op_Equality() | 5.11 | 3.40% | 165.25 | 3.48% | 5.39x |
| ReadOnlyStringEntity.Slice() | 10.82 | 7.20% | 348.70 | 7.34% | 5.37x |
| StringSplitterExt.Split() | 29.93 | 19.9% | 904.67 | 19.0% | 5.04x |
| StringParserExt.TryParse() | 34.11 | 22.7% | 1071.26 | 22.5% | 5.23x |
| NativeBase64Decoder.GetBytes() | 8.65 | 5.75% | 329.31 | 6.90% | 6.35x |
| NativeStringList.Add() | 17.01 | 11.3% | 552.84 | 11.6% | 5.42x |
| NativeStringList.get_Last | 4.66 | 3.10% | 155.91 | 3.28% | 5.58x |
| (others) | 6.54 | 4.35% | 156.24 | 3.29% | 3.98x |
| PostReadProc() | 0.013 | - | 35.30 | - | 452x |
表右端の slower/Job は6Jobの実行時間を1Jobの実行時間で割った後、さらに6で除して Job 1つあたり何倍遅くなったかの比です。
不思議なことに関数全体にわたって均等に遅くなっています。
プロファイラによる観測データの転送でメモリ帯域を食われた可能性も考えましたが、
リリースビルドで同じ 4096 サイズに対し、LoadJob 1つの処理時間は
約 6.5 ms (@ 1 Job)-> 約 80 ms (@ 6 Job)
とむしろ比率的にはよりひどい状態で同様の現象が見られます。
また、 PostReadProc() はファイル先頭部分に Base64 で埋め込んだ全データのIDのリストを ParseLine() で実際に解析した CharaData のIDと照合して読み込みエラーがないか確認をするのと、 NativeStringList.Add() の繰り返しでバッファが伸長し、各 CharaData の name の参照先が無効になっているはずなのでその再構築をしています。
つまりほぼ計算なしに全データを走査して long の比較とchar配列のコピーをしているだけなので、真にメモリバウンドな処理をするとここまで遅くなるということを示していると考えられます。
以上から、やはりキャッシュミスとは異なる現象が起きているように思われ、
自明並列の部分が並列化でなぜ遅くなるのか私の頭では原因がつかめません……
AsyncReadManager 自体あまり公式 script reference 以外の情報がなく、そもそもアセットバンドル等のひとまとめにしたバイナリデータをロードするのに用意されたAPIで、完全に用途が違うものを変な使い方している、と言われればそれまでですが……
Unityの中の人に聞ければ解決するかもしれませんが、ちょっとそこまでのお金はないのでだれか解決してくれるとすごくたすかります(他力本願)
参考記事
Qiita:
【Unity】ファイルを非同期で読み込んでアンマネージドメモリに展開できるAsyncReadManagerを試してみた
【Unity】NativeArrayについての解説及び実装コードを読んでみる
【Unity】UnsafeUtilityについて纏めてみる
【Unity】BurstCompilerをJobSystem以外でも使いたい
Unity C# Job Systemに参照型を持ち込む
【Unity】スタックトレースを有効にしてNativeArrayのメモリリークを探す
【Unity】UnsafeUtility基礎論【入門者向け】
Blog:
System.Text.Encoding で Shift JIS を使いたい
【C#】Big Size Structが値コピーでつらいならin引数で値コピーしなければいいじゃない!! < それ本当?
Official:
C# Reference Source